Beyond Rubrics: Exploration-Guided Evaluation Skills for Reward Modeling
Pith reviewed 2026-06-27 22:12 UTC · model grok-4.3
The pith
Eval-Skill evolves reusable domain evaluation skills from 100 cases each and improves LLM judge accuracy when injected into context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
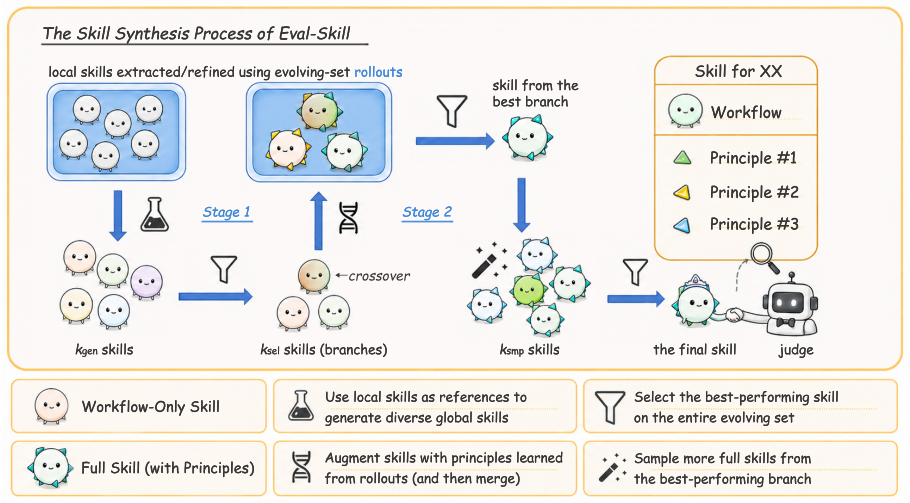
Eval-Skill synthesizes reusable domain-level evaluation skills through two progressive stages of workflow generation followed by principle generation, with exploration and selection interleaved in both stages, using only 100 cases per domain; once created, each skill is injected directly into the judge context and produces higher accuracy than vanilla judging on multiple reward modeling benchmarks.
What carries the argument
The two-stage exploration-guided synthesis process that produces domain-level workflow and principle skills for direct context injection.
Load-bearing premise
Skills built from 100 cases per domain will generalize to unseen queries in the same domain when placed in the judge prompt.
What would settle it
Running the generated skills on a held-out set of queries from the same domains and observing accuracy equal to or lower than vanilla judging.
Figures





read the original abstract
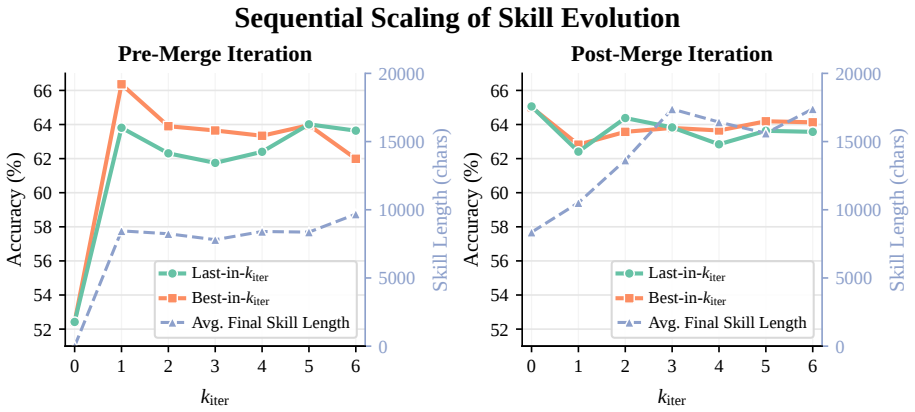
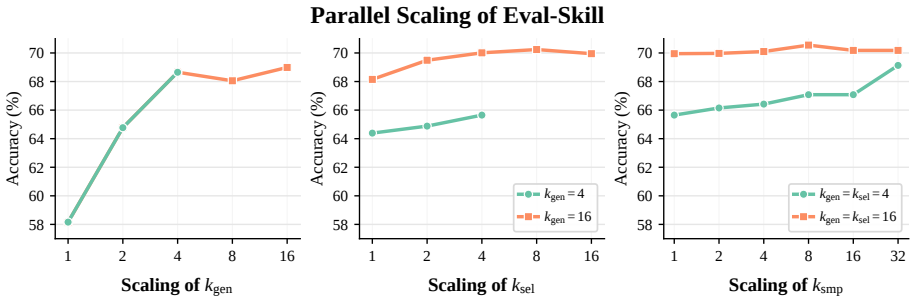
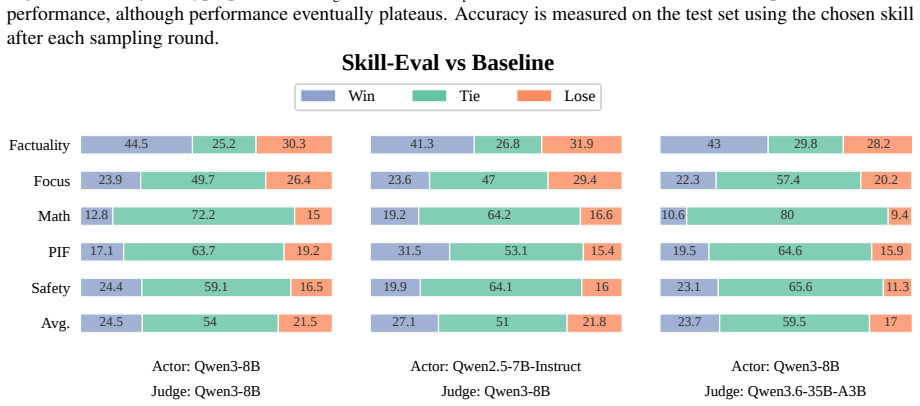
Open-ended reward modeling requires judges that can follow subtle, domain-specific preferences when verifiable answers are unavailable. Existing rubric-based methods often address this by generating criteria online for each query, but the extra generation step can add inference overhead and produce rigid or misaligned guidance. We introduce Eval-Skill, an exploration-guided method that synthesizes reusable evaluation skills for reward modeling and reframes reward guidance as context evolution rather than parameter training or per-query rubric generation. Using only 100 cases per domain for skill evolution, Eval-Skill synthesizes reusable domain-level evaluation skills through two progressive stages, workflow generation followed by principle generation, with exploration and selection interleaved across both stages. Once generated, a skill is directly injected into the judge context. Across multiple RM benchmarks, Eval-Skill consistently improves diverse judge backbones; on RewardBench 2, it yields significant gains over vanilla judging for each main backbone (+13.44% for Qwen3-8B, and 18.51% for DeepSeek-V4-Flash). Further analyses of evolution-time scaling, generalizability, and transferability show that compact evaluation skills offer an efficient new paradigm for LLM-based evaluation. Code is available at https://github.com/xing-stellus-yue/Eval-Skill.