Trio: Learning Time-Series Forecasting with Temporal-Spatial-Sample Attention and Structural Causal Priors
Pith reviewed 2026-06-27 22:35 UTC · model grok-4.3
The pith
Trio improves multivariate time-series forecasts by adding sample attention to reuse relevant past lookback-future pairs alongside temporal and spatial attention, trained on tasks from a structural causal model generator.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Trio organizes forecasting around three attention streams: temporal attention for within-window dynamics, spatial attention for inter-variable dependencies, and sample attention for retrieving relevant historical lookback-future pairs to guide the current output. These are paired with a Time-Series Structural Causal Model generator that produces synthetic tasks containing controlled lags, cross-variable effects, noise, feedback loops, and distributional drift. The resulting architecture yields measurable improvements in forecasting accuracy on held-out synthetic, industrial, and public datasets, while exploratory zero-shot transfer from the generated tasks indicates they can serve as structu
What carries the argument
The Temporal-Spatial-Sample attention mechanism, which adds an explicit retrieval step over historical input-output pairs to the standard temporal and spatial modeling, together with the TS-SCM generator that supplies the structured synthetic training tasks.
If this is right
- Forecasting performance rises on synthetic, industrial, and public benchmarks when the three attention types and TS-SCM training are used together.
- Historical input-output pairs can be organized and reused inside the model to guide predictions beyond what window-internal patterns alone provide.
- Tasks generated by the structural causal model can supply priors that support zero-shot transfer in some settings.
- Fully general prior-data fitted forecasting for arbitrary time series remains open.
Where Pith is reading between the lines
- The same sample-retrieval idea could be tested on other sequential tasks such as anomaly detection or control where past trajectories matter.
