DirectAudioEdit: Inversion-Free Text-Guided Audio Editing via Diffusion Prediction Contrast
Pith reviewed 2026-06-27 20:51 UTC · model grok-4.3
The pith
DirectAudioEdit performs text-guided audio editing without inversion or training by contrasting diffusion predictions during denoising.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
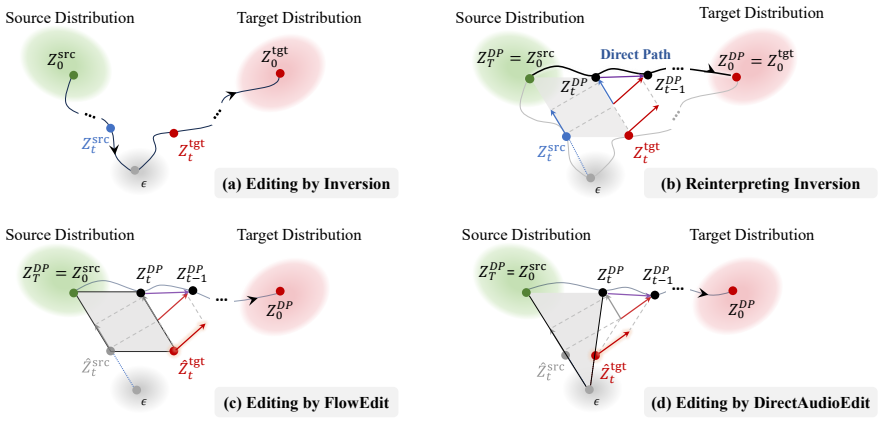
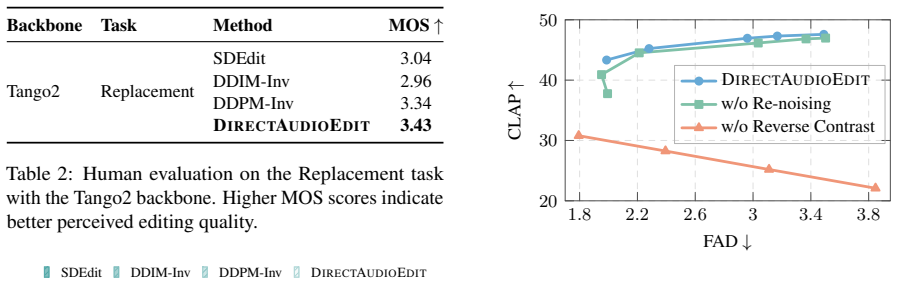
DirectAudioEdit is the first training-free and inversion-free method for text-guided audio editing. It constructs a source-to-target editing path through diffusion denoising dynamics via diffusion prediction contrast. On music and event-level benchmarks across two backbones, the approach reduces macro-averaged FAD by 15.9 percent and KL by 15.8 percent relative to DDPM inversion while delivering up to 64.5 percent editing speedup.
What carries the argument
Diffusion prediction contrast, which builds the editing trajectory by comparing model predictions across the denoising process without requiring inversion or additional training.
Load-bearing premise
Diffusion prediction contrast can construct a reliable source-to-target editing path through denoising dynamics without inversion or training.
What would settle it
An experiment in which DirectAudioEdit produces higher macro-averaged FAD or KL scores than DDPM inversion on the same music and event benchmarks, or fails to achieve measurable speedup.
