Review the Code, Not the Story: A Vision and Protocol for Code-First Peer Review
Pith reviewed 2026-06-27 21:43 UTC · model grok-4.3
The pith
Peer review should target executable code and evidence rather than author-written narratives, using a controlled AI system to verify claims.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
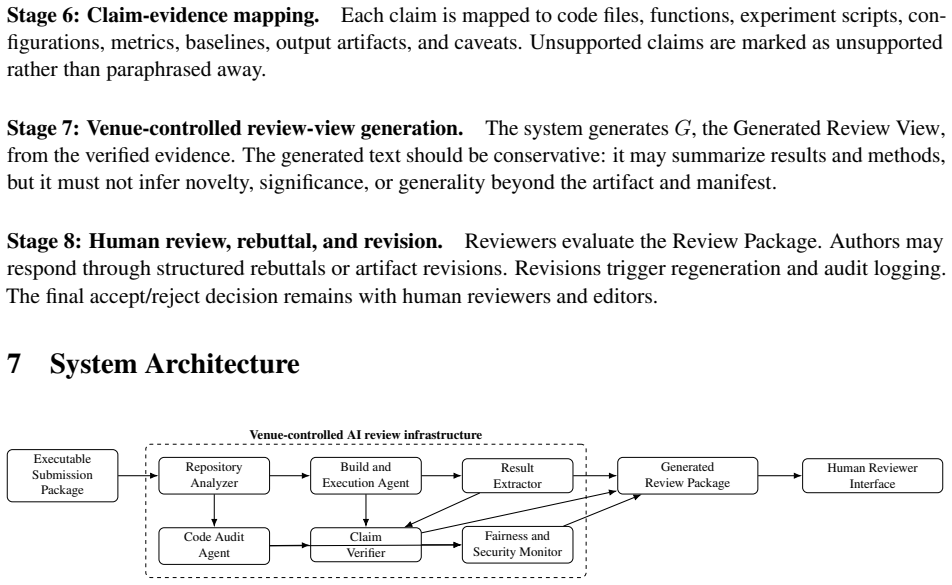
Authors submit executable research artifacts together with minimal claim manifests; a venue-controlled AI system builds the execution environment, executes the experiments, audits code paths, maps each claim to supporting evidence, and generates a standardized Review Package that human reviewers then inspect, thereby redirecting peer review from polished narratives to executable evidence.
What carries the argument
The claim-evidence contract, which requires authors to link each stated claim directly to executable code and data artifacts that the AI can verify.
If this is right
- Reviewers receive a standardized evidence mapping instead of depending primarily on author framing.
- Reproducibility failures are detected during the AI execution step before human review begins.
- Authors must ensure submitted code is executable and that claims are directly traceable to artifacts.
- Venues must establish governance for the AI system, including handling of bias, prompt injection, and author appeals.
Where Pith is reading between the lines
- The protocol could reduce reviewer time spent on narrative interpretation and increase time spent on technical verification.
- Fields outside strict computational research that still rely on data and code might adopt similar claim-evidence contracts.
- The AI-generated Review Package creates a new audit trail that could support post-publication verification or meta-analyses.
- Implementation would require new venue policies for storing and re-executing artifacts over time.
Load-bearing premise
A venue-controlled AI system can reliably build environments, execute experiments, audit code paths, and map claims to evidence without introducing new biases or errors that would undermine the review.
What would settle it
A controlled test in which submitted code contains a fabricated result or unsupported claim and the generated Review Package fails to flag the mismatch.
