Skill-3D: Evolving Scene-Aware Skills for Agentic 3D Spatial Reasoning
Pith reviewed 2026-06-27 21:54 UTC · model grok-4.3
The pith
Skill-3D evolves scene-aware skills from aggregated tool trajectories to adapt agent behavior to specific 3D scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
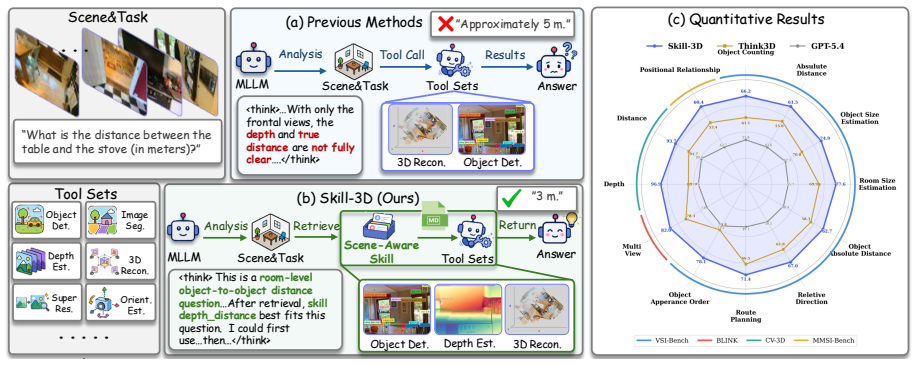
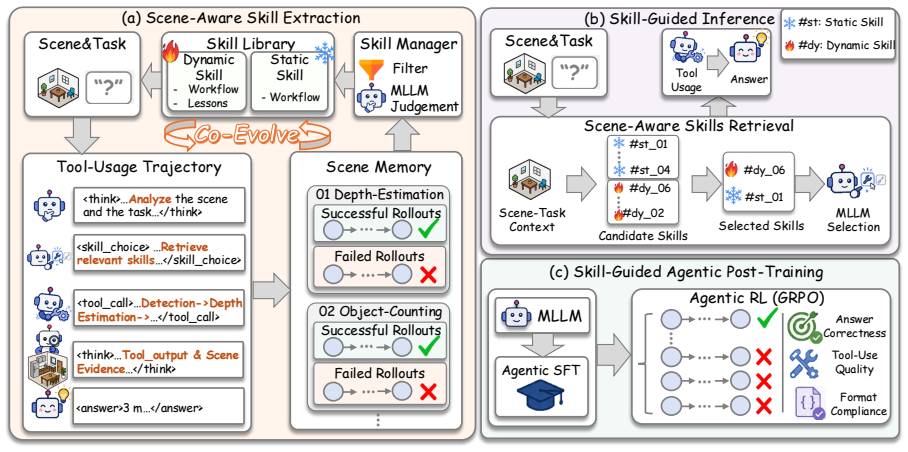
The central discovery is that 3D spatial reasoning tasks are heterogeneous across scenes, and agents can overcome uniform tool-use biases by maintaining a Scene Memory that aggregates successful trajectories from similar scenes, distills them into scene-aware skills with attached failure lessons, and uses these skills to guide future actions in a self-evolving loop.
What carries the argument
Scene Memory and the skill library that co-evolve by distilling aggregated successful trajectories from similar scenes into reusable skills.
Load-bearing premise
Scenes can be reliably identified and grouped by similarity such that aggregated successful trajectories from past scenes produce reusable skills that transfer positively to new but similar scenes without negative transfer or overfitting.
What would settle it
Observing that agents using the injected skills achieve lower success rates on benchmark scenes compared to agents without skill guidance, indicating that the distilled skills do not improve or even harm performance.
