UniSHARP: Universal Sharp Monocular View Synthesis
Pith reviewed 2026-06-27 22:07 UTC · model grok-4.3
The pith
UniSHARP aligns monocular images from any camera in a unified omnidirectional latent space to enable photorealistic view synthesis beyond pinhole assumptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
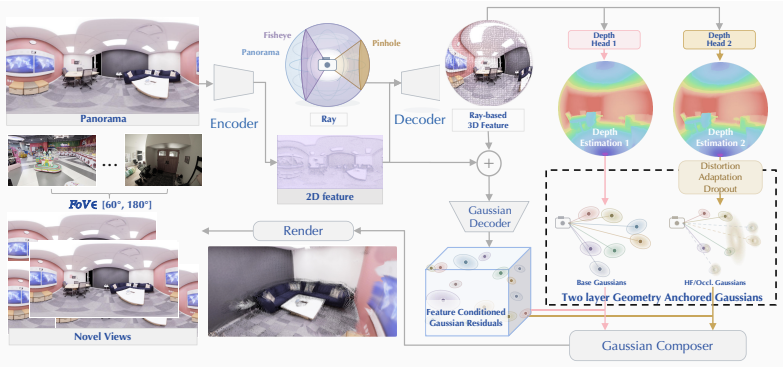
By arranging Gaussian primitives along rays and radial distances in a ray-based universal representation and jointly decoding 2D semantic and 3D spatial features extracted from UniK3D-inspired encoders, UniSHARP performs implicit alignment in feature and Gaussian spaces that overcomes the pinhole-specific assumptions of SHARP and supports photorealistic monocular rendering across the continuum of camera systems.
What carries the argument
ray-based universal representation that arranges Gaussian primitives along rays and radial distances while enabling joint decoding of features from UniK3D-inspired encoders to form the Gaussian cloud
If this is right
- Monocular view synthesis becomes possible for wide-field-of-view, fisheye, and panoramic cameras without separate models or explicit calibration.
- The stratified benchmark enables fine-grained assessment of rendering quality as field of view increases.
- Outperformance over alternative methods by a large margin holds across the tested scenes and camera types.
- The complete Gaussian cloud generated from the joint decoding supports consistent novel view rendering from single input images.
Where Pith is reading between the lines
- The ray-based alignment could allow training on mixed-camera datasets without preprocessing to a common projection model.
- If the implicit alignment generalizes, the same pipeline might support synthesis from casually captured phone videos that mix lens types.
- Extending the representation to handle rolling shutter or non-central projections would be a direct next test of the universal claim.
Load-bearing premise
That performing implicit alignment in both feature and Gaussian spaces via a ray-based universal representation and UniK3D-inspired encoders is sufficient to overcome pinhole-specific assumptions of SHARP while preserving photorealism across the full continuum of camera systems.
What would settle it
A controlled experiment on the benchmark where UniSHARP produces visible artifacts or lower quality on fisheye or omnidirectional images than on perspective images, or fails to show large-margin gains over camera-specific baselines, would indicate the alignment does not fully generalize.
Figures





read the original abstract
In this work, we focus on extending SHARP, the popular photorealistic view synthesis method, for universal monocular rendering across a continuum of camera systems, from conventional perspective cameras to wide-field-of-view, fisheye and omnidirectional panoramic settings. To overcome the pinhole-specific assumptions of SHARP, our key idea is to align various images in a unified omnidirectional latent space. Thus, we propose UniSHARP, which performs implicit alignment in both feature and Gaussian spaces. Specifically, Gaussian primitives are arranged along rays and radial distances in a ray-based universal representation, while 2D semantic and 3D spatial features extracted from UniK3D-inspired encoders are jointly decoded to generate the complete Gaussian cloud. To comprehensively evaluate our method, we construct a benchmark covering diverse imaging systems across various scenes. The benchmark is further stratified by field of view (FoV) to enable fine-grained assessment of the universal monocular rendering task. Extensive experiments on the proposed benchmark demonstrate the effectiveness of UniSHARP, outperforming alternative methods by a large margin. The project page can be found at: https://insta360-research-team.github.io/Unisharp-website/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniSHARP as an extension of SHARP for photorealistic monocular view synthesis across a continuum of camera models (pinhole to fisheye and omnidirectional). The core idea is implicit alignment of images in a unified omnidirectional latent space via a ray-based universal representation in which Gaussian primitives are arranged along rays and radial distances, combined with joint decoding of 2D semantic and 3D spatial features extracted by UniK3D-inspired encoders to produce the complete Gaussian cloud. A new benchmark stratified by field of view is introduced, and the authors claim that extensive experiments on this benchmark show UniSHARP outperforming alternative methods by a large margin.
