Structure-Preserving Correction Learning for Sparse Bayesian Inference in Brain Source Imaging
Pith reviewed 2026-06-27 22:56 UTC · model grok-4.3
The pith
Unfolding classical sparse Bayesian solvers and learning structured corrections improves M/EEG brain source reconstruction while preserving interpretability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
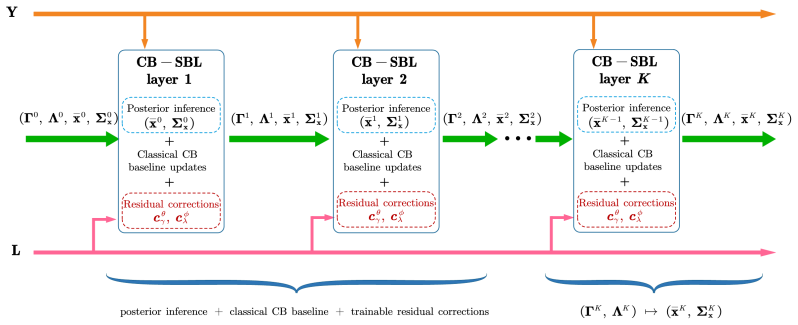
By unfolding a classical joint hyperparameter-learning solver into a trainable neural architecture that mirrors the original iterations and initializing it to recover the classical solver exactly, then adding progressively expressive correction-learning mechanisms, the framework learns structured corrections to the update dynamics. This improves empirical reconstruction performance and convergence behavior over the baseline while retaining the interpretability and model-based character of the original Bayesian inference.
What carries the argument
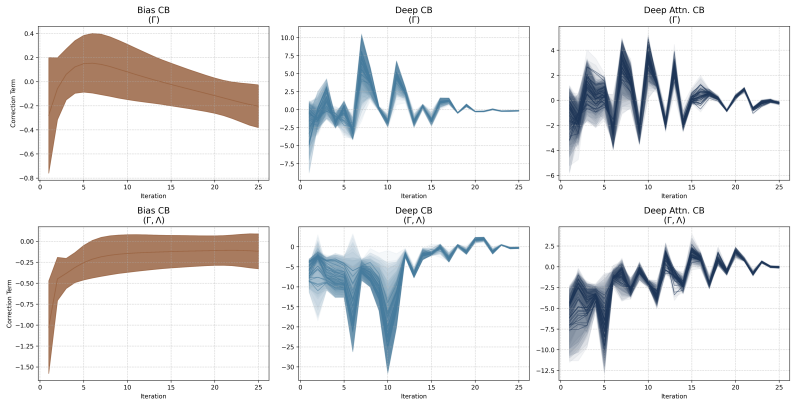
The unfolded neural architecture with learnable correction terms (biases, MLP, attention-based refinements) that mirror the original solver iterations and are initialized to recover it exactly.
If this is right
- Learned correction variants improve reconstruction performance over the baseline unfolded solver.
- Convergence behavior is enhanced compared to the classical approach.
- The algorithmic transparency and Bayesian structure of the original solver are preserved.
- Joint estimation of source and noise hyperparameters remains supported.
Where Pith is reading between the lines
- This approach could extend to other iterative solvers in Bayesian inference tasks outside neuroimaging.
- Attention mechanisms might allow the corrections to adapt to spatial patterns in brain sources.
- Hybrid use of different correction types could be tested for optimal performance.
Load-bearing premise
The neural architecture can be initialized to recover the classical iterative solver exactly, and the learned corrections improve performance without violating the Bayesian structure or causing instability in hyperparameter estimation.
What would settle it
Training the correction mechanisms and observing no improvement in reconstruction accuracy or convergence speed on validation M/EEG data compared to the baseline unfolded solver.
