Partially Performative Prediction
Pith reviewed 2026-06-27 22:12 UTC · model grok-4.3
The pith
Partially performative prediction models distribution shifts from both model influence and external time variation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The data distribution evolves both in response to the deployed model and according to an external time-varying process. Online analogues of performative stability and performative optimality are defined to track this evolving partially performative environment. Repeated retraining is analyzed as a practical heuristic, with conditions identified for when it successfully adapts.
What carries the argument
The partially performative prediction framework, which decomposes the data distribution into a model-responsive component and an independent external time-varying process.
If this is right
- Repeated retraining adapts to the environment when the rates of model-induced and external shifts satisfy the derived conditions.
- Online performative stability provides a moving target that learning procedures can track over time.
- Performative optimality extends to a sequence of time-dependent targets rather than a single fixed point.
Where Pith is reading between the lines
- Deployed systems in recommendation or pricing could estimate external drift rates separately to set retraining schedules.
- The decomposition might apply to multi-model environments where each model's effect combines with shared external trends.
- Simulations with controlled external time series could test whether measured adaptation error matches the predicted conditions.
Load-bearing premise
The distribution shift can be cleanly separated into a model-responsive part and an independent external process whose changes do not depend on the model.
What would settle it
An experiment showing that the external process changes in direct response to model deployment in a manner that breaks the independence, causing repeated retraining to fail where the framework predicts success.
Figures
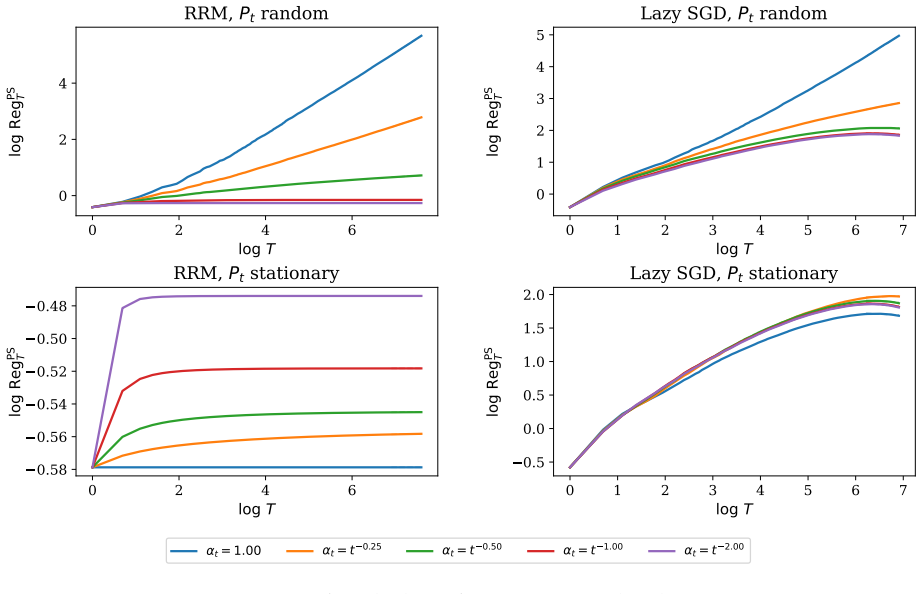
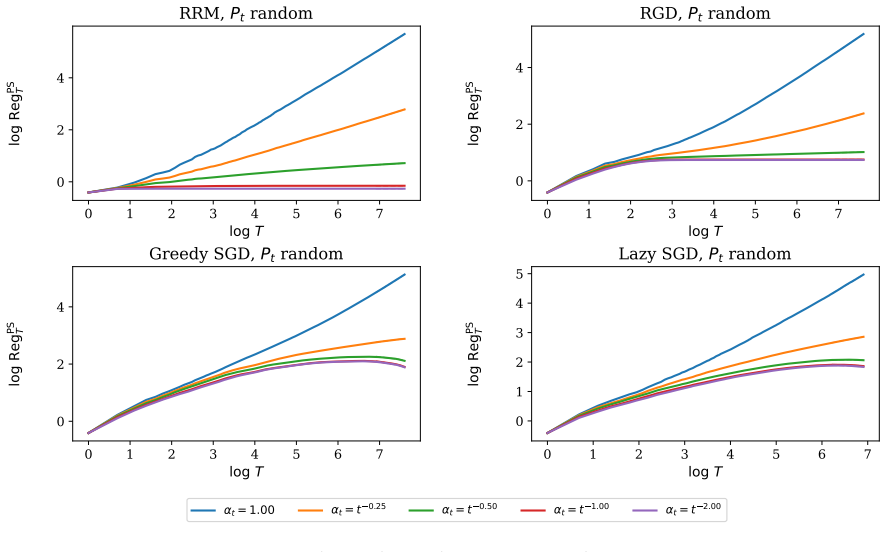
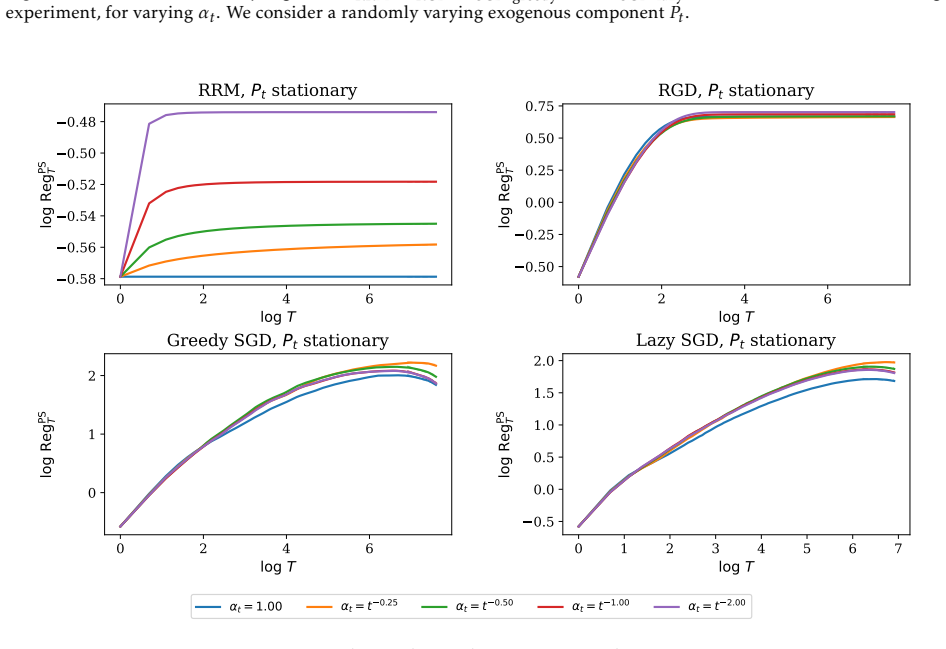
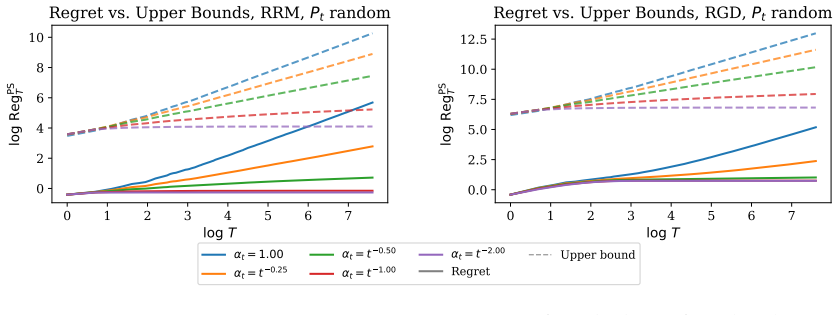
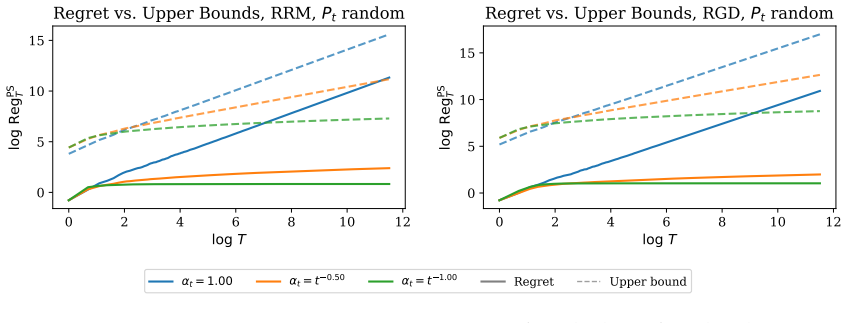
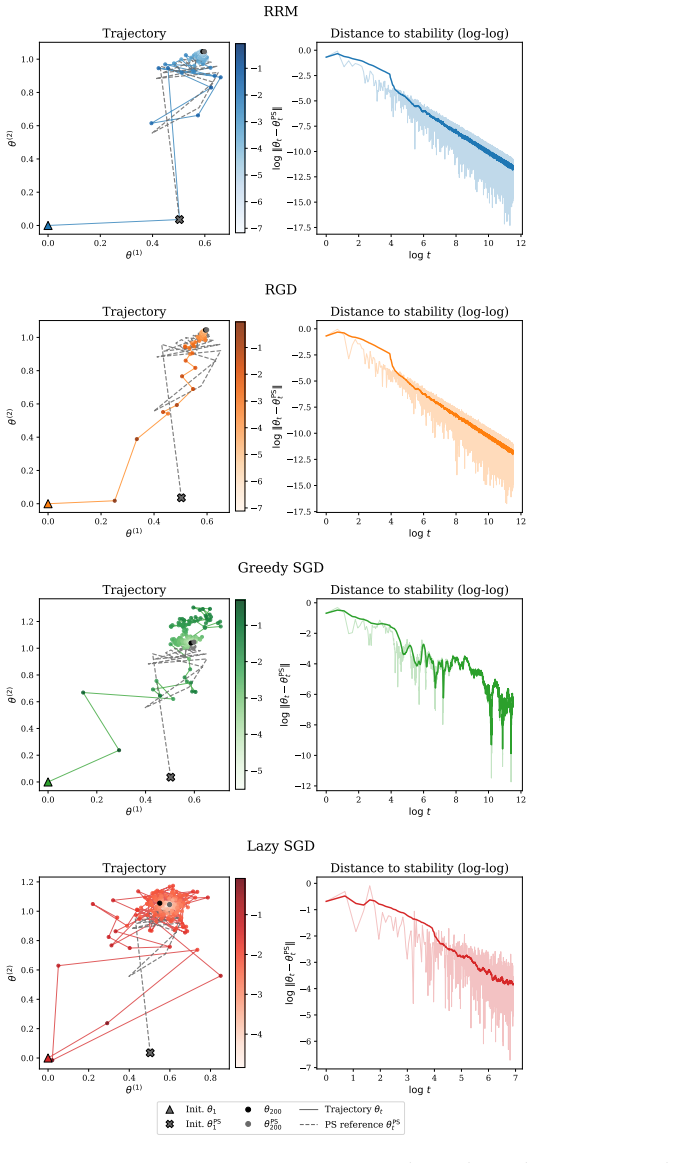
read the original abstract
Performative prediction studies feedback loops that arise when predictive models are deployed in consequential domains. In these settings, deploying a model can change the population whose patterns the model aims to predict, inducing a distribution shift that is endogenous to the learning system. This perspective departs from classical treatments of distribution shift, where shifts are typically modeled as exogenous changes in the data-generating process. Yet, in practice, distribution shift is rarely one or the other. Predictive models may influence future data through the decisions they support, while the world itself continues to drift for reasons beyond the learner's control. We study partially performative prediction, a framework that captures both endogenous and exogenous sources of distribution shift. The framework generalizes performative prediction by allowing the data distribution to evolve both in response to the deployed model and according to an external, time-varying process. We extend the central notions of performative stability and performative optimality to this setting by defining their online analogues that track the evolving partially performative environment. We analyze practical learning heuristics, including repeated retraining, and characterize when they successfully adapt to partially performative environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces partially performative prediction as a generalization of performative prediction. It models distribution shift as arising from both an endogenous response to the deployed model and an independent exogenous time-varying external process. The work extends performative stability and optimality to online analogues that track the evolving environment and analyzes practical heuristics such as repeated retraining, characterizing conditions under which they adapt successfully.
