Bradley-Terry Rankings for Recommender Systems Across Dataset Taxonomies
Pith reviewed 2026-06-27 20:24 UTC · model grok-4.3
The pith
Bradley-Terry models produce dataset-aware rankings of recommendation algorithms that generalize to new data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The ranking of recommendation algorithms obtained via the Bradley-Terry model depends on key dataset statistics, and extensions of the framework allow ranking algorithms on unseen datasets without executing the models.
What carries the argument
Bradley-Terry model applied to pairwise algorithm performance comparisons, extended via BT trees and models with covariates to incorporate dataset statistics.
If this is right
- Rankings of algorithms become sensitive to measurable dataset characteristics rather than remaining uniform across benchmarks.
- A dedicated metric quantifies how consistent the derived rankings are across different data subsets.
- The procedure tolerates incomplete pairwise comparison data without large changes in the final order.
- Algorithm rankings for previously unseen datasets can be produced from dataset statistics alone using BT trees or covariate models.
Where Pith is reading between the lines
- Dataset taxonomies could be built directly from the statistics that most strongly shift the BT rankings.
- Selection of models for production systems might shift from running full benchmarks to computing a small set of dataset descriptors.
- The same pairwise modeling approach could be tested on ranking tasks outside recommender systems, such as classifier selection.
Load-bearing premise
Pairwise comparisons of algorithm performance on datasets can be validly modeled by the Bradley-Terry framework and the chosen dataset statistics capture the factors driving performance differences.
What would settle it
A collection of new datasets where the BT-predicted ranking order disagrees with the order obtained by actually running every algorithm and measuring performance.
Figures

read the original abstract
The ranking of recommendation algorithms is a challenging problem since model performance is sensitive to dataset characteristics such as sparsity, sequential structure, and scale. This drives a demand for a proper methodology for fair comparison between algorithms. Naive aggregation of performance metrics (e.g., averaging NDCG over benchmarks) can yield misleading rankings, undermining practical selection. To address this problem, we introduce a novel, data-driven ranking methodology based on Bradley-Terry (BT) model. We demonstrate that the obtained ranking depends on key dataset statistics. Additionally, we propose a novel metric for evaluating ranking consistency and demonstrate robustness of our ranking to incomplete data. Finally, we introduce a dataset-specific methodology for ranking algorithms on unseen datasets without running the models, relying on extensions of the Bradley-Terry framework, including BT trees and BT models with covariates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Bradley-Terry (BT) model-based methodology for ranking recommender system algorithms that accounts for dataset characteristics such as sparsity, sequential structure, and scale. It claims that the derived rankings depend on these key statistics, proposes a novel metric for evaluating ranking consistency, demonstrates robustness to incomplete data, and extends the BT framework (via BT trees and models with covariates) to enable ranking algorithms on unseen datasets without executing the models.
Significance. If the central claims hold, the work could provide a principled alternative to naive metric aggregation for algorithm comparison across heterogeneous datasets, with practical value for selecting models on new data. The extension to covariate-adjusted BT models for zero-shot ranking on unseen datasets is potentially impactful if the chosen statistics prove sufficient, but this requires strong empirical support that is not verifiable from the abstract alone.
major comments (2)
- [Section describing BT models with covariates / unseen dataset methodology] The load-bearing claim for the dataset-specific methodology on unseen datasets (BT models with covariates and BT trees) requires that the selected dataset statistics suffice as covariates to capture performance drivers. The manuscript must include ablation or sensitivity analyses showing that predictions generalize beyond the fitted data and are not undermined by unmodeled factors (e.g., domain-specific distributions). Without this, the extension reduces to an unvalidated assumption.