Figures
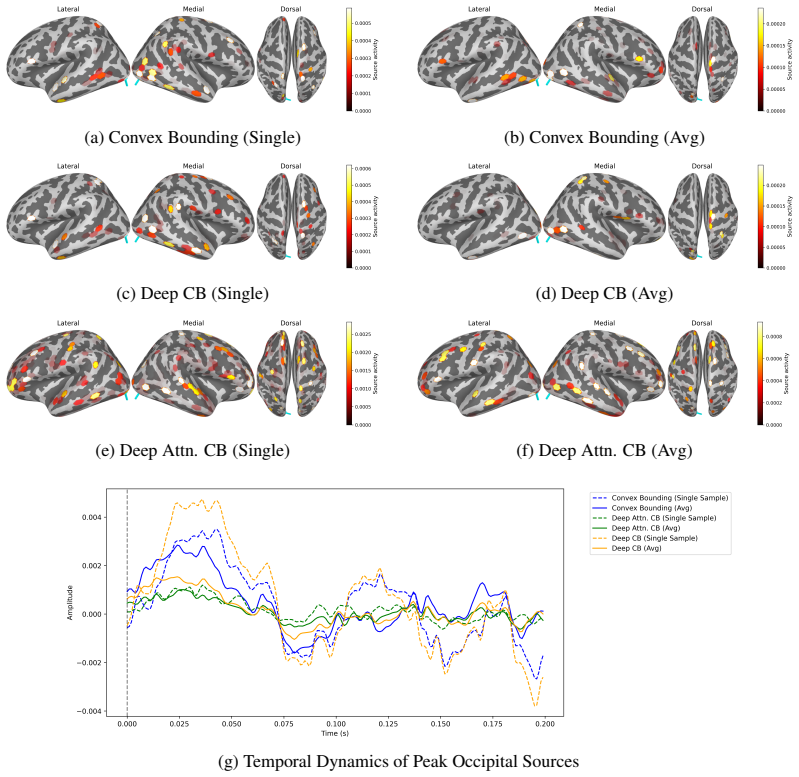
read the original abstract
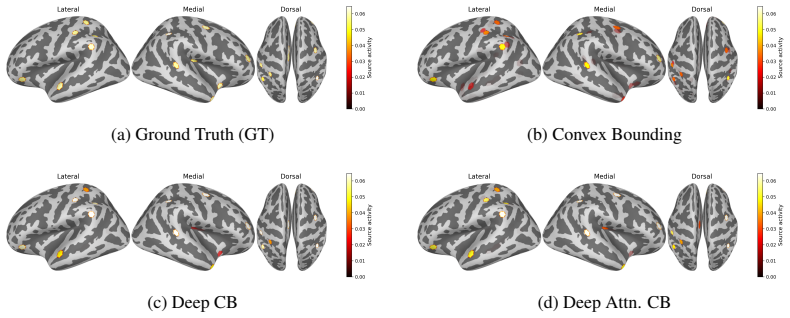
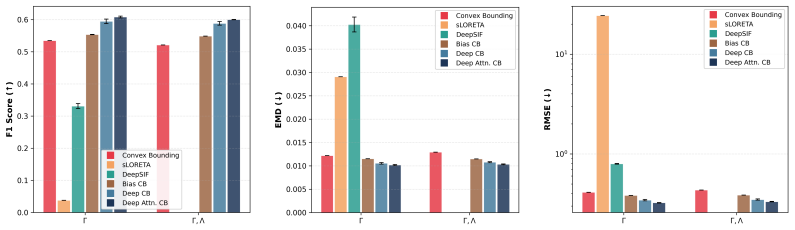
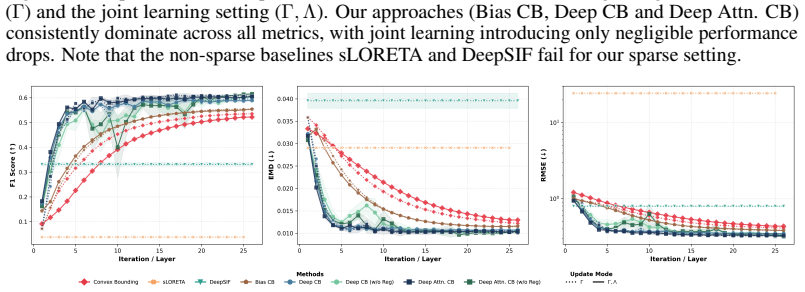
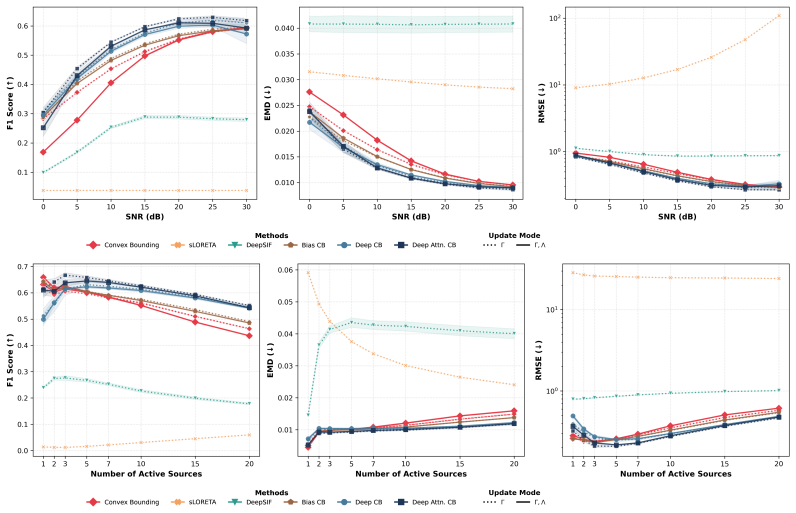
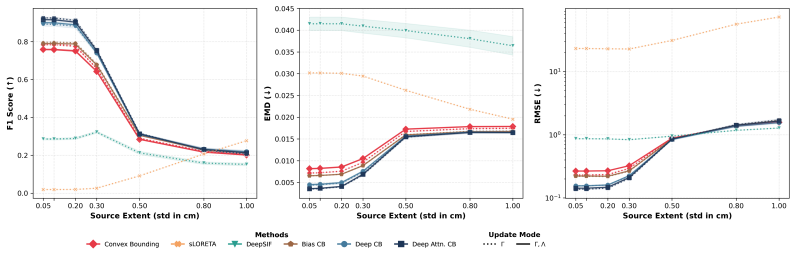
Classical sparse Type-II Bayesian methods for M/EEG brain imaging support joint estimation of source and noise hyperparameters, but rely on fixed iterative update rules. Although these updates are principled and interpretable, their dynamics cannot be adapted from data. We propose to learn the update mechanism itself while preserving the underlying Bayesian structure by unfolding a classical joint hyperparameter-learning solver into a trainable neural architecture whose layers mirror the original iterations. The resulting framework is initialized to recover the classical solver exactly before training and is enriched through progressively more expressive correction-learning mechanisms, ranging from learnable biases to adaptive MLP and attention-based contextual refinements. In this way, training does not replace Bayesian inference with a black-box predictor, but instead learns structured correction terms while retaining the interpretability and model-based character of the original update dynamics. Structured correction learning therefore aims to improve empirical reconstruction performance without replacing the original model-based inference mechanism. Experimental results show that the learned correction variants improve reconstruction performance and convergence behavior over the baseline unfolded solver while preserving its algorithmic transparency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes unfolding a classical joint hyperparameter-learning solver for sparse Type-II Bayesian inference in M/EEG brain source imaging into a trainable