Significance. If the performance claims are substantiated, the work would meaningfully advance general-purpose view synthesis by removing pinhole-specific assumptions while preserving photorealism, which is relevant for applications involving wide-FoV or panoramic cameras. Construction of a FoV-stratified benchmark is a constructive addition that could support future standardized evaluation. No parameter-free derivations, machine-checked proofs, or reproducible code artifacts are highlighted.
major comments (2)
- [Abstract / Experiments] The central performance claim (outperforming alternatives by a large margin) is load-bearing for the paper's contribution, yet the abstract provides no quantitative metrics, tables, or specific comparisons; this must be addressed with concrete numbers, error analysis, and ablation results in the experiments section to allow verification of the claim.
- [Method] The description of the ray-based universal representation and the implicit alignment procedure in both feature and Gaussian spaces lacks any equations or pseudocode showing how the alignment is implemented or how radial distances are encoded; without these details it is difficult to assess whether the construction truly removes pinhole assumptions in a general way.
minor comments (1)
- The project page URL is provided but the manuscript does not indicate whether code or the benchmark dataset will be released; adding a clear statement on reproducibility would strengthen the submission.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to improve clarity and substantiation of claims.
read point-by-point responses
-
Referee: [Abstract / Experiments] The central performance claim (outperforming alternatives by a large margin) is load-bearing for the paper's contribution, yet the abstract provides no quantitative metrics, tables, or specific comparisons; this must be addressed with concrete numbers, error analysis, and ablation results in the experiments section to allow verification of the claim.
Authors: We agree that the abstract would benefit from quantitative support for the performance claims. In the revised manuscript we will update the abstract to report key metrics (such as PSNR and SSIM gains on the FoV-stratified benchmark) drawn directly from the experiments section. The experiments section already contains tables, error analysis, and ablations; we will ensure these are cross-referenced clearly from the abstract. revision: yes
-
Referee: [Method] The description of the ray-based universal representation and the implicit alignment procedure in both feature and Gaussian spaces lacks any equations or pseudocode showing how the alignment is implemented or how radial distances are encoded; without these details it is difficult to assess whether the construction truly removes pinhole assumptions in a general way.
