Letting Homogeneity Entropy Select S-Pairs in Buchberger's Algorithm
Pith reviewed 2026-06-27 20:34 UTC · model grok-4.3
The pith
Homogeneity Entropy selects S-pairs more efficiently than classical strategies on random polynomial systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Homogeneity Entropy strategy, which chooses the next S-pair according to an information-theoretic measure of how evenly the degrees are distributed among the monomials appearing in that pair, produces shorter reduction sequences than the classical Degree, Normal and Sugar strategies when the input consists of randomly generated polynomial systems, yet produces longer sequences than the same classical strategies when the input consists of the PHCpack benchmark problems.
What carries the argument
Homogeneity Entropy, the information-theoretic measure computed from the degree distribution of monomials inside each S-polynomial, used to rank and select the next pair to reduce.
If this is right
- No single S-pair selection heuristic is optimal for every shape of polynomial system.
- An information-theoretic criterion can be used to guide ordering decisions inside Groebner-basis algorithms.
- Performance of any given selection rule can be predicted from measurable properties of the input such as density and degree spread.
- Practical speed-ups are available for problem classes that resemble the random test distributions.
Where Pith is reading between the lines
- A hybrid selector that first measures the input distribution and then switches between entropy and classical rules could capture the best of both regimes.
- The same entropy idea might be applied to other ordering problems inside computer-algebra systems, such as monomial ordering or critical-pair selection in other algorithms.
- The method invites direct comparison against the machine-learning selectors mentioned in the paper on the same controlled random families.
Load-bearing premise
The observed performance gaps are produced by the entropy measure rather than by unstated implementation choices or tuning parameters.
What would settle it
A controlled experiment that applies the four strategies to a new family of polynomial systems whose variable count, degree profile and sparsity lie between the random test set and the PHCpack set and records which strategy requires the fewest reductions.
Figures
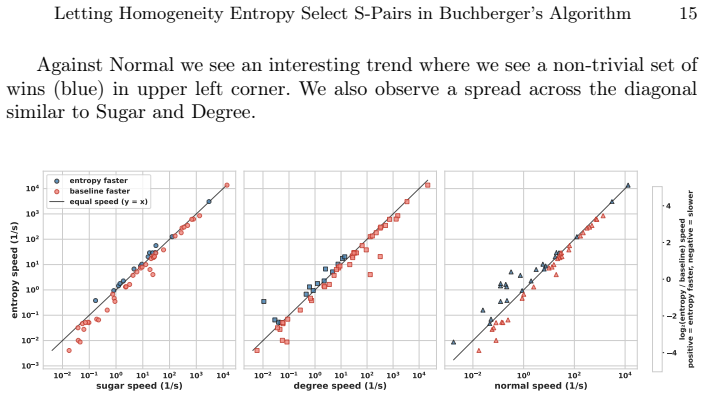
read the original abstract
We present a novel S-pair selection strategy called Homogeneity Entropy, for deciding the sequence of S-polynomials to construct in Buchberger's algorithm to compute a Groebner basis. The strategy uses an information theoretic measure derived from the distribution of degrees among the monomials of the S-polynomial: a very different approach to the classical heuristics such as Degree, Normal and Sugar, or indeed the more recent machine learning approaches to the problem. We implement this strategy and evaluate it on two different datasets: (1) variations of randomly generated polynomial systems with controlled numbers of variables, degrees, and densities; and (2) the PHCpack benchmark dataset sourced from real world problems. The Homogeneity Entropy strategy significantly outperforms classical strategies on random polynomial datasets, but on the PHCpack dataset the classical strategies perform better. This suggests the right strategy varies with the shape of the data and we explore this in several experiments. The new strategy offers practically meaningful gains on certain distributions, and represents the first use of such information-theoretic guidance in the optimisation of symbolic computation algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Homogeneity Entropy, a new S-pair selection strategy for Buchberger's algorithm that uses an information-theoretic measure based on the degree distribution among monomials in each S-polynomial. This is contrasted with classical heuristics (Degree, Normal, Sugar) and recent ML approaches. The strategy is implemented and tested on two collections: (1) randomly generated polynomial systems with controlled numbers of variables, degrees and densities, where it significantly outperforms the classical strategies, and (2) the PHCpack benchmark of real-world problems, where the classical strategies perform better. The authors conclude that the appropriate strategy is data-dependent and that the new criterion yields practically meaningful gains on certain distributions; they present this as the first use of information-theoretic guidance for optimizing symbolic computation algorithms.
