Breaking the Bubble: Asynchronous Pipeline Parallel Training with Bounded Weight Inconsistency
Pith reviewed 2026-06-27 22:17 UTC · model grok-4.3
The pith
PACI bounds pipeline weight inconsistency with local gradient accumulation to enable bubble-free asynchronous training that matches synchronous stability and perplexity in language model pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
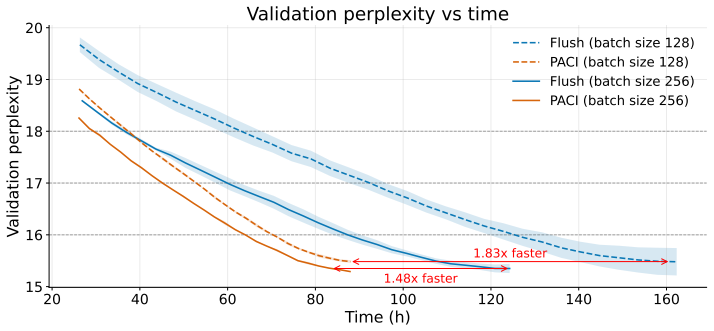
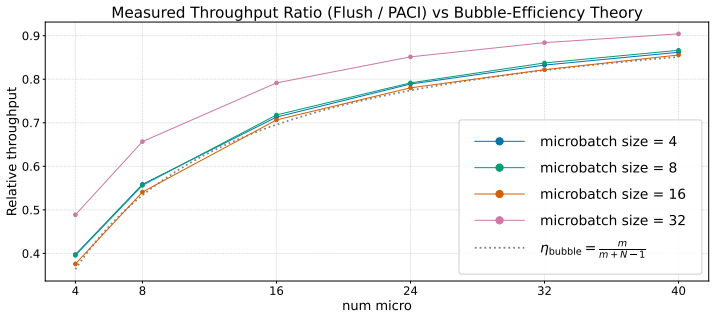
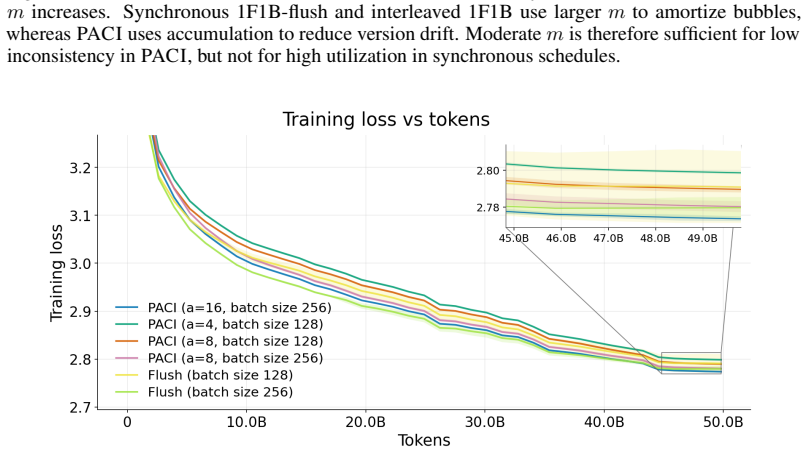
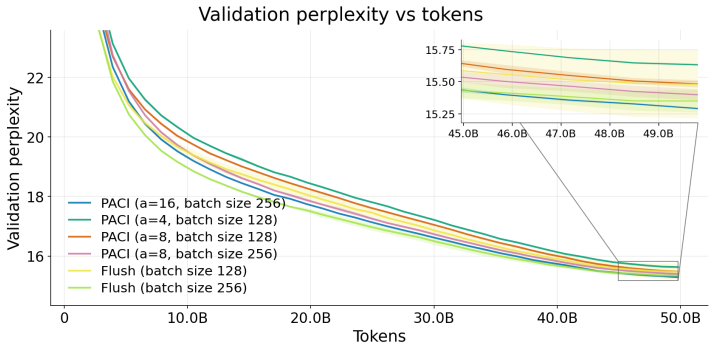
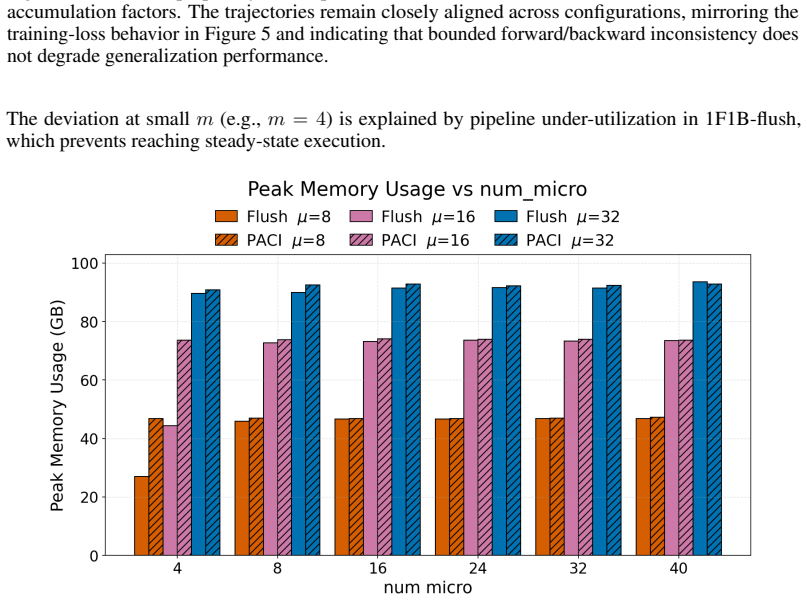
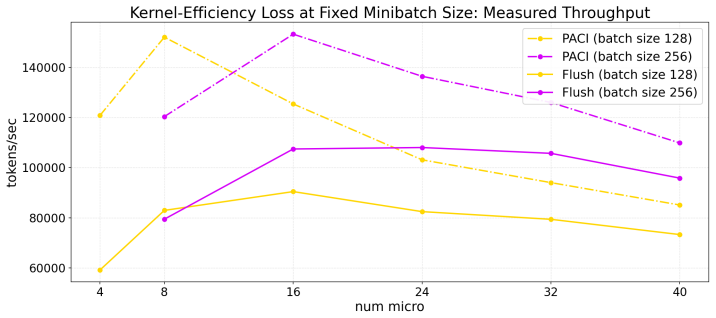
PACI is a bubble-free asynchronous pipeline method that bounds forward/backward version drift without weight stashing, prediction, additional parameter copies, or global synchronization. The key idea is to use local gradient accumulation as a version-control mechanism: by slowing parameter-version evolution relative to pipeline delay, PACI limits the number of optimizer updates crossed by any micro-batch while preserving steady-state utilization. In GPT-style language-model pretraining, PACI matches the stability and final perplexity of synchronous 1F1B-flush, retains the same peak memory footprint, achieves fully utilized pipeline throughput, and improves training time-to-accuracy by up to
What carries the argument
Local gradient accumulation used as a version-control mechanism to bound the number of optimizer updates crossed by any micro-batch in the pipeline
If this is right
- Matches the stability and final perplexity of synchronous 1F1B-flush
- Retains the same peak memory footprint
- Achieves fully utilized pipeline throughput
- Improves training time-to-accuracy by up to 1.69× over the fastest flush baseline
Where Pith is reading between the lines
- The same local-accumulation bound could be tested on other model families to see whether the stability equivalence holds beyond GPT-style transformers.
- Because no global synchronization is required, the approach may tolerate higher network latency between pipeline stages than methods that rely on frequent barriers.
- Varying the number of accumulation steps per micro-batch offers a direct knob for trading throughput against the allowed inconsistency bound in future schedule designs.