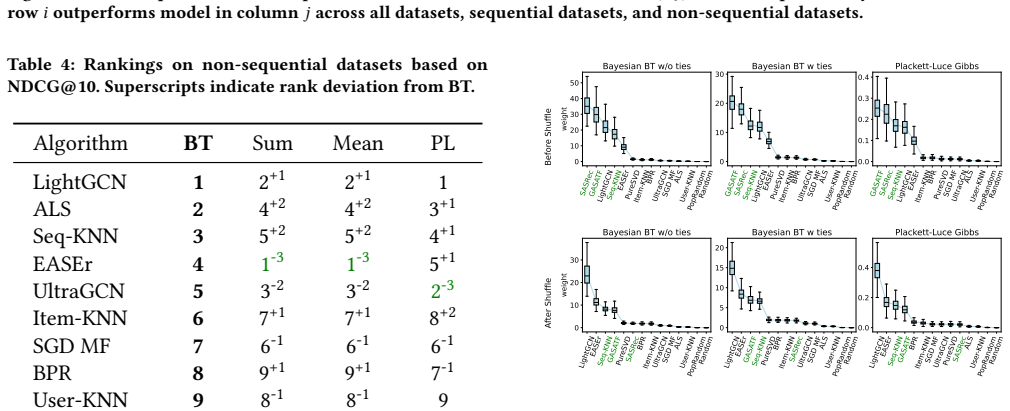
- [Results section on ranking dependence on dataset statistics] The demonstration that obtained rankings depend on key dataset statistics needs explicit quantification (e.g., via regression coefficients or ranking shifts in tables) rather than qualitative statements; otherwise the dependence claim lacks load-bearing evidence.
minor comments (2)
- [Metric definition] Clarify the exact form of the consistency metric and how it is computed from pairwise BT outcomes.
- [Covariate selection] Provide the full set of dataset statistics used as covariates and justify their selection with references to prior recsys literature on performance factors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the empirical support and clarity of our claims.
read point-by-point responses
-
Referee: [Section describing BT models with covariates / unseen dataset methodology] The load-bearing claim for the dataset-specific methodology on unseen datasets (BT models with covariates and BT trees) requires that the selected dataset statistics suffice as covariates to capture performance drivers. The manuscript must include ablation or sensitivity analyses showing that predictions generalize beyond the fitted data and are not undermined by unmodeled factors (e.g., domain-specific distributions). Without this, the extension reduces to an unvalidated assumption.
Authors: We agree that the generalization capability of the BT models with covariates and BT trees requires stronger empirical validation to confirm that the chosen dataset statistics adequately capture performance drivers. In the revised manuscript, we will add ablation studies that systematically remove or perturb individual covariates and measure out-of-sample prediction accuracy on held-out datasets. We will also include sensitivity analyses that evaluate prediction performance across different data domains to quantify the effect of potential unmodeled factors. These additions will directly address the concern and provide the necessary evidence for the zero-shot ranking methodology. revision: yes
-
Referee: [Results section on ranking dependence on dataset statistics] The demonstration that obtained rankings depend on key dataset statistics needs explicit quantification (e.g., via regression coefficients or ranking shifts in tables) rather than qualitative statements; otherwise the dependence claim lacks load-bearing evidence.
Authors: We acknowledge that the current description of ranking dependence on dataset statistics is primarily qualitative. To provide explicit, load-bearing evidence, we will revise the results section to include tables reporting the estimated coefficients from the Bradley-Terry models for each key statistic (sparsity, sequential structure, and scale). We will also add quantitative examples of ranking shifts observed when varying these statistics, such as changes in algorithm positions across different sparsity levels. This will make the dependence claim more rigorous and verifiable. revision: yes
Circularity Check
No significant circularity; standard BT application with independent statistical extensions
full rationale
The provided abstract and claims describe application of the established Bradley-Terry model to derive rankings from pairwise algorithm comparisons on datasets, with dependence on statistics like sparsity shown empirically rather than by definitional reduction. Extensions to BT trees and covariate models are standard and not shown to reduce to fitted parameters by construction or via self-citation chains. No equations, self-citations, or ansatzes are quoted that force the central claims (e.g., unseen-dataset prediction) to equal their inputs. The derivation chain is therefore self-contained against external benchmarks like the BT literature.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. 2019. Optuna: A Next-generation Hyperparameter Optimization Framework. InProceedings of the 25th ACM SIGKDD International Confer- ence on Knowledge Discovery & Data Mining(Anchorage, AK, USA)(KDD ’19). Association for Computing Machinery, New York, NY, USA, 2623–2631. doi:10.1...