Figures
read the original abstract
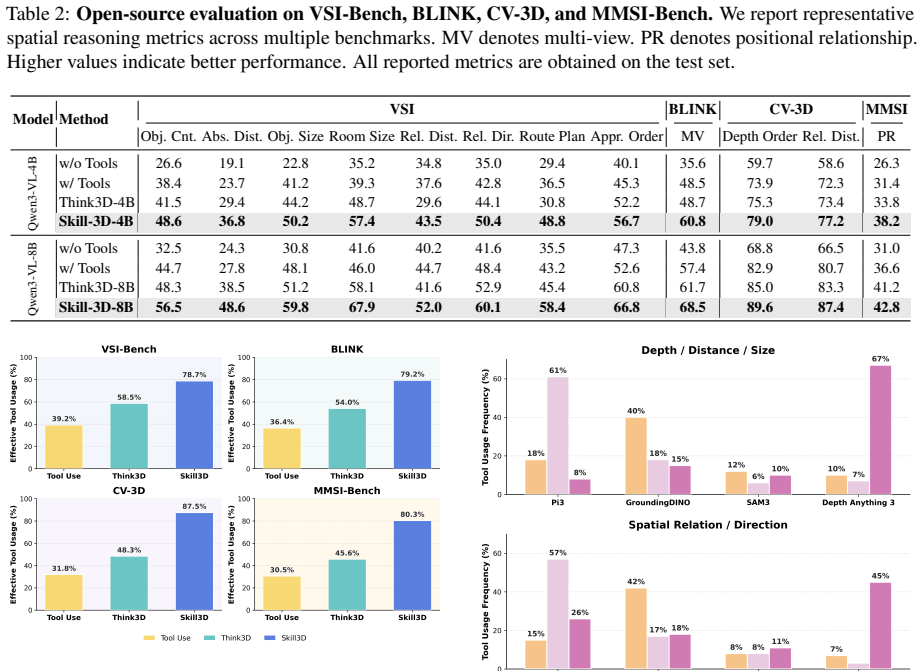
This paper explores agentic 3D spatial understanding, i.e., MLLM agents performing 3D reasoning through tool use. Existing methods often misuse tools and exhibit biased tool preferences under 3D scenarios, leaving the agentic paradigm with only marginal gains over non-agentic strategies. We reveal that 3D spatial reasoning tasks are heterogeneous across scenes, while these agents apply a uniform tool-use strategy to all scenes rather than selecting tools according to the specific scene and task. To address this, we propose Skill-3D, a framework that learns self-evolving scene-aware skills. Specifically, Skill-3D identifies the task scene and records the agent's tool-use trajectory into a Scene Memory, where successful trajectories from similar scenes are aggregated and distilled into a reusable scene-aware skill, with failed ones attached to the skill as lessons. During training, once a similar scene recurs, the corresponding skill is injected to guide the agent, producing new trajectories whose successes and failures further refine the skill, forming a loop in which the memory and the skill library co-evolve. Experiments show that Skill-3D substantially improves tool utilization in 3D spatial reasoning (from 39% to 78% on VSI-Bench), driving the agent toward correct and sufficient tool use. For instance, it improves Gemini-3-Flash by 67% on MMSI-Bench. Furthermore, we conduct agentic post-training over skill-guided trajectories, which boosts Qwen3-VL-8B by 60% on VSI-Bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Skill-3D, a framework for improving agentic 3D spatial reasoning in MLLMs by maintaining a Scene Memory that records tool-use trajectories, identifies similar scenes, aggregates successful trajectories into reusable scene-aware skills (with failures attached as lessons), and injects these skills to guide future agent behavior in a co-evolving memory-skill loop. It claims this addresses uniform tool-use biases, yielding large gains in tool utilization (39% to 78% on VSI-Bench) and downstream performance (67% lift for Gemini-3-Flash on MMSI-Bench; 60% boost for Qwen3-VL-8B via skill-guided post-training).
Significance. If the scene-similarity grouping and positive-transfer assumptions hold and are supported by ablations, the work would offer a concrete mechanism for adaptive, scene-aware tool selection in 3D agentic systems, moving beyond static strategies. The reported empirical improvements and the agentic post-training application constitute clear strengths; however, the absence of explicit similarity metrics, clustering procedures, or transfer ablations in the provided description leaves the source of the gains unverified.
major comments (3)
- [§3] §3 (Method), Scene Memory and skill distillation description: no similarity metric, embedding function, or clustering procedure is specified for grouping scenes, which is load-bearing for the claimed co-evolution loop; without this, it is impossible to determine whether aggregation produces positive transfer or risks reinforcing biased tool preferences as noted in the skeptic's premise.