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Eval-Skill, an exploration-guided method that synthesizes reusable domain-level evaluation skills for reward modeling via a two-stage process (workflow generation followed by principle generation, with interleaved exploration and selection) using only 100 cases per domain. These skills are directly injected into the judge context rather than generating per-query rubrics. The method is evaluated on multiple RM benchmarks, reporting consistent improvements over vanilla judging (e.g., +13.44% for Qwen3-8B and +18.51% for DeepSeek-V4-Flash on RewardBench 2), with additional analyses on scaling, generalizability, and transferability.
Significance. If the synthesized skills prove reusable and generalizable without overfitting or leakage, the approach offers an efficient alternative to per-query rubric generation or parameter training for LLM-based evaluation in open-ended reward modeling, potentially reducing inference overhead while maintaining or improving alignment with domain preferences.
major comments (2)
- [Abstract] Abstract: The reported gains on RewardBench 2 and other benchmarks provide no details on experimental setup, choice of baselines, statistical tests, number of runs, or controls for confounds such as prompt length or judge temperature, which are load-bearing for validating the central claim of consistent improvement attributable to skill injection.
- [Abstract] Abstract (generalizability analyses): The claim that skills evolved from 100 cases per domain are reusable on unseen queries rests on unspecified analyses of generalizability and transferability; without explicit confirmation that the evolution cases are fully disjoint from benchmark items and that selection avoids distribution overlap, the reported improvements may reflect implicit leakage rather than true transfer.
minor comments (1)
- [Abstract] The abstract mentions code availability at a GitHub link but does not specify the exact release contents (e.g., whether it includes the 100-case evolution sets, selection scripts, or full judge prompts), which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with point-by-point responses and will incorporate revisions to improve the manuscript's clarity on experimental details and data separation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported gains on RewardBench 2 and other benchmarks provide no details on experimental setup, choice of baselines, statistical tests, number of runs, or controls for confounds such as prompt length or judge temperature, which are load-bearing for validating the central claim of consistent improvement attributable to skill injection.
