HKVM-RAG: Key-Value-Separated Hypergraph Evidence Organization for Multi-Hop RAG
Pith reviewed 2026-06-27 20:47 UTC · model grok-4.3
The pith
Key-value-separated hypergraph organization improves multi-hop RAG evidence control over pairwise graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
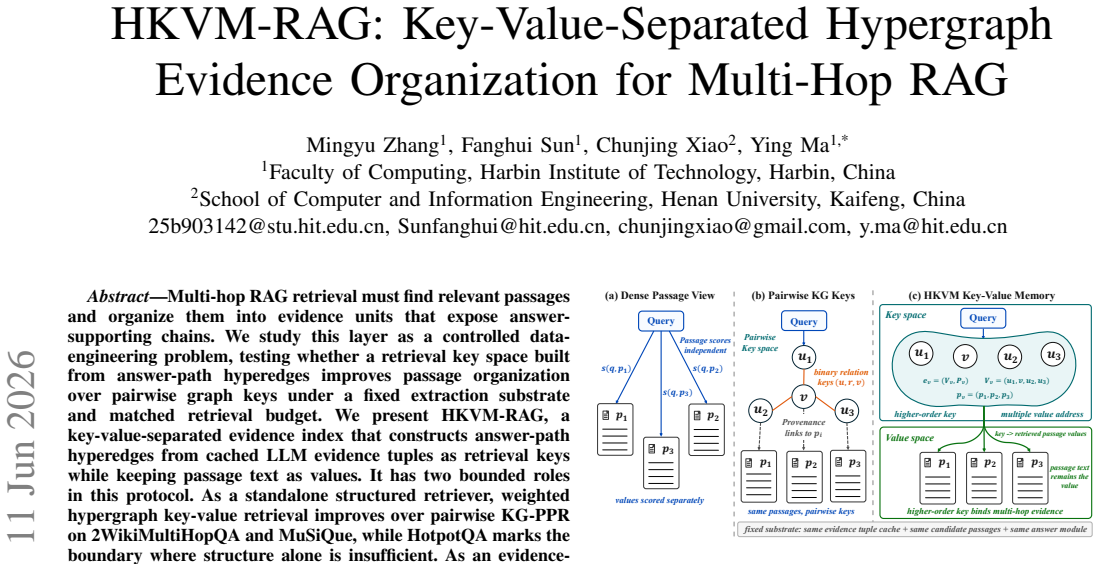
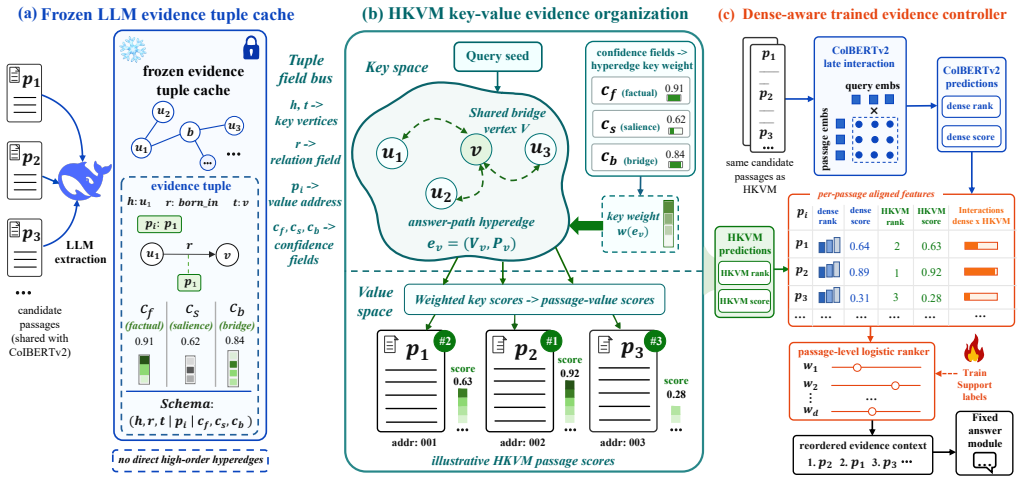
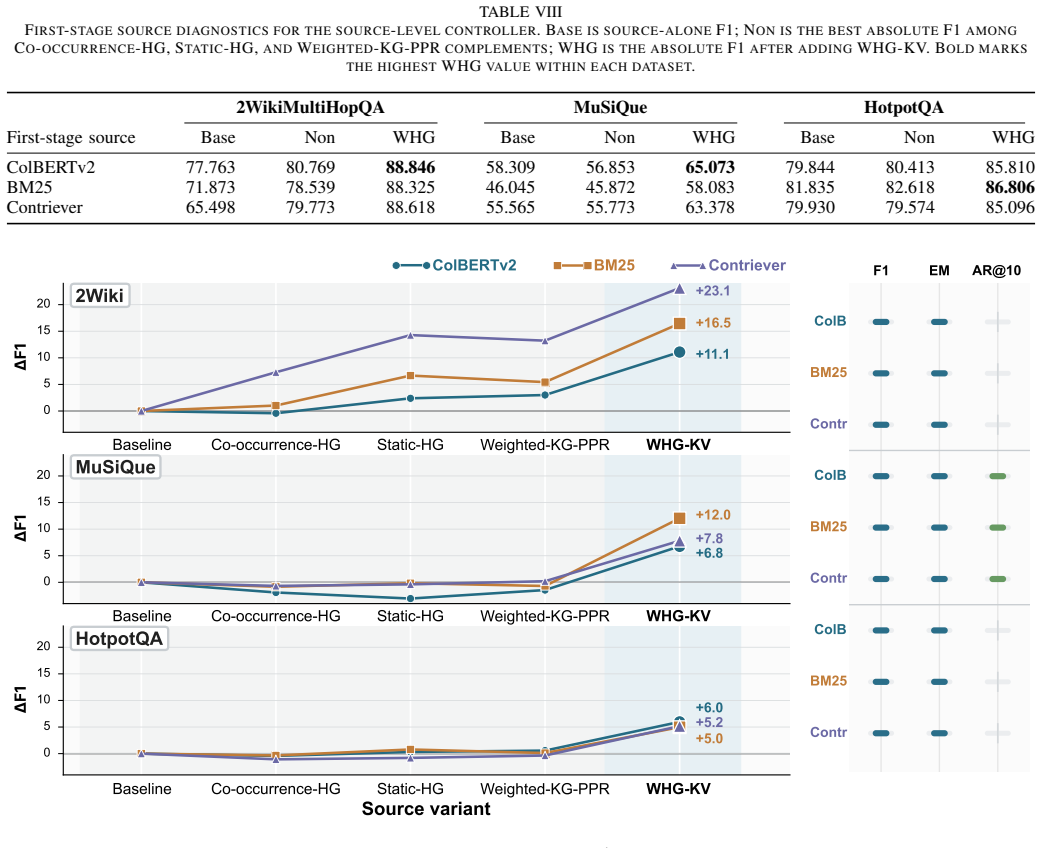
HKVM-RAG assembles answer-path hyperedges from cached passage-level LLM evidence tuples to serve as retrieval keys while retaining passage text as answer values; weighted hypergraph key-value retrieval improves over KG-PPR by +3.426 F1 on 2WikiMultiHopQA and +3.592 F1 on MuSiQue, and a dense-aware controller combining it with ColBERTv2 reaches 88.846, 65.073, and 85.810 F1 on the three benchmarks.
What carries the argument
Key-value-separated hypergraph evidence-organization layer that assembles answer-path hyperedges from evidence tuples as retrieval keys and passage text as values.