neural architecture. Layers mirror the original iterations and are initialized to recover the classical solver exactly; the architecture is then augmented with progressively expressive correction modules (learnable biases, MLPs, attention-based refinements) that add structured corrections to the updates. The central claim is that this yields improved reconstruction performance and convergence while preserving the original Bayesian structure, interpretability, and model-based character rather than replacing it with a black-box predictor.
Significance. If the initialization exactly recovers the classical solver and the learned corrections demonstrably improve performance without violating the Bayesian update dynamics or introducing instability, the approach offers a principled hybrid between model-based and data-driven methods. The exact recoverability at initialization and the explicit retention of algorithmic transparency are concrete strengths that could be valuable in neuroimaging applications where both accuracy and interpretability matter.
major comments (1)
- [§4] §4 (Experimental results): The abstract and framework description assert that learned correction variants improve reconstruction performance and convergence over the baseline unfolded solver, yet the manuscript provides no details on the datasets, baselines, quantitative metrics, statistical tests, or controls for post-hoc selection. This absence prevents verification that the reported gains are robust and directly attributable to the correction mechanism rather than implementation choices.
minor comments (2)
- [Abstract] Abstract: The description of the correction mechanisms (biases to MLP to attention) is clear, but adding one sentence on the scale of the reported gains (e.g., relative improvement in a standard metric) would strengthen the summary of results.
