Assessing True Generalisability of Audio-Visual Speech Recognisers
Pith reviewed 2026-06-27 21:02 UTC · model grok-4.3
The pith
Audio-visual speech recognition models that reach near-perfect LRS3 scores suffer sharp accuracy drops on a new test set that exactly matches LRS3 distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By constructing a controlled, unseen evaluation set subsampled from MultiVSR that strictly matches the acoustic, visual, and demographic distributions of the LRS3 test set, the authors show that five state-of-the-art AVSR architectures undergo a universal performance collapse. This establishes that current systems fail to generalise even under strictly aligned conditions. Fine-grained attribute analysis across seven factors isolates the drivers of degradation, while further examination uncovers a profound lexical bias, distinct error patterns, and cases where audio-visual performance lags behind audio-only settings.
What carries the argument
The distribution-matched unseen evaluation set subsampled from MultiVSR, which isolates generalisability failure from any distribution shift.
If this is right
- Standard LRS3-style benchmarks are insufficient to certify generalisability of AVSR models.
- Lexical bias must be mitigated during training to reduce the observed degradation.
- Current audio-visual fusion can degrade accuracy relative to audio alone under matched conditions.
- The released matched test set supplies a stricter benchmark for future AVSR development.
- Performance collapse occurs even when acoustic, visual, and demographic factors are controlled.
Where Pith is reading between the lines
- Models may be relying on dataset-specific artifacts instead of learning robust multimodal speech patterns.
- Similar distribution-matched subsets could be built from other large corpora to test for hidden overfitting in related tasks.
- The audio-visual performance lag points to potential weaknesses in how visual features are integrated when conditions are tightly controlled.
Load-bearing premise
The subsampled evaluation set from MultiVSR strictly matches the acoustic, visual, and demographic distributions of the LRS3 test set.
What would settle it
Showing that the five architectures maintain near-LRS3 performance levels on the matched set, or that any measured drop stems from residual mismatches in the subsampling process, would falsify the universal collapse claim.
Figures

read the original abstract
Current Audio-Visual Speech Recognition (AVSR) models achieve near-perfect performance on the standard LRS3 benchmark, raising concerns of adaptive overfitting. To systematically assess true generalisability, we construct a highly controlled, unseen evaluation set subsampled from the massive MultiVSR dataset. Unlike standard out-of-distribution benchmarks, our subset strictly matches the acoustic, visual, and demographic distributions of the LRS3 test set. Evaluating five state-of-the-art architectures reveals a universal performance collapse, proving that current systems fail to generalise even under strictly aligned conditions. Through a fine-grained attribute analysis across seven factors, we isolate the specific drivers of this degradation. Furthermore, we uncover a profound lexical bias, expose distinct error patterns, and surprisingly reveal that audio-visual performance even lags behind audio-only settings. We release our matched test set for future benchmarking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that current AVSR models overfit to the LRS3 benchmark. To test true generalisability, the authors subsample a test set from MultiVSR that strictly matches LRS3 in acoustic, visual, and demographic distributions. Evaluation of five state-of-the-art architectures on this set shows a universal performance collapse, which they take as proof of generalisation failure even under matched conditions. Additional contributions include a seven-factor attribute analysis of degradation drivers, identification of lexical bias and distinct error patterns, the observation that AV performance can lag audio-only, and release of the matched test set.
Significance. If the distribution matching is shown to be rigorous and the performance drops are supported by quantitative results and statistical tests, the work would be significant for highlighting potential overfitting in AVSR and supplying a new controlled benchmark. The dataset release would further increase its value for the community.
major comments (1)
- [§3 (Dataset Construction)] §3 (Dataset Construction): The central claim that current systems 'fail to generalise even under strictly aligned conditions' rests on the MultiVSR subsample having identical acoustic, visual, and demographic distributions to the LRS3 test set. The manuscript asserts that the subset 'strictly matches' these distributions but supplies no description of the matching procedure, the embeddings or feature space used, tolerance thresholds, or any verification (e.g., KL divergence, moment matching, or statistical tests). Without this, residual un-matched shifts remain a plausible alternative explanation for the observed collapse.
minor comments (1)
- [Abstract] Abstract: The abstract states that the work 'uncover[s] a profound lexical bias' and 'expose[s] distinct error patterns' but provides no quantitative measures or examples, reducing the ability to assess these claims at a glance.