Figures

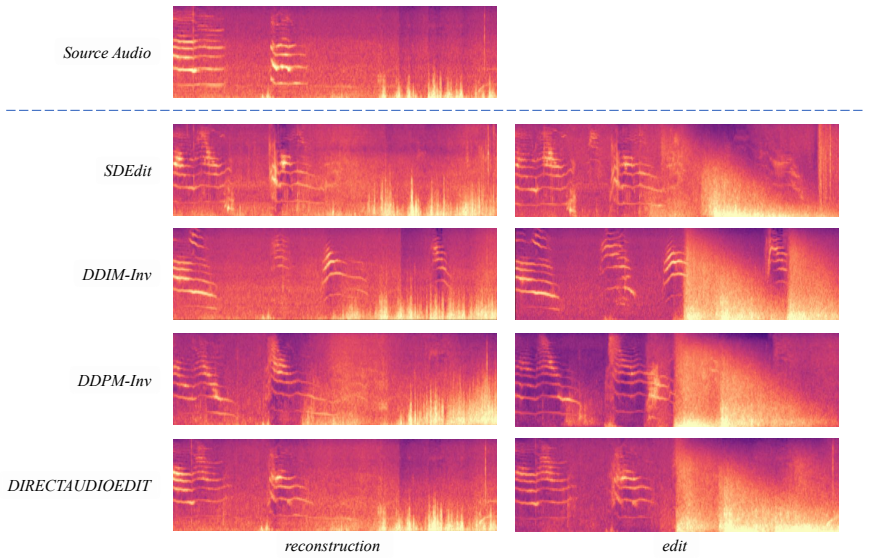
read the original abstract
Text-guided audio editing aims to modify the language-specified acoustic content while preserving edit-irrelevant source components. Existing training-free methods typically rely on inversion-based editing. While inversion-free editing is appealing as it decreases computational overhead and reconstruction errors, it remains largely unexplored for audio editing. The key challenge is to construct a source-to-target editing path through diffusion denoising dynamics. In this paper, we introduce DirectAudioEdit, the first attempt to develop a training-free and inversion-free method for audio editing. Experiments on music and event-level benchmarks across two backbones show that DirectAudioEdit reduces macro-averaged FAD and KL by 15.9% and 15.8% compared with DDPM inversion, while achieving up to 64.5% editing speedup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DirectAudioEdit, the first training-free and inversion-free method for text-guided audio editing. It uses diffusion prediction contrast to construct a source-to-target editing path through denoising dynamics without relying on inversion or additional training. Experiments on music and event-level benchmarks across two backbones report that the method reduces macro-averaged FAD and KL by 15.9% and 15.8% relative to DDPM inversion while achieving up to 64.5% editing speedup.
Significance. If the empirical gains hold under re-implementation, the work offers a lower-overhead alternative to inversion-based audio editing, addressing reconstruction errors and computational cost. The falsifiable performance claims and focus on an unexplored direction in diffusion-based audio editing constitute a modest but concrete contribution.
minor comments (2)
- [Abstract] The abstract states quantitative improvements but the provided text does not include the experimental protocol, error bars, or statistical significance tests; the methods and results sections should supply these details to support the reported metric reductions.
- [Experiments] The two backbones used in the experiments are referenced but not named; listing them explicitly (e.g., in §4) would improve clarity and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation of minor revision. The assessment correctly identifies the core contribution as a training-free, inversion-free editing path via diffusion prediction contrast.
Circularity Check
No significant circularity detected
full rationale
The paper presents DirectAudioEdit as an empirical training-free inversion-free audio editing method based on diffusion prediction contrast. Claims rest on benchmark comparisons (FAD, KL reductions and speedup vs. DDPM inversion) rather than any derivation chain. No equations, fitted parameters called predictions, self-definitional constructs, or load-bearing self-citations appear that would reduce results to inputs by construction. The method is described as falsifiable via re-implementation on music and event benchmarks, rendering the argument self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zero-Shot Unsupervised and Text-Based Audio Editing Using
Hila Manor and Tomer Michaeli , bibsource =. Zero-Shot Unsupervised and Text-Based Audio Editing Using. Forty-first International Conference on Machine Learning,
-
[2]
Yixiao Zhang and Yukara Ikemiya and Gus Xia and Naoki Murata and Marco A. Mart. MusicMagus: Zero-Shot Text-to-Music Editing via Diffusion Models , url =. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence,
-
[3]
Separate anything you describe , volume =
Liu, Xubo and Kong, Qiuqiang and Zhao, Yan and Liu, Haohe and Yuan, Yi and Liu, Yuzhuo and Xia, Rui and Wang, Yuxuan and Plumbley, Mark D and Wang, Wenwu , journal =. Separate anything you describe , volume =
-
[4]
Audioldm 2: Learning holistic audio generation with self-supervised pretraining , volume =
Liu, Haohe and Yuan, Yi and Liu, Xubo and Mei, Xinhao and Kong, Qiuqiang and Tian, Qiao and Wang, Yuping and Wang, Wenwu and Wang, Yuxuan and Plumbley, Mark D , journal =. Audioldm 2: Learning holistic audio generation with self-supervised pretraining , volume =
-
[5]
Mandic and Wenwu Wang and Mark D
