Reversible Foundations: Training a 120B Sparse MoE through State-Preserving Scaling
Pith reviewed 2026-06-27 22:53 UTC · model grok-4.3
The pith
A 120B sparse mixture-of-experts model can be trained end to end on a single eight-GPU node by growing it from a small dense seed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
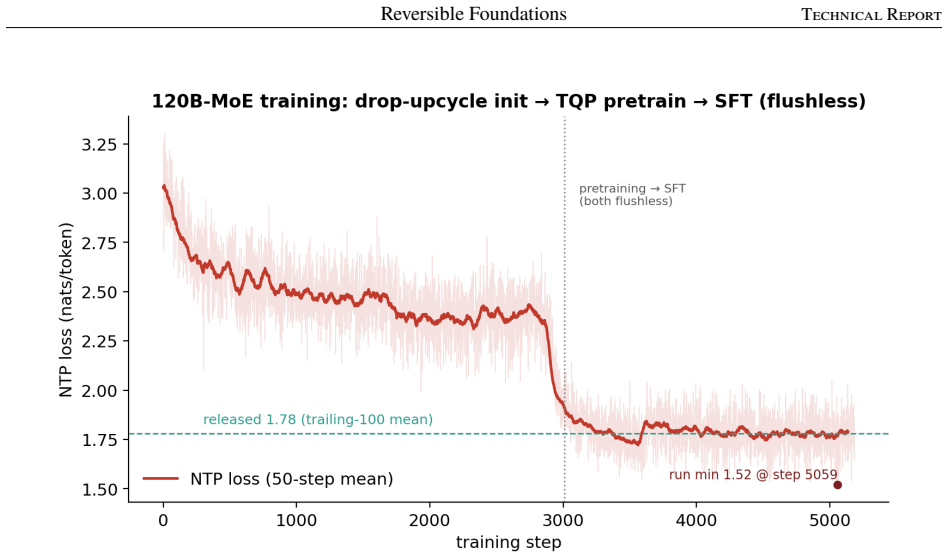
The central claim is that a full lineage of sparse MoE models can be grown on a single node from a dense 1.78B seed through 5B and 9B stages to a 120B model with 460 routed experts under top-12 routing, using reversible recurrence to hold activation memory constant, state-preserving expansion rules to avoid silent failures, and quantized base experts plus trained adapters to reduce optimizer state by a factor of roughly 45, reaching a released training loss of 1.78.
What carries the argument
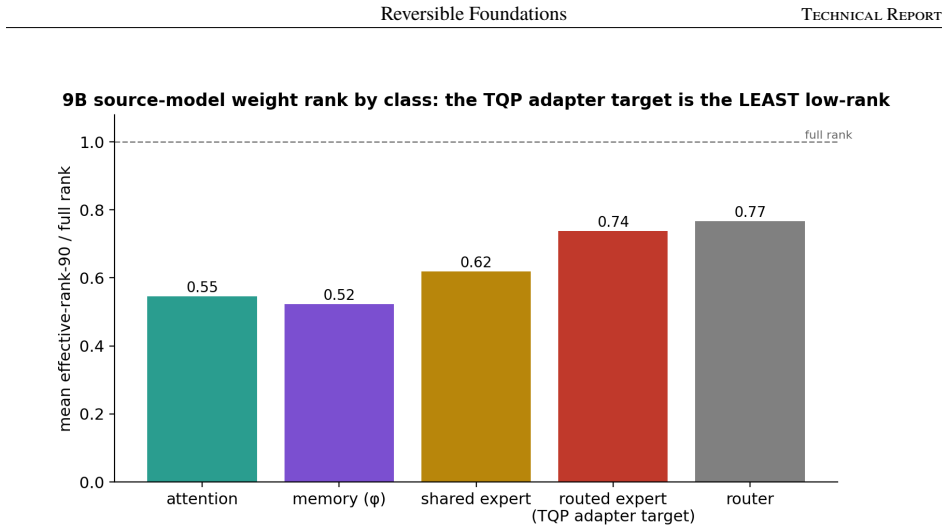
State-preserving growth: each expansion (dense to MoE, shallow to deep, few experts to many) is given as a reproducible principle paired with the failure that results from getting it wrong; reversible recurrence stack that reconstructs activations in the backward pass; TQP strategy of quantized base expert weights and trained low-rank adapters.