Figures

read the original abstract
Peer review in computational fields remains centered on author-written manuscripts, even though the decisive evidence for many claims resides in executable code, data, configurations, and experiment pipelines. This manuscript-first workflow gives authors substantial control over narrative framing while leaving reviewers with limited time to inspect implementation details, reproduce results, or detect unsupported claims. This vision and protocol paper proposes code-first peer review: authors submit executable research artifacts and minimal claim manifests; a venue-controlled AI system builds the environment, executes experiments, audits code paths, maps claims to evidence, and generates a standardized Review Package for human reviewers. The goal is not to replace reviewers or to give authors an automatic writing assistant. Instead, AI serves as review infrastructure that shifts the target of peer review from polished narratives to executable evidence. We formalize a claim-evidence contract, define the Generated Review View and Review Package abstractions, give a worked example, outline a system architecture, and analyze evaluation and governance challenges including AI bias, prompt injection, model instability, auditability, and author appeal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a shift to code-first peer review in computational fields, where authors submit executable artifacts and claim manifests rather than polished manuscripts. A venue-controlled AI system builds environments, executes experiments, audits code paths, maps claims to evidence, and generates a standardized Review Package for human reviewers. It formalizes the 'claim-evidence contract', defines 'Generated Review View' and 'Review Package' abstractions, provides a worked example, outlines a system architecture, and analyzes challenges including AI bias, prompt injection, model instability, auditability, and author appeal. The aim is to use AI as review infrastructure to focus on executable evidence instead of narratives.
Significance. This vision paper identifies a key limitation in current manuscript-centric peer review and offers a structured protocol to address it. If the proposed system can be implemented without introducing unacceptable new biases or instabilities, it could enhance reproducibility and claim verification in fields reliant on code and data. The manuscript is credited for its formal abstractions, explicit worked example, and balanced discussion of open challenges without empirical overclaims.
minor comments (2)
- [Worked example] The worked example would benefit from including specific pseudocode or diagrams to illustrate how the claim-evidence contract is applied in practice.
- [System architecture] The architecture outline could clarify the interface between the AI system and the human reviewer to avoid ambiguity in the Generated Review View.
Simulated Author's Rebuttal
We thank the referee for their thoughtful summary, positive significance assessment, and recommendation of minor revision. The feedback affirms the value of formalizing the claim-evidence contract and the balanced treatment of implementation challenges.
Circularity Check
No significant circularity; vision/protocol paper with no derivations or self-referential reductions
full rationale
The manuscript is a forward-looking vision and protocol proposal that introduces abstractions (claim-evidence contract, Generated Review View, Review Package) and outlines an architecture plus open challenges. It contains no equations, no fitted parameters, no predictions of empirical quantities, and no load-bearing self-citations or uniqueness theorems. The central claim is the proposal itself rather than any derivation that reduces to its own inputs by construction. The paper is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Peer review in computational fields remains centered on author-written manuscripts even though decisive evidence resides in executable code and pipelines.
invented entities (3)
-
claim-evidence contract
no independent evidence
-
Generated Review View
no independent evidence
-
Review Package
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ACM artifact review and badging
Association for Computing Machinery. ACM artifact review and badging. Policy document, 2020. URL https://www.acm.org/publications/policies/artifact-review-badging. Accessed 2026-06-02
2020
-
[2]
Scientists hide messages in papers to game ai peer review.Nature,
Elizabeth Gibney. Scientists hide messages in papers to game ai peer review.Nature,
-
[3]
URL https://www.nature.com/articles/ d41586-025-02172-y
doi: 10.1038/d41586-025-02172-y. URL https://www.nature.com/articles/ d41586-025-02172-y
-
[4]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Zhouchi Lin, Bowen Zhang, Lionel Ni, Wen Gao, Yuanzhuo Wang, and Jian Guo. A survey on llm-as-a-judge, 2024. URL https: //arxiv.org/abs/2411.15594
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [5]
-
[6]
IOS Press , year = 2016, pages =
Thomas Kluyver, Benjamin Ragan-Kelley, Fernando P ´erez, Brian Granger, Matthias Bussonnier, Jonathan Frederic, Kyle Kelley, Jessica Hamrick, Jason Grout, Sylvain Corlay, Paul Ivanov, Damian Avila, Safia Abdalla, Carol Willing, and Jupyter Development Team. Jupyter notebooks: A publishing format for reproducible computational workflows. InPositioning and ...