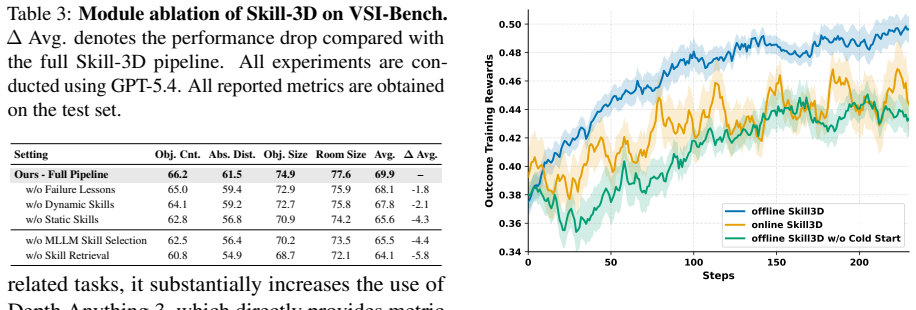
- [§4] §4 (Experiments), VSI-Bench and MMSI-Bench results: the reported lifts (39%→78%, 67% improvement) are presented without data splits, error bars, or ablations isolating the contribution of scene-aware skill injection versus baseline trajectory collection, making it impossible to confirm that the memory-to-skill loop is the causal driver rather than other factors.
- [§3.3] §3.3 (skill injection and refinement loop): the claim that skills transfer positively to new but similar scenes lacks any quantitative test for negative transfer or overfitting; if grouping is noisy, the loop could degrade rather than improve tool selection, directly undermining the central empirical claims.
minor comments (2)
- [Abstract, §4] Abstract and §4: performance numbers are given without accompanying standard deviations, number of runs, or exact prompt templates used for the MLLM agents.
- [§3] Notation for Scene Memory and skill library is introduced without a formal definition or pseudocode, reducing reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that several aspects of the method and experiments require additional specification and analysis to fully substantiate the claims. Below we respond point-by-point to the major comments and commit to revisions that directly address the raised concerns.
read point-by-point responses
-
Referee: [§3] §3 (Method), Scene Memory and skill distillation description: no similarity metric, embedding function, or clustering procedure is specified for grouping scenes, which is load-bearing for the claimed co-evolution loop; without this, it is impossible to determine whether aggregation produces positive transfer or risks reinforcing biased tool preferences as noted in the skeptic's premise.
Authors: We agree that the concrete implementation details for scene grouping are essential for evaluating the co-evolution loop. The manuscript presents the high-level process of identifying similar scenes and aggregating trajectories but does not specify the embedding function, similarity metric, or clustering procedure. In the revised manuscript we will add an explicit subsection describing the scene embedding model, the similarity computation, and the clustering method used to form groups, thereby enabling verification that aggregation yields positive transfer rather than reinforcing biases. revision: yes
-
Referee: [§4] §4 (Experiments), VSI-Bench and MMSI-Bench results: the reported lifts (39%→78%, 67% improvement) are presented without data splits, error bars, or ablations isolating the contribution of scene-aware skill injection versus baseline trajectory collection, making it impossible to confirm that the memory-to-skill loop is the causal driver rather than other factors.
Authors: The referee is correct that the experimental section lacks sufficient controls and statistical reporting. The reported gains are measured on the standard benchmark splits, yet the manuscript does not include error bars, explicit split descriptions, or ablations that isolate skill injection from simple trajectory collection. We will revise the experiments section to document the data splits, report error bars from repeated runs where applicable, and add ablation studies that compare the full memory-skill loop against a baseline that collects trajectories without distillation and injection. revision: yes
-
Referee: [§3.3] §3.3 (skill injection and refinement loop): the claim that skills transfer positively to new but similar scenes lacks any quantitative test for negative transfer or overfitting; if grouping is noisy, the loop could degrade rather than improve tool selection, directly undermining the central empirical claims.