Authors: The current manuscript presents the ray-based representation at a conceptual level in Section 3. To address the request for rigor, we will insert the explicit equations governing Gaussian primitive placement along rays, the encoding of radial distances, and the implicit alignment operations in both feature and Gaussian spaces, together with pseudocode for the overall procedure. revision: yes
Circularity Check
Minor self-citation present but central claim independent
full rationale
The manuscript presents UniSHARP as an engineering construction that aligns images in a unified omnidirectional latent space using ray-based Gaussian primitives and joint decoding from UniK3D-inspired encoders. No equations, derivations, or fitted parameters are shown that reduce the claimed photorealistic output or benchmark superiority to a quantity defined by the method itself. The UniK3D reference constitutes a self-citation, but it is not load-bearing for the performance claim, which rests on external benchmark experiments. This matches the expected non-circular outcome for an applied architecture paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hqgs: High-quality novel view synthesis with gaussian splatting in degraded scenes
Xin Lin, Shi Luo, Xiaojun Shan, Xiaoyu Zhou, Chao Ren, Lu Qi, Ming-Hsuan Yang, and Nuno Vasconcelos. Hqgs: High-quality novel view synthesis with gaussian splatting in degraded scenes. InICLR, 2025. 2
2025
-
[2]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. InCVPR, 2024. 3
2024
-
[3]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. InECCV, 2024. 3
2024
-
[4]
Meixi Song, Xin Lin, Dizhe Zhang, Haodong Li, Xiangtai Li, Bo Du, and Lu Qi. D 2GS: Depth-and-density guided gaussian splatting for stable and accurate sparse-view reconstruction. arXiv preprint arXiv:2510.08566, 2025
arXiv 2025
-
[5]
Prior does matter: Visual navigation via denoising diffusion bridge models
Hao Ren, Yiming Zeng, Zetong Bi, Zhaoliang Wan, Junlong Huang, and Hui Cheng. Prior does matter: Visual navigation via denoising diffusion bridge models. InCVPR, pages 12100–12110, 2025
2025
-
[6]
Holigs: Holistic gaussian splatting for embodied view synthesis.NeurIPS, 38:96820–96849, 2026
Xiaoyuan Wang, Yizhou Zhao, Botao Ye, Shan Xiaojun, Weijie Lyu, Lu Qi, Kelvin Chan, Yinxiao Li, and Ming-Hsuan Yang. Holigs: Holistic gaussian splatting for embodied view synthesis.NeurIPS, 38:96820–96849, 2026. 10
2026
-
[7]
Mosiv: Multi-object system identification from videos.arXiv preprint arXiv:2603.06022, 2026
Chunjiang Liu, Xiaoyuan Wang, Qingran Lin, Albert Xiao, Haoyu Chen, Shizheng Wen, Hao Zhang, Lu Qi, Ming-Hsuan Yang, Laszlo A Jeni, et al. Mosiv: Multi-object system identification from videos.arXiv preprint arXiv:2603.06022, 2026
arXiv 2026
-
[8]
Jingtong Yue, Zhiwei Lin, Xin Lin, Xiaoyu Zhou, Xiangtai Li, Lu Qi, Yongtao Wang, and Ming-Hsuan Yang. Roburcdet: Enhancing robustness of radar-camera fusion in bird’s eye view for 3d object detection.arXiv preprint arXiv:2502.13071, 2025
arXiv 2025
-
[9]
Strnet: Visual navigation with spatio-temporal representation through dynamic graph aggregation
Hao Ren, Zetong Bi, Yiming Zeng, Zhaoliang Wan, Lu Qi, and Hui Cheng. Strnet: Visual navigation with spatio-temporal representation through dynamic graph aggregation. InCVPR, pages 42464–42473, 2026. 2
2026
-
[10]