Load-bearing premise
Bounding the number of optimizer updates crossed by any micro-batch through local gradient accumulation alone is sufficient to preserve optimization stability and final model quality equivalent to synchronous training without weight stashing, prediction, or global synchronization.
What would settle it
An experiment in which PACI produces measurably higher final perplexity or training instability than synchronous 1F1B-flush on the same GPT-style pretraining run would falsify the claim of equivalent quality.
Figures

read the original abstract
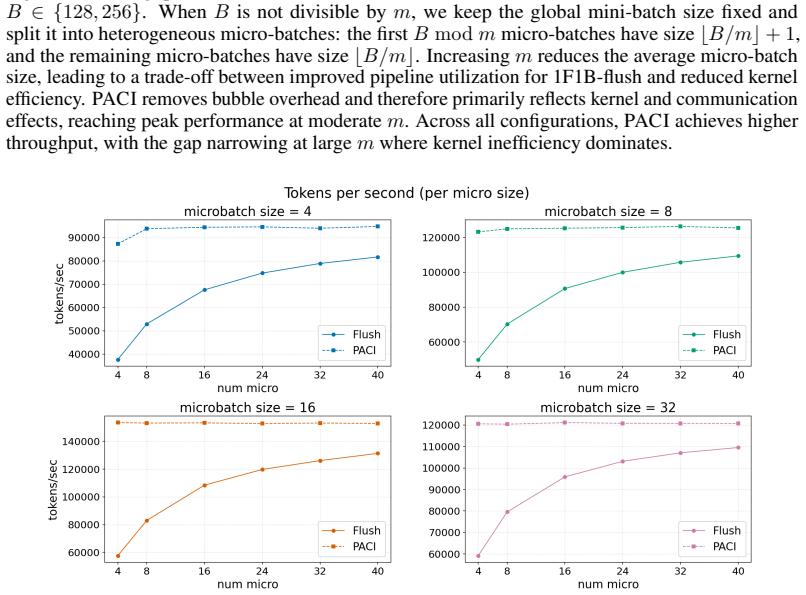
Pipeline parallelism is essential for training large neural networks, but existing schedules trade off throughput, memory, and optimization consistency. Synchronous pipelines preserve forward/backward weight consistency but suffer from bubbles; asynchronous pipelines remove bubbles but introduce weight-version mismatch, typically requiring weight stashing, prediction, or correction mechanisms. We introduce PACI (Pipeline Asynchronous training with Controlled Inconsistency), a bubble-free asynchronous pipeline method that bounds forward/backward version drift without weight stashing, prediction, additional parameter copies, or global synchronization. The key idea is to use local gradient accumulation as a version-control mechanism: by slowing parameter-version evolution relative to pipeline delay, PACI limits the number of optimizer updates crossed by any micro-batch while preserving steady-state utilization. In GPT-style language-model pretraining, PACI matches the stability and final perplexity of synchronous 1F1B-flush, retains the same peak memory footprint, achieves fully utilized pipeline throughput, and improves training time-to-accuracy by up to $1.69\times$ over the fastest flush baseline. These results show that forward/backward inconsistency need not be eliminated: when explicitly bounded, it can be safely traded for substantial efficiency gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PACI, an asynchronous pipeline-parallel training schedule for large neural networks. It uses local gradient accumulation to bound forward/backward weight-version drift without weight stashing, prediction, extra parameter copies, or global synchronization. The central empirical claim is that, in GPT-style language-model pretraining, PACI matches the stability and final perplexity of synchronous 1F1B-flush, retains identical peak memory, achieves full pipeline utilization, and improves time-to-accuracy by up to 1.69× over the fastest flush baseline.