If this is right
- Active parameter count can rise monotonically across stages while total stored parameters reach 118.67B without exceeding single-node memory.
- Optimizer state can be carried on 2.26B adapter parameters rather than on the full routed experts.
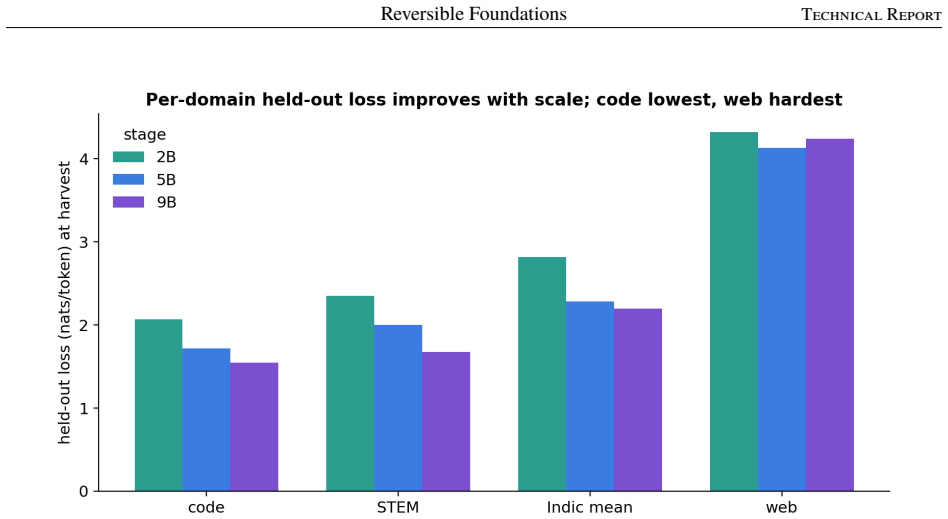
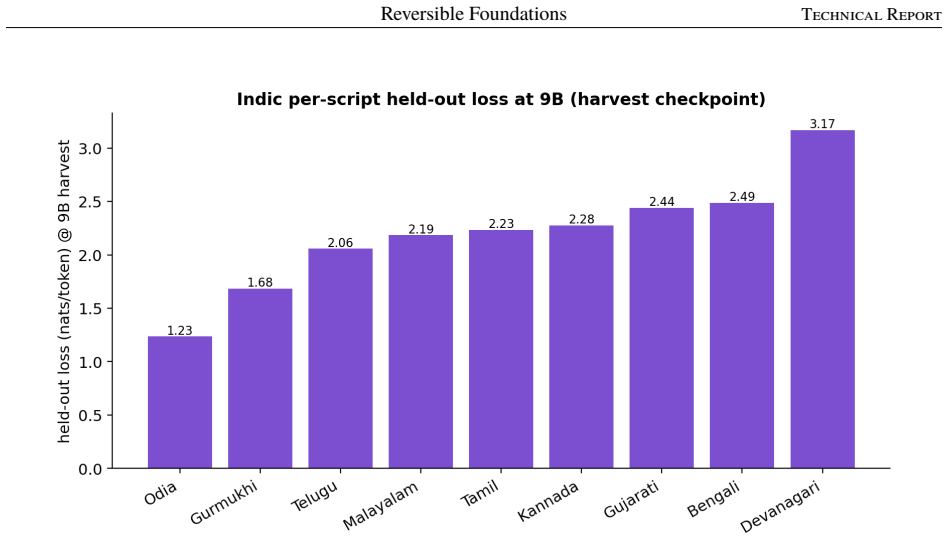
- Per-domain held-out loss can serve as evidence that multilingual Indic competence and code capabilities were learned by construction.
- The full training lineage, tokenizer, and code can be released for a 120B model trained at 8K context.
Where Pith is reading between the lines
- The same growth sequence might allow continued scaling beyond 120B on the same hardware if additional stages follow the same rules.
- The approach could be tested on non-recurrent backbones to check whether reversibility is required for the memory savings.
- Single-node economics might shift the feasible batch size or context length for future expansions.
Load-bearing premise
The state-preserving growth rules and reversible recurrence can be applied without introducing silent performance degradations that would invalidate the final loss and capability claims.