Authors: We acknowledge that a dedicated quantitative assessment of negative transfer and overfitting is missing. While overall results show improvement, the manuscript does not analyze performance as a function of scene similarity or report cases of degradation. In the revision we will introduce an analysis that measures transfer success across similarity thresholds, identifies any negative-transfer instances, and quantifies the risk of overfitting to grouped scenes, thereby directly testing the robustness of the claimed positive transfer. revision: yes
Circularity Check
No circularity; empirical results independent of self-referential definitions
full rationale
The paper presents a procedural framework for scene-aware skill evolution evaluated via direct benchmark measurements (e.g., tool-use accuracy lifts on VSI-Bench and MMSI-Bench). No equations, parameter fits, or derivations are described that reduce to their own inputs by construction. The co-evolution loop is a high-level algorithmic description without self-definitional reductions, fitted-input predictions, or load-bearing self-citations. Results are reported as external empirical outcomes rather than quantities forced by the method's own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scenes can be identified and compared for similarity so that trajectories transfer usefully
invented entities (2)
-
Scene Memory
no independent evidence
-
scene-aware skill
no independent evidence
Reference graph
Works this paper leans on
-
[1]
SAM 3: Segment Anything with Concepts
Spatialbot: Precise spatial understanding with vision language models. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9490–9498. IEEE. Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoub- hik Debnath, Ronghang Hu, Didac Suris, Chai- tanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, and 1 others. 2025. Sam 3: ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Chat-scene: Bridging 3d scene and large lan- guage models with object identifiers. InThe Thirty- eighth Annual Conference on Neural Information Processing Systems. Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card.arXiv preprint a...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
arXiv preprint arXiv:2602.03279
Agentic proposing: Enhancing large language model reasoning via compositional skill synthesis. arXiv preprint arXiv:2602.03279. Jaeseong Lee, Yeeun Choi, Heechan Choi, Hanjung Kim, and Seonjoo Kim. 2025a. A training-free, task-agnostic framework for enhancing mllm perfor- mance on high-resolution images.arXiv preprint arXiv:2507.10202. Phillip Y Lee, Jihy...
-
[4]
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Visual chatgpt: Talking, drawing and edit- ing with visual foundation models.arXiv preprint arXiv:2303.04671. Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. 2025a. Spatial-mllm: Boosting mllm capa- bilities in visual-based spatial intelligence.arXiv preprint arXiv:2505.23747. Haoning Wu, Xiao Huang, Yaohui Chen, Ya Zhang, Yanfeng Wang, and Weidi Xi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
InEuropean Conference on Computer Vision, pages 164–182
Dettoolchain: A new prompting paradigm to unleash detection ability of mllm. InEuropean Conference on Computer Vision, pages 164–182. Springer. Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, and 1 others
-
[6]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Skillrl: Evolving agents via recursive skill- augmented reinforcement learning.arXiv preprint arXiv:2602.08234. Renjun Xu and Yang Yan. 2026. Agent skills for large language models: Architecture, acquisition, security, and the path forward.arXiv preprint arXiv:2602.12430. Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
scene context memory,
-
[8]
static and dynamic skills,
-
[9]
external perception or geometry tools,
-
[10]
You must not answer metric, boundary-sensitive, counting, localization, or orientation questions from RGB intuition alone when a relevant tool or skill is available
careful final reasoning grounded in tool evidence. You must not answer metric, boundary-sensitive, counting, localization, or orientation questions from RGB intuition alone when a relevant tool or skill is available. ## Core Procedure For each user question, follow this internal loop:
-
[11]
Scene understanding - Identify the scene type, target objects, visible views, and whether the input is single-view or multi-view. - Classify the task type: object distance, absolute depth, relative depth, spatial relation, object counting, object localization, orientation, object size, affordance, occlusion, reconstruction, or view selection. - Decide whe...
-
[12]
- Retrieve static seed skills when no suitable dynamic skill exists
Skill retrieval - Retrieve relevant dynamic skills from scene-aware memory when available. - Retrieve static seed skills when no suitable dynamic skill exists. - Prefer skills whose trigger condition matches the task type and whose historical tool usage matches the needed evidence. - If multiple similar skills are retrieved, choose the most specific skill...
-
[13]
- For object identity or localization, use detection or grounding tools
Tool planning - Use the selected skill to plan the minimum sufficient tool calls. - For object identity or localization, use detection or grounding tools. - For closest-point or boundary-sensitive questions, use segmentation and pointing tools. - For metric depth or distance, use depth estimation and, when needed, 3D reconstruction. - For multi-view or ro...