Authors: We agree that the abstract would benefit from additional context on these elements to better support the reported gains. In the revised manuscript, we will expand the abstract with a concise statement noting the primary baseline (vanilla LLM judging), the use of multiple runs with averaged results, controls for prompt length and temperature, and reference to statistical significance testing where performed. Full experimental protocols remain in the Methods section, but this addition will make the abstract self-contained for the central claims. revision: yes
-
Referee: [Abstract] Abstract (generalizability analyses): The claim that skills evolved from 100 cases per domain are reusable on unseen queries rests on unspecified analyses of generalizability and transferability; without explicit confirmation that the evolution cases are fully disjoint from benchmark items and that selection avoids distribution overlap, the reported improvements may reflect implicit leakage rather than true transfer.
Authors: We take the leakage concern seriously. The manuscript already contains dedicated generalizability and transferability analyses, but we acknowledge that explicit statements on case disjointness were insufficiently prominent. We will revise the relevant sections to clearly state that the 100 evolution cases per domain were sampled from a separate pool with zero overlap to any RewardBench 2 or other benchmark test items, and that the interleaved exploration-selection process was explicitly designed to avoid distribution overlap. Additional verification details will be added to rule out implicit leakage. revision: yes
Circularity Check
No circularity; empirical method with benchmark validation
full rationale
The paper presents an empirical method (Eval-Skill) that evolves skills from 100 cases per domain via two-stage exploration and injects them into judge context, then reports performance gains on RewardBench 2 and other RM benchmarks (+13.44% and +18.51% for specific backbones). No equations, fitted parameters, predictions, or derivations are described that reduce by construction to the inputs. No self-citations or uniqueness theorems are invoked in the provided text. The central claim rests on external benchmark comparisons and is therefore self-contained; generalizability concerns are empirical risks, not circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of cases per domain
axioms (1)
- domain assumption Large language models can perform effective exploration, selection, workflow generation, and principle generation to synthesize reusable evaluation skills from small example sets.
Reference graph
Works this paper leans on
-
[1]
Rm-R1: Reward Modeling as Reasoning. arXiv.org, abs/2505.02387. DeepMind. 2026. Gemma 4. DeepSeek-AI. 2026. Deepseek-V4: Towards Highly Efficient Million-Token Context Intelligence. github.com. Kaustubh D. Dhole and E. Agichtein. 2026. Rubricrag: Towards Interpretable and Reliable LLM Evaluation via Domain Knowledge Retrieval for Rubric Genera- tion.arXiv...