Significance. If the empirical claims hold under rigorous verification, the result would be significant: it shows that an explicitly bounded (but non-zero) weight inconsistency can be safely substituted for more elaborate consistency mechanisms, yielding bubble-free throughput at no extra memory cost. This would simplify pipeline schedules for large-model training and provide a concrete efficiency gain that is directly measurable in wall-clock time-to-accuracy.
major comments (2)
- [Abstract] Abstract: the load-bearing claim that 'bounding the number of optimizer updates crossed by any micro-batch through local gradient accumulation alone' suffices to preserve optimization trajectory and final perplexity equivalent to synchronous 1F1B-flush is stated without any derivation of the resulting version-drift bound, any analysis of cumulative gradient bias, or any ablation on accumulation steps versus pipeline depth. This assumption is exactly the weakest link identified in the stress-test and must be supported either theoretically or by targeted experiments before the central contribution can be accepted.
- [Abstract] Abstract: the reported outcomes (matching stability/perplexity, 1.69× time-to-accuracy, identical peak memory) are presented with no experimental details, model sizes, dataset, baseline implementations, number of runs, or statistical tests. Without these, the soundness of the empirical comparison cannot be assessed; the manuscript must supply a complete methods/results section with reproducible configurations.
minor comments (1)
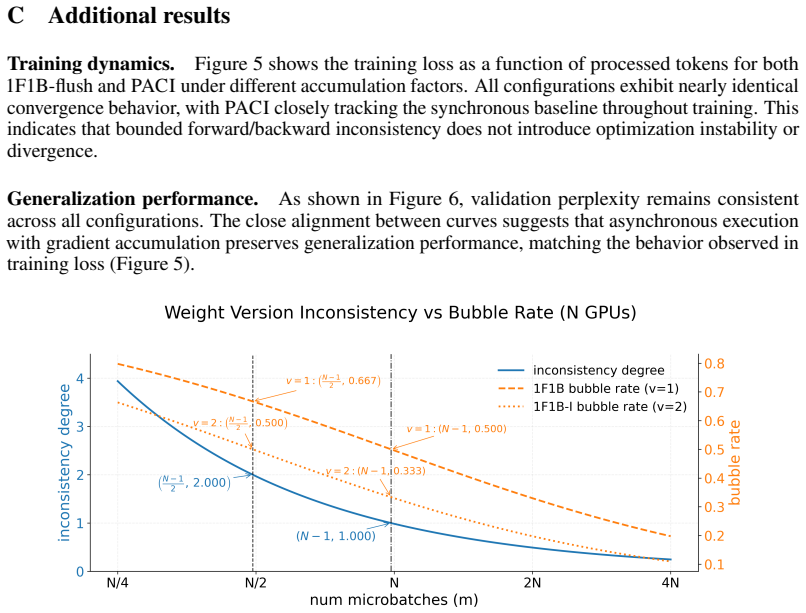
- Notation for 'version drift' and 'optimizer updates crossed' should be defined precisely (e.g., as a function of pipeline stages, micro-batch size, and accumulation steps) the first time it appears.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the manuscript can be strengthened. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the load-bearing claim that 'bounding the number of optimizer updates crossed by any micro-batch through local gradient accumulation alone' suffices to preserve optimization trajectory and final perplexity equivalent to synchronous 1F1B-flush is stated without any derivation of the resulting version-drift bound, any analysis of cumulative gradient bias, or any ablation on accumulation steps versus pipeline depth. This assumption is exactly the weakest link identified in the stress-test and must be supported either theoretically or by targeted experiments before the central contribution can be accepted.
Authors: We agree that additional support for this assumption would strengthen the paper. The current manuscript relies on empirical validation across GPT-style pretraining runs showing equivalent stability and perplexity, but lacks an explicit derivation or ablation. In revision we will add a dedicated subsection deriving the version-drift bound in terms of local accumulation steps and pipeline depth, together with an ablation that varies accumulation steps relative to pipeline stages while measuring gradient bias and final perplexity. This will directly address the identified weakest link. revision: yes
-
Referee: [Abstract] Abstract: the reported outcomes (matching stability/perplexity, 1.69× time-to-accuracy, identical peak memory) are presented with no experimental details, model sizes, dataset, baseline implementations, number of runs, or statistical tests. Without these, the soundness of the empirical comparison cannot be assessed; the manuscript must supply a complete methods/results section with reproducible configurations.