If this is right
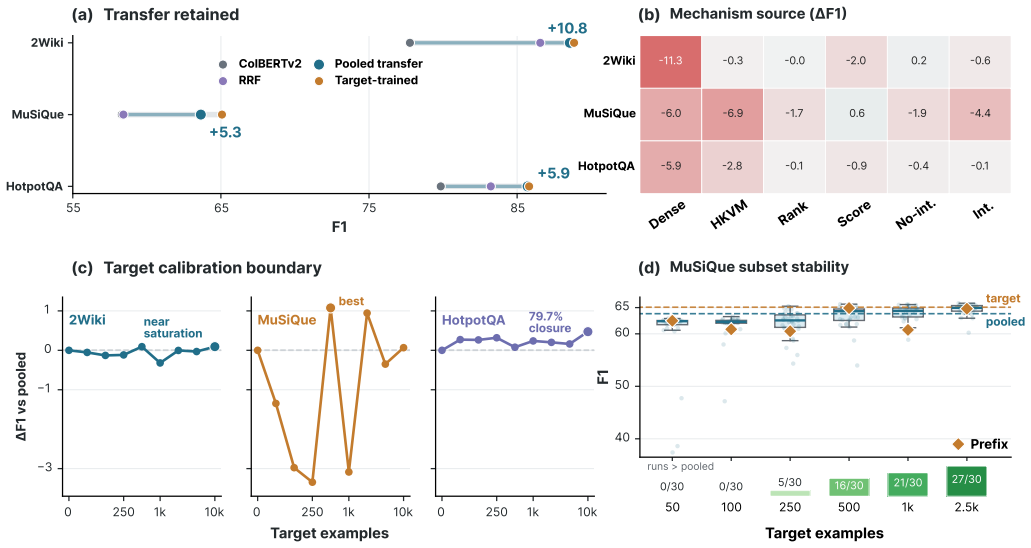
- Weighted hypergraph key-value retrieval functions as a reusable evidence-control signal rather than a standalone dense-retrieval replacement.
- Oracle and train-to-dev analyses show support selection remains repairable and can further raise answer F1.
- Source-level ablations demonstrate that matched non-hypergraph structured signals fail to match the observed gains.
- On HotpotQA, higher structured support coverage does not automatically translate into standalone answer-F1 improvements.
Where Pith is reading between the lines
- The separation of hyperedge keys from passage values may generalize to other evidence-chaining tasks where retrieval budgets are constrained.
- Combining the hypergraph signal with additional frozen retrievers could be tested by varying only the controller features.
- If the evidence tuples are generated by different LLMs, the resulting hypergraph keys could be compared for robustness across generators.
Load-bearing premise
The fixed-substrate protocol holds the tuple cache, candidate passages, reader, and evaluation budget constant so that performance differences can be attributed to key-space design.
What would settle it
No measurable F1 improvement from the weighted hypergraph variant relative to the pairwise graph variant when the tuple cache, candidate passages, reader, and evaluation budget remain identical.
Figures
read the original abstract
Multi-hop RAG poses a data-engineering problem beyond passage matching: under fixed retrieval budgets, a system must organize retrieved text into evidence units that expose answer chains. Dense retrievers score passages independently, while graph-based memories make associations explicit but often rely on pairwise or entity-centered keys that fragment multi-hop evidence. We present HKVM-RAG, a key-value-separated evidence-organization layer. It assembles answer-path hyperedges from cached passage-level LLM evidence tuples and uses them as retrieval keys, while retaining passage text as answer values. To isolate key-space design, our fixed-substrate protocol holds the tuple cache, candidate passages, reader, and evaluation budget constant across pairwise graph and hypergraph variants. Weighted hypergraph key-value retrieval improves over KG-PPR by +3.426 F1 on 2WikiMultiHopQA and +3.592 F1 on MuSiQue; HotpotQA shows that higher structured support coverage need not yield standalone answer-F1 gains. We therefore study WHG-KV as an evidence-control signal rather than a dense-retrieval replacement. Oracle and train-to-dev analyses identify support selection as repairable, and a dense-aware controller combines frozen ColBERTv2 and HKVM rank/score features using out-of-fold HKVM predictions. It reaches 88.846, 65.073, and 85.810 F1 on the three benchmarks, improving over ColBERTv2 by +11.084, +6.763, and +5.966 F1. Source-level ablations show that matched non-WHG structured signals do not match the WHG-KV gains. These results provide bounded evidence that key-value-separated hypergraph organization can serve as a reusable evidence-control mechanism for multi-hop RAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents HKVM-RAG, a key-value-separated hypergraph evidence organization layer for multi-hop RAG. It assembles answer-path hyperedges from cached passage-level LLM evidence tuples as retrieval keys while keeping passage text as values. Under a fixed-substrate protocol holding tuple cache, candidate passages, reader, and budget constant, it reports F1 improvements of +3.426 on 2WikiMultiHopQA and +3.592 on MuSiQue over KG-PPR. A dense-aware controller combining ColBERTv2 and HKVM features achieves 88.846, 65.073, and 85.810 F1 on the three benchmarks, with ablations showing structured signals contribute to gains.