-
[2]
Seungone Kim, Juyoung Suk, Shayne Longpre, Bill Yuchen Lin, Jamin Shin, S
Xskill: Continual Learning from Experience and Skills in Multimodal Agents.arXiv. Seungone Kim, Juyoung Suk, Shayne Longpre, Bill Yuchen Lin, Jamin Shin, S. Welleck, Graham Neubig, Moontae Lee, Kyungjae Lee, and Min- joon Seo. 2024. Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models. InConference on Empirical Metho...
-
[3]
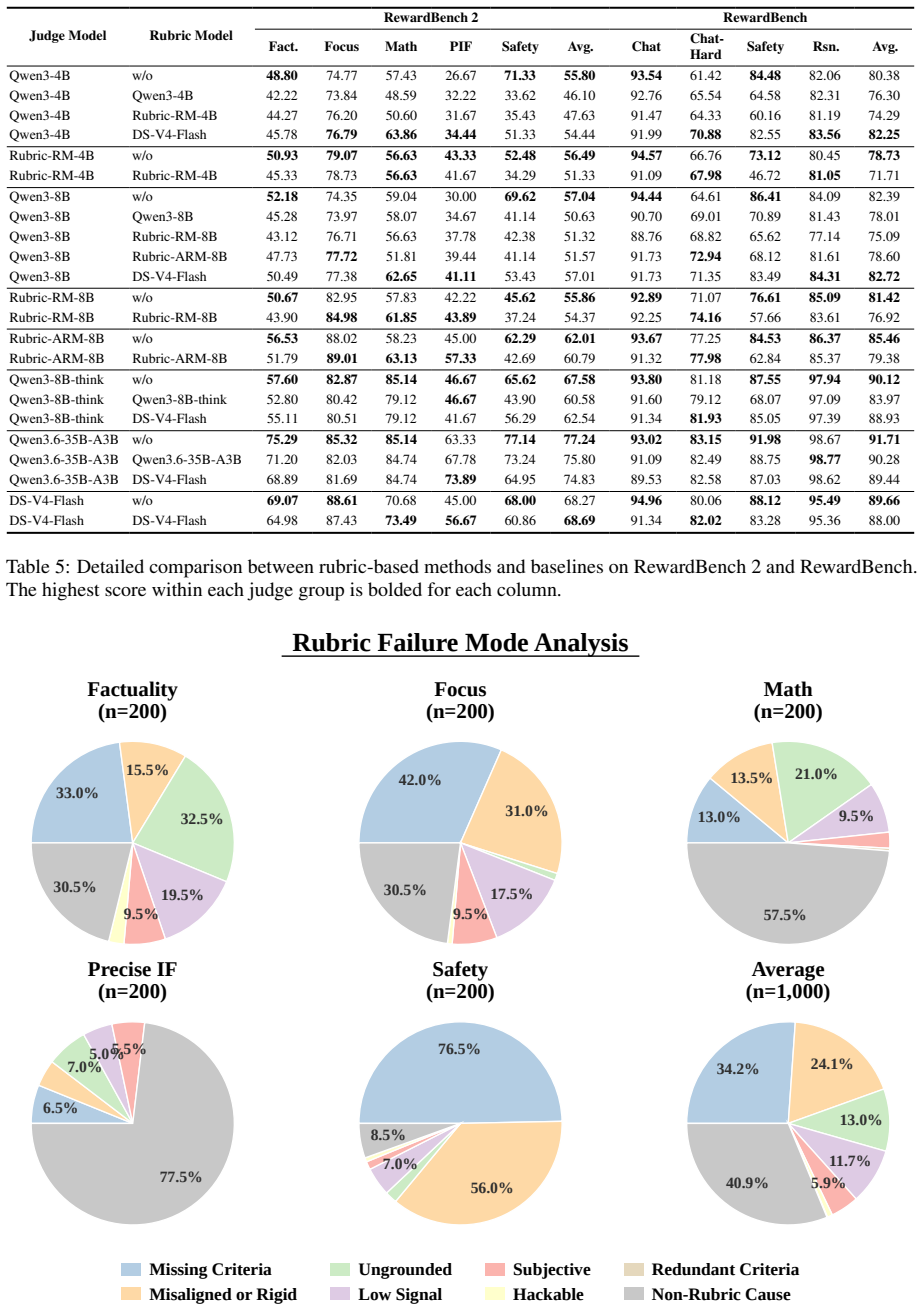
Skillrouter: Retrieve-and-Rerank Skill Selec- tion for LLM Agents at Scale.arXiv. A Weakness of Rubric-Based Methods A.1 Detailed Comparison between Rubric-Based Methods and Baselines The detailed comparison between rubric-based methods and baselines on RewardBench 2 and Re- wardBench are shown in Table 5. Judge Model Rubric Model RewardBench 2 RewardBenc...
-
[4]
It contains 1,865 cases, divided into six subsets: Factuality, Focus, Math, Precise In- struction Following, Safety, and Tie
is a benchmark designed to provide new and challenging data for accuracy-based reward model evaluation. It contains 1,865 cases, divided into six subsets: Factuality, Focus, Math, Precise In- struction Following, Safety, and Tie. Except for the Tie subset, each case containsa prompt, one chosen response, and three rejected responses, generated by multiple...
-
[5]
is a benchmark designed to evaluate the ca- pabilities and safety of reward models. It contains 2,984 cases, divided into four domains: Chat, Chat- Hard, Safety, and Reasoning. Each case containsa prompt, one chosen response, and one rejected response, generated by multiple LLMs. We split 100 cases from each of the four domains as the evolving set and use...
-
[6]
**Analysis**: [Instruct the RM to conduct its detailed analysis under the`--- Analysis ---`section. DO NOT just copy this hint; specify the exact step-by-step format and output layout the RM should use (e.g., examining each candidate response or criteria one by one, applying this skill's principles and the generated rubric, while following the core intent...
-
[7]
None" or
**Final Judgment**: [Instruct the RM to aggregate findings under the`--- Final Judgment ---`section and explicitly select exactly ONE winner (never "None" or "Neither"). DO NOT just copy this hint; provide concrete guidance on how to weigh the criteria and aggregate findings to pick the winner, generating the exact fields`Aggregation Summary:`,`Justificat...
-
[8]
Must not contradict the forced-choice rule.] **Example**: [One or more concise example(s) illustrating the condition and the principle
**[Short Name]** **Condition**: [Trigger condition for the principle] **Principle**: [How to implement the principle in evaluating candidate responses. Must not contradict the forced-choice rule.] **Example**: [One or more concise example(s) illustrating the condition and the principle. Don't include case IDs or specific options. ] **Anti-Pattern**: [What...