Nerf: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoor- thi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 2021. 2, 3
2021
-
[11]
3d gaussian splatting for real-time radiance field rendering.TOG, 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.TOG, 2023. 2, 3
2023
-
[12]
Richter, and Vladlen Koltun
Lars Mescheder, Wei Dong, Shiwei Li, Xuyang Bai, Marcel Santos, Peiyun Hu, Bruno Lecouat, Mingmin Zhen, Amael Delaunoy, Tian Fang, Yanghai Tsin, Stephan R. Richter, and Vladlen Koltun. Sharp monocular view synthesis in less than a second. InICLR, 2026. 2, 3, 7, 8, 9, 15
2026
-
[13]
Stanislaw Szymanowicz, Christian Rupprecht, and Andrea Vedaldi. Flash3d: Feed-forward generalisable 3d scene reconstruction from a single image.arXiv preprint arXiv:2406.04343,
-
[14]
Longwei Li, Huajian Huang, Sai-Kit Yeung, and Hui Cheng. Omnigs: Fast radiance field reconstruction using omnidirectional gaussian splatting.arXiv preprint arXiv:2404.03202, 2024. 2, 3
arXiv 2024
-
[15]
Splatter-360: Generalizable 360 gaussian splatting for wide-baseline panoramic images
Zheng Chen, Chenming Wu, Zhelun Shen, Chen Zhao, Weicai Ye, Haocheng Feng, Errui Ding, and Song-Hai Zhang. Splatter-360: Generalizable 360 gaussian splatting for wide-baseline panoramic images. InCVPR, 2025. 4
2025
-
[16]
Pansplat: 4k panorama synthesis with feed-forward gaussian splatting
Cheng Zhang, Haofei Xu, Qianyi Wu, Camilo Cruz Gambardella, Dinh Phung, and Jianfei Cai. Pansplat: 4k panorama synthesis with feed-forward gaussian splatting. InCVPR, 2025
2025
-
[17]
Omnisplat: Taming feed-forward 3d gaussian splatting for omnidirectional images with editable capabilities
Suyoung Lee, Jaeyoung Chung, Kihoon Kim, Jaeyoo Huh, Gunhee Lee, Minsoo Lee, and Kyoung Mu Lee. Omnisplat: Taming feed-forward 3d gaussian splatting for omnidirectional images with editable capabilities. InCVPR, 2025. 4
2025
-
[18]
Self-calibrating gaussian splatting for large field-of-view recon- struction
Youming Deng, Wenqi Xian, Guandao Yang, Leonidas Guibas, Gordon Wetzstein, Steve Marschner, and Paul Debevec. Self-calibrating gaussian splatting for large field-of-view recon- struction. InICCV, 2025. 2, 3
2025
-
[20]
Xin Lin, Meixi Song, Dizhe Zhang, Wenxuan Lu, Haodong Li, Bo Du, Ming-Hsuan Yang, Truong Nguyen, and Lu Qi. Depth any panoramas: A foundation model for panoramic depth estimation.arXiv preprint arXiv:2512.16913, 2025
arXiv 2025
-
[21]
Fly360: Omnidirectional obstacle avoidance within drone view.arXiv preprint arXiv:2603.06573, 2026
Xiangkai Zhang, Dizhe Zhang, WenZhuo Cao, Zhaoliang Wan, Yingjie Niu, Lu Qi, Xu Yang, and Zhiyong Liu. Fly360: Omnidirectional obstacle avoidance within drone view.arXiv preprint arXiv:2603.06573, 2026
arXiv 2026
-
[22]
Haoran Feng, Dizhe Zhang, Xiangtai Li, Bo Du, and Lu Qi. Dit360: High-fidelity panoramic image generation via hybrid training.arXiv preprint arXiv:2510.11712, 2025
arXiv 2025
-
[23]
Yuheng Liu, Xin Lin, Xinke Li, Baihan Yang, Chen Wang, Kalyan Sunkavalli, Yannick Hold- Geoffroy, Hao Tan, Kai Zhang, Xiaohui Xie, Zifan Shi, and Yiwei Hu. Omniroam: World wandering via long-horizon panoramic video generation.arXiv preprint arXiv:2603.30045, 2026. 11
arXiv 2026
-
[24]
Xin Lin, Xian Ge, Dizhe Zhang, Zhaoliang Wan, Xianshun Wang, Xiangtai Li, Wenjie Jiang, Bo Du, Dacheng Tao, Ming-Hsuan Yang, et al. One flight over the gap: A survey from perspective to panoramic vision.arXiv preprint arXiv:2509.04444, 2025