Authors: We agree the abstract omits these details due to length constraints. The full manuscript already contains an Experiments section specifying model sizes, dataset, baseline implementations, run counts, and evaluation protocol. To make the work more self-contained, we will expand the abstract with key configuration parameters and ensure the methods section explicitly lists all hyperparameters, hardware, and statistical procedures for full reproducibility. revision: yes
Circularity Check
No circularity; empirical claims rest on direct comparison
full rationale
The paper introduces PACI as an empirical scheduling technique whose central claims (matching stability/perplexity of synchronous 1F1B-flush while removing bubbles) are supported solely by experimental runs on GPT-style models. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The mechanism (local gradient accumulation to bound version drift) is presented as a design choice whose sufficiency is validated externally by the reported metrics rather than by construction or prior self-referential results. This is the common honest case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Thalaiyasingam Ajanthan, Sameera Ramasinghe, Yan Zuo, Gil Avraham, and Alexander Long. Nesterov method for asynchronous pipeline parallel optimization.arXiv preprint arXiv:2505.01099, 2025
-
[2]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[3]
Chi-Chung Chen, Chia-Lin Yang, and Hsiang-Yun Cheng. Efficient and robust parallel dnn training through model parallelism on multi-gpu platform.arXiv preprint arXiv:1809.02839, 2018
-
[4]
Amdp: Asynchronous multi-directional pipeline parallelism for large-scale models training
Ling Chen, Houming Wu, and Wenjie Yu. Amdp: Asynchronous multi-directional pipeline parallelism for large-scale models training
-
[5]
Dapple: A pipelined data parallel approach for training large models
Shiqing Fan, Yi Rong, Chen Meng, Zongyan Cao, Siyu Wang, Zhen Zheng, Chuan Wu, Guoping Long, Jun Yang, Lixue Xia, et al. Dapple: A pipelined data parallel approach for training large models. InProceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 431–445, 2021
2021
-
[6]
Lei Guan, Wotao Yin, Dongsheng Li, and Xicheng Lu. Xpipe: Efficient pipeline model parallelism for multi-gpu dnn training.arXiv preprint arXiv:1911.04610, 2019
-
[7]
Pipeop- tim: Ensuring effective 1f1b schedule with optimizer-dependent weight prediction.IEEE Transactions on Knowledge and Data Engineering, 2025
Lei Guan, Dongsheng Li, Yongle Chen, Jiye Liang, Wenjian Wang, and Xicheng Lu. Pipeop- tim: Ensuring effective 1f1b schedule with optimizer-dependent weight prediction.IEEE Transactions on Knowledge and Data Engineering, 2025
2025
-
[8]
PipeDream: Fast and Efficient Pipeline Parallel DNN Training
Aaron Harlap, Deepak Narayanan, Amar Phanishayee, Vivek Seshadri, Nikhil Devanur, Greg Ganger, and Phil Gibbons. Pipedream: Fast and efficient pipeline parallel dnn training.arXiv preprint arXiv:1806.03377, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, DDL Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 10, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Ashpipe: Asyn- chronous hybrid pipeline parallel for dnn training
Ryubu Hosoki, Toshio Endo, Takahiro Hirofuchi, and Tsutomu Ikegami. Ashpipe: Asyn- chronous hybrid pipeline parallel for dnn training. InProceedings of the International Confer- ence on High Performance Computing in Asia-Pacific Region, pages 117–126, 2024
2024
-
[11]
Tianjin Huang, Ziquan Zhu, Gaojie Jin, Lu Liu, Zhangyang Wang, and Shiwei Liu. Spam: Spike- aware adam with momentum reset for stable llm training.arXiv preprint arXiv:2501.06842, 2025
-
[12]
Gpipe: Efficient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems, 32, 2019
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, Hy- oukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems, 32, 2019