Significance. If the empirical comparisons hold under the claimed isolation, the work demonstrates that hypergraph-based key-value organization can provide a reusable evidence-control mechanism beyond standard dense or pairwise graph retrieval in multi-hop settings. The controller results and source-level ablations offer concrete evidence of utility, and the fixed-substrate design is a strength for controlled comparison.
major comments (2)
- [Abstract] Abstract: The fixed-substrate protocol is presented as isolating key-space design, but the hypergraph assembly ('assembles answer-path hyperedges from cached passage-level LLM evidence tuples') and 'weighted hypergraph key-value retrieval' introduce multi-way path aggregation and non-pairwise matching with no direct counterpart in the KG-PPR pairwise variant. This raises the possibility that the reported +3.426 and +3.592 F1 gains arise from algorithmic differences rather than the hypergraph structure itself.
- [Abstract] Abstract: No error bars, dataset statistics, or full experimental protocol details are provided despite reporting concrete F1 deltas and controller results, limiting assessment of statistical significance and reproducibility of the gains.
minor comments (2)
- The manuscript would benefit from explicit definition of the hypergraph construction process in a dedicated methods section for clarity.
- Consider adding references to prior work on hypergraph retrieval in IR to contextualize the contribution.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments. We address each major comment below with point-by-point responses.
read point-by-point responses
-
Referee: [Abstract] Abstract: The fixed-substrate protocol is presented as isolating key-space design, but the hypergraph assembly ('assembles answer-path hyperedges from cached passage-level LLM evidence tuples') and 'weighted hypergraph key-value retrieval' introduce multi-way path aggregation and non-pairwise matching with no direct counterpart in the KG-PPR pairwise variant. This raises the possibility that the reported +3.426 and +3.592 F1 gains arise from algorithmic differences rather than the hypergraph structure itself.
Authors: The fixed-substrate protocol explicitly holds the LLM evidence tuple cache, candidate passages, reader, and budget fixed while varying only the key-space organization and retrieval operator. KG-PPR implements the pairwise-graph counterpart over the identical tuples (entity-centered edges), whereas HKVM-RAG uses hyperedges to encode answer-paths; the multi-way aggregation is therefore the direct consequence of adopting a hypergraph key space rather than an extraneous algorithmic change. We will revise the abstract and methods to state this equivalence of substrate more explicitly. revision: partial
-
Referee: [Abstract] Abstract: No error bars, dataset statistics, or full experimental protocol details are provided despite reporting concrete F1 deltas and controller results, limiting assessment of statistical significance and reproducibility of the gains.