-
[2]
Alessio Benavoli, Giorgio Corani, Janez Demšar, and Marco Zaffalon. 2017. Time for a Change: a Tutorial for Comparing Multiple Classifiers Through Bayesian Analysis.Journal of Machine Learning Research18, 77 (2017), 1–36. http://jmlr. org/papers/v18/16-305.html
2017
-
[3]
Ralph Allan Bradley and Milton E Terry. 1952. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika39, 3/4 (1952), 324–345
1952
-
[4]
Francois Caron and Arnaud Doucet. 2012. Efficient Bayesian inference for gener- alized Bradley–Terry models.Journal of Computational and Graphical Statistics 21, 1 (2012), 174–196. KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Grishina et al
2012
-
[5]
Giuseppe Casalicchio, Gerhard Tutz, and Gunther Schauberger. 2015. Subject- specific Bradley–Terry–Luce models with implicit variable selection.Statistical Modelling15, 6 (2015), 526–547
2015
-
[6]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E Gonzalez, et al. 2024. Chatbot arena: An open platform for evaluating llms by human preference.arXiv preprint arXiv:2403.04132(2024)
Pith/arXiv arXiv 2024
-
[7]
Paolo Cremonesi, Yehuda Koren, and Roberto Turrin. 2010. Performance of recommender algorithms on top-n recommendation tasks. InProceedings of the Fourth ACM Conference on Recommender Systems(Barcelona, Spain)(RecSys ’10). Association for Computing Machinery, New York, NY, USA, 39–46. doi:10.1145/ 1864708.1864721
arXiv 2010
-
[8]
Roger R Davidson. 1970. On extending the Bradley-Terry model to accommodate ties in paired comparison experiments.J. Amer. Statist. Assoc.65, 329 (1970), 317–328
1970
-
[9]
Gerard Debreu. 1960. Individual choice behavior: A theoretical analysis
1960
-
[10]
Janez Demšar. 2006. Statistical Comparisons of Classifiers over Multiple Data Sets.Journal of Machine Learning Research7, 1 (2006), 1–30. http://jmlr.org/ papers/v7/demsar06a.html
2006
-
[11]
Jianqing Fan, Jikai Hou, and Mengxin Yu. 2024. Uncertainty quantification of MLE for entity ranking with covariates.Journal of Machine Learning Research 25, 358 (2024), 1–83
2024
-
[12]
Evgeny Frolov and Ivan Oseledets. 2023. Tensor-Based Sequential Learning via Hankel Matrix Representation for Next Item Recommendations.IEEE Access11 (2023), 6357–6371. doi:10.1109/ACCESS.2023.3234863
-
[13]
Chao Gao, Yandi Shen, and Anderson Y Zhang. 2023. Uncertainty quantification in the Bradley–Terry–Luce model.Information and Inference: A Journal of the IMA12, 2 (2023), 1073–1140
2023
-
[14]
Pieter Gijsbers, Marcos LP Bueno, Stefan Coors, Erin LeDell, Sébastien Poirier, Janek Thomas, Bernd Bischl, and Joaquin Vanschoren. 2024. Amlb: an automl benchmark.Journal of Machine Learning Research25, 101 (2024), 1–65
2024
-
[15]
Mark E Glickman. [n. d.]. Paired comparison models with strength-dependent ties and order effects.Statistical Modelling([n. d.]), 1471082X251400474
-
[16]
Danil Gusak, Anna Volodkevich, Anton Klenitskiy, Alexey Vasilev, and Evgeny Frolov. 2025. Time to Split: Exploring Data Splitting Strategies for Offline Evalu- ation of Sequential Recommenders. InProceedings of the Nineteenth ACM Confer- ence on Recommender Systems (RecSys ’25). Association for Computing Machinery, New York, NY, USA, 874–883. doi:10.1145/...
-
[17]
Malay Haldar, Daochen Zha, Huiji Gao, Liwei He, and Sanjeev Katariya. 2025. Beyond Pairwise Learning-To-Rank At Airbnb. InProceedings of the 34th ACM International Conference on Information and Knowledge Management(Seoul, Re- public of Korea)(CIKM ’25). ACM, New York, NY, USA, 8 pages. doi:10.1145/ 3746252.3761521
arXiv 2025
-
[18]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, YongDong Zhang, and Meng Wang. 2020. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation(SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 639–648. doi:10.1145/3397271.3401063
-
[19]
Reinhard Heckel, Max Simchowitz, Kannan Ramchandran, and Martin Wain- wright. 2018. Approximate Ranking from Pairwise Comparisons. InProceedings of the Twenty-First International Conference on Artificial Intelligence and Sta- tistics (Proceedings of Machine Learning Research, Vol. 84), Amos Storkey and Fernando Perez-Cruz (Eds.). PMLR, 1057–1066. https://...