Significance. If the observed performance differences can be shown to arise from the entropy criterion itself rather than implementation artifacts, the work would open a new direction for heuristic design in Groebner-basis algorithms by importing tools from information theory. The explicit comparison across two qualitatively different datasets (controlled random systems versus PHCpack) is a positive feature that already illustrates the data-dependence claim. The absence of any free parameters in the proposed measure is also a conceptual strength.
major comments (2)
- [Evaluation section] Evaluation (datasets and results): the manuscript reports that Homogeneity Entropy 'significantly outperforms' the classical strategies on the random-polynomial collection yet is outperformed by them on PHCpack, but supplies no pseudocode, tie-breaking conventions, monomial-ordering details, or data-structure choices for any of the four strategies. Because the central claim of 'practically meaningful gains on certain distributions' rests entirely on these empirical differences being attributable to the entropy measure, the lack of implementation transparency makes it impossible to exclude confounding factors.
- [Dataset description] Random-system generator: the description is limited to 'controlled numbers of variables, degrees, and densities' with no explicit generation procedure, density model, or seed information. Any hidden bias in how the random instances are produced could systematically favor or disfavor the degree-distribution statistic used by Homogeneity Entropy, undermining the attribution of performance differences to the selection criterion.
minor comments (1)
- The abstract states that 'several experiments' explore the dependence on data shape, yet the manuscript provides no section or figure references that would allow a reader to locate those supporting results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important issues of reproducibility and attribution. We address each major comment below and will revise the manuscript accordingly to strengthen the empirical claims.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation (datasets and results): the manuscript reports that Homogeneity Entropy 'significantly outperforms' the classical strategies on the random-polynomial collection yet is outperformed by them on PHCpack, but supplies no pseudocode, tie-breaking conventions, monomial-ordering details, or data-structure choices for any of the four strategies. Because the central claim of 'practically meaningful gains on certain distributions' rests entirely on these empirical differences being attributable to the entropy measure, the lack of implementation transparency makes it impossible to exclude confounding factors.
Authors: We agree that the absence of these implementation details limits the ability to attribute performance differences unambiguously to the entropy criterion. In the revised manuscript we will add pseudocode for Homogeneity Entropy together with the three classical strategies, explicit tie-breaking rules (lexicographic on leading monomials when scores are equal), the monomial ordering used throughout (graded reverse lexicographic), and the data structures (binary heaps for the S-pair queue). These additions will make the experiments fully reproducible and allow readers to verify that observed gains are not due to implementation artifacts. revision: yes
-
Referee: [Dataset description] Random-system generator: the description is limited to 'controlled numbers of variables, degrees, and densities' with no explicit generation procedure, density model, or seed information. Any hidden bias in how the random instances are produced could systematically favor or disfavor the degree-distribution statistic used by Homogeneity Entropy, undermining the attribution of performance differences to the selection criterion.
Authors: We acknowledge that the current description of the random-system generator is insufficient for reproducibility and for ruling out systematic bias. The revised manuscript will include the precise generation algorithm: monomials are drawn uniformly from the possible exponent vectors subject to a density parameter that controls the fraction of non-zero coefficients, with explicit ranges for number of variables, total degree, and density; we will also report the random seeds employed and a short discussion of why the chosen model does not preferentially advantage the homogeneity-entropy statistic over degree-based heuristics. revision: yes
Circularity Check
No circularity: new heuristic defined directly from degree distribution and evaluated on external benchmarks
full rationale
The paper introduces Homogeneity Entropy as an information-theoretic measure computed directly from the degree distribution of monomials in each S-polynomial. This definition is independent of any fitted parameters or prior results from the same authors. Performance is assessed via direct empirical comparison against classical strategies on two fixed external collections (controlled random systems and PHCpack), with no derivation step that reduces a claimed prediction back to the input data or a self-citation. The central claim therefore rests on observable differences rather than any definitional or fitted loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Barket, R., England, M., Gerhard, J.: Symbolic integration algorithm selection with machine learning: LSTMs vs tree LSTMs. In: Buzzard, K., Dickenstein, A., Letting Homogeneity Entropy Select S-Pairs in Buchberger’s Algorithm 19 Eick, B., Leykin, A., Ren, Y. (eds.) Mathematical Software – ICMS 2024. Lecture Notes in Computer Science, vol. 14749, pp. 167–1...