Authors: We agree that the current manuscript lacks error bars, dataset statistics, and expanded protocol details. In the revision we will add (i) standard deviations from repeated runs, (ii) basic dataset statistics (question counts, hop distributions), and (iii) a consolidated experimental-protocol subsection describing the fixed-substrate controls and evaluation budget. revision: yes
Circularity Check
No circularity: empirical comparisons under fixed-substrate protocol
full rationale
The paper presents HKVM-RAG as an evidence-organization layer for multi-hop RAG and reports benchmark F1 deltas (+3.426 on 2WikiMultiHopQA, etc.) from a fixed-substrate protocol that holds tuple cache, passages, reader, and budget constant across pairwise-graph and hypergraph variants. No mathematical derivation chain, equations, or first-principles results are claimed or visible. Central results are direct empirical measurements; the 'out-of-fold HKVM predictions' phrase refers to cross-validation usage for a downstream controller, not a self-referential fit. No self-citations, ansatzes, or renamings reduce any claim to its own inputs by construction. The skeptic concern about whether the protocol fully isolates key-space design is an experimental-validity issue, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewiset al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 9459–9474
2020
-
[2]
Retrieval augmented language model pre-training,
K. Guu, K. Lee, Z. Tung, P. Pasupat, and M.-W. Chang, “Retrieval augmented language model pre-training,” inProceedings of the 37th International Conference on Machine Learning, PMLR, vol. 119, 2020, pp. 3929–3938
2020
-
[3]
G. Izacard and E. Grave, “Leveraging passage retrieval with gener- ative models for open domain question answering,” inProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, 2021, pp. 874–880, doi: 10.18653/v1/2021.eacl-main.74
-
[4]
HippoRAG: Neurobiologically inspired long-term memory for large language mod- els,
B. J. Gutierrez, Y . Shu, Y . Gu, M. Yasunaga, and Y . Su, “HippoRAG: Neurobiologically inspired long-term memory for large language mod- els,” inAdvances in Neural Information Processing Systems, vol. 37, 2024
2024
-
[5]
From RAG to mem- ory: Non-parametric continual learning for large language models,
B. J. Gutierrez, Y . Shu, W. Qi, S. Zhou, and Y . Su, “From RAG to mem- ory: Non-parametric continual learning for large language models,” in Proceedings of the 42nd International Conference on Machine Learning, PMLR, vol. 267, pp. 21497–21515, 2025
2025
-
[6]
EcphoryRAG: Re-imagining knowledge-graph RAG via hu- man associative memory,
Z. Liao, “EcphoryRAG: Re-imagining knowledge-graph RAG via hu- man associative memory,” arXiv:2510.08958, 2025
arXiv 2025
-
[7]
H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering
Z. Yang, P. Qi, S. Zhang, Y . Bengio, W. W. Cohen, R. Salakhutdinov, and C. D. Manning, “HotpotQA: A dataset for diverse, explainable multi- hop question answering,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018, pp. 2369– 2380, doi: 10.18653/v1/D18-1259
-
[8]
Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps,
X. Ho, A.-K. D. Nguyen, S. Sugawara, and A. Aizawa, “Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps,” inProceedings of the 28th International Conference on Computa- tional Linguistics, 2020, pp. 6609–6625, doi: 10.18653/v1/2020.coling- main.580
-
[9]
URL https: //aclanthology.org/2022.tacl-1.66/
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal, “MuSiQue: Multihop questions via single-hop question composition,”Transactions of the Association for Computational Linguistics, vol. 10, pp. 539–554, 2022, doi: 10.1162/tacl a 00475
work page internal anchor Pith review doi:10.1162/tacl 2022
-
[10]
S. E. Robertson, S. Walker, S. Jones, M. Hancock-Beaulieu, and M. Gatford, “Okapi at TREC-3,” inProceedings of The Third Text REtrieval Conference (TREC 1994), D. K. Harman, Ed., NIST Special Publication 500-225. Gaithersburg, MD, USA: National Institute of Standards and Technology, 1994, pp. 109–126, doi: 10.6028/NIST.SP.500-225.routing- city
-
[11]
Dense Passage Retrieval for Open-Domain Question Answering
V . Karpukhinet al., “Dense passage retrieval for open-domain ques- tion answering,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, 2020, pp. 6769–6781, doi: 10.18653/v1/2020.emnlp-main.550
-
[12]
Unsupervised dense information retrieval with contrastive learning,
G. Izacard, M. Caron, L. Hosseini, S. Riedel, P. Bojanowski, A. Joulin, and E. Grave, “Unsupervised dense information retrieval with contrastive learning,”Transactions on Machine Learning Research, 2022. [Online]. Available: https://openreview.net/forum?id=jKN1pXi7b0
2022
-
[13]
ColBERTv2: Effective and efficient retrieval via lightweight late inter- action,
K. Santhanam, O. Khattab, J. Saad-Falcon, C. Potts, and M. Zaharia, “ColBERTv2: Effective and efficient retrieval via lightweight late inter- action,” inProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Seattle, United States: Association for Compu- tational Ling...