Significance. If the decomposition, online stability definitions, and retraining analysis are rigorously developed with clear theorems and examples, the framework would usefully bridge performative prediction and classical exogenous-shift literature, offering a more realistic model for deployed systems. The emphasis on online analogues and heuristic analysis addresses a practical gap, but the abstract provides no derivations, proofs, or results with which to evaluate whether these extensions are non-vacuous or yield new insights.
major comments (1)
- [Abstract] Abstract: the central claim that the framework 'generalizes performative prediction' and that repeated retraining 'successfully adapt[s]' cannot be assessed; no definitions of the decomposition, no statements of the online stability or optimality notions, and no theorems or experiments are available to verify internal consistency or non-triviality.
Simulated Author's Rebuttal
We thank the referee for their review and summary of the work. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the framework 'generalizes performative prediction' and that repeated retraining 'successfully adapt[s]' cannot be assessed; no definitions of the decomposition, no statements of the online stability or optimality notions, and no theorems or experiments are available to verify internal consistency or non-triviality.
Authors: Abstracts are concise summaries by design and do not include formal definitions, theorems, or proofs. The full manuscript develops these elements in detail: Section 2 defines the partially performative framework and the decomposition of distribution shift into endogenous (model-induced) and exogenous (time-varying external) components; Section 3 introduces the online analogues of performative stability and optimality with formal statements; Section 4 provides theorems characterizing conditions under which repeated retraining adapts successfully, along with illustrative examples. These sections contain the requested technical content for assessing internal consistency and non-triviality. revision: no
Circularity Check
No significant circularity
full rationale
The paper defines partially performative prediction as a direct generalization that decomposes distribution shift into an endogenous model-responsive component plus an independent exogenous time-varying process. Central notions of stability and optimality are extended by explicit online analogues constructed from this decomposition, and analysis of repeated retraining follows from the stated framework. No equations, predictions, or load-bearing claims reduce to fitted inputs, self-citations, or prior author results by construction; the work is self-contained as a definitional extension.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Optimal algorithms for online convex optimization with multi-point bandit feedback
Alekh Agarwal, Ofer Dekel, and Lin Xiao. Optimal algorithms for online convex optimization with multi-point bandit feedback. InConference on Learning Theory (COLT), 2010
2010
-
[2]
Performative prediction in a stateful world
Gavin Brown, Shlomi Hod, and Iden Kalemaj. Performative prediction in a stateful world. InInternational confer- ence on artificial intelligence and statistics, pages 6045–6061. PMLR, 2022
2022
-
[3]
Performative prediction with bandit feedback: Learning through reparameterization
Yatong Chen, Wei Tang, Chien-Ju Ho, and Yang Liu. Performative prediction with bandit feedback: Learning through reparameterization. InInternational Conference on Machine Learning, pages 7298–7324. PMLR, 2024
2024
-
[4]
Stochastic optimization with decision-dependent distributions.Mathematics of Operations Research, 48(2):954–998, 2023
Dmitriy Drusvyatskiy and Lin Xiao. Stochastic optimization with decision-dependent distributions.Mathematics of Operations Research, 48(2):954–998, 2023
2023
-
[5]
The Stability of Online Algorithms in Performative Prediction
Gabriele Farina and Juan Carlos Perdomo. The stability of online algorithms in performative prediction.arXiv preprint arXiv:2602.24207, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Flaxman, Adam Tauman Kalai, and H
Abraham D. Flaxman, Adam Tauman Kalai, and H. Brendan McMahan. Online convex optimization in the bandit setting: gradient descent without a gradient. InProceedings of the Sixteenth Annual ACM-SIAM Symposium on Discrete Algorithms, 2005
2005
-
[7]
Performative prediction: Past and future.Statistical Science, 40(3): 417–436, 2025