Simulated Author's Rebuttal
We thank the referee for their detailed review and for highlighting the need for greater transparency in our dataset construction. We address the single major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: §3 (Dataset Construction): The central claim that current systems 'fail to generalise even under strictly aligned conditions' rests on the MultiVSR subsample having identical acoustic, visual, and demographic distributions to the LRS3 test set. The manuscript asserts that the subset 'strictly matches' these distributions but supplies no description of the matching procedure, the embeddings or feature space used, tolerance thresholds, or any verification (e.g., KL divergence, moment matching, or statistical tests). Without this, residual un-matched shifts remain a plausible alternative explanation for the observed collapse.
Authors: We agree that the current manuscript lacks sufficient detail on the distribution-matching procedure, which is necessary to substantiate the claim of strict alignment. In the revised version we will expand §3 with: (i) the exact feature extractors (Wav2Vec 2.0 for audio, ArcFace for visual, and a demographic classifier for age/gender/ethnicity), (ii) the matching algorithm (iterative nearest-neighbour sampling in the joint embedding space with explicit tolerance thresholds on each modality), and (iii) quantitative verification (KL divergence, Wasserstein distance, and two-sample Kolmogorov-Smirnov tests on all marginals, plus a demographic balance table). These additions will allow readers to evaluate residual shift directly. revision: yes
Circularity Check
No circularity in empirical benchmark study
full rationale
This paper is a purely empirical evaluation: it subsamples MultiVSR to create a test set claimed to match LRS3 distributions, then reports performance drops on five AVSR models. No derivation chain, equations, fitted parameters renamed as predictions, or self-citations that bear the central claim exist. The distribution-matching step is an assumption whose verification details are absent, but that is a methodological gap, not a reduction of any result to its own inputs by construction. The study is self-contained against external benchmarks and receives the default non-circular finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- Distribution matching criteria
axioms (1)
- domain assumption The MultiVSR dataset contains sufficient samples to allow strict matching of distributions across acoustic, visual, and demographic factors.
Reference graph
Works this paper leans on
-
[1]
Introduction For decades, Audio-Visual Speech Recognition (A VSR) re- search has sought to enhance conventional audio-only speech recognition by exploiting visual cues from the speaker’s lip movements [1, 2]. In recent years, the A VSR field has expe- rienced a rapid architectural evolution, advancing from super- vised end-to-end networks [3, 4, 5] and se...
-
[2]
Constructing a Matched Test Set Prior efforts in the broader computer vision field [11] and VSR
-
[3]
Assessing True Generalisability of Audio-Visual Speech Recognisers
provide valuable inspiration for assessing the true gener- alisation of machine learning models. However, these founda- tional studies mainly analyse distribution shifts and the result- ing performance degradation from a broad, statistical machine learning perspective. In the highly complex domain of audio- visual speech, a purely statistical approach is ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Evaluated Models We select five state-of-the-art models representing the rapid ar- chitectural evolution of A VSR over recent years. These encom- 2https://github.com/yakhyo/uniface 0 2 4 6 0.0 0.2 0.4Density Duration (s) 20 40 60 80 0.00 0.01 0.02 0.03Density Speaker age 0 50 100 0.00 0.01 0.02 0.03Density Audio SNR (dB) 0.0 2.5 5.0 7.5 0.0 0.2 0.4Density...