What would settle it
An observation that held-out per-domain loss rises sharply or targeted capabilities fail to appear during any growth stage, or a direct side-by-side run showing that the grown 120B model underperforms a model trained from random initialization at the same scale.
Figures
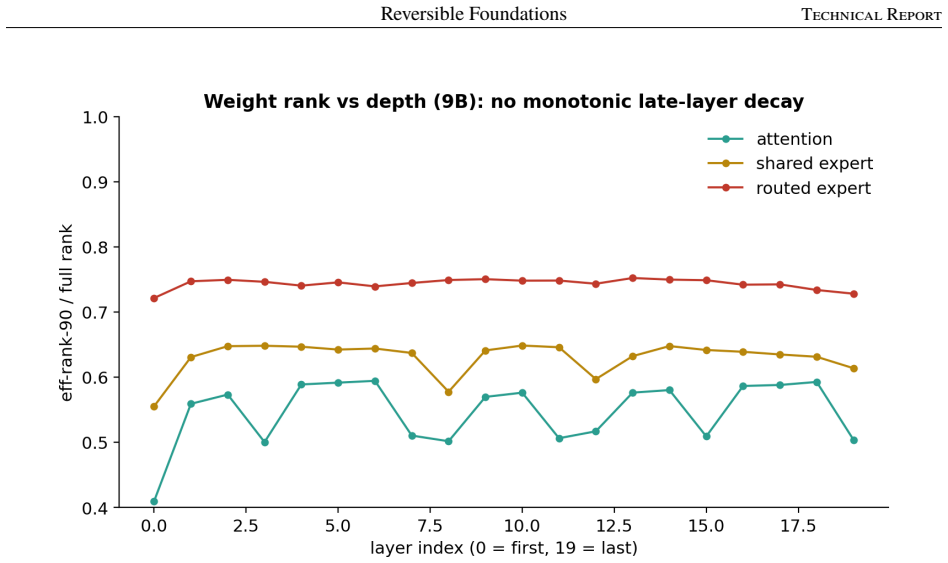
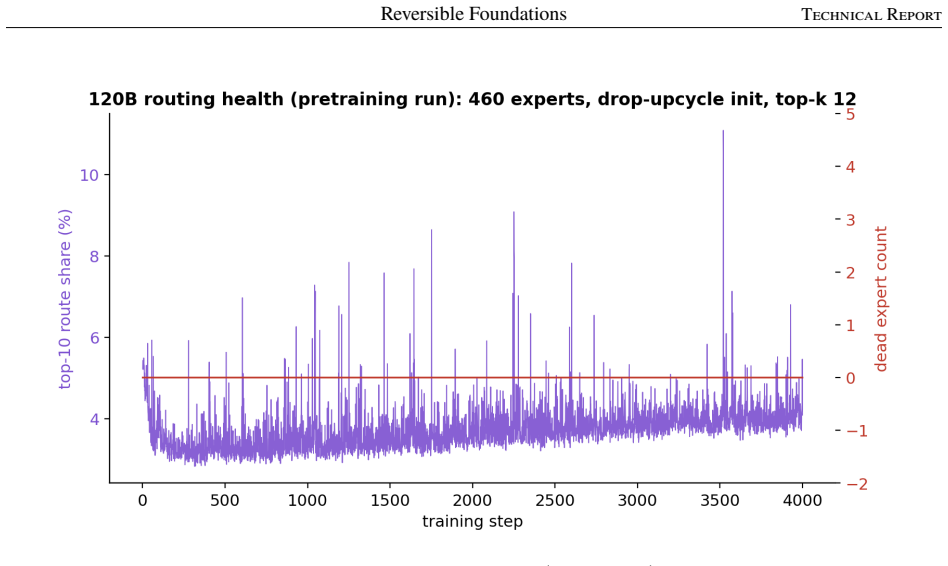
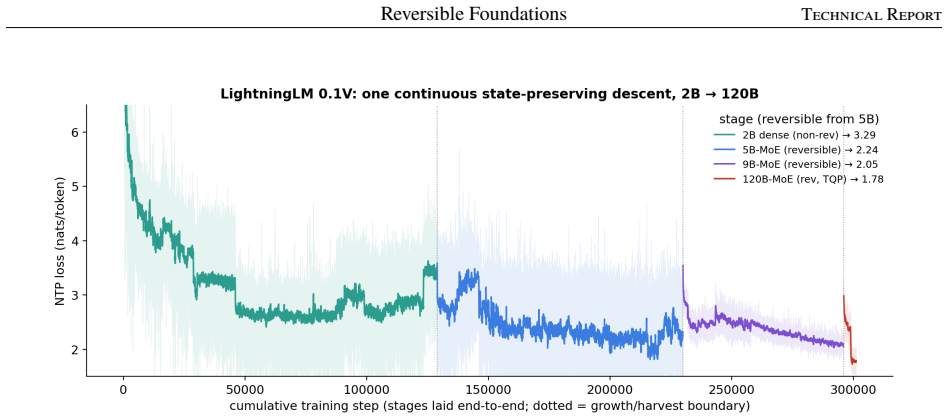
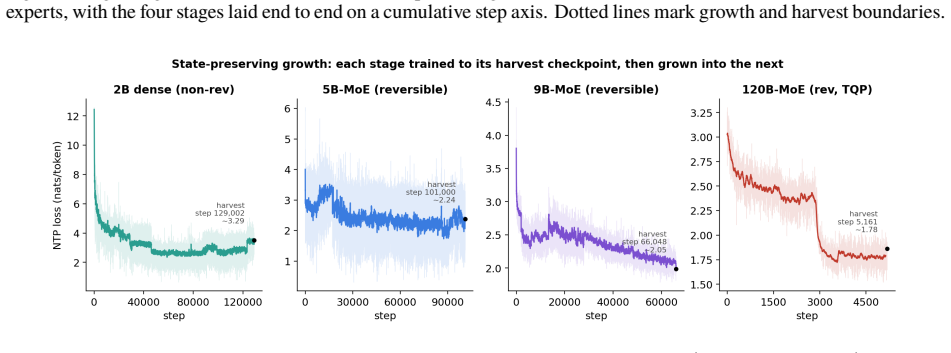
read the original abstract
This paper reports on training a hundred-billion-parameter sparse mixture of experts on a single eight-GPU node, end to end. LightningLM 0.1V is a recurrence-backbone language model family grown in four stages from a small dense seed, through a 5B and a 9B mixture of experts, to a 120B model with 460 routed experts under top-12 routing. Each larger model is grown from the trained weights of the smaller one; active parameters rise monotonically from 1.78B at the dense seed to 5.93B at 120B (about 5% of the 118.67B stored). The full lineage runs on single nodes, the larger stages at 8K context, reaching a released training loss of 1.78 at 120B scale. This is a systems and experience report. It is organized around three disciplines. Reversibility: a reversible recurrence stack reconstructs activations in the backward pass instead of storing them, holding activation memory flat as the model grows. State-preserving growth: each expansion (dense to MoE, shallow to deep, few experts to many) is given as a reproducible principle paired with the failure that results from getting it wrong; several failures are silent. Single-node economics: the 120B trains through TQP, a strategy of quantized base expert weights and trained low-rank adapters that carries optimizer state on 2.26B adapter parameters rather than 100B+ resident in routed experts, cutting expert-path optimizer state by a factor of ~45. What is new is the integration of known primitives, not any primitive in isolation: one grown lineage running end to end on a single node, documented at practitioner level, with per-domain held-out loss as evidence that targeted capabilities (multilingual Indic competence, code) were learned by construction. Model family, tokenizer, and training code are released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is an experience report describing the end-to-end training of LightningLM 0.1V, a 120B-parameter sparse MoE language model grown in four stages (dense seed o 5B MoE o 9B MoE o 120B MoE with 460 routed experts under top-12 routing) on a single 8-GPU node. Active parameters increase monotonically to 5.93B while total stored parameters reach 118.67B; reversibility keeps activation memory flat, state-preserving growth rules are claimed to avoid silent degradations, and TQP (quantized experts + low-rank adapters) reduces optimizer state. The lineage reaches a released training loss of 1.78 at 8K context; the model family, tokenizer, and code are released, with per-domain held-out loss offered as evidence of targeted capability acquisition.