- [§3] Notation: The distinction between the original iterative updates and the correction terms could be made more explicit with a single equation contrasting the classical form and the corrected form.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation of minor revision. The single major comment highlights a genuine gap in the presentation of experimental details, which we will address directly in the revision.
read point-by-point responses
-
Referee: [§4] §4 (Experimental results): The abstract and framework description assert that learned correction variants improve reconstruction performance and convergence over the baseline unfolded solver, yet the manuscript provides no details on the datasets, baselines, quantitative metrics, statistical tests, or controls for post-hoc selection. This absence prevents verification that the reported gains are robust and directly attributable to the correction mechanism rather than implementation choices.
Authors: We agree that the current §4 lacks sufficient detail for independent verification. In the revised manuscript we will expand the experimental section to explicitly report: (i) the precise synthetic and real M/EEG datasets employed together with their generation or acquisition parameters, (ii) the complete set of baselines (including the classical Type-II solver and any other unfolded or data-driven comparators), (iii) all quantitative metrics and their definitions, (iv) the statistical tests performed and any multiple-comparison corrections, and (v) any post-hoc selection procedures or controls. These additions will make the performance claims fully reproducible and directly attributable to the correction modules. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper unfolds a classical Type-II Bayesian solver into a neural architecture that is explicitly initialized to recover the original iterative updates exactly, then adds learnable correction terms (biases, MLPs, attention) on top. The central claim is that these corrections empirically improve reconstruction and convergence while preserving the Bayesian structure; this is presented as an experimental outcome rather than a quantity forced by the initialization or by any fitted parameter being renamed as a prediction. No self-citation is invoked as a load-bearing uniqueness theorem, no ansatz is smuggled, and no derivation step reduces the target performance metric to a definition or fit by construction. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- correction module parameters
axioms (1)
- domain assumption Classical iterative update rules can be exactly recovered by appropriate initialization of the neural architecture.
Reference graph
Works this paper leans on
-
[1]
Chang Cai, Ali Hashemi, Mithun Diwakar, Stefan Haufe, Kensuke Sekihara, and Srikantan S. Nagarajan. Robust estimation of noise for electromagnetic brain imaging with the Champagne algorithm.NeuroImage, 225:117411, 2021. doi: 10.1016/j.neuroimage.2020.117411
-
[2]
Colton and Rainer Kress.Inverse Acoustic and Electromagnetic Scattering Theory, volume 93
David L. Colton and Rainer Kress.Inverse Acoustic and Electromagnetic Scattering Theory, volume 93. Springer, 1998
1998
-
[3]
Sereno, Roger B
Bruce Fischl, Martin I. Sereno, Roger B. H. Tootell, and Anders M. Dale. High-resolution intersubject averaging and a coordinate system for the cortical surface.Human Brain Mapping, 8(4):272–284, 1999
1999
-
[4]
Ebersole
Manfred Fuchs, Jörn Kastner, Michael Wagner, Susan Hawes, and John S. Ebersole. A standardized boundary element method volume conductor model.Clinical Neurophysiology, 113(5):702–712, 2002
2002
-
[5]
Mecklenbräuker, and Geert Leus