-
[7]
Hidden Prompts in Manuscripts Exploit AI-Assisted Peer Review
Zhicheng Lin. Hidden prompts in manuscripts exploit ai-assisted peer review, 2025. URL https: //arxiv.org/abs/2507.06185
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery, 2024. URL https://arxiv.org/abs/ 2408.06292. 16
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Proceedings of the National Academy of Sciences , volume =
Brian A. Nosek, Charles R. Ebersole, Alexander C. DeHaven, and David T. Mellor. The preregistration revolution.Proceedings of the National Academy of Sciences, 115(11):2600–2606, 2018. doi: 10.1073/ pnas.1708274114. URLhttps://www.pnas.org/doi/10.1073/pnas.1708274114
-
[10]
Opening the publication process with executable research compendia.D-Lib Magazine, 23(1/2), 2017
Daniel N¨ust, Markus Konkol, Marc Schutzeichel, Edzer Pebesma, Christian Kray, Holger Przibytzin, and J ¨org Lorenz. Opening the publication process with executable research compendia.D-Lib Magazine, 23(1/2), 2017. doi: 10.1045/january2017-nuest. URL https://www.dlib.org/ dlib/january17/nuest/01nuest.html
-
[11]
Tony Ross-Hellauer. What is open peer review? a systematic review.F1000Research, 6:588, 2017. doi: 10.12688/f1000research.11369.2. URL https://f1000research.com/articles/6-588/ v2
-
[12]
Paper2code: Automating code generation from scientific papers in machine learning, 2025
Minju Seo, Jinheon Baek, Seongyun Lee, and Sung Ju Hwang. Paper2code: Automating code generation from scientific papers in machine learning, 2025. URLhttps://arxiv.org/abs/2504.17192
-
[13]
Siegel, Sayash Kapoor, Nitya Nagdir, Benedikt Stroebl, and Arvind Narayanan
Zachary S. Siegel, Sayash Kapoor, Nitya Nagdir, Benedikt Stroebl, and Arvind Narayanan. Core-bench: Fostering the credibility of published research through a computational reproducibility agent benchmark,
-
[14]
URLhttps://arxiv.org/abs/2409.11363
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
PaperBench: Evaluating AI's Ability to Replicate AI Research
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. Paperbench: Evaluating ai’s ability to replicate ai research, 2025. URL https: //arxiv.org/abs/2504.01848
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Bailey, Ewa Deelman, Yolanda Gil, Brooks Hanson, Michael A
Victoria Stodden, Marcia McNutt, David H. Bailey, Ewa Deelman, Yolanda Gil, Brooks Hanson, Michael A. Heroux, John P. A. Ioannidis, and Michela Taufer. Enhancing reproducibility for com- putational methods.Science, 354(6317):1240–1241, 2016. doi: 10.1126/science.aah6168. URL https://www.science.org/doi/10.1126/science.aah6168
-
[17]
Justice in Judgment: Unveiling (Hidden) Bias in LLM-assisted Peer Reviews
Sai Suresh Macharla Vasu, Ivaxi Sheth, Hui-Po Wang, Ruta Binkyte, and Mario Fritz. Justice in judgment: Unveiling (hidden) bias in llm-assisted peer reviews, 2025. URL https://arxiv.org/ abs/2509.13400
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Schmitt, Moritz Thiele, Raphael Leuner, Denys Shay, Simone Redaelli, and Maximilian S
Dario von Wedel, Rico A. Schmitt, Moritz Thiele, Raphael Leuner, Denys Shay, Simone Redaelli, and Maximilian S. Schaefer. Affiliation bias in peer review of abstracts by a large language model. JAMA, 331(3):252–253, 2024. doi: 10.1001/jama.2023.24641. URL https://jamanetwork. com/journals/jama/fullarticle/2813511
-
[19]
The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search,
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search,
-
[20]
URLhttps://arxiv.org/abs/2504.08066. 17
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.