Moritz Hardt and Celestine Mendler-D ¨unner. Performative prediction: Past and future.Statistical Science, 40(3): 417–436, 2025
2025
-
[8]
Algorithmic collective action in machine learning
Moritz Hardt, Eric Mazumdar, Celestine Mendler-D ¨unner, and Tijana Zrnic. Algorithmic collective action in machine learning. InInternational Conference on Machine Learning, pages 12570–12586. PMLR, 2023
2023
-
[9]
Introduction to online convex optimization.Foundations and Trends in Optimization, 2(3-4):157–325, 2016
Elad Hazan. Introduction to online convex optimization.Foundations and Trends in Optimization, 2(3-4):157–325, 2016
2016
-
[10]
Tracking the best expert.Machine learning, 32(2):151–178, 1998
Mark Herbster and Manfred K Warmuth. Tracking the best expert.Machine learning, 32(2):151–178, 1998
1998
-
[11]
How to learn when data reacts to your model: performative gradient descent
Zachary Izzo, Lexing Ying, and James Zou. How to learn when data reacts to your model: performative gradient descent. InInternational Conference on Machine Learning, pages 4641–4650. PMLR, 2021
2021
-
[12]
How to learn when data gradually reacts to your model
Zachary Izzo, James Zou, and Lexing Ying. How to learn when data gradually reacts to your model. InInterna- tional Conference on Artificial Intelligence and Statistics, pages 3998–4035. PMLR, 2022
2022
-
[13]
Online optimization: Competing with dynamic comparators
Ali Jadbabaie, Alexander Rakhlin, Shahin Shahrampour, and Karthik Sridharan. Online optimization: Competing with dynamic comparators. InInternational Conference on Artificial Intelligence and Statistics, pages 398–406. PMLR, 2015
2015
-
[14]
Regret minimization with performative feed- back
Meena Jagadeesan, Tijana Zrnic, and Celestine Mendler-D ¨unner. Regret minimization with performative feed- back. InInternational Conference on Machine Learning, pages 9760–9785. PMLR, 2022
2022
-
[15]
Dissecting perfor- mative prediction: A comprehensive survey.ACM Computing Surveys, 2026
Thomas Kehrenberg, Francisco Javier Sanguino Bautiste, Jose Lozano, and Novi Quadrianto. Dissecting perfor- mative prediction: A comprehensive survey.ACM Computing Surveys, 2026
2026
-
[16]
Making decisions under outcome performativity
Michael P Kim and Juan C Perdomo. Making decisions under outcome performativity. In14th Innovations in Theoretical Computer Science Conference (ITCS 2023), volume 251, page 79, 2023
2023
-
[17]
State dependent performative prediction with stochastic approximation
Qiang Li and Hoi-To Wai. State dependent performative prediction with stochastic approximation. InInternational Conference on Artificial Intelligence and Statistics, pages 3164–3186. PMLR, 2022
2022
-
[18]
Plug-in performative optimization
Licong Lin and Tijana Zrnic. Plug-in performative optimization. InInternational Conference on Machine Learning, pages 30546–30565, 2024. 12
2024
-
[19]
Two-timescale derivative free optimization for performative prediction with markovian data
Haitong Liu, Qiang Li, and Hoi To Wai. Two-timescale derivative free optimization for performative prediction with markovian data. InInternational Conference on Machine Learning, pages 31425–31450. PMLR, 2024
2024
-
[20]
Stochastic optimization for performa- tive prediction.Advances in Neural Information Processing Systems, 33:4929–4939, 2020
Celestine Mendler-D ¨unner, Juan Perdomo, Tijana Zrnic, and Moritz Hardt. Stochastic optimization for performa- tive prediction.Advances in Neural Information Processing Systems, 33:4929–4939, 2020
2020
-
[21]
Outside the echo chamber: Optimizing the performative risk
John P Miller, Juan C Perdomo, and Tijana Zrnic. Outside the echo chamber: Optimizing the performative risk. InInternational Conference on Machine Learning, pages 7710–7720. PMLR, 2021
2021
-
[22]
Performative prediction with neural networks
Mehrnaz Mofakhami, Ioannis Mitliagkas, and Gauthier Gidel. Performative prediction with neural networks. In International Conference on Artificial Intelligence and Statistics, pages 11079–11093. PMLR, 2023
2023
-
[23]
Online optimization in dynamic environments: Improved regret rates for strongly convex problems
Aryan Mokhtari, Shahin Shahrampour, Ali Jadbabaie, and Alejandro Ribeiro. Online optimization in dynamic environments: Improved regret rates for strongly convex problems. InIEEE Conference on Decision and Control (CDC), 2016
2016
-
[24]