-
[5]
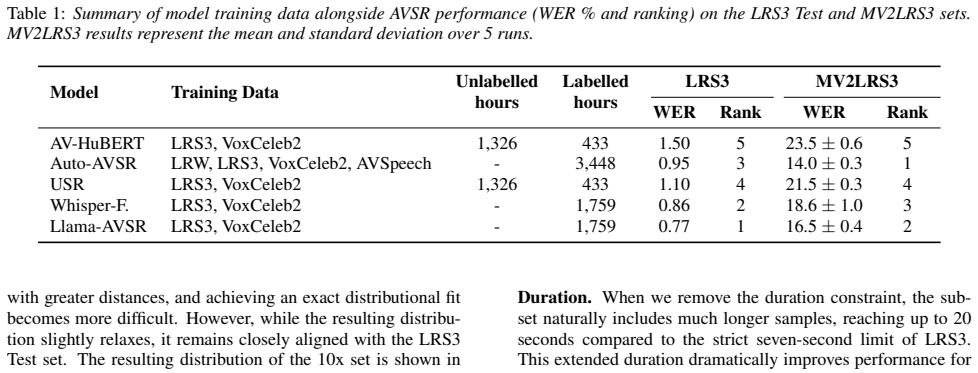
Table 1 details their performance and relative rankings on both LRS3 benchmark and our MV2LRS3 set
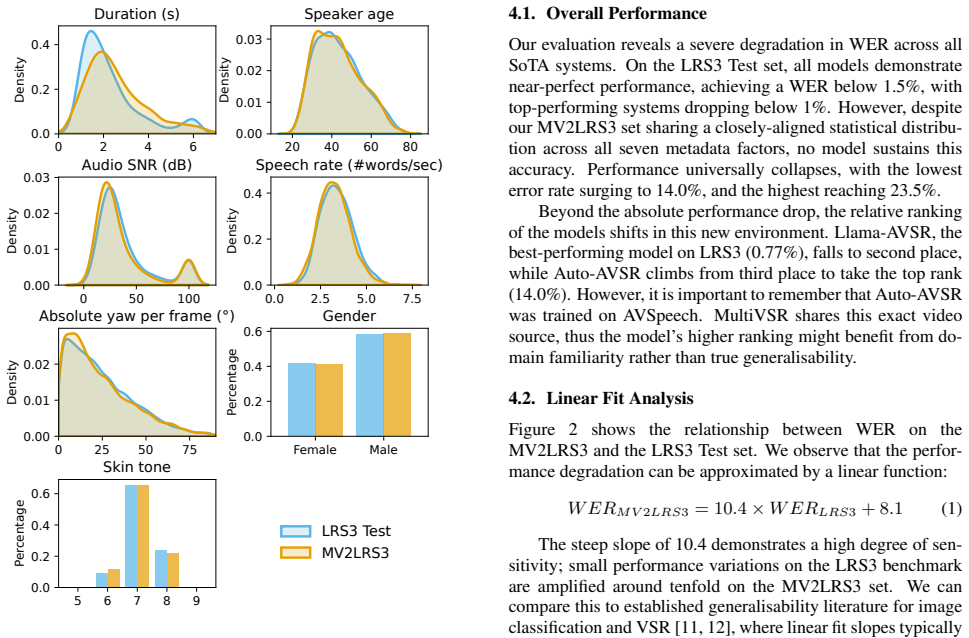
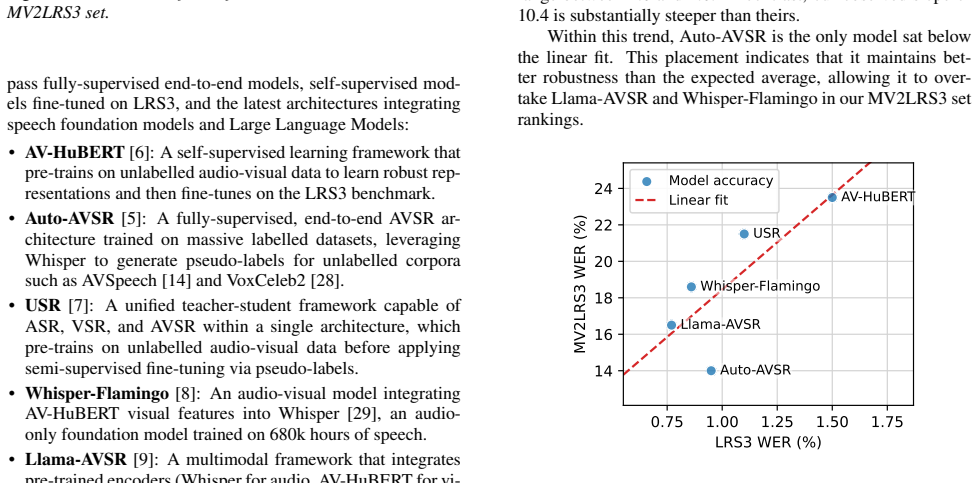
MV2LRS3 Set Evaluation Having constructed a subset strictly matched to the LRS3 distri- bution across all seven factors, we evaluate the WER of the five chosen models. Table 1 details their performance and relative rankings on both LRS3 benchmark and our MV2LRS3 set. 4.1. Overall Performance Our evaluation reveals a severe degradation in WER across all So...
