AgentCompile: An LLM-Guided Compiler for Direct CUDA Inference
Pith reviewed 2026-06-27 23:07 UTC · model grok-4.3
The pith
AgentCompile treats LLM outputs as advisory metadata to select CUDA specializations, achieving 5.66x average speedup over PyTorch eager on Qwen3-1.7B.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
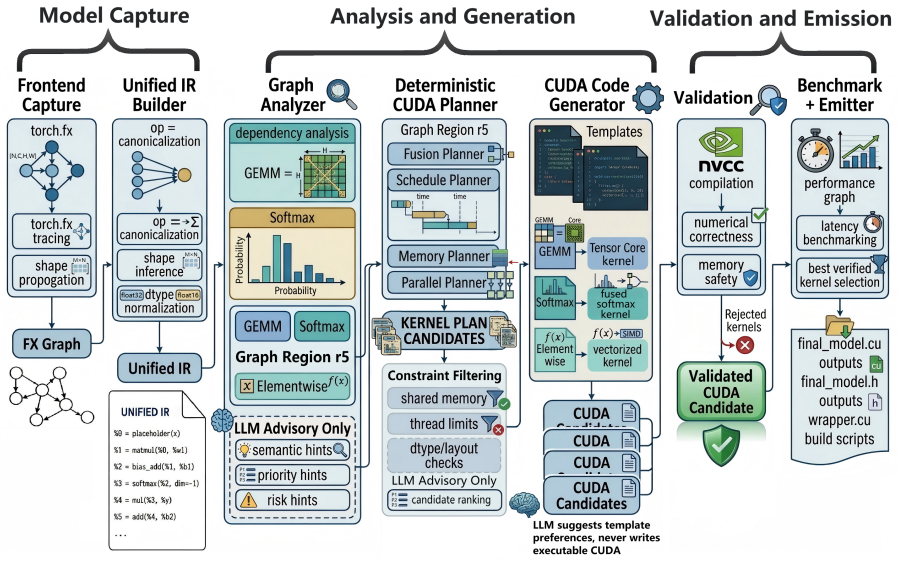
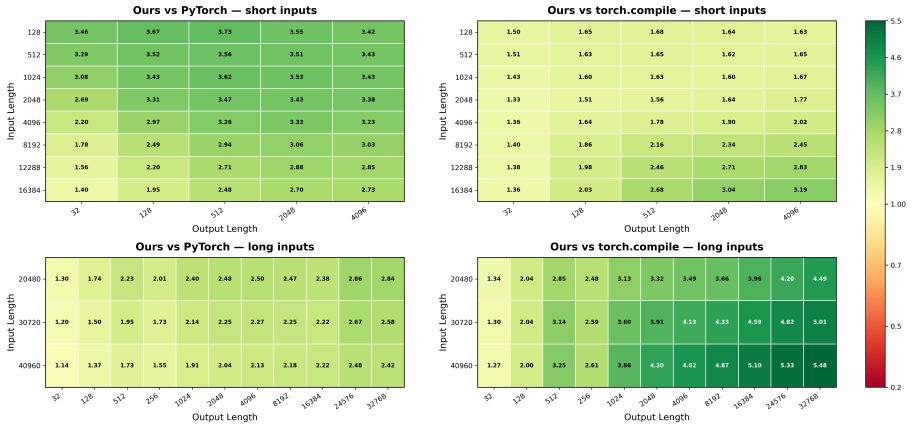
AgentCompile is an LLM-guided CUDA inference compiler that uses LLM outputs only as advisory search metadata. Given compiler-derived region summaries and bounded candidate spaces, the LLM proposes semantic labels, candidate priorities, parameter hints, and risk annotations; the compiler materializes CUDA candidates through templates, checks interface and hardware constraints, validates candidates empirically, selects implementations by measured latency, and falls back when specialization is unsupported or unprofitable. In end-to-end autoregressive generation, AgentCompile averages 5.66x, 4.05x, and 4.26x speedup over PyTorch eager on Qwen3-1.7B, Qwen3-4B, and Llama-3.2-1B-Instruct, respectiv
What carries the argument
LLM advisory metadata restricted to compiler-supplied bounded candidate spaces for CUDA template selection
If this is right
- Measured latency serves as the final selector among LLM-prioritized candidates.
- Unsupported or unprofitable specializations trigger automatic fallback to safe execution.
- The method applies directly to end-to-end autoregressive generation on the tested models without manual per-operator tuning.
- Semantic decisions are delegated to the LLM while interface checks and empirical timing remain with the compiler.
- The open-sourced implementation allows direct measurement of the reported speedups on the same models and workloads.
Where Pith is reading between the lines
- The same advisory-metadata pattern could be reused for other accelerator targets that already possess template-based code generators.
- Keeping candidate spaces explicitly bounded limits the impact of any single LLM error on final correctness.
- If empirical validation cost grows with model size, the technique may be most practical for models under a few billion parameters.