- Success would depend on keeping the synthetic data distribution close enough to real data that retrieved pairs remain relevant.
- If sample attention proves reliable, training data requirements might be reduced by supplementing limited real series with the generated structural tasks.
Load-bearing premise
Retrieved historical pairs will match the current forecasting situation closely enough that their reuse actually improves accuracy rather than introducing harmful mismatches.
What would settle it
An ablation in which sample attention is replaced by random selection of historical pairs or removed entirely, with no resulting drop in accuracy on the benchmark suites.
Figures
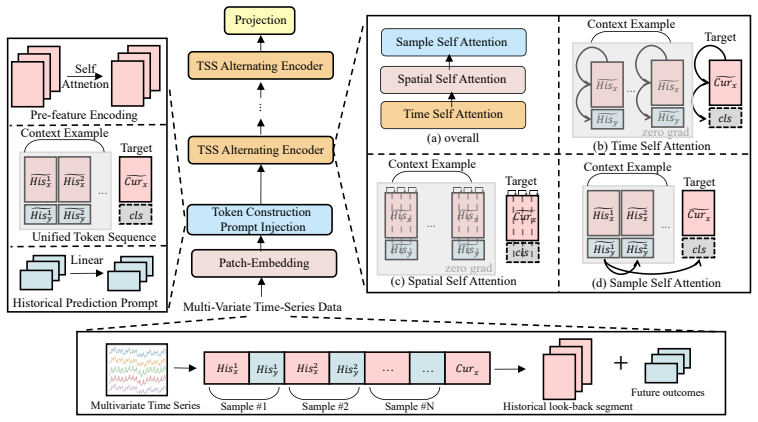
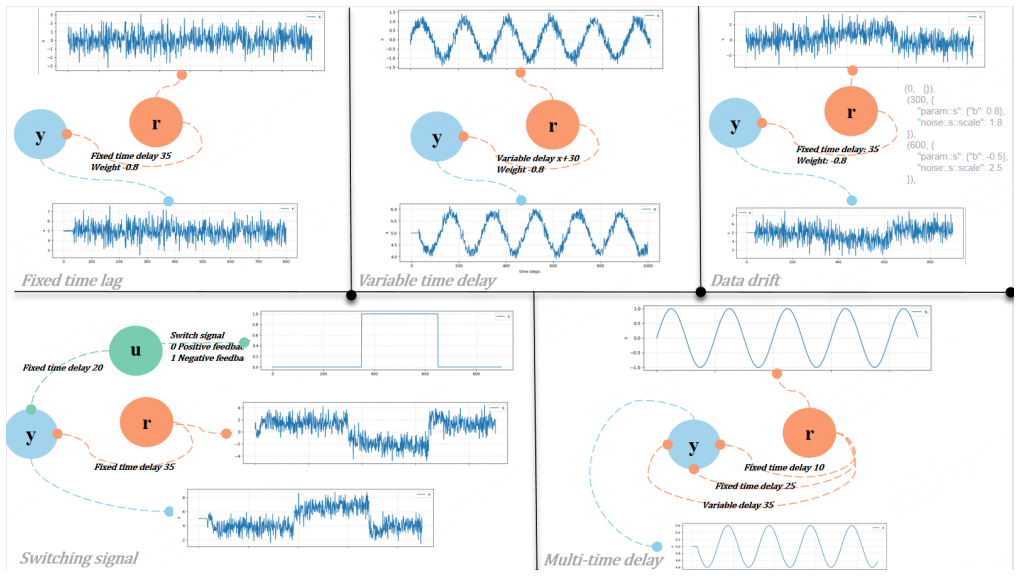
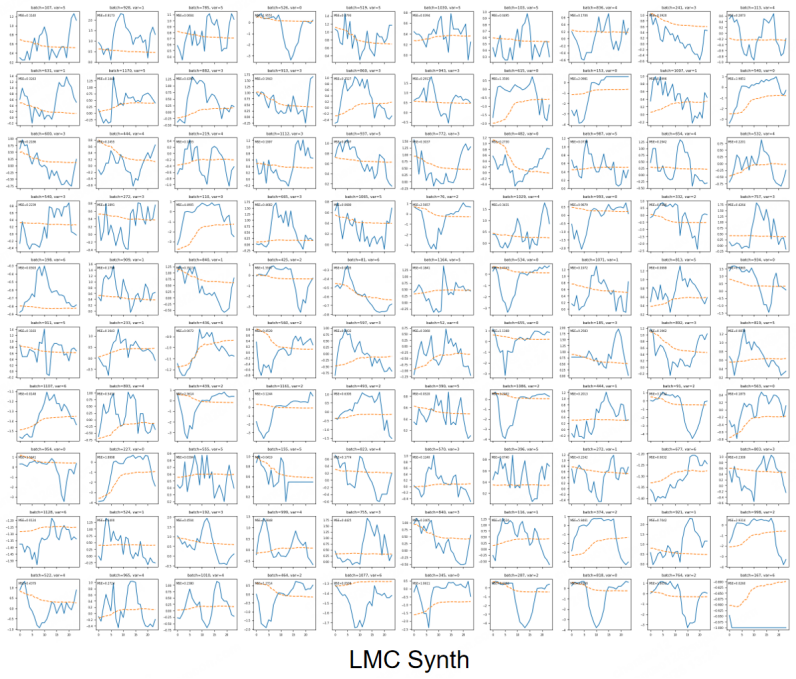
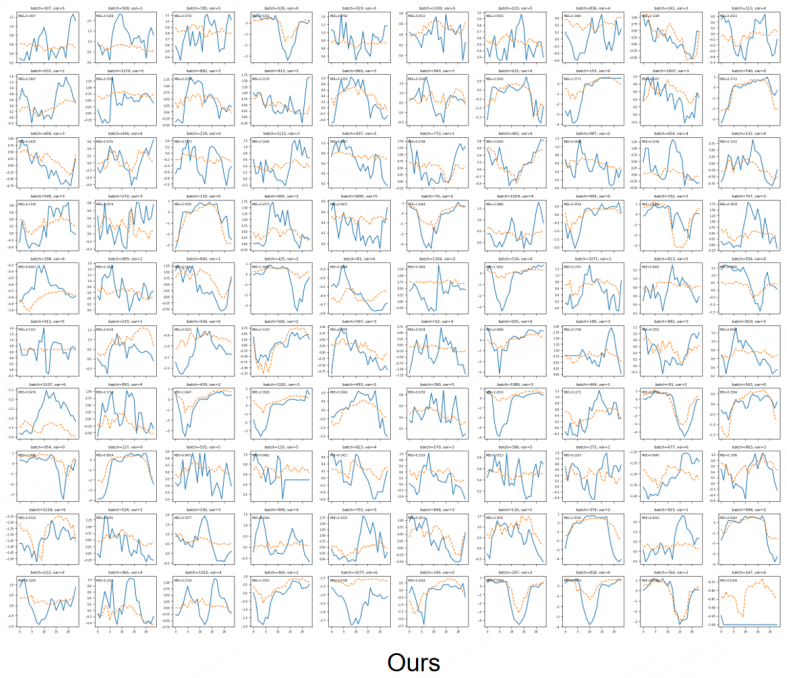
read the original abstract
Multivariate time-series forecasting requires models to reason over temporal dynamics, cross-variable dependencies, and historical input-output correspondences. Recent Prior-Data Fitted Networks (PFNs) suggest that synthetic tasks can be useful for learning transferable inference behavior. However, directly transferring this paradigm to time-series forecasting remains difficult, since temporal order, dynamic lags, and recurring historical patterns are not naturally captured by ordinary tabular priors. Motivated by this observation, we propose Trio, a sample-aware time-series forecasting architecture based on Temporal-Spatial-Sample attention. Temporal attention captures within-window dynamics, spatial attention models inter-variable dependencies, and sample attention retrieves relevant historical lookback-future pairs to guide the current prediction. Rather than claiming a fully general PFN-style forecaster, our goal is to study how historical input-output examples can be explicitly organized and reused within a forecasting model. We further introduce a Time-Series Structural Causal Model (TS-SCM) generator to create structured synthetic forecasting tasks with