Haohe Liu and Zehua Chen and Yi Yuan and Xinhao Mei and Xubo Liu and Danilo P. Mandic and Wenwu Wang and Mark D. Plumbley , bibsource =. AudioLDM: Text-to-Audio Generation with Latent Diffusion Models , url =. International Conference on Machine Learning,
-
[6]
Yuancheng Wang and Zeqian Ju and Xu Tan and Lei He and Zhizheng Wu and Jiang Bian and Sheng Zhao , bibsource =. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , editor =
2023
-
[7]
Audioeditor: A training-free diffusion-based audio editing framework , year =
Jia, Yuhang and Chen, Yang and Zhao, Jinghua and Zhao, Shiwan and Zeng, Wenjia and Chen, Yong and Qin, Yong , booktitle =. Audioeditor: A training-free diffusion-based audio editing framework , year =
-
[8]
Tango 2: Aligning diffusion-based text-to-audio generations through direct preference optimization , year =
Majumder, Navonil and Hung, Chia-Yu and Ghosal, Deepanway and Hsu, Wei-Ning and Mihalcea, Rada and Poria, Soujanya , booktitle =. Tango 2: Aligning diffusion-based text-to-audio generations through direct preference optimization , year =
-
[9]
Auffusion: Leveraging the power of diffusion and large language models for text-to-audio generation , year =
Xue, Jinlong and Deng, Yayue and Gao, Yingming and Li, Ya , journal =. Auffusion: Leveraging the power of diffusion and large language models for text-to-audio generation , year =
-
[10]
Flowedit: Inversion-free text-based editing using pre-trained flow models , year =
Kulikov, Vladimir and Kleiner, Matan and Huberman-Spiegelglas, Inbar and Michaeli, Tomer , booktitle =. Flowedit: Inversion-free text-based editing using pre-trained flow models , year =
-
[11]
Audiocaps: Generating captions for audios in the wild,
Kim, Chris Dongjoo and Kim, Byeongchang and Lee, Hyunmin and Kim, Gunhee , booktitle =. doi:10.18653/v1/N19-1011 , editor =
-
[12]
doi:10.1109/ICASSP49357.2023.10095889 , abstract =
Yusong Wu and Ke Chen and Tianyu Zhang and Yuchen Hui and Taylor Berg. Large-Scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation , url =. doi:10.1109/ICASSP49357.2023.10095969 , pages =
-
[13]
Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models , url =
Rongjie Huang and Jiawei Huang and Dongchao Yang and Yi Ren and Luping Liu and Mingze Li and Zhenhui Ye and Jinglin Liu and Xiang Yin and Zhou Zhao , bibsource =. Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models , url =. International Conference on Machine Learning,
-
[14]
Yaron Lipman and Ricky T. Q. Chen and Heli Ben. Flow Matching for Generative Modeling , url =. The Eleventh International Conference on Learning Representations,
-
[15]
InstructME: An Instruction Guided Music Edit Framework with Latent Diffusion Models , url =
Bing Han and Junyu Dai and Weituo Hao and Xinyan He and Dong Guo and Jitong Chen and Yuxuan Wang and Yanmin Qian and Xuchen Song , bibsource =. InstructME: An Instruction Guided Music Edit Framework with Latent Diffusion Models , url =. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence,
-
[16]
InstructSpeech: Following Speech Editing Instructions via Large Language Models , url =
Rongjie Huang and Ruofan Hu and Yongqi Wang and Zehan Wang and Xize Cheng and Ziyue Jiang and Zhenhui Ye and Dongchao Yang and Luping Liu and Peng Gao and Zhou Zhao , bibsource =. InstructSpeech: Following Speech Editing Instructions via Large Language Models , url =. Forty-first International Conference on Machine Learning,
-
[17]
Steermusic: Enhanced musical consistency for zero-shot text-guided and personalized music editing , volume =
Niu, Xinlei and Cheuk, Kin Wai and Zhang, Jing and Murata, Naoki and Lai, Chieh-Hsin and Mancusi, Michele and Choi, Woosung and Fabbro, Giorgio and Liao, Wei-Hsiang and Martin, Charles Patrick and others , booktitle =. Steermusic: Enhanced musical consistency for zero-shot text-guided and personalized music editing , volume =
-
[18]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis , url =
Patrick Esser and Sumith Kulal and Andreas Blattmann and Rahim Entezari and Jonas M. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis , url =. Forty-first International Conference on Machine Learning,
-
[19]
Classifier-Free Diffusion Guidance , url =