-
[6]
We observe that the fundamental degradation in performance persists across all models. While the absolute magnitude of this drop is slightly smaller on the 10x set, the performance ranking of the models on the 10x set is still identical to the ranking ob- served on the MV2LRS3 set. This consistent ranking across a substantially larger test set confirms th...
-
[7]
Leave-one-out Attribute Analysis During the construction of our controlled MV2LRS3 set, we identified 7 distinct attributes with the potential to influence A VSR performance
Isolating the Impact of Each Factor 5.1. Leave-one-out Attribute Analysis During the construction of our controlled MV2LRS3 set, we identified 7 distinct attributes with the potential to influence A VSR performance. Guided by established research concern- ing demographic and acoustic bias in the ASR field [17, 16], we hypothesise that specific factors may...
-
[8]
Eval- uating this is complex because the SoTA models rely on vastly different training corpora
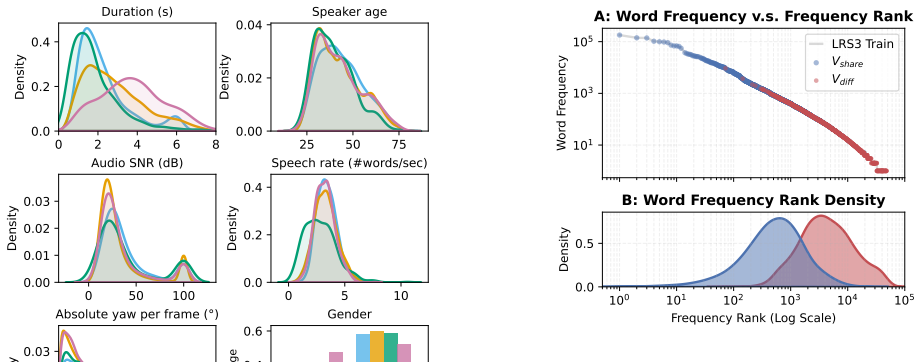
Impact of the Vocabulary V ocabulary divergence is a critical factor influencing A VSR per- formance, and it is important to isolate its specific impact. Eval- uating this is complex because the SoTA models rely on vastly different training corpora. While some are fine-tuned exclu- sively on LRS3, others incorporate pseudo-labels from datasets like A VSpe...
-
[9]
Therefore, we do not treatV diff as out-of-vocabulary
or massive external pre-training datasets. Therefore, we do not treatV diff as out-of-vocabulary. However, the words inV diff are rarer than words inV share within the LRS3 training vocabu- lary, potentially making them harder for the recognition. Also, it serves as a critical measure of out-of-benchmark vocabulary: words that fall outside the highly expe...
-
[10]
We evaluated the models on the MV2LRS3 set using Audio-Visual (A V), Audio-Only (AO), and Video- Only (VO) inputs
Dive into the Modalities To understand how these architectures process distinct streams of information, we tested their performance across different modality settings. We evaluated the models on the MV2LRS3 set using Audio-Visual (A V), Audio-Only (AO), and Video- Only (VO) inputs. Table 6 reveals an unexpected trend: for several top-tier foundation model...
-
[11]
As shown in Table 7, the error profiles on the LRS3 Test set are extremely low and well-balanced across all three categories
Dive into the Errors We here dive deep into the specific error: Substitutions (Sub), Deletions (Del), and Insertions (Ins) errors. As shown in Table 7, the error profiles on the LRS3 Test set are extremely low and well-balanced across all three categories. However, the tran- sition to the MV2LRS3 set reveals completely different error behaviours among the...