dynamic lags, cross-variable interactions, noise, feedback, and distributional drift. Experiments on synthetic, industrial, and public benchmarks show that the proposed architecture improves forecasting performance. Exploratory zero-shot experiments further suggest that TS-SCM-generated tasks may provide useful structural priors, while fully general PFN-style time-series forecasting remains an open problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Trio, a forecasting architecture that augments standard temporal and spatial attention with a sample-attention mechanism to retrieve and reuse historical lookback-future pairs, together with a TS-SCM generator that produces synthetic tasks containing dynamic lags, cross-variable interactions, noise, feedback, and distributional drift. Experiments on synthetic, industrial, and public benchmarks are reported to show performance gains, and exploratory zero-shot tests are said to indicate that TS-SCM tasks supply useful structural priors; the authors position the work as a study of explicit historical-example reuse rather than a fully general PFN-style forecaster.
Significance. If the reported gains are reproducible and the sample-attention mechanism is shown to be the operative factor, the contribution would lie in demonstrating a concrete way to organize and exploit historical input-output correspondences inside an attention-based forecaster and in providing a structured synthetic generator that encodes causal time-series properties; these elements could inform subsequent work on transferable priors for sequential data.
major comments (2)
- [Experiments section (implied by abstract claims)] The central claim that sample attention improves predictions by retrieving relevant historical pairs rests on the untested premise that TS-SCM-generated tasks are distributionally close enough to the industrial and public benchmarks for retrieval to remain informative; no quantitative comparison of marginals, lag structures, or cross-variable dependencies between synthetic and real data is supplied to support this transfer.