Peter Gerstoft, Santosh Nannuru, Christoph F. Mecklenbräuker, and Geert Leus. Sparse bayesian learning for doa estimation in heteroscedastic noise.arXiv preprint arXiv:1711.03847, 2017
Pith/arXiv arXiv 2017
-
[6]
Gifford, Kshitij Dwivedi, Gemma Roig, and Radoslaw M
Alessandro T. Gifford, Kshitij Dwivedi, Gemma Roig, and Radoslaw M. Cichy. A large and rich EEG dataset for modeling human visual object recognition.NeuroImage, 264:119754, 2022
2022
-
[7]
Engemann, Daniel Strohmeier, Christian Brodbeck, Roman Goj, Mainak Jas, Teon Brooks, Lauri Parkkonen, and Matti S
Alexandre Gramfort, Martin Luessi, Eric Larson, Denis A. Engemann, Daniel Strohmeier, Christian Brodbeck, Roman Goj, Mainak Jas, Teon Brooks, Lauri Parkkonen, and Matti S. Hämäläinen. MEG and EEG data analysis with MNE-Python.Frontiers in Neuroscience, 7 (267):1–13, 2013
2013
-
[8]
Learning fast approximations of sparse coding
Karol Gregor and Yann LeCun. Learning fast approximations of sparse coding. InProceedings of the 27th International Conference on Machine Learning, pages 399–406, 2010
2010
-
[9]
Ali Hashemi, Chang Cai, Gitta Kutyniok, Klaus-Robert Müller, Srikantan S. Nagarajan, and Stefan Haufe. Unification of sparse bayesian learning algorithms for electromagnetic brain imaging with the majorization minimization framework.NeuroImage, 239:118309, 2021. doi: 10.1016/j.neuroimage.2021.118309
-
[10]
Nagara- jan, and Stefan Haufe
Ali Hashemi, Yijing Gao, Chang Cai, Sanjay Ghosh, Klaus-Robert Müller, Srikantan S. Nagara- jan, and Stefan Haufe. Efficient hierarchical bayesian inference for spatio-temporal regression models in neuroimaging. InAdvances in Neural Information Processing Systems, volume 34, pages 24855–24870, 2021
2021
-
[11]
Ali Hashemi, Chang Cai, Yijing Gao, Sanjay Ghosh, Klaus-Robert Müller, Srikantan S. Na- garajan, and Stefan Haufe. Joint learning of full-structure noise in hierarchical bayesian regression models.IEEE Transactions on Medical Imaging, 43(2):610–624, 2024. doi: 10.1109/TMI.2022.3224085
-
[12]
Lukas Hecker, Rebekka Rupprecht, Ludger Tebartz van Elst, and Jürgen Kornmeier. ConvDip: A convolutional neural network for better EEG source imaging.Frontiers in Neuroscience, 15: 569918, 2021. doi: 10.3389/fnins.2021.569918
-
[13]
Hershey, Jonathan Le Roux, and Felix Weninger
John R. Hershey, Jonathan Le Roux, and Felix Weninger. Deep unfolding: Model-based inspiration of novel deep architectures.arXiv preprint arXiv:1409.2574, 2014. doi: 10.48550/ arXiv.1409.2574
Pith/arXiv arXiv 2014
-
[14]
Bayesian compressive sensing.IEEE Transactions on Signal Processing, 56(6):2346–2356, 2008
Shihao Ji, Ya Xue, and Lawrence Carin. Bayesian compressive sensing.IEEE Transactions on Signal Processing, 56(6):2346–2356, 2008. doi: 10.1109/TSP.2007.914345
-
[15]
Statistical inverse problems: Discretization, model reduction and inverse crimes.Journal of Computational and Applied Mathematics, 198(2):493–504, 2007
Jari Kaipio and Erkki Somersalo. Statistical inverse problems: Discretization, model reduction and inverse crimes.Journal of Computational and Applied Mathematics, 198(2):493–504, 2007
2007
-
[16]
Deeply- supervised nets
Chen-Yu Lee, Saining Xie, Patrick Gallagher, Zhengyou Zhang, and Zhuowen Tu. Deeply- supervised nets. InProceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics, volume 38 ofProceedings of Machine Learning Research, pages 562–570. PMLR, 2015. URLhttps://proceedings.mlr.press/v38/lee15a.html. 10
2015
-
[17]
Jiawen Liang, Zhu Liang Yu, Zhenghui Gu, and Yuanqing Li. Electromagnetic source imaging with a combination of sparse bayesian learning and deep neural network.IEEE Transactions on Neural Systems and Rehabilitation Engineering, 31:2338–2348, 2023. doi: 10.1109/TNSRE. 2023.3251420
-
[18]