arXiv 2025
-
[25]
PanoWorld: Towards spatial supersensing in 360◦ panorama world.arXiv preprint arXiv:2605.13169, 2026
Changpeng Wang, Xin Lin, Junhan Liu, Yuheng Liu, Zhen Wang, Donglian Qi, Yunfeng Yan, and Xi Chen. PanoWorld: Towards spatial supersensing in 360◦ panorama world.arXiv preprint arXiv:2605.13169, 2026. 2
Pith/arXiv arXiv 2026
-
[26]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. InCVPR, 2022. 3
2022
-
[27]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Zip-nerf: Anti-aliased grid-based neural radiance fields. InICCV, 2023. 3
2023
-
[28]
Srinivasan, Howard Zhou, Jonathan T
Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul P. Srinivasan, Howard Zhou, Jonathan T. Barron, Ricardo Martin-Brualla, Noah Snavely, and Thomas Funkhouser. Ibrnet: Learning multi-view image-based rendering. InCVPR, 2021. 3
2021
-
[29]
Mvsnerf: Fast generalizable radiance field reconstruction from multi-view stereo
Anpei Chen, Zexiang Xu, Fuqiang Zhao, Xiaoshuai Zhang, Fanbo Xiang, Jingyi Yu, and Hao Su. Mvsnerf: Fast generalizable radiance field reconstruction from multi-view stereo. InICCV,
-
[30]
Depthsplat: Connecting gaussian splatting and depth
Haofei Xu, Songyou Peng, Fangjinhua Wang, Hermann Blum, Daniel Barath, Andreas Geiger, and Marc Pollefeys. Depthsplat: Connecting gaussian splatting and depth. InCVPR, 2025. 3
2025
-
[31]
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, Dahua Lin, and Bo Dai. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.arXiv preprint arXiv:2505.23716, 2025. 3
arXiv 2025
-
[32]
Pf3plat: Pose-free feed-forward 3d gaussian splatting for novel view synthesis
Sunghwan Hong, Jaewoo Jung, Heeseong Shin, Jisang Han, Jiaolong Yang, Chong Luo, and Seungryong Kim. Pf3plat: Pose-free feed-forward 3d gaussian splatting for novel view synthesis. InICML, 2025
2025
-
[33]
Lara: Efficient large-baseline radiance fields
Anpei Chen, Haofei Xu, Stefano Esposito, Siyu Tang, and Andreas Geiger. Lara: Efficient large-baseline radiance fields. InECCV, 2024
2024
-
[34]
Gs-lrm: Large reconstruction model for 3d gaussian splatting
Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, and Zexiang Xu. Gs-lrm: Large reconstruction model for 3d gaussian splatting. InECCV, 2024. 3
2024
-
[35]
pixelnerf: Neural radiance fields from one or few images
Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. pixelnerf: Neural radiance fields from one or few images. InCVPR, 2021. 3
2021
-
[36]
Single-view view synthesis with multiplane images
Richard Tucker and Noah Snavely. Single-view view synthesis with multiplane images. In CVPR, 2020. 3
2020
-
[37]
Synsin: End-to-end view synthesis from a single image
Olivia Wiles, Georgia Gkioxari, Richard Szeliski, and Justin Johnson. Synsin: End-to-end view synthesis from a single image. InCVPR, 2020. 3
2020
-
[38]
Freeman, David Salesin, Brian Curless, Noah Snavely, and Ce Liu
Varun Jampani, Huiwen Chang, Kyle Sargent, Abhishek Kar, Richard Tucker, Michael Krainin, Dominik Kaeser, William T. Freeman, David Salesin, Brian Curless, Noah Snavely, and Ce Liu. Slide: Single image 3d photography with soft layering and depth-aware inpainting. InICCV, 2021
2021
-
[39]
Single-view view synthesis in the wild with learned adaptive multiplane images.ACM Transactions on Graphics, 41(4), 2022