- An iterative loop in which compiler timing results are fed back to the LLM for re-ranking could further improve selection without enlarging the initial candidate set.
Load-bearing premise
The LLM can reliably propose useful semantic labels, priorities, and risk annotations within the bounded candidate spaces supplied by the compiler, and empirical validation will always be feasible and sufficient to select profitable specializations without excessive overhead.
What would settle it
A workload in which LLM proposals consistently select candidates whose measured latency is no better than PyTorch eager despite the existence of faster hand-written CUDA alternatives.
Figures

read the original abstract
Transformer inference increasingly depends on specialized compiler and runtime support, but real model graphs still require semantic decisions about which regions are worth specializing and which CUDA implementation families are plausible. We present AgentCompile, an LLM-guided CUDA inference compiler that uses LLM outputs only as advisory search metadata. Given compiler-derived region summaries and bounded candidate spaces, the LLM proposes semantic labels, candidate priorities, parameter hints, and risk annotations; the compiler materializes CUDA candidates through templates, checks interface and hardware constraints, validates candidates empirically, selects implementations by measured latency, and falls back when specialization is unsupported or unprofitable. In end-to-end autoregressive generation, AgentCompile averages 5.66x, 4.05x, and 4.26x speedup over PyTorch eager on Qwen3-1.7B, Qwen3-4B, and Llama-3.2-1B-Instruct, respectively, across five representative workloads. We will open-source the project.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. AgentCompile is an LLM-guided CUDA inference compiler that restricts LLM use to advisory metadata (semantic labels, priorities, parameter hints, risk annotations) within compiler-supplied bounded candidate spaces. The compiler materializes CUDA candidates via templates, performs interface/hardware checks, empirically validates them, selects by measured latency, and falls back to non-specialized paths when necessary. The paper reports average end-to-end speedups of 5.66×, 4.05×, and 4.26× over PyTorch eager for Qwen3-1.7B, Qwen3-4B, and Llama-3.2-1B-Instruct across five workloads in autoregressive generation, and states it will open-source the project.
Significance. If substantiated, the work offers a pragmatic hybrid compiler design that safely incorporates LLMs by confining them to advisory roles and relying on direct measurement for final selection and fallback. This addresses reliability concerns in LLM-assisted optimization for transformer inference. The planned open-sourcing is a positive step for reproducibility in the PL and systems communities.
major comments (1)
- [Abstract] Abstract: the central claims of 5.66×, 4.05×, and 4.26× average speedups are presented without error bars, workload specifications, region-selection methodology, or counts of candidates tested per region. These details are load-bearing for evaluating whether the reported gains are statistically reliable and not artifacts of particular choices.
minor comments (1)
- The abstract ends with a future-tense statement about open-sourcing without a timeline or link; this is a minor presentation detail.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that additional details are needed to substantiate the reported speedups and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 5.66×, 4.05×, and 4.26× average speedups are presented without error bars, workload specifications, region-selection methodology, or counts of candidates tested per region. These details are load-bearing for evaluating whether the reported gains are statistically reliable and not artifacts of particular choices.
Authors: We agree that the abstract should be expanded to include these details for proper evaluation of statistical reliability. In the revised version we will add: (1) error bars or standard deviation from repeated measurements, (2) explicit names and descriptions of the five workloads, (3) a concise statement of the region-selection methodology, and (4) the typical number of candidates evaluated per region. These elements already appear in the experimental evaluation section; we will make the abstract self-contained on this point while preserving its length constraints. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical compiler pipeline in which LLM outputs serve only as advisory metadata within compiler-supplied bounded spaces; final implementation selection is performed by direct empirical latency measurement, interface/hardware constraint checks, and fallback to non-specialized paths. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the described derivation. The reported speedups are obtained from external benchmarks against PyTorch eager execution, rendering the central claims self-contained and independent of any construction that reduces to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , editor =