Multiplayer perfor- mative prediction: Learning in decision-dependent games.Journal of Machine Learning Research, 24(202):1–56, 2023
Adhyyan Narang, Evan Faulkner, Dmitriy Drusvyatskiy, Maryam Fazel, and Lillian J Ratliff. Multiplayer perfor- mative prediction: Learning in decision-dependent games.Journal of Machine Learning Research, 24(202):1–56, 2023
2023
-
[25]
Sungwoo Park, Junyeop Kwon, Byeongnoh Kim, Suhyun Chae, Jeeyong Lee, and Dabeen Lee. Parameter- free algorithms for performative regret minimization under decision-dependent distributions.arXiv preprint arXiv:2402.15188, 2024
-
[26]
Performative prediction
Juan Perdomo, Tijana Zrnic, Celestine Mendler-D ¨unner, and Moritz Hardt. Performative prediction. InInterna- tional Conference on Machine Learning, pages 7599–7609. PMLR, 2020
2020
-
[27]
Revisiting the predictability of performative, social events
Juan Carlos Perdomo. Revisiting the predictability of performative, social events. InInternational Conference on Machine Learning, pages 48948–48961. PMLR, 2025
2025
-
[28]
Decision-dependent risk minimization in geometrically decaying dynamic environments
Mitas Ray, Lillian J Ratliff, Dmitriy Drusvyatskiy, and Maryam Fazel. Decision-dependent risk minimization in geometrically decaying dynamic environments. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 8081–8088, 2022
2022
-
[29]
Actionable recourse in linear classification
Berk Ustun, Alexander Spangher, and Yang Liu. Actionable recourse in linear classification. InProceedings of the Conference on Fairness, Accountability, and Transparency, page 10–19. Association for Computing Machinery, 2019
2019
-
[30]
Network effects in performative prediction games
Xiaolu Wang, Chung-Yiu Yau, and Hoi To Wai. Network effects in performative prediction games. InInternational Conference on Machine Learning, pages 36514–36540. PMLR, 2023
2023
-
[31]
Distributionally robust performative prediction
Songkai Xue and Yuekai Sun. Distributionally robust performative prediction. InAdvances in Neural Information Processing Systems, volume 37, pages 55030–55052, 2024
2024
-
[32]
Zero-regret performative prediction under inequality constraints.Advances in Neural Information Processing Systems, 36:1298–1308, 2023
Wenjing Yan and Xuanyu Cao. Zero-regret performative prediction under inequality constraints.Advances in Neural Information Processing Systems, 36:1298–1308, 2023
2023
-
[33]
Tracking slowly moving clairvoyant: Optimal dynamic regret of online learning with true and noisy gradient
Tianbao Yang, Lijun Zhang, Rong Jin, and Jinfeng Yi. Tracking slowly moving clairvoyant: Optimal dynamic regret of online learning with true and noisy gradient. InInternational Conference on Machine Learning, pages 449–457. PMLR, 2016
2016
-
[34]
The comparisons of data mining techniques for the predictive accuracy of proba- bility of default of credit card clients.Expert systems with applications, 36(2):2473–2480, 2009
I-Cheng Yeh and Che-hui Lien. The comparisons of data mining techniques for the predictive accuracy of proba- bility of default of credit card clients.Expert systems with applications, 36(2):2473–2480, 2009
2009
-
[35]
Improved dynamic regret for non- degenerate functions
Lijun Zhang, Tianbao Yangt, Jinfeng Yi, Rong Jin, and Zhi-Hua Zhou. Improved dynamic regret for non- degenerate functions. InInternational Conference on Neural Information Processing Systems, page 732–741. Curran Associates Inc., 2017
2017
-
[36]
Bandit convex optimization in non-stationary environments
Peng Zhao, Guanghui Wang, Lijun Zhang, and Zhi-Hua Zhou. Bandit convex optimization in non-stationary environments. InInternational conference on artificial intelligence and statistics, 2020
2020
-
[37]
Look-ahead reasoning on learning platforms.Advances in Neural Information Processing Systems, 38:82399–82422, 2025
Haiqing Zhu, Tijana Zrnic, and Celestine Mendler-D¨unner. Look-ahead reasoning on learning platforms.Advances in Neural Information Processing Systems, 38:82399–82422, 2025
2025
-
[38]
Online convex programming and generalized infinitesimal gradient ascent
Martin Zinkevich. Online convex programming and generalized infinitesimal gradient ascent. InInternational Conference on Machine Learning, 2003. 13 A Auxiliary lemmas Lemma A.1.Suppose that we have a recursive inequality of the form Ft+1 ≤γ tFt +∆ t. Then we have TX t=1 (1−γ t)Ft ≤F 1 −γ T FT + T−1X t=1 ∆t.(14) Proof.Since we have (1−γ t)Ft ≤F t −F t+1 +∆...
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.