-
[12]
Does A VSR generalise beyond LRS3? The primary focus of this paper is the generalisation capabil- ity of current A VSR systems beyond the LRS3 benchmark
Discussion 9.1. Does A VSR generalise beyond LRS3? The primary focus of this paper is the generalisation capabil- ity of current A VSR systems beyond the LRS3 benchmark. Our empirical results reveal that performance on the controlled MV2LRS3 set universally collapses across all models, exposing a massive gap compared to the LRS3 Test set. Consequently, cu...
-
[13]
To achieve this, we constructed the MV2LRS3 set: a controlled LRS3-like test set that strictly aligns with the demographic, acoustic and visual distributions of the LRS3 Test set
Conclusion This paper systematically assesses the true generalisability of state-of-the-art A VSR systems beyond the standard LRS3 benchmark. To achieve this, we constructed the MV2LRS3 set: a controlled LRS3-like test set that strictly aligns with the demographic, acoustic and visual distributions of the LRS3 Test set. By evaluating five leading A VSR sy...
-
[14]
Ethical Disclaimer Demographic metadata for this dataset was generated via auto- mated extraction tools and represents algorithmic inference, not self-reported identity. We acknowledge the limitations of these off-the-shelf models, including potential algorithmic bias, un- even accuracy across demographics, and the reduction of com- plex traits into rigid...
-
[15]
Generative AI Use Disclosure Generative AI tools were used to improve the paper’s grammar and clarity, as well as to assist in writing the code for the plots
-
[16]
18/CRT/6224
Acknowledgements This work was conducted with the financial support of the Research Ireland Centre for Research Training in Digitally- Enhanced Reality (d-real) under Grant No. 18/CRT/6224
-
[17]
Re- cent advances in the automatic recognition of audiovisual speech,
G. Potamianos, C. Neti, G. Gravier, A. Garg, and A. Senior, “Re- cent advances in the automatic recognition of audiovisual speech,” Proceedings of the IEEE, vol. 91, no. 9, pp. 1306–1326, 2003
2003
-
[18]
Deep audio-visual speech recognition,
T. Afouras, J. S. Chung, A. Senior, O. Vinyals, and A. Zisser- man, “Deep audio-visual speech recognition,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 12, pp. 8717–8727, 2022
2022
-
[19]
Attention-based audio-visual fusion for robust automatic speech recognition,
G. Sterpu, C. Saam, and N. Harte, “Attention-based audio-visual fusion for robust automatic speech recognition,” inProceedings of the 20th ACM International conference on Multimodal Interac- tion, 2018, pp. 111–115
2018
-
[20]
End-to-end audiovisual speech recognition,
S. Petridis, T. Stafylakis, P. Ma, F. Cai, G. Tzimiropoulos, and M. Pantic, “End-to-end audiovisual speech recognition,” in2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 6548–6552
2018
-
[21]
Auto-avsr: Audio-visual speech recognition with automatic labels,
P. Ma, A. Haliassos, A. Fernandez-Lopez, H. Chen, S. Petridis, and M. Pantic, “Auto-avsr: Audio-visual speech recognition with automatic labels,” inICASSP 2023-2023 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[22]
Learning audio-visual speech representation by masked multimodal cluster prediction,
B. Shi, W.-N. Hsu, K. Lakhotia, and A. Mohamed, “Learning audio-visual speech representation by masked multimodal cluster prediction,” inInternational Conference on Learning Representa- tions, 2022
2022
-
[23]
Unified speech recognition: A single model for au- ditory, visual, and audiovisual inputs,
A. Haliassos, R. Mira, H. Chen, Z. Landgraf, S. Petridis, and M. Pantic, “Unified speech recognition: A single model for au- ditory, visual, and audiovisual inputs,”Advances in Neural Infor- mation Processing Systems, vol. 37, pp. 139 673–139 699, 2024
2024
-
[24]
Whisper-Flamingo: Integrating Visual Features into Whisper for Audio-Visual Speech Recognition and Translation,
A. Rouditchenko, Y . Gong, S. Thomas, L. Karlinsky, H. Kuehne, R. Feris, and J. Glass, “Whisper-Flamingo: Integrating Visual Features into Whisper for Audio-Visual Speech Recognition and Translation,” inInterspeech 2024, 2024, pp. 2420–2424
2024
-
[25]
Large language models are strong audio-visual speech recognition learners,
U. Cappellazzo, M. Kim, H. Chen, P. Ma, S. Petridis, D. Falavi- gna, A. Brutti, and M. Pantic, “Large language models are strong audio-visual speech recognition learners,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[26]
LRS3-TED: a large-scale dataset for visual speech recognition
T. Afouras, J. S. Chung, and A. Zisserman, “Lrs3-ted: a large-scale dataset for visual speech recognition,”arXiv preprint arXiv:1809.00496, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Do ImageNet classifiers generalize to ImageNet?