- [Exploratory zero-shot experiments] Exploratory zero-shot results are presented as evidence that TS-SCM tasks provide useful structural priors, yet the manuscript supplies neither the precise zero-shot protocol (e.g., how many synthetic tasks, how the prior is injected) nor ablation controls that isolate the contribution of the causal structure versus generic synthetic data.
minor comments (2)
- [Abstract] The abstract asserts performance improvements without any numerical values, error bars, or dataset identifiers, which hinders immediate assessment even though the full manuscript presumably contains these details.
- [Method] Notation for the three attention modules and their combination is introduced only descriptively; explicit equations defining the sample-attention retrieval operation would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. We address each major comment point by point below, providing clarifications based on the current work and indicating where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: The central claim that sample attention improves predictions by retrieving relevant historical pairs rests on the untested premise that TS-SCM-generated tasks are distributionally close enough to the industrial and public benchmarks for retrieval to remain informative; no quantitative comparison of marginals, lag structures, or cross-variable dependencies between synthetic and real data is supplied to support this transfer.
Authors: We appreciate this observation. The sample-attention mechanism is designed to retrieve historical lookback-future pairs primarily from within the same dataset distribution during both training and inference on each benchmark, rather than assuming direct transfer from TS-SCM to real data. However, we agree that the manuscript would benefit from explicit quantitative support for any cross-distributional aspects of the structural priors. We will add comparisons of marginal distributions, lag structures (via autocorrelation and cross-correlation metrics), and cross-variable dependencies between TS-SCM tasks and the real benchmarks in a new subsection of the experiments. revision: yes
-
Referee: Exploratory zero-shot results are presented as evidence that TS-SCM tasks provide useful structural priors, yet the manuscript supplies neither the precise zero-shot protocol (e.g., how many synthetic tasks, how the prior is injected) nor ablation controls that isolate the contribution of the causal structure versus generic synthetic data.
Authors: We acknowledge that the exploratory zero-shot section lacks sufficient detail on the protocol and controls. The zero-shot setup involves pre-training the model on a collection of TS-SCM tasks before evaluating on held-out real benchmarks without further fine-tuning, with the structural priors injected through the sample-attention module. We will revise the manuscript to specify the exact number of synthetic tasks, the injection mechanism, and to include ablation experiments comparing TS-SCM against generic synthetic generators (e.g., without causal structure) to isolate the contribution of the priors. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The paper introduces an architecture (Trio) and a synthetic data generator (TS-SCM) then reports empirical improvements on synthetic, industrial, and public benchmarks plus exploratory zero-shot results. No equations, derivations, or first-principles predictions appear that reduce a claimed output to a quantity defined by the model itself or to a self-citation chain. The performance claims are measured against held-out data and are therefore falsifiable independently of the model's internal attention mechanisms or generator parameters.
Axiom & Free-Parameter Ledger
invented entities (1)
-
TS-SCM generator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[2]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[3]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[4]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[5]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[6]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[7]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[8]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[9]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[10]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[11]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[12]
The Fourteenth International Conference on Learning Representations , year=
MambaSL: Exploring Single-Layer Mamba for Time Series Classification , author=. The Fourteenth International Conference on Learning Representations , year=
-
[13]
arXiv preprint arXiv:2411.00278 , year=
KAN-AD: Time series anomaly detection with Kolmogorov-Arnold networks , author=. arXiv preprint arXiv:2411.00278 , year=
-
[14]
arXiv preprint arXiv:2501.13041 , year=
TimeFilter: Patch-specific spatial-temporal graph filtration for time series forecasting , author=. arXiv preprint arXiv:2501.13041 , year=
-
[15]
arXiv preprint arXiv:2207.01848 , year=