2019
-
[13]
A Study of BFLOAT16 for Deep Learning Training
Dhiraj Kalamkar, Dheevatsa Mudigere, Naveen Mellempudi, Dipankar Das, Kunal Banerjee, Sasikanth Avancha, Dharma Teja V ooturi, Nataraj Jammalamadaka, Jianyu Huang, Hector Yuen, et al. A study of bfloat16 for deep learning training.arXiv preprint arXiv:1905.12322, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[14]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[15]
Chimera: efficiently training large-scale neural networks with bidirectional pipelines
Shigang Li and Torsten Hoefler. Chimera: efficiently training large-scale neural networks with bidirectional pipelines. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–14, 2021
2021
-
[16]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983, 2016. 10
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
On the sdes and scaling rules for adaptive gradient algorithms.Advances in Neural Information Processing Systems, 35: 7697–7711, 2022
Sadhika Malladi, Kaifeng Lyu, Abhishek Panigrahi, and Sanjeev Arora. On the sdes and scaling rules for adaptive gradient algorithms.Advances in Neural Information Processing Systems, 35: 7697–7711, 2022
2022
-
[19]
Memory- efficient pipeline-parallel dnn training
Deepak Narayanan, Amar Phanishayee, Kaiyu Shi, Xie Chen, and Matei Zaharia. Memory- efficient pipeline-parallel dnn training. InInternational Conference on Machine Learning, pages 7937–7947. PMLR, 2021
2021
-
[20]
Efficient large-scale language model training on gpu clusters using megatron-lm
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, et al. Efficient large-scale language model training on gpu clusters using megatron-lm. In Proceedings of the international conference for high performance computing, networking, s...
2021
-
[21]
Zero bubble pipeline parallelism
Penghui Qi, Xinyi Wan, Guangxing Huang, and Min Lin. Zero bubble pipeline parallelism. arXiv preprint arXiv:2401.10241, 2023
-
[22]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
2019
-
[23]
Zero: Memory optimiza- tions toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimiza- tions toward training trillion parameter models. InSC20: international conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020
2020
-
[24]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[25]
Ao Sun, Weilin Zhao, Xu Han, Cheng Yang, Xinrong Zhang, Zhiyuan Liu, Chuan Shi, and Maosong Sun. Seq1f1b: Efficient sequence-level pipeline parallelism for large language model training.arXiv preprint arXiv:2406.03488, 2024
-
[26]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[27]
Pipemare: Asynchronous pipeline parallel dnn training.Proceedings of Machine Learning and Systems, 3:269–296, 2021
Bowen Yang, Jian Zhang, Jonathan Li, Christopher Ré, Christopher Aberger, and Christopher De Sa. Pipemare: Asynchronous pipeline parallel dnn training.Proceedings of Machine Learning and Systems, 3:269–296, 2021
2021
-
[28]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, et al. Pytorch fsdp: experiences on scaling fully sharded data parallel.arXiv preprint arXiv:2304.11277, 2023. 11 A Detailed comparison of pipeline parallelism methods Table 5: Detailed trade-offs in pipeline parallelism methods...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Throughput.Pipeline throughput is bottle-necked by the slowest stage; we therefore want to minimize the maximum stage time maxj T(G j), where T(G j) is the sum of the per-layer forward times inG j
-
[30]
Per-device memory.To approximate the steady state memory footprint of a particular split, we split the per-layer footprint into astaticcomponent sℓ - parameters, gradients and optimizer state, which are resident on the stage regardless of pipeline occupancy — and a per-micro-batchactivationcomponent aℓ, the bytes saved by autograd for the backward pass on...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.