Ho, Jonathan and Salimans, Tim , journal =. Classifier-Free Diffusion Guidance , url =
-
[20]
Kevin Kilgour and Mauricio Zuluaga and Dominik Roblek and Matthew Sharifi , bibsource =. Fr. Interspeech 2019, 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 15-19 September 2019 , doi =
2019
-
[21]
Goodfellow and Wojciech Zaremba and Vicki Cheung and Alec Radford and Xi Chen , bibsource =
Tim Salimans and Ian J. Goodfellow and Wojciech Zaremba and Vicki Cheung and Alec Radford and Xi Chen , bibsource =. Improved Techniques for Training GANs , url =. Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain , editor =
2016
-
[22]
Image quality assessment: from error visibility to structural similarity , volume =
Wang, Zhou , journal =. Image quality assessment: from error visibility to structural similarity , volume =
-
[23]
Comparing individual means in the analysis of variance , year =
Tukey, John W , journal =. Comparing individual means in the analysis of variance , year =
-
[24]
DeepSeek-V3 Technical Report , url =
DeepSeek-AI , journal =. DeepSeek-V3 Technical Report , url =
-
[25]
AudioMorphix: Training-free audio editing with diffusion probabilistic models , url =
Liang, Jinhua and Chen, Yuanzhe and Yuan, Yi and Jia, Dongya and Zhuang, Xiaobin and Chen, Zhuo and Wang, Yuping and Wang, Yuxuan , journal =. AudioMorphix: Training-free audio editing with diffusion probabilistic models , url =
-
[26]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations , url =
Chenlin Meng and Yutong He and Yang Song and Jiaming Song and Jiajun Wu and Jun. SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations , url =. The Tenth International Conference on Learning Representations,
-
[27]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Inbar Huberman. An Edit Friendly. doi:10.1109/CVPR52733.2024.01185 , pages =
-
[28]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Ron Mokady and Amir Hertz and Kfir Aberman and Yael Pritch and Daniel Cohen. Null-text Inversion for Editing Real Images using Guided Diffusion Models , url =. doi:10.1109/CVPR52729.2023.00585 , pages =
-
[29]
SteerFlow: Steering Rectified Flows for Faithful Inversion-Based Image Editing , url =
Dao, Thinh and Wang, Zhen and Pham, Kien T and Chen, Long , journal =. SteerFlow: Steering Rectified Flows for Faithful Inversion-Based Image Editing , url =
-
[30]
Flowalign: Trajectory-regularized, inversion-free flow-based image editing , url =
Kim, Jeongsol and Hong, Yeobin and Park, Jonghyun and Ye, Jong Chul , journal =. Flowalign: Trajectory-regularized, inversion-free flow-based image editing , url =
-
[31]
Advances in text-guided 3D editing: a survey , volume =
Lu, Lihua and Li, Ruyang and Zhang, Xiaohui and Wei, Hui and Du, Guoguang and Wang, Binqiang , journal =. Advances in text-guided 3D editing: a survey , volume =
-
[32]
A survey of multimodal-guided image editing with text-to-image diffusion models , url =
Shuai, Xincheng and Ding, Henghui and Ma, Xingjun and Tu, Rongcheng and Jiang, Yu-Gang and Tao, Dacheng , journal =. A survey of multimodal-guided image editing with text-to-image diffusion models , url =
-
[33]
Diffusion model-based image editing: A survey , year =
Huang, Yi and Huang, Jiancheng and Liu, Yifan and Yan, Mingfu and Lv, Jiaxi and Liu, Jianzhuang and Xiong, Wei and Zhang, He and Cao, Liangliang and Chen, Shifeng , journal =. Diffusion model-based image editing: A survey , year =
-
[34]
Guiding audio editing with audio language model , url =
Lan, Zitong and Hao, Yiduo and Zhao, Mingmin , journal =. Guiding audio editing with audio language model , url =
-
[35]
WavCraft: Audio editing and generation with large language models , url =
Liang, Jinhua and Zhang, Huan and Liu, Haohe and Cao, Yin and Kong, Qiuqiang and Liu, Xubo and Wang, Wenwu and Plumbley, Mark D and Phan, Huy and Benetos, Emmanouil , journal =. WavCraft: Audio editing and generation with large language models , url =
-
[36]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , url =
Xingchao Liu and Chengyue Gong and Qiang Liu , bibsource =. Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , url =. The Eleventh International Conference on Learning Representations,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.