Yuxuan Han, Ruicheng Wang, and Jiaolong Yang. Single-view view synthesis in the wild with learned adaptive multiplane images.ACM Transactions on Graphics, 41(4), 2022
2022
-
[40]
Tiled multiplane images for practical 3d photography
Numair Khan, Eric Penner, Douglas Lanman, and Lei Xiao. Tiled multiplane images for practical 3d photography. InICCV, 2023. 3, 7, 8, 9
2023
-
[41]
Lrm: Large reconstruction model for single image to 3d.arXiv preprint arXiv:2311.04400, 2023
Yuan Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. Lrm: Large reconstruction model for single image to 3d.arXiv preprint arXiv:2311.04400, 2023. 3 12
Pith/arXiv arXiv 2023
-
[42]
Lvsm: A large view synthesis model with minimal 3d inductive bias
Haian Jin, Hanwen Jiang, Hao Tan, Kai Zhang, Sai Bi, Tianyuan Zhang, Fujun Luan, Noah Snavely, and Zexiang Xu. Lvsm: A large view synthesis model with minimal 3d inductive bias. InICLR, 2025. 3, 7, 8, 9
2025
-
[43]
Splatter image: Ultra-fast single-view 3d reconstruction
Stanislaw Szymanowicz, Christian Rupprecht, and Andrea Vedaldi. Splatter image: Ultra-fast single-view 3d reconstruction. InCVPR, 2024. 3
2024
-
[44]
Chan, Dmitry Lagun, Li Fei-Fei, Deqing Sun, and Jiajun Wu
Kyle Sargent, Zizhang Li, Tanmay Shah, Charles Herrmann, Hong-Xing Yu, Yunzhi Zhang, Eric R. Chan, Dmitry Lagun, Li Fei-Fei, Deqing Sun, and Jiajun Wu. Zeronvs: Zero-shot 360-degree view synthesis from a single real image. InCVPR, 2024. 3
2024
-
[45]
Plataniotis, Sergey Tulyakov, and Jian Ren
Hanwen Liang, Junli Cao, Vidit Goel, Guocheng Qian, Sergei Korolev, Demetri Terzopoulos, Konstantinos N. Plataniotis, Sergey Tulyakov, and Jian Ren. Wonderland: Navigating 3d scenes from a single image. InCVPR, 2025
2025
-
[46]
Gen3c: 3d-informed world- consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Mueller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world- consistent video generation with precise camera control. InCVPR, 2025. 3
2025
-
[47]
Unik3d: Universal camera monocular 3d estimation
Luigi Piccinelli, Christos Sakaridis, Mattia Segu, Yung-Hsu Yang, Siyuan Li, Wim Abbeloos, and Luc Van Gool. Unik3d: Universal camera monocular 3d estimation. InCVPR, 2025. 3, 4, 6, 14
2025
-
[48]
Zimu Liao, Siyan Chen, Rong Fu, Yi Wang, Zhongling Su, Hao Luo, Li Ma, Linning Xu, Bo Dai, Hengjie Li, Zhilin Pei, and Xingcheng Zhang. Fisheye-gs: Lightweight and extensible gaussian splatting module for fisheye cameras.arXiv preprint arXiv:2409.04751, 2024. 3
arXiv 2024
-
[49]
Sc-omnigs: Self-calibrating omnidirectional gaussian splatting
Huajian Huang, Yingshu Chen, Longwei Li, Hui Cheng, Tristan Braud, Yajie Zhao, and Sai-Kit Yeung. Sc-omnigs: Self-calibrating omnidirectional gaussian splatting. InICLR, 2025. 3
2025
-
[50]
Zhengxian Yang, Fei Xie, Xutao Xue, Rui Zhang, Taicheng Huang, Yang Liu, Mengqi Ji, and Tao Yu. Directfisheye-gs: Enabling native fisheye input in gaussian splatting with cross-view joint optimization.arXiv preprint arXiv:2604.00648, 2026. 3
Pith/arXiv arXiv 2026
-
[51]
Panogrf: Generalizable spherical radiance fields for wide-baseline panoramas
Zheng Chen, Yan-Pei Cao, Yuan-Chen Guo, Chen Wang, Ying Shan, and Song-Hai Zhang. Panogrf: Generalizable spherical radiance fields for wide-baseline panoramas. InNeurIPS,
-