B. Recht, R. Roelofs, L. Schmidt, and V . Shankar, “Do ImageNet classifiers generalize to ImageNet?” inProceedings of the 36th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 97. PMLR, 09–15 Jun 2019, pp. 5389–5400. [Online]. Available: https://proceedings.mlr.press/v97/recht19a.html
2019
-
[28]
Do vsr models generalize beyond lrs3?
Y . A. D. Djilali, S. Narayan, E. LeBihan, H. Boussaid, E. Al- mazrouei, and M. Debbah, “Do vsr models generalize beyond lrs3?” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 6635–6644
2024
-
[29]
Scaling multilingual visual speech recognition,
K. R. Prajwal, S. Hegde, and A. Zisserman, “Scaling multilingual visual speech recognition,” inICASSP 2025 - 2025 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[30]
Looking to listen at the cock- tail party: a speaker-independent audio-visual model for speech separation,
A. Ephrat, I. Mosseri, O. Lang, T. Dekel, K. Wilson, A. Hassidim, W. T. Freeman, and M. Rubinstein, “Looking to listen at the cock- tail party: a speaker-independent audio-visual model for speech separation,”ACM Transactions on Graphics (TOG), vol. 37, no. 4, pp. 1–11, 2018
2018
-
[31]
WhisperX: Time- Accurate Speech Transcription of Long-Form Audio,
M. Bain, J. Huh, T. Han, and A. Zisserman, “WhisperX: Time- Accurate Speech Transcription of Long-Form Audio,” inInter- speech 2023, 2023, pp. 4489–4493
2023
-
[32]
To- wards inclusive automatic speech recognition,
S. Feng, B. M. Halpern, O. Kudina, and O. Scharenborg, “To- wards inclusive automatic speech recognition,”Computer Speech & Language, vol. 84, p. 101567, 2024
2024
-
[33]
Towards measuring fairness in speech recognition: Casual conversations dataset transcriptions,
C. Liu, M. Picheny, L. Sarı, P. Chitkara, A. Xiao, X. Zhang, M. Chou, A. Alvarado, C. Hazirbas, and Y . Saraf, “Towards measuring fairness in speech recognition: Casual conversations dataset transcriptions,” inICASSP 2022-2022 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6162–6166
2022
-
[34]
An overview of noise-robust automatic speech recognition,
J. Li, L. Deng, Y . Gong, and R. Haeb-Umbach, “An overview of noise-robust automatic speech recognition,”IEEE/ACM Transac- tions on Audio, Speech, and Language Processing, vol. 22, no. 4, pp. 745–777, 2014
2014
-
[35]
Performance evaluation of slam-asr: The good, the bad, the ugly, and the way forward,
S. Kumar, I. Thorbecke, S. Burdisso, E. Villatoro-Tello, M. KE, K. Hacio ˘glu, P. Rangappa, P. Motlicek, A. Ganapathiraju, and A. Stolcke, “Performance evaluation of slam-asr: The good, the bad, the ugly, and the way forward,” in2025 IEEE International Conference on Acoustics, Speech, and Signal Processing Work- shops (ICASSPW). IEEE, 2025, pp. 1–5
2025
-
[36]
Gimeno G ´omez,Contributions to Automatic Lipreading for Spanish
D. Gimeno G ´omez,Contributions to Automatic Lipreading for Spanish. Universitat Polit `ecnica de Val`encia, 2025
2025
-
[37]
Accuracy comparison across face recognition algorithms: Where are we on measuring race bias?