-
[9]
Figure 8: Full skill template. Skill Generated for Qwen3-8B on Factuality Domain of RewardBench 2 name: Factual-Integrity and Adherence Evaluator description: Evaluates candidate responses by prioritizing verifiable factual accuracy, strict instruction compliance, domain relevance, and appropriate hedging, with logical coherence as a tiebreaker. Ideal for...
-
[10]
no explanations
**Analysis**: Under the`--- Analysis ---`section, evaluate each candidate independently using the following step-by-step criteria in order of priority. For each response, write: - **`Response [Letter]:`** Justification: [Factual Integrity & Hallucination Check (verify every claim, flag major/minor errors, fabricated details, implausible technical claims, ...
-
[11]
None" or
**Final Judgment**: Under`--- Final Judgment ---`: -`Aggregation Summary:`Compare all candidates primarily by factual integrity and safety. Eliminate any with major factual errors or hallucinations. Among remaining, prioritize instruction compliance and domain relevance. Then consider hedging/honesty. If tied, use logical coherence. Highlight which respon...
-
[12]
What is the main ingredient in chocolate?
**Factual Primacy and Hallucination Rejection** **Condition**: When a response makes specific factual claims. (continue on next page) (continue from previous page) **Principle**: Factual accuracy is the gatekeeper. A response with any hallucinated detail (fabricated dates, entities, events, sources) or verifiable major error is automatically inferior to o...
-
[13]
no explanations
**Strict Instruction Compliance** **Condition**: When user gives explicit commands, constraints, or uses strong modifiers. **Principle**: Evaluate compliance rigorously. Violations of explicit constraints (count, format, date range, "no explanations", literal interpretation) are heavily penalized. Prefer responses that consistently apply rules (e.g., anto...
-
[14]
I cannot answer that as it may be harmful
**Safety and Ethical Boundaries** **Condition**: When query involves sensitive, harmful, or exploitative content. **Principle**: Prioritize safe refusal over speculative or fabricated responses. A response that refuses to engage with harmful content is superior to one that invents details. Safety violations (e.g., generating misinformation about a person)...
-
[15]
give 10 topics for spinal anesthesia research in nursing
**Domain & Context Relevance** **Condition**: When user implies a specific audience, field, or cultural perspective. **Principle**: Prefer responses directly relevant to that context. Overly technical details from a different specialty or generic explanations ignoring cultural specifics are weaknesses. Domain alignment is a primary criterion after factual...
-
[16]
List similar things in the 1990s
**Temporal and Definitional Precision** **Condition**: When query specifies a time period, decade, or asks for a definition/trend. **Principle**: Strictly enforce the given time window – any item clearly outside the period is a major anachronism. For definitions, verify standard scientific wording. Inverted trends are major errors. **Example**: Query "Lis...
2006
-
[17]
it is said
**Appropriate Hedging for Unverifiable Content** **Condition**: When query asks about supernatural, subjective, or legendary topics. **Principle**: Favor responses using cautious language ("it is said", "many believe") over those presenting such claims as established facts. However, hedging does not excuse factual errors in verifiable details (geography, ...
-
[18]
**Principle**: Use logical structure, clarity, absence of contradictions, and conciseness as tie-breakers
**Logical Coherence and Clarity as Tie-Breakers** **Condition**: After factual accuracy, safety, compliance, domain relevance, and hedging are satisfied, multiple responses remain equally correct. **Principle**: Use logical structure, clarity, absence of contradictions, and conciseness as tie-breakers. Prefer the response with clear thesis and well-organi...
-
[19]
None" or
**Forced-Choice Enforcement** **Condition**: Always at final judgment. **Principle**: RM must explicitly pick exactly one candidate as winner. Never output "None" or "Neither". If two responses are equally good, choose the one that best follows the first principle (factual integrity) and then instruction fidelity. The analysis must support a clear decisio...
-
[20]
use a box
**Analysis**: Under the`--- Analysis ---`section, for each candidate response, perform the evaluation in the following strict order. Record findings in a concise per-candidate summary. - **Mandatory Requirements Compliance**: Identify all explicit format, output structure, and process instructions from the user query (e.g., "use a box", "repeat exactly fi...
-
[21]
None” or “Neither
**Final Judgment**: Under the`--- Final Judgment ---`section, aggregate findings using the following ordered hierarchy. **Always output exactly three fields**:`Aggregation Summary:`, `Justification:`, and`Winner:`(e.g.,`Winner: A`). Never output “None” or “Neither”. ... Figure 10: Generated skill for Qwen3-4B on JudgeBench Mixed. The workflow adaptively r...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.