[52]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, Xuanmao Li, Xingpeng Sun, Rohan Ashok, Aniruddha Mukherjee, Hao Kang, Xiangrui Kong, Gang Hua, Tianyi Zhang, Bedrich Benes, and Aniket Bera. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InCVPR, 2024. 6, 7
2024
-
[53]
Stereo magnifi- cation: Learning view synthesis using multiplane images.ACM Transactions on Graphics, 37 (4), 2018
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnifi- cation: Learning view synthesis using multiplane images.ACM Transactions on Graphics, 37 (4), 2018. 6, 7
2018
-
[54]
Tanks and temples: Bench- marking large-scale scene reconstruction.ACM Transactions on Graphics, 36(4), 2017
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Bench- marking large-scale scene reconstruction.ACM Transactions on Graphics, 36(4), 2017. 6, 9
2017
-
[55]
Rgbd objects in the wild: Scaling real-world 3d object learning from rgb-d videos
Hongchi Xia, Yang Fu, Sifei Liu, and Xiaolong Wang. Rgbd objects in the wild: Scaling real-world 3d object learning from rgb-d videos. InCVPR, 2024. 6, 7, 10, 14
2024
-
[56]
Scannet++: A high-fidelity dataset of 3d indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Niessner, and Angela Dai. Scannet++: A high-fidelity dataset of 3d indoor scenes. InICCV, 2023. 6, 9
2023
-
[57]
Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J. Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, Anton Clarkson, Mingfei Yan, Brian Budge, Yajie Yan, Xiaqing Pan, June Yon, Yuyang Zou, Kimberly Leon, Nigel Carter, Jesus Briales, Tyler Gillingham, Elias Mueggler, Luis Pesqueira, Manolis Savva, Dhruv Batra, Hauke M. S...
Pith/arXiv arXiv 1906
-
[58]
Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X
Santhosh Kumar Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alexan- der Clegg, John M. Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X. Chang, Manolis Savva, Yili Zhao, and Dhruv Batra. Habitat-matterport 3d dataset (HM3d): 1000 large-scale 3d environments for embodied AI. InNeurIPS Datasets and Benchmarks Track, 20...
2021
-
[59]
Airsim360: A panoramic simulation platform within drone view.arXiv preprint arXiv:2512.02009, 2025
Xian Ge, Yuling Pan, Yuhang Zhang, Xiang Li, Weijun Zhang, Dizhe Zhang, Zhaoliang Wan, Xin Lin, Xiangkai Zhang, Juntao Liang, et al. Airsim360: A panoramic simulation platform within drone view.arXiv preprint arXiv:2512.02009, 2025. 6, 7
arXiv 2025
-
[60]
Panodreamer: Optimization-based single image to 360 3d scene with diffusion
Avinash Paliwal, Xilong Zhou, Andrii Tsarov, and Nima Khademi Kalantari. Panodreamer: Optimization-based single image to 360 3d scene with diffusion. InSIGGRAPH Asia Conference Papers, 2025. 8, 9, 16
2025
-
[61]
Matrix3d: Large photogrammetry model all-in-one
Yuanxun Lu, Jingyang Zhang, Tian Fang, Jean-Daniel Nahmias, Yanghai Tsin, Long Quan, Xun Cao, Yao Yao, and Shiwei Li. Matrix3d: Large photogrammetry model all-in-one. InCVPR,
-
[62]
Zixun Huang, Cho-Ying Wu, Yuliang Guo, Xinyu Huang, and Liu Ren. 3dgeer: 3d gaussian rendering made exact and efficient for generic cameras.arXiv preprint arXiv:2505.24053, 2026. 14
arXiv 2026
-
[63]
Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014. 14 A Additional Experiments and Ablations A.1 Implementation Details All experiments are conducted on 8 H20 GPUs. UniSHARP uses the feature-only architecture described in Sec. 3, with a UniK3D ViT-L backbone initialized from pretrained weights ...
Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.