Tabpfn: A transformer that solves small tabular classification problems in a second , author=. arXiv preprint arXiv:2207.01848 , year=
-
[16]
Nature , volume=
Accurate predictions on small data with a tabular foundation model , author=. Nature , volume=. 2025 , publisher=
2025
-
[17]
arXiv preprint arXiv:2605.13986 , year=
TabPFN-3: Technical Report , author=. arXiv preprint arXiv:2605.13986 , year=
-
[18]
The Thirteenth International Conference on Learning Representations , year=
In-context Time Series Predictor , author=. The Thirteenth International Conference on Learning Representations , year=
-
[19]
The Thirty-Ninth Annual Conference on Neural Information Processing Systems , year =
Andreas Auer and Patrick Podest and Daniel Klotz and Sebastian B. The Thirty-Ninth Annual Conference on Neural Information Processing Systems , year =
-
[20]
Forty-first International Conference on Machine Learning , year=
A decoder-only foundation model for time-series forecasting , author=. Forty-first International Conference on Machine Learning , year=
-
[21]
Advances in neural information processing systems , volume=
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting , author=. Advances in neural information processing systems , volume=
-
[22]
International Conference on Learning Representations , year =
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers , author =. International Conference on Learning Representations , year =
-
[23]
The Twelfth International Conference on Learning Representations , year=
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting , author=. The Twelfth International Conference on Learning Representations , year=
-
[24]
Advances in Neural Information Processing Systems , year=
Timexer: Empowering transformers for time series forecasting with exogenous variables , author=. Advances in Neural Information Processing Systems , year=
-
[25]
arXiv preprint arXiv:2501.02945 , year=
From Tables to Time: Extending TabPFN-v2 to Time Series Forecasting , author=. arXiv preprint arXiv:2501.02945 , year=
-
[26]
1st ICML Workshop on Foundation Models for Structured Data , year=
Explore the Time Series Forecasting Potential of TabPFN Leveraging the Intrinsic Periodicity of Data , author=. 1st ICML Workshop on Foundation Models for Structured Data , year=
-
[27]
arXiv preprint arXiv:2407.13278 , year=
Deep Time Series Models: A Comprehensive Survey and Benchmark , author=. arXiv preprint arXiv:2407.13278 , year=
-
[28]
International Conference on Learning Representations , year=
TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis , author=. International Conference on Learning Representations , year=
-
[29]
International Conference on Learning Representations , volume=
Timemixer++: A general time series pattern machine for universal predictive analysis , author=. International Conference on Learning Representations , volume=
-
[30]
Forty-second International Conference on Machine Learning , year=
Patch-wise Structural Loss for Time Series Forecasting , author=. Forty-second International Conference on Machine Learning , year=
-
[31]
Songtao Huang and Zhen Zhao and Can Li and LEI BAI , booktitle=. Time. 2025 , url=
2025
-
[32]
Forty-first International Conference on Machine Learning , year=
Unified Training of Universal Time Series Forecasting Transformers , author=. Forty-first International Conference on Machine Learning , year=
-
[33]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Das, Abhimanyu and Kong, Weihao and Sen, Rajat and Zhou, Yichen , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[34]
International conference on learning representations , volume=
Timemixer: Decomposable multiscale mixing for time series forecasting , author=. International conference on learning representations , volume=
-
[35]
arXiv preprint arXiv:2211.14730 , year=
A time series is worth 64 words: Long-term forecasting with transformers , author=. arXiv preprint arXiv:2211.14730 , year=
-
[36]
Proceedings of the AAAI conference on artificial intelligence , volume=
Are transformers effective for time series forecasting? , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[37]
arXiv preprint arXiv:2405.14982 , year=
In-context time series predictor , author=. arXiv preprint arXiv:2405.14982 , year=
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
TimePFN: Effective multivariate time series forecasting with synthetic data , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[39]
arXiv preprint arXiv:2505.16620 , year=
CausalDynamics: A large-scale benchmark for structural discovery of dynamical causal models , author=. arXiv preprint arXiv:2505.16620 , year=
-
[40]
arXiv preprint arXiv:2602.10847 , year=
Enhancing multivariate time series forecasting with global temporal retrieval , author=. arXiv preprint arXiv:2602.10847 , year=
-
[41]
arXiv preprint arXiv:2411.08249 , year=
Retrieval augmented time series forecasting , author=. arXiv preprint arXiv:2411.08249 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.