-
[2]
In: The 4th Workshop on Mathematical Reasoning and AI (MATH-AI) at NeurIPS’24
Barket, R., Shafiq, U., England, M., Gerhard, J.: Transformers to predict the appli- cability of symbolic integration routines. In: The 4th Workshop on Mathematical Reasoning and AI (MATH-AI) at NeurIPS’24. NeurIPS 2024, Vancouver, Canada (2024), https://openreview.net/forum?id=b2Ni828As7
2024
-
[3]
In: Symbolic and Algebraic Computation
Buchberger, B.: A criterion for detecting unnecessary reductions in the con- struction of Gröbner-bases. In: Symbolic and Algebraic Computation. pp. 3–21. Springer Berlin Heidelberg, Berlin, Heidelberg (1979). https://doi.org/10.1007/ 3-540-09519-5_52
1979
-
[4]
Buchberger, B.: Gröbner Bases and Systems Theory. Multidimensional Sys- tems and Signal Processing12(3-4), 223–251 (2001). https://doi.org/10.1023/A: 1011949421611
work page doi:10.1023/a: 2001
-
[5]
Journal of Symbolic Computation41(3), 475–511 (2006)
Buchberger, B.: Bruno Buchberger’s PhD thesis 1965: An algorithm for finding the basis elements of the residue class ring of a zero dimensional polynomial ideal. Journal of Symbolic Computation41(3), 475–511 (2006). https://doi.org/10.1016/ j.jsc.2005.09.007
1965
-
[6]
In: Proceedings of the Twenty-First International Symposium on Symbolic and Algebraic Computation
Caboara, M., Caruso, F., Traverso, C.: Gröbner bases for public key cryptogra- phy. In: Proceedings of the Twenty-First International Symposium on Symbolic and Algebraic Computation. p. 315–324. ISSAC ’08, Association for Computing Machinery, New York, NY, USA (2008). https://doi.org/10.1145/1390768.1390811
-
[7]
Springer Inter- national Publishing, Cham (2015)
Cox,D.A.,Little,J.,O’Shea,D.:Ideals,Varieties,andAlgorithms:AnIntroduction to Computational Algebraic Geometry and Commutative Algebra. Springer Inter- national Publishing, Cham (2015). https://doi.org/10.1007/978-3-319-16721-3_2
-
[8]
Mathematics in Computer Science18, 1–27 (2024)
del Rıo, T., England, M.: Lessons on datasets and paradigms in machine learn- ing for symbolic computation: A case study on CAD. Mathematics in Computer Science18, 1–27 (2024). https://doi.org/10.1007/s11786-024-00591-0
-
[9]
In: Proceedings of the 2002 international symposium on Symbolic and algebraic computation
Faugère, J.C.: A new efficient algorithm for computing Gröbner bases without reduction to zero (F5). In: Proceedings of the 2002 international symposium on Symbolic and algebraic computation. pp. 75–83. ACM, Lille France (Jul 2002). https://doi.org/10.1145/780506.780516
-
[10]
Jour- nal of Symbolic Computation6(2), 275–286 (1988)
Gebauer, R., Möller, H.M.: On an installation of Buchberger’s algorithm. Jour- nal of Symbolic Computation6(2), 275–286 (1988). https://doi.org/10.1016/ S0747-7171(88)80048-8
1988
-
[11]
Giovini, A., Mora, T., Niesi, G., Robbiano, L., Traverso, C.: “One sugar cube, please” or selection strategies in the Buchberger algorithm. In: Proceedings of the 1991 international symposium on Symbolic and algebraic computation. pp. 49–54. ACM, Bonn West Germany (1991). https://doi.org/10.1145/120694.120701
-
[12]
Journal of Symbolic Computa- tion126, 102345 (2025), https://doi.org/10.1016/j.jsc.2024.102345
Hashemi, A., Mirhashemi, M., Seiler, W.M.: Machine learning parameter systems, Noether normalisations and quasi-stable positions. Journal of Symbolic Computa- tion126, 102345 (2025), https://doi.org/10.1016/j.jsc.2024.102345
-
[13]
In: Watt, S.M., Davenport, J.H., Sexton, A.P., Sojka, P., Urban, J
Huang, Z., England, M., Wilson, D., Davenport, J.H., Paulson, L., Bridge, J.: Ap- plying machine learning to the problem of choosing a heuristic to select the variable ordering for cylindrical algebraic decomposition. In: Watt, S.M., Davenport, J.H., Sexton, A.P., Sojka, P., Urban, J. (eds.) Intelligent Computer Mathematics, Lec- ture Notes in Artificial ...