Significance. If the central claims hold, the work shows that known primitives (reversible recurrence, careful staged expansion, and adapter-based optimizer compression) can be integrated to train a 120B-scale sparse model on single-node hardware while preserving state across growth steps. The artifact release and explicit documentation of failure modes add practical value for reproducibility in efficient large-model training.
major comments (1)
- [state-preserving growth] The state-preserving growth section describes reproducible principles and notes that incorrect growth produces silent failures, yet provides no controlled ablations or side-by-side comparisons (loss curves, downstream metrics, or intermediate-scale checkpoints) between models grown under the stated rules and otherwise identical models expanded by naive rules. This is load-bearing for the central claim that the final 1.78 loss and capability evidence reflect successful preservation rather than undetected degradation.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting the importance of the state-preserving growth methodology. We provide a point-by-point response to the major comment below.
read point-by-point responses
-
Referee: [state-preserving growth] The state-preserving growth section describes reproducible principles and notes that incorrect growth produces silent failures, yet provides no controlled ablations or side-by-side comparisons (loss curves, downstream metrics, or intermediate-scale checkpoints) between models grown under the stated rules and otherwise identical models expanded by naive rules. This is load-bearing for the central claim that the final 1.78 loss and capability evidence reflect successful preservation rather than undetected degradation.
Authors: We acknowledge that the manuscript does not include controlled ablations comparing state-preserving growth to naive expansion. As this is an experience report documenting an end-to-end training run on constrained hardware, the evidence presented is the successful training of the full lineage to a loss of 1.78, with released code and model allowing for reproduction and further experimentation by the community. The principles are accompanied by descriptions of the silent failures that occur when they are not followed, providing practical value. We believe this suffices for the scope of the paper, though we agree that ablations would be valuable in future work. No revision is planned for this aspect. revision: no
Circularity Check
No derivations or predictions present; report is empirical training account
full rationale
The manuscript is explicitly a systems and experience report on a training run and released artifacts. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The growth rules and reversibility are described as reproducible principles with noted failure modes, but these are presented as engineering choices supported by final held-out loss rather than any chain that reduces to its own inputs by construction. The reader's assessment of 0.0 circularity is consistent with the absence of any mathematical structure that could exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- top-12 routing
- 460 routed experts
axioms (2)
- domain assumption Reversible recurrence reconstructs activations without accuracy loss
- domain assumption State-preserving growth can be performed without silent failures
Reference graph
Works this paper leans on
-
[3]
2022 , eprint =
Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints , author =. 2022 , eprint =
2022
-
[7]
2024 , eprint =
Upcycling Large Language Models into Mixture of Experts , author =. 2024 , eprint =
2024
-
[9]
2026 , eprint =
The Depth Delusion: Why Transformers Should Be Wider, Not Deeper , author =. 2026 , eprint =
2026
-
[10]
2021 , eprint =
Linear Transformers Are Secretly Fast Weight Programmers , author =. 2021 , eprint =
2021
-
[11]
2024 , eprint =
Parallelizing Linear Transformers with the Delta Rule over Sequence Length , author =. 2024 , eprint =
2024
-
[12]
2025 , eprint =
Reversing Large Language Models for Efficient Training and Fine-Tuning , author =. 2025 , eprint =
2025
-
[14]
2020 , eprint =
Rajbhandari, Samyam and Rasley, Jeff and Ruwase, Olatunji and He, Yuxiong , booktitle =. 2020 , eprint =
2020
-
[15]
2024 , eprint =
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts , author =. 2024 , eprint =
2024
-
[18]
2025 , eprint =
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention , author =. 2025 , eprint =
2025
-
[19]
2026 , eprint =
Manifold-Constrained Hyper-Connections , author =. 2026 , eprint =
2026
-
[20]
2024 , eprint =
Hyper-Connections , author =. 2024 , eprint =
2024
-
[21]
Pacific Journal of Mathematics , volume =
Concerning nonnegative matrices and doubly stochastic matrices , author =. Pacific Journal of Mathematics , volume =
-
[22]
2020 , eprint =
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning , author =. 2020 , eprint =
2020
-
[25]
2024 , eprint =
Approaching Deep Learning through the Spectral Dynamics of Weights , author =. 2024 , eprint =
2024
-
[26]
2024 , eprint =
Weight decay induces low-rank attention layers , author =. 2024 , eprint =
2024
-
[33]
2025 , eprint =
Drop-Upcycling: Training Sparse Mixture of Experts with Partial Re-initialization , author =. 2025 , eprint =
2025
-
[36]
A. Aghajanyan, L. Zettlemoyer, and S. Gupta. Intrinsic dimensionality explains the effectiveness of language model fine-tuning, 2020. URL https://arxiv.org/abs/2012.13255. ACL 2021
arXiv 2020
- [37]
-
[38]
The depth delusion: Why transformers should be wider, not deeper, 2026
Fahim and Karim. The depth delusion: Why transformers should be wider, not deeper, 2026. URL https://arxiv.org/abs/2601.20994. Source of the active-path depth heuristic adopted in Section 3.5
arXiv 2026
-
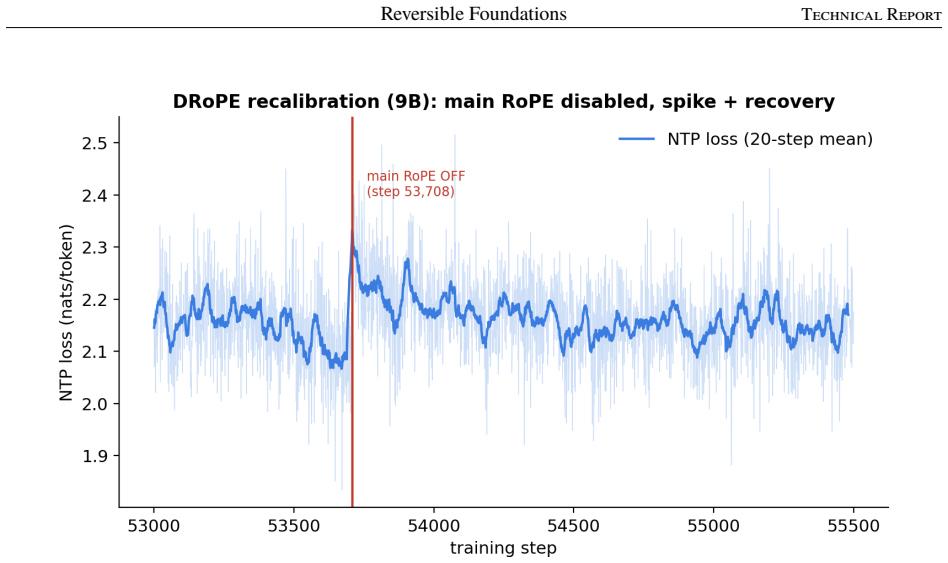
[39]
E. Gal, M. Eliasof, J. Turek, U. Ascher, E. Treister, and E. Haber. Reversing large language models for efficient training and fine-tuning, 2025. URL https://arxiv.org/abs/2512.02056. Source of the reversible-transformer construction adopted as the LightningLM 0.1V backbone; introduces the reversible midpoint stack and integrator and poses hundred-billion...
arXiv 2025
-
[40]
T. Galanti, Z. S. Siegel, A. Gupte, and T. Poggio. SGD and weight decay secretly minimize the rank of your neural network, 2022. URL https://arxiv.org/abs/2206.05794. Earlier versions titled ``SGD and Weight Decay Provably Induce a Low-Rank Bias in Neural Networks''; current canonical title used here
arXiv 2022
-
[41]
Y. Gelberg, R. Eguchi, T. Akiba, and E. Cetin. Extending the context of pretrained LLMs by dropping their positional embeddings, 2025. URL https://arxiv.org/abs/2512.12167. Code: https://github.com/SakanaAI/DroPE
arXiv 2025
-
[42]
Gemma 2 : Improving open language models at a practical size, 2024
Gemma Team, Google DeepMind . Gemma 2 : Improving open language models at a practical size, 2024. URL https://arxiv.org/abs/2408.00118. Technical report