Vishal Monga, Yuelong Li, and Yonina C. Eldar. Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing.IEEE Signal Processing Magazine, 38(2):18–44, 2021
2021
-
[19]
Marco Morik, Ali Hashemi, Klaus-Robert Müller, Stefan Haufe, and Shinichi Nakajima. Enhancing brain source reconstruction by initializing 3-d neural networks with physical inverse solutions.IEEE Transactions on Medical Imaging, 45(1):231–242, 2026. doi: 10.1109/TMI.2025.3594724
-
[20]
J. P. Owen, David P. Wipf, Hagai T. Attias, Kensuke Sekihara, and Srikantan S. Nagarajan. Performance evaluation of the Champagne source reconstruction algorithm on simulated and real M/EEG data.NeuroImage, 60(1):305–323, 2012. doi: 10.1016/j.neuroimage.2011.12.027
-
[21]
MEG source localization via deep learning.Sensors, 21 (13):4278, 2021
Dimitrios Pantazis and Amir Adler. MEG source localization via deep learning.Sensors, 21 (13):4278, 2021. doi: 10.3390/s21134278
-
[22]
Pascual-Marqui
Roberto D. Pascual-Marqui. Standardized low-resolution brain electromagnetic tomography (sLORETA): Technical details.Methods and Findings in Experimental and Clinical Pharma- cology, 24(Suppl D):5–12, 2002
2002
-
[23]
Rao, and David P
Rey Ramírez, Jason Palmer, Scott Makeig, Bhaskar D. Rao, and David P. Wipf. Analysis of empirical bayesian methods for neuroelectromagnetic source localiza- tion. InAdvances in Neural Information Processing Systems 19, pages 1505–1512. MIT Press, 2007. URL https://papers.nips.cc/paper_files/paper/2006/hash/ ccd2e3eaa5c991ac880991328c8f1463-Abstract.html
2007
-
[24]
Nagarajan.Electromagnetic Brain Imaging: A Bayesian Perspective
Kensuke Sekihara and Srikantan S. Nagarajan.Electromagnetic Brain Imaging: A Bayesian Perspective. Springer International Publishing, Cham, 2015. doi: 10.1007/978-3-319-14947-9
-
[25]
Rui Sun, Abbas Sohrabpour, Gregory A. Worrell, and Bin He. Deep neural networks constrained by neural mass models improve electrophysiological source imaging of spatiotemporal brain dynamics.Proceedings of the National Academy of Sciences, 119(31):e2201128119, 2022. doi: 10.1073/pnas.2201128119
-
[26]
Michael E. Tipping. Sparse bayesian learning and the relevance vector machine.Journal of Machine Learning Research, 1:211–244, 2001
2001
-
[27]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems 30. Curran Associates, Inc., 2017. URL https: //papers.nips.cc/paper/7181-attention-is-all-you-need
2017
-
[28]
A unified bayesian framework for MEG/EEG source imaging.NeuroImage, 44(3):947–966, 2009
David Wipf and Srikantan Nagarajan. A unified bayesian framework for MEG/EEG source imaging.NeuroImage, 44(3):947–966, 2009. doi: 10.1016/j.neuroimage.2008.02.059
-
[29]
Wipf and Srikantan S
David P. Wipf and Srikantan S. Nagarajan. A new view of automatic relevance determination. InAdvances in Neural Information Processing Systems 20, pages 1625–1632, 2007
2007
-
[30]
David P. Wipf and Bhaskar D. Rao. Sparse bayesian learning for basis selection.IEEE Transactions on Signal Processing, 52(8):2153–2164, 2004. doi: 10.1109/TSP.2004.831016
-
[31]
David P. Wipf, J. P. Owen, Hagai T. Attias, Kensuke Sekihara, and Srikantan S. Nagarajan. Robust bayesian estimation of the location, orientation, and time course of multiple correlated neural sources using MEG.NeuroImage, 49(1):641–655, 2010. doi: 10.1016/j.neuroimage. 2009.06.083
-
[32]
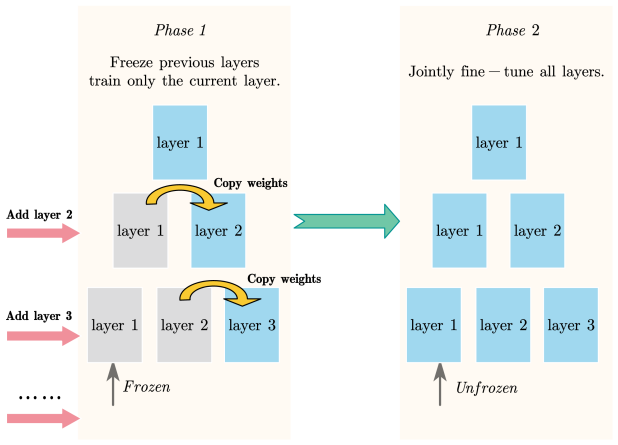
Carsten H. Wolters, Seok Lew, Rob S. MacLeod, and Matti Hämäläinen. Combined EEG/MEG source analysis using calibrated finite element head models.Biomedizinische Technik/Biomedical Engineering, 55(Suppl 1):64–68, 2010. 11 A Additional Architectural and Training Details A.1 Stochastic deep supervision as training regularization To stabilize optimization acr...
arXiv 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.