-
[14]
From local to global: A graph RAG approach to query-focused summarization,
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, D. Metropolitansky, R. O. Ness, and J. Larson, “From local to global: A graph RAG approach to query-focused summarization,” arXiv:2404.16130, 2024
Pith/arXiv arXiv 2024
-
[15]
Think-on-Graph: Deep and responsible reasoning of large language model on knowledge graph,
J. Sunet al., “Think-on-Graph: Deep and responsible reasoning of large language model on knowledge graph,” inInternational Conference on Learning Representations, 2024
2024
-
[16]
Y . Feng, H. You, Z. Zhang, R. Ji, and Y . Gao, “Hypergraph neural networks,” inProceedings of the AAAI Conference on Ar- tificial Intelligence, vol. 33, no. 01, pp. 3558–3565, 2019, doi: 10.1609/aaai.v33i01.33013558
-
[17]
HyperGCN: A new method for training graph convolutional networks on hypergraphs,
N. Yadati, M. Nimishakavi, P. Yadav, V . Nitin, A. Louis, and P. Talukdar, “HyperGCN: A new method for training graph convolutional networks on hypergraphs,” inAdvances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[18]
You are AllSet: A multiset function framework for hypergraph neural networks,
E. Chien, C. Pan, J. Peng, and O. Milenkovic, “You are AllSet: A multiset function framework for hypergraph neural networks,” in International Conference on Learning Representations, 2022
2022
-
[19]
A survey on hypergraph representation learning,
A. Antelmi, G. Cordasco, M. Polato, V . Scarano, C. Spagnuolo, and D. Yang, “A survey on hypergraph representation learning,”ACM Computing Surveys, vol. 56, no. 1, article 10, pp. 1–38, 2023, doi: 10.1145/3605776
-
[20]
Hyper-RAG: Combating LLM hallucina- tions using hypergraph-driven retrieval-augmented generation,
Y . Feng, H. Hu, S. Ying, X. Hou, S. Liu, M. Yang, J. Li, S. Du, N. Zheng, H. Hu, and Y . Gao, “Hyper-RAG: Combating LLM hallucina- tions using hypergraph-driven retrieval-augmented generation,”Nature Communications, 2026, doi: 10.1038/s41467-026-71411-1
-
[21]
C. Zhou, C. Zhang, G. Yu, F. Meng, J. Zhou, W. Lam, and M. Yu, “HG- MEM: Hypergraph-based Working Memory to Improve Multi-step RAG for Long-Context Complex Relational Modeling,” arXiv:2512.23959, 2025, rev. 2026, doi: 10.48550/arXiv.2512.23959
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.23959 2025
-
[22]
Answering complex open-domain questions with multi-hop dense retrieval,
W. Xionget al., “Answering complex open-domain questions with multi-hop dense retrieval,” inInternational Conference on Learning Representations, 2021
2021
-
[23]
Baleen: Robust multi-hop reasoning at scale via condensed retrieval,
O. Khattab, C. Potts, and M. Zaharia, “Baleen: Robust multi-hop reasoning at scale via condensed retrieval,” inAdvances in Neural Information Processing Systems, vol. 34, 2021, pp. 27670–27682
2021
-
[24]
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal, “Interleav- ing retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 2023, pp. 10014–10037, doi: 10.18653/v1/2023.acl-long.557
-
[25]
End-to-end memory networks,
S. Sukhbaatar, A. Szlam, J. Weston, and R. Fergus, “End-to-end memory networks,” inAdvances in Neural Information Processing Systems, vol. 28, 2015
2015
-
[26]
Key-value memory networks for directly reading documents,
A. Miller, A. Fisch, J. Dodge, A.-H. Karimi, A. Bordes, and J. We- ston, “Key-value memory networks for directly reading documents,” in Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, 2016, pp. 1400–1409, doi: 10.18653/v1/D16- 1147
-
[27]
Hopfield Networks is All You Need,
H. Ramsauer, B. Sch ¨afl, J. Lehner, P. Seidl, M. Widrich, T. Adler, L. Gruber, M. Holzleitner, M. Pavlovi ´c, G. K. Sandve, V . Greiff, D. Kreil, M. Kopp, G. Klambauer, J. Brandstetter, and S. Hochreiter, “Hopfield Networks is All You Need,” inInternational Conference on Learning Representations, 2021. [Online]. Available: https://openreview. net/forum?i...