Pith/arXiv arXiv 2024
-
[43]
F. Gloeckle, B. Y. Idrissi, B. Rozi \`e re, D. Lopez-Paz, and G. Synnaeve. Better & faster large language models via multi-token prediction. In International Conference on Machine Learning (ICML), 2024. URL https://arxiv.org/abs/2404.19737. Multi-token prediction as an auxiliary training objective; LightningLM uses a t+2 variant
Pith/arXiv arXiv 2024
-
[44]
E. He, A. Khattar, R. Prenger, V. Korthikanti, Z. Yan, T. Liu, S. Fan, A. Aithal, M. Shoeybi, and B. Catanzaro. Upcycling large language models into mixture of experts, 2024. URL https://arxiv.org/abs/2410.07524. NVIDIA. Introduces virtual-group initialization and weight scaling. Manuscript cites this as the Nemotron upcycling reference
arXiv 2024
-
[45]
A. Henry, P. R. Dachapally, S. Pawar, and Y. Chen. Query-key normalization for transformers. In Findings of the Association for Computational Linguistics: EMNLP, 2020. URL https://arxiv.org/abs/2010.04245. Origin of QKNorm; adopted by DroPE in the higher-learning-rate recalibration regime used in §5.3
arXiv 2020
-
[46]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. LoRA : Low-rank adaptation of large language models, 2021. URL https://arxiv.org/abs/2106.09685. ICLR 2022
Pith/arXiv arXiv 2021
- [47]
-
[48]
S. Kobayashi, Y. Akram, and J. von Oswald. Weight decay induces low-rank attention layers, 2024. URL https://arxiv.org/abs/2410.23819. NeurIPS 2024
arXiv 2024
-
[49]
A. Komatsuzaki, J. Puigcerver, J. Lee-Thorp, C. Riquelme Ruiz, B. Mustafa, J. Ainslie, Y. Tay, M. Dehghani, and N. Houlsby. Sparse upcycling: Training mixture-of-experts from dense checkpoints, 2022. URL https://arxiv.org/abs/2212.05055. ICLR 2023
arXiv 2022
- [50]
-
[51]
N. Liao, X. Wang, Z. Lin, W. Guo, F. Hong, et al. Innovator: Scientific continued pretraining with fine-grained MoE upcycling, 2025. URL https://arxiv.org/abs/2507.18671. Upcycles Qwen2.5-7B dense into fine-grained MoE
arXiv 2025
-
[52]
X. Meng, D. Dai, W. Luo, Z. Yang, S. Wu, X. Wang, P. Wang, Q. Dong, L. Chen, and Z. Sui. PeriodicLoRA : Breaking the low-rank bottleneck in LoRA optimization, 2024. URL https://arxiv.org/abs/2402.16141
arXiv 2024
-
[53]
T. Nakamura, T. Akiba, K. Fujii, Y. Oda, R. Yokota, and J. Suzuki. Drop-upcycling: Training sparse mixture of experts with partial re-initialization, 2025. URL https://arxiv.org/abs/2502.19261. ICLR 2025
arXiv 2025
-
[54]
OpenAI . GPT-4 technical report, 2023. URL https://arxiv.org/abs/2303.08774. Approximately 280 authors. Technical report
Pith/arXiv arXiv 2023
-
[55]
Qwen1.5-MoE : Matching 7B model performance with 1/3 activated parameters, 2024
Qwen Team . Qwen1.5-MoE : Matching 7B model performance with 1/3 activated parameters, 2024. URL https://qwenlm.github.io/blog/qwen-moe/. Official Qwen team blog post, 2024-03-28. No arXiv preprint
2024
-
[56]
H. Rajabzadeh, M. Valipour, T. Zhu, M. Tahaei, H. J. Kwon, A. Ghodsi, B. Chen, and M. Rezagholizadeh. QDyLoRA : Quantized dynamic low-rank adaptation for efficient large language model tuning, 2024. URL https://arxiv.org/abs/2402.10462. EMNLP 2024 Industry Track
arXiv 2024
-
[57]
S. Rajbhandari, J. Rasley, O. Ruwase, and Y. He. ZeRO : Memory optimizations toward training trillion parameter models. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC), 2020. URL https://arxiv.org/abs/1910.02054. Introduces the ZeRO sharding family (ZeRO-1/2/3) used throughout the Lightn...