2018
-
[20]
Yifan Hu, Yehuda Koren, and Chris Volinsky. 2008. Collaborative filtering for implicit feedback datasets. In2008 Eighth IEEE international conference on data mining. Ieee, 263–272
2008
-
[21]
Wang-Cheng Kang and Julian McAuley. 2018. Self-Attentive Sequential Recom- mendation. InProceedings of the IEEE International Conference on Data Mining (ICDM). IEEE, 197–206
2018
-
[22]
Anton Klenitskiy, Anna Volodkevich, Anton Pembek, and Alexey Vasilev. 2024. Does it look sequential? an analysis of datasets for evaluation of sequential recommendations. InProceedings of the 18th ACM Conference on Recommender Systems. 1067–1072
2024
-
[23]
PS Kostenetskiy, RA Chulkevich, and VI Kozyrev. 2021. HPC resources of the higher school of economics. InJournal of Physics: Conference Series, Vol. 1740. IOP Publishing, 012050
2021
-
[24]
Kelong Mao, Jieming Zhu, Xi Xiao, Biao Lu, Zhaowei Wang, and Xiuqiang He
-
[25]
InProceedings of the 30th ACM international conference on information & knowledge management
UltraGCN: ultra simplification of graph convolutional networks for recom- mendation. InProceedings of the 30th ACM international conference on information & knowledge management. 1253–1262
-
[26]
Oseledets, and Evgeny Frolov
Gleb Mezentsev, Danil Gusak, Ivan V. Oseledets, and Evgeny Frolov. 2024. Scalable Cross-Entropy Loss for Sequential Recommendations with Large Item Catalogs. InProceedings of the 18th ACM Conference on Recommender Systems (RecSys). ACM, 475–485
2024
-
[27]
Frederick Mosteller. 1951. Remarks on the Method of Paired Comparisons: I. The Least Squares Solution Assuming Equal Standard Deviations and Equal Correlations.Psychometrika16, 1 (1951), 3–9
1951
-
[28]
Sewoong Oh. 2017. Rank centrality: Ranking from pairwise comparisons.Opera- tions research(2017)
2017
-
[29]
Robin L Plackett. 1975. The analysis of permutations.Journal of the Royal Statistical Society Series C: Applied Statistics24, 2 (1975), 193–202
1975
-
[30]
Wang Qinsi, Jinghan Ke, Masayoshi Tomizuka, Kurt Keutzer, and Chenfeng Xu
-
[31]
InThe Thirteenth International Conference on Learning Representations
Dobi-SVD: Differentiable SVD for LLM Compression and Some New Per- spectives. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=kws76i5XB8
-
[32]
P. V. Rao and Lawrence L. Kupper. 1967. Ties in Paired-Comparison Experiments: A Generalization of the Bradley–Terry Model.J. Amer. Statist. Assoc.62, 317 (1967), 194–204
1967
-
[33]
Steffen Rendle and Christoph Freudenthaler. 2014. Improving pairwise learning for item recommendation from implicit feedback. InProceedings of the 7th ACM International Conference on Web Search and Data Mining(New York, New York, USA)(WSDM ’14). Association for Computing Machinery, New York, NY, USA, 273–282. doi:10.1145/2556195.2556248
-
[34]
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme
-
[35]
InProceed- ings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence (UAI)
BPR: Bayesian Personalized Ranking from Implicit Feedback. InProceed- ings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence (UAI). Montreal, QC, Canada, 452–461
-
[36]
Gunther Schauberger and Gerhard Tutz. 2019. BTLLasso: a common framework and software package for the inclusion and selection of covariates in Bradley- Terry models.Journal of Statistical Software88 (2019), 1–29
2019
-
[37]
Mete Sertkan, Sophia Althammer, Sebastian Hofstätter, Peter Knees, and Julia Neidhardt. 2023. Exploring Effect-Size-Based Meta-Analysis for Multi-Dataset Evaluation. InProceedings of the 3rd Workshop Perspectives on the Evaluation of Rec- ommender Systems 2023 co-located with the 17th ACM Conference on Recommender Systems (RecSys 2023) (CEUR Workshop Proc...