2021
-
[28]
Key-value memory in the brain,
S. J. Gershman, I. Fiete, and K. Irie, “Key-value memory in the brain,”Neuron, vol. 113, no. 11, pp. 1694–1707.e1, 2025, doi: 10.1016/j.neuron.2025.02.029
-
[29]
To- wards retrieval-augmented large language models: Data management and system design,
W. Fan, P. Wu, Y . Ding, L. Ning, S. Wang, and Q. Li, “To- wards retrieval-augmented large language models: Data management and system design,” inProceedings of the 41st IEEE Interna- tional Conference on Data Engineering, 2025, pp. 4509–4512, doi: 10.1109/ICDE65448.2025.00341
-
[30]
Retrieval- augmented generation (RAG): What is there for data management researchers?
A. Khan, Y . Luo, W. Zhang, M. Zhou, and X. Zhou, “Retrieval- augmented generation (RAG): What is there for data management researchers?”SIGMOD Record, vol. 54, no. 4, pp. 33–42, 2025, doi: 10.1145/3793217.3793229
-
[31]
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom
Y . A. Malkov and D. A. Yashunin, “Efficient and robust ap- proximate nearest neighbor search using hierarchical navigable small world graphs,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 42, no. 4, pp. 824–836, 2020, doi: 10.1109/TPAMI.2018.2889473
-
[32]
Billion-scalesimilaritysearchwithgpus
J. Johnson, M. Douze, and H. J ´egou, “Billion-scale similarity search with GPUs,”IEEE Transactions on Big Data, vol. 7, no. 3, pp. 535– 547, 2021, doi: 10.1109/TBDATA.2019.2921572
-
[33]
Accelerating large-scale inference with anisotropic vector quantization,
R. Guo, P. Sun, E. Lindgren, Q. Geng, D. Simcha, F. Chern, and S. Kumar, “Accelerating large-scale inference with anisotropic vector quantization,” inProceedings of the 37th International Conference on Machine Learning, PMLR, vol. 119, 2020, pp. 3887–3896. [Online]. Available: https://proceedings.mlr.press/v119/guo20h.html
2020
-
[34]
Sax, John Roesler, Sophie Blee-Goldman, Bruno Cadonna, Apurva Mehta, Varun Madan, and Jun Rao
J. Wang, X. Yi, R. Guo,et al., “Milvus: A purpose-built vector data management system,” inProceedings of the 2021 International Conference on Management of Data, 2021, pp. 2614–2627, doi: 10.1145/3448016.3457550
-
[35]
A. Khan, “Knowledge graphs querying,”SIGMOD Record, vol. 52, no. 2, pp. 18–29, 2023, doi: 10.1145/3615952.3615956
-
[36]
The LDBC social network benchmark: Interactive workload,
O. Erling, A. Averbuch, J. Larriba-Pey, H. Chafi, A. Gubichev, A. Prat-P´erez, M.-D. Pham, and P. A. Boncz, “The LDBC social network benchmark: Interactive workload,” inProceedings of the 2015 ACM SIGMOD International Conference on Management of Data, 2015, pp. 619–630, doi: 10.1145/2723372.2742786
-
[37]
Artifacts availability & reproducibility: VLDB 2021 round table,
M. Athanassoulis, P. Triantafillou, R. Appuswamy,et al., “Artifacts availability & reproducibility: VLDB 2021 round table,”SIGMOD Record, vol. 51, no. 2, pp. 74–77, 2022, doi: 10.1145/3552490.3552511
-
[38]
A survey on provenance: What for? What form? What from?
M. Herschel, R. Diestelk ¨amper, and H. Ben Lahmar, “A survey on provenance: What for? What form? What from?”The VLDB Journal, vol. 26, no. 6, pp. 881–906, 2017, doi: 10.1007/s00778-017-0486-1
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.