Pith/arXiv arXiv 2020
- [58]
-
[59]
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In International Conference on Learning Representations (ICLR), 2017. URL https://arxiv.org/abs/1701.06538
Pith/arXiv arXiv 2017
-
[60]
R. Shravan. BrahmicTokenizer-131K : A 131 , 072 -token tokenizer for English and the major Brahmic scripts, 2026 a . URL https://arxiv.org/abs/2605.29379. Companion paper. Tokenizer used throughout the LightningLM 0.1V family
Pith/arXiv arXiv 2026
-
[61]
R. Shravan. Kronecker embeddings: Compressing token embedding tables by two orders of magnitude, 2026 b . URL https://arxiv.org/abs/2605.29459. Companion paper. Replaces standard learned embedding table with a Kronecker construction
Pith/arXiv arXiv 2026
-
[62]
Sinkhorn and P
R. Sinkhorn and P. Knopp. Concerning nonnegative matrices and doubly stochastic matrices. Pacific Journal of Mathematics, 21: 0 343--348, 1967
1967
-
[63]
OPUS : Towards efficient and principled data selection in LLM pre-training in every iteration, 2026
Wang et al. OPUS : Towards efficient and principled data selection in LLM pre-training in every iteration, 2026. URL https://arxiv.org/abs/2602.05400. SJTU EPIC Lab / Qwen Team, Alibaba. Source of the dynamic data selector amortized across the lineage
arXiv 2026
-
[64]
L. Wang, H. Gao, C. Zhao, X. Sun, and D. Dai. Auxiliary-loss-free load balancing strategy for mixture-of-experts, 2024. URL https://arxiv.org/abs/2408.15664. DeepSeek. Loss-free expert balancing via per-expert routing-logit bias; adopted across the LightningLM MoE family
Pith/arXiv arXiv 2024
-
[65]
Y. Weiss, D. D. Africa, P. Buttery, and R. Diehl Martinez. Investigating ReLoRA : Effects on the learning dynamics of small language models, 2025. URL https://arxiv.org/abs/2509.12960. Reports that merge-restart helps larger models but not capacity-limited small ones, consistent with the flush divergence at 120B reported here
arXiv 2025
-
[66]
C. Wu, Y. Gan, Y. Ge, Z. Lu, J. Wang, Y. Feng, Y. Shan, and P. Luo. LLaMA Pro : Progressive LLaMA with block expansion, 2024. URL https://arxiv.org/abs/2401.02415. ACL 2024 main conference
arXiv 2024
-
[67]
H. Wu, H. Chen, X. Chen, Z. Zhou, T. Chen, Y. Zhuang, G. Lu, Z. Huang, J. Zhao, L. Liu, Z. Lan, B. Yu, and J. Li. Grove MoE : Towards efficient and superior MoE LLMs with adjugate experts, 2025. URL https://arxiv.org/abs/2508.07785. Upcycles Qwen3-30B-A3B-Base into 33B MoE
arXiv 2025
-
[68]
Manifold-constrained hyper-connections, 2026
Xie, Wei, Cao, et al. Manifold-constrained hyper-connections, 2026. URL https://arxiv.org/abs/2512.24880. DeepSeek. Constrained variant of HyperConnections using Sinkhorn-Knopp normalization
Pith/arXiv arXiv 2026
-
[69]
S. Yang et al. Parallelizing linear transformers with the delta rule over sequence length, 2024. URL https://arxiv.org/abs/2406.06484. NeurIPS 2024. Gated parallel variant of the DeltaNet recurrence
arXiv 2024
-
[70]
J. Yuan, H. Gao, D. Dai, J. Luo, L. Zhao, Z. Zhang, Z. Xie, Y. X. Wei, L. Wang, Z. Xiao, Y. Wang, C. Ruan, M. Zhang, W. Liang, and W. Zeng. Native sparse attention: Hardware-aligned and natively trainable sparse attention, 2025. URL https://arxiv.org/abs/2502.11089. DeepSeek NSA. Learnable sparse attention with per-token block selection; used in the G-lay...
Pith/arXiv arXiv 2025
- [71]
-
[72]
A. Zandieh, M. Daliri, M. Hadian, and V. Mirrokni. TurboQuant : Online vector quantization with near-optimal distortion rate, 2025. URL https://arxiv.org/abs/2504.19874. ICLR 2026. The vector quantizer repurposed as the trainable base of the 120B expert stack (TQP)
Pith/arXiv arXiv 2025
-
[73]
D. Zhu, H. Huang, Z. Huang, Y. Zeng, Y. Mao, B. Wu, Q. Min, and X. Zhou. Hyper-connections, 2024. URL https://arxiv.org/abs/2409.19606. ByteDance
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.