2023
-
[38]
Valeriy Shevchenko, Nikita Belousov, Alexey Vasilev, Vladimir Zholobov, Artyom Sosedka, Natalia Semenova, Anna Volodkevich, Andrey Savchenko, and Alexey Zaytsev. 2024. From Variability to Stability: Advancing RecSys Benchmarking Practices. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Dis- covery and Data Mining(Barcelona, Spain)(KDD ’24). ...
-
[39]
Vladimir Spokoiny. 2025. Semiparametric plug-in estimation, sup-norm risk bounds, marginal optimization, and inference in BTL model.arXiv preprint arXiv:2503.15045(2025)
arXiv 2025
-
[40]
Harald Steck. 2019. Embarrassingly Shallow Autoencoders for Sparse Data. InThe World Wide Web Conference(San Francisco, CA, USA)(WWW ’19). Association for Computing Machinery, New York, NY, USA, 3251–3257. doi:10.1145/3308558. 3313710
-
[41]
Carolin Strobl, Florian Wickelmaier, and Achim Zeileis. 2011. Accounting for individual differences in Bradley-Terry models by means of recursive partitioning. Journal of Educational and Behavioral Statistics36, 2 (2011), 135–153
2011
-
[42]
Gábor Takács, István Pilászy, and Domonkos Tikk. 2011. Applications of the con- jugate gradient method for implicit feedback collaborative filtering. InProceedings of the fifth ACM conference on Recommender systems. 297–300
2011
-
[43]
Thurstone
Louis L. Thurstone. 1927. A Law of Comparative Judgment.Psychological Review 34 (1927), 273–286
1927
-
[44]
Askar Tsyganov, Evgeny Frolov, Sergey Samsonov, and Maxim Rakhuba. 2026. Matrix-Free Two-to-Infinity and One-to-Two Norms Estimation.Proceedings of the AAAI Conference on Artificial Intelligence40, 31 (2026), 26010–26018
2026
-
[45]
Askar Tsyganov, Uliana Parkina, Ekaterina Grishina, Sergey Samsonov, and Maxim Rakhuba. 2026. Faster SVD via Accelerated Newton-Schulz Iteration. In ICLR Blogposts 2026(April 27, 2026). https://iclr-blogposts.github.io/2026/blog/ 2026/polar-svd/
2026
-
[46]
Tobias Vente, Michael Heep, Abdullah Abbas, Theodor Sperle, Joeran Beel, and Bart Goethals. 2025. APS Explorer: Navigating Algorithm Performance Spaces for Informed Dataset Selection. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 1322–1324
2025
-
[47]
Jacques Wainer. 2023. A Bayesian Bradley–Terry Model to Compare Multiple Machine Learning Algorithms on Multiple Data Sets.Journal of Machine Learning Research24 (10 2023), 1–34
2023
-
[48]
Jordan, and Nebojsa Jojic
Fabian Wauthier, Michael I. Jordan, and Nebojsa Jojic. 2013. Efficient Ranking from Pairwise Comparisons. InProceedings of the 30th International Conference on Machine Learning (ICML) (Proceedings of Machine Learning Research, Vol. 28). 109–117
2013
-
[49]
Achim Zeileis, Torsten Hothorn, and Kurt Hornik. 2008. Model-based Recursive Partitioning.Journal of Computational and Graphical Statistics17, 2 (2008), 492–514. doi:10.1198/10618600SX319331
-
[50]
A Zeileis, C Strobl, F Wickelmaier, and J Kopf. 2011. psychotree: Recursive parti- tioning based on psychometric models.R package version 0.12-1, URL http://CRAN. R-project. org/package= psychotree(2011)
2011
-
[51]
Ernst Zermelo. 1929. Die berechnung der turnier-ergebnisse als ein maxi- mumproblem der wahrscheinlichkeitsrechnung.Mathematische Zeitschrift29, 1 (1929), 436–460. Bradley-Terry Rankings for Recommender Systems Across Dataset Taxonomies KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea A Supplementary tables Table 7: Recommendation algorithms us...
arXiv 1929
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.