Dao, Tri and Fu, Dan and Ermon, Stefano and Rudra, Atri and R. Advances in Neural Information Processing Systems , editor =. 2022 , url =
2022
-
[2]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness , url =
Dao, Tri and Fu, Dan and Ermon, Stefano and Rudra, Atri and R\'. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness , url =. Advances in Neural Information Processing Systems , editor =
-
[3]
2024 , publisher =
Ansel, Jason and Yang, Edward and He, Horace and Gimelshein, Natalia and Jain, Animesh and Voznesensky, Michael and Bao, Bin and Bell, Peter and Berard, David and Burovski, Evgeni and others , booktitle =. 2024 , publisher =
2024
-
[4]
2018 , publisher =
Chen, Tianqi and Moreau, Thierry and Jiang, Ziheng and Zheng, Lianmin and Yan, Eddie and Shen, Haichen and Cowan, Meghan and Wang, Leyuan and Hu, Yuwei and Ceze, Luis and Guestrin, Carlos and Krishnamurthy, Arvind , booktitle =. 2018 , publisher =
2018
-
[5]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author =. arXiv preprint arXiv:2107.03374 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
and Zhang, Hao and Stoica, Ion , booktitle =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , booktitle =. Efficient Memory Management for Large Language Model Serving with. 2023 , publisher =
2023
-
[7]
Competition-Level Code Generation with
Li, Yujia and Choi, David and Chung, Junyoung and Kushman, Nate and Schrittwieser, Julian and Leblond, R. Competition-Level Code Generation with. Science , volume =. 2022 , publisher =
2022
-
[8]
2023 , url =
Li, Raymond and Ben Allal, Loubna and Zi, Yangtian and Muennighoff, Niklas and Kocetkov, Denis and Mou, Chenghao and Marone, Marc and Akiki, Christopher and Li, Jia and Chim, Jenny and others , journal =. 2023 , url =
2023
-
[9]
2024 , url =
Ni, Ansong and Allamanis, Miltiadis and Cohan, Arman and Deng, Yinlin and Shi, Kensen and Sutton, Charles and Yin, Pengcheng , booktitle =. 2024 , url =
2024
-
[10]
2021 , publisher =
Niu, Wei and Guan, Jiexiong and Wang, Yanzhi and Agrawal, Gagan and Ren, Bin , booktitle =. 2021 , publisher =
2021
-
[11]
Advances in Neural Information Processing Systems , editor =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems , editor =. 2023 , url =
2023
-
[12]
, booktitle =
Tillet, Philippe and Kung, Hsiang-Tsung and Cox, David D. , booktitle =. 2019 , publisher =
2019
-
[13]
2022 , publisher =
Yu, Gyeong-In and Jeong, Joo Seong and Kim, Geon-Woo and Kim, Soojeong and Chun, Byung-Gon , booktitle =. 2022 , publisher =
2022
-
[14]
2022 , publisher =
Zheng, Zhen and Yang, Xuanda and Zhao, Pengzhan and Long, Guoping and Zhu, Kai and Zhu, Feiwen and Zhao, Wenyi and Liu, Xiaoyong and Yang, Jun and Zhai, Jidong and others , booktitle =. 2022 , publisher =
2022
-
[15]
2021 , organization =
Lattner, Chris and Amini, Mehdi and Bondhugula, Uday and Cohen, Albert and Davis, Andy and Pienaar, Jacques and Riddle, River and Shpeisman, Tatiana and Vasilache, Nicolas and Zinenko, Oleksandr , booktitle =. 2021 , organization =
2021
-
[16]
and Stoica, Ion , booktitle =
Zheng, Lianmin and Jia, Chengfan and Sun, Minmin and Wu, Zhao and Yu, Cody Hao and Haj-Ali, Ameer and Wang, Yida and Yang, Jun and Zhuo, Danyang and Sen, Koushik and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. 2020 , publisher =
2020
-
[17]
2019 , publisher =
Jia, Zhihao and Padon, Oded and Thomas, James and Warszawski, Todd and Zaharia, Matei and Aiken, Alex , booktitle =. 2019 , publisher =
2019
-
[18]
Advances in Neural Information Processing Systems , editor =
Learning to Optimize Tensor Programs , author =. Advances in Neural Information Processing Systems , editor =. 2018 , url =
2018
-
[19]
2020 , publisher =
Ma, Lingxiao and Xie, Zhiqiang and Yang, Zhi and Xue, Jilong and Miao, Youshan and Cui, Wei and Hu, Wenxiang and Yang, Fan and Zhang, Lintao and Zhou, Lidong , booktitle =. 2020 , publisher =
2020
-
[20]
2022 , publisher =
Zhu, Hongyu and Wu, Ruofan and Diao, Yijia and Ke, Shanbin and Li, Haoyu and Zhang, Chen and Xue, Jilong and Ma, Lingxiao and Xia, Yuqing and Cui, Wei and Yang, Fan and Yang, Mao and Zhou, Lidong and Cidon, Asaf and Pekhimenko, Gennady , booktitle =. 2022 , publisher =
2022
-
[21]
2023 , publisher =
Shi, Yining and Yang, Zhi and Xue, Jilong and Ma, Lingxiao and Xia, Yuqing and Miao, Ziming and Guo, Yuxiao and Yang, Fan and Zhou, Lidong , booktitle =. 2023 , publisher =
2023
-
[22]
arXiv preprint arXiv:2309.07062 , year =
Large Language Models for Compiler Optimization , author =. arXiv preprint arXiv:2309.07062 , year =
-
[23]
KernelBench: Can LLMs Write Efficient GPU Kernels?
Ouyang, Anne and Guo, Simon and Arora, Simran and Zhang, Alex L. and Hu, William and R. arXiv preprint arXiv:2502.10517 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
torch.fx: Practical Program Capture and Transformation for Deep Learning in Python , url =
Reed, James and DeVito, Zachary and He, Horace and Ussery, Ansley and Ansel, Jason , booktitle =. torch.fx: Practical Program Capture and Transformation for Deep Learning in Python , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.