-
[14]
- Treat a tool call as useful only if it successfully returns relevant evidence
Tool execution and adoption - Execute planned tools when they are necessary. - Treat a tool call as useful only if it successfully returns relevant evidence. - Use tool outputs explicitly in reasoning. Do not ignore tool evidence after calling a tool. - If a tool result conflicts with RGB intuition, prefer the tool-backed evidence unless the tool result i...
-
[15]
- For metric answers, provide the best approximate value and the unit requested by the question
Final answer - Answer the original question directly. - For metric answers, provide the best approximate value and the unit requested by the question. - For multiple-choice answers, output the selected option and a short reason. - Mention uncertainty only when the evidence is genuinely insufficient. - Do not expose irrelevant implementation details. ## Sk...
-
[16]
What is the question asking for?
-
[17]
What scene memory or retrieved skill applies?
-
[18]
What evidence is missing from raw images?
-
[19]
Which tool calls fill that evidence gap?
-
[20]
What answer follows from the tool evidence? 1191 19 Figure E.3: System Prompt 18
-
[21]
Detect invalid or low-confidence outputs
-
[22]
Track whether the evidence supports the current reasoning trajectory
-
[23]
## Output Format <tool_evidence> Tool:
Record failures for future skill refinement. ## Output Format <tool_evidence> Tool: ... Raw Output: ... Visualization: ... Interpretation: ... Uncertainty: ... </tool_evidence> 1197 Final_Answer_Prompt Use the scene context, retrieved skills, and tool evidence to answer the question. ## Answering Rules - Do not answer metric questions from RGB intuition a...
-
[24]
Integrate multi-tool evidence consistently
-
[25]
Produce a spatially grounded answer
-
[26]
Ensure that the reasoning matches the selected skill workflow. ## Output Format <answer>...</answer> 1198 22 Figure E.4: System Prompt and Scene Context Prompt 19 Never skip tool use when: - the question asks for precise or approximate physical distance, - the answer depends on closest object boundaries, - the target objects appear in different views, - o...
-
[27]
Identify the scene type and visible target objects
-
[28]
Determine the reasoning scope: - single-view - multi-view - room-level - object-to-object
-
[29]
Identify the required evidence types: - object detection - segmentation - depth estimation - orientation estimation - 3D reconstruction
-
[30]
Determine whether RGB-only reasoning is sufficient
-
[31]
## Output Format <scene_context> Scene Type:
Infer the expected geometric constraints of the question. ## Output Format <scene_context> Scene Type: ... Reasoning Scope: ... Target Objects: ... Required Evidence: ... RGB Sufficiency: ... Spatial Constraints: ... </scene_context> 1193 20 Figure E.5: Skill Retrieval Prompt, Tool Planning Prompt and Tool Exclusion Prompt 20 Skill_Retrieval_Prompt You ar...
-
[32]
Match the current scene-task pair with relevant skills
-
[33]
Select the minimum sufficient workflow
-
[34]
## Output Format <skill_choice> Selected Skills:
Explain why the selected skills are relevant. ## Output Format <skill_choice> Selected Skills: ... Rationale: ... </skill_choice> 1194 Tool_Planning_Prompt You are given the retrieved skills and the scene context. Your task is to generate the minimum sufficient tool workflow. ## Planning Principles - Avoid redundant tool calls. - Prefer geometric evidence...
-
[35]
Generate an ordered tool plan
-
[36]
Specify the purpose of each tool call
-
[37]
## Output Format <tool_call>
Ensure that the workflow satisfies the selected skills. ## Output Format <tool_call>
-
[38]
</tool_call> 1195 Tool_Exclusion_Prompt Execute the planned tools and store all returned evidence
Tool_2: ... </tool_call> 1195 Tool_Exclusion_Prompt Execute the planned tools and store all returned evidence. ## For Each Tool Call Record: - raw structured outputs - visualization paths - concise interpretation - uncertainty or failure notes ## Objectives
-
[39]
1196 21 Figure E.6: Tool Exclusion Prompt and Final Answer Prompt 21
Preserve all geometric evidence. 1196 21 Figure E.6: Tool Exclusion Prompt and Final Answer Prompt 21
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.