-
[14]
In: Thirty- 20 U
Jia, F., Dong, Y., Liu, M., Huang, P., Ma, F., Zhang, J.: Suggesting variable order for cylindrical algebraic decomposition via reinforcement learning. In: Thirty- 20 U. Shafiqet al. seventh Conference on Neural Information Processing Systems (NIPS 2023) (2023), https://openreview.net/forum?id=vNsdFwjPtL
2023
-
[15]
Jour- nal of Symbolic Computation2(4), 399–408 (1986)
Kapur, D.: Using Gröbner bases to reason about geometry problems. Jour- nal of Symbolic Computation2(4), 399–408 (1986). https://doi.org/10.1016/ S0747-7171(86)80007-4
1986
-
[16]
In: Proceedings of the 38th International Conference on Neural Information Processing Systems
Kera, H., Ishihara, Y., Kambe, Y., Vaccon, T., Yokoyama, K.: Learning to compute Gröbner bases. In: Proceedings of the 38th International Conference on Neural Information Processing Systems. NIPS ’24, Curran Associates Inc., Red Hook, NY, USA (2024), https://openreview.net/forum?id=ZRz7XlxBzQ
2024
-
[17]
Advances in Mathematics46(3), 305–329 (Dec 1982)
Mayr, E.W., Meyer, A.R.: The complexity of the word problems for commutative semigroups and polynomial ideals. Advances in Mathematics46(3), 305–329 (Dec 1982). https://doi.org/10.1016/0001-8708(82)90048-2
-
[18]
Master’s thesis, University of Maryland, Col- lege Park, College Park, MD (Dec 2004), https://drum.lib.umd.edu/items/ 07444dba-4078-430d-b77f-fe8fb25ba3bf
McKay, C.E.: An Analysis of Improvements to Buchberger’s Algorithm for Gröbner Basis Computation. Master’s thesis, University of Maryland, Col- lege Park, College Park, MD (Dec 2004), https://drum.lib.umd.edu/items/ 07444dba-4078-430d-b77f-fe8fb25ba3bf
2004
-
[19]
PeerJ Computer Science3, e103 (Jan 2017)
Meurer, A., Smith, C.P., Paprocki, M., Čertík, O., Kirpichev, S.B., Rocklin, M., Kumar, A., Ivanov, S., Moore, J.K., Singh, S., Rathnayake, T., Vig, S., Granger, B.E., Muller, R.P., Bonazzi, F., Gupta, H., Vats, S., Johansson, F., Pedregosa, F., Curry, M.J., Terrel, A.R., Š. Roučka, Saboo, A., Fernando, I., Kulal, S., Cimrman, R., Scopatz, A.: SymPy: Symb...
-
[20]
In: Proceedings of the 37th International Conference on Machine Learning
Peifer, D., Stillman, M., Halpern-Leistner, D.: Learning selection strategies in Buchberger’s algorithm. In: Proceedings of the 37th International Conference on Machine Learning. pp. 7575–7585. PMLR, Vienna, Austria (2020), https: //proceedings.mlr.press/v119/peifer20a.html
2020
-
[21]
Peifer, D.J.: Reinforcement Learning in Buchberger’s Algorithm. Ph.D. thesis, Cor- nell University (2021), http://doi.org/10.7298/4fpv-bn09
-
[22]
Journal of Symbolic Computation123, 102276 (2024)
Pickering, L., Del Rio Almajano, T., England, M., Cohen, K.: Explainable AI insights for symbolic computation: A case study on selecting the variable ordering for cylindrical algebraic decomposition. Journal of Symbolic Computation123, 102276 (2024). https://doi.org/10.1016/j.jsc.2023.102276
-
[23]
Advances in Applied Mathematics107, 74–101 (2019)
Sadeghimanesh,A.,Feliu,E.:Gröbnerbasesofreactionnetworkswithintermediate species. Advances in Applied Mathematics107, 74–101 (2019). https://doi.org/ https://doi.org/10.1016/j.aam.2019.02.006
-
[24]
(eds.): Gröbner Bases, Coding, and Cryptography
Sala, M., Mora, T., Perret, L., Sakata, S., Traverso, C. (eds.): Gröbner Bases, Coding, and Cryptography. Springer, Berlin, Heidelberg (2009). https://doi.org/ 10.1007/978-3-540-93806-4
-
[25]
Shannon, C.E.: A mathematical theory of communication. The Bell System Tech- nical Journal27(3), 379–423 (1948). https://doi.org/10.1002/j.1538-7305.1948. tb01338.x
-
[26]
In: Proceedings of the 3rd Workshop on Mathematical Reasoning and AI (MATH-AI
Sharma, V., Nagpal, A., Balin, M.: SIRD: Symbolic integration rules dataset. In: Proceedings of the 3rd Workshop on Mathematical Reasoning and AI (MATH-AI
-
[27]
at NIPS 2023 (2023), https://mathai2023.github.io/papers/39.pdf
2023
-
[28]
ACM Transactions on Mathematical Software 25(2), 251–276 (1999)
Verschelde, J.: Algorithm 795: PHCpack: A general-purpose solver for polynomial systems by homotopy continuation. ACM Transactions on Mathematical Software 25(2), 251–276 (1999). https://doi.org/10.1145/317275.317286
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.