J. G. Cavazos, P. J. Phillips, C. D. Castillo, and A. J. O’Toole, “Accuracy comparison across face recognition algorithms: Where are we on measuring race bias?”IEEE transactions on biometrics, behavior, and identity science, vol. 3, no. 1, pp. 101–111, 2020
2020
-
[38]
Classification algorithm for skin color (casco): A new tool to measure skin color in social science research,
R. A. Rej ´on Pi ˜na and C. Ma, “Classification algorithm for skin color (casco): A new tool to measure skin color in social science research,”Social Science Quarterly, vol. 104, no. 2, pp. 168–179, 2023
2023
-
[39]
Monk skin tone scale,
E. Monk, “Monk skin tone scale,” 2019. [Online]. Available: https://skintone.google
2019
-
[40]
6d rota- tion representation for unconstrained head pose estimation,
T. Hempel, A. A. Abdelrahman, and A. Al-Hamadi, “6d rota- tion representation for unconstrained head pose estimation,” in 2022 IEEE International Conference on Image Processing (ICIP), 2022, pp. 2496–2500
2022
-
[41]
Lrw-1000: A naturally-distributed large- scale benchmark for lip reading in the wild,
S. Yang, Y . Zhang, D. Feng, M. Yang, C. Wang, J. Xiao, K. Long, S. Shan, and X. Chen, “Lrw-1000: A naturally-distributed large- scale benchmark for lip reading in the wild,” in2019 14th IEEE International Conference on Automatic Face & Gesture Recogni- tion (FG 2019), 2019, pp. 1–8
2019
-
[42]
Robust signal-to-noise ratio estima- tion based on waveform amplitude distribution analysis,
C. Kim and R. M. Stern, “Robust signal-to-noise ratio estima- tion based on waveform amplitude distribution analysis,” inInter- speech 2008, 2008, pp. 2598–2601
2008
-
[43]
K-nearest neighbour classifiers- a tutorial,
P. Cunningham and S. J. Delany, “K-nearest neighbour classifiers- a tutorial,”ACM computing surveys (CSUR), vol. 54, no. 6, pp. 1–25, 2021
2021
-
[44]
V oxCeleb2: Deep Speaker Recognition,
J. S. Chung, A. Nagrani, and A. Zisserman, “V oxCeleb2: Deep Speaker Recognition,” inInterspeech 2018, 2018, pp. 1086–1090
2018
-
[45]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[46]
G. K. Zipf,The psycho-biology of language: An introduction to dynamic philology. Routledge, 2013
2013
-
[47]
Which words are hard to recognize? prosodic, lexical, and disfluency factors that increase speech recognition error rates,
S. Goldwater, D. Jurafsky, and C. D. Manning, “Which words are hard to recognize? prosodic, lexical, and disfluency factors that increase speech recognition error rates,”Speech Communication, vol. 52, no. 3, pp. 181–200, 2010
2010
-
[48]
What’s so complex about conversational speech? a comparison of hmm- based and transformer-based asr architectures,
J. Linke, B. C. Geiger, G. Kubin, and B. Schuppler, “What’s so complex about conversational speech? a comparison of hmm- based and transformer-based asr architectures,”Computer Speech & Language, vol. 90, p. 101738, 2025
2025
-
[49]
Uncovering the visual contribution in audio- visual speech recognition,
Z. Lin and N. Harte, “Uncovering the visual contribution in audio- visual speech recognition,” inICASSP 2025 - 2025 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[50]
Cocktail-Party Audio-Visual Speech Recognition,
T.-B. Nguyen, N.-Q. Pham, and A. Waibel, “Cocktail-Party Audio-Visual Speech Recognition,” inInterspeech 2025, 2025, pp. 1828–1832
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.