TBD-VLA: Temporal Block Diffusion Vision Language Action Model
Pith reviewed 2026-06-27 21:47 UTC · model grok-4.3
The pith
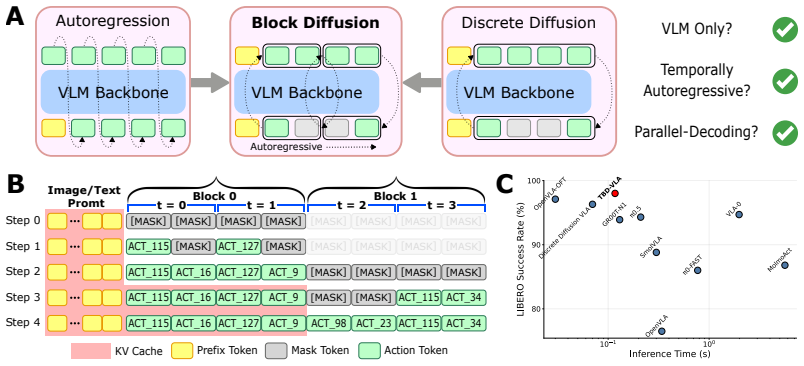
TBD-VLA partitions action sequences into temporal blocks for masked discrete diffusion inside each block and autoregressive generation across blocks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
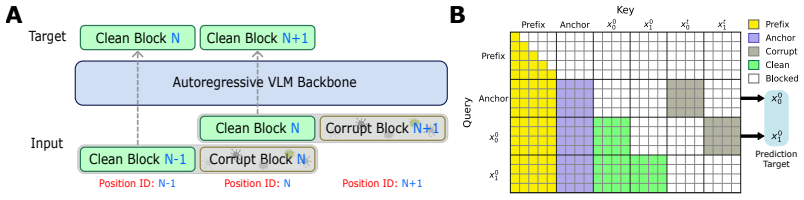
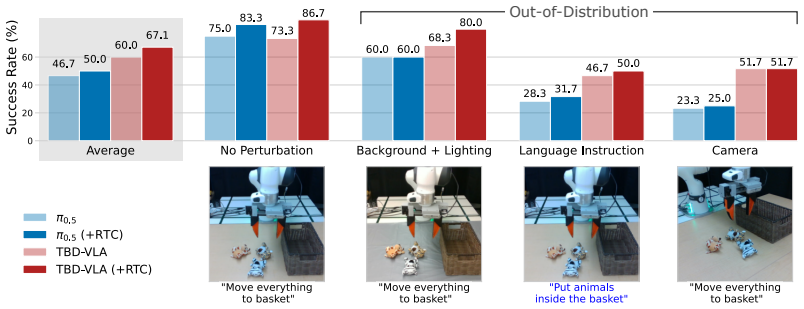
TBD-VLA partitions action sequences into temporal blocks and performs masked discrete diffusion within each block while maintaining autoregressive generation across blocks. This design unifies temporal autoregression and parallel action decoding, achieving both strong temporal coherence and improved inference speed. The explicit temporal modeling enables asynchronous execution of action chunks via temporal in-painting. TBD-VLA significantly outperforms prior VLA approaches in both simulation and real-world manipulation tasks.
What carries the argument
Temporal block diffusion: action sequences are split into blocks so that masked discrete diffusion operates in parallel inside each block while autoregression connects blocks sequentially.
If this is right
- The model outperforms prior VLA approaches in simulation and real-world manipulation tasks.
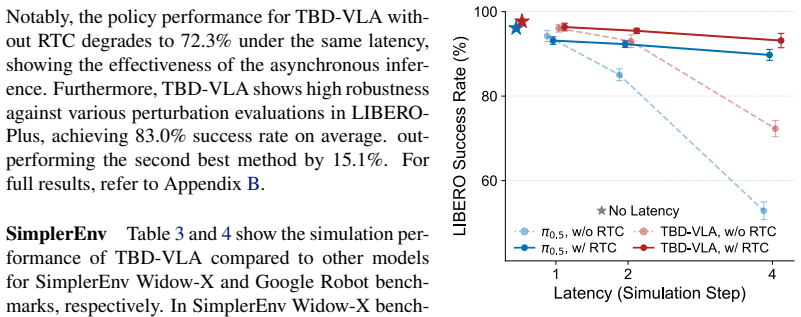
- Explicit temporal modeling supports asynchronous execution of action chunks such as Real-Time Chunking.
- The approach supplies a scalable route to fast yet temporally aware discrete VLA models.
- Inference speed improves while temporal coherence in action trajectories is retained.
Where Pith is reading between the lines
- The block structure may let models update or replace only later action chunks when fresh sensor data arrives, without recomputing the full sequence.
- Similar block-wise diffusion could be tested on other sequential generation problems that need both order and parallelism, such as video frame prediction.
- Faster inference might allow discrete VLA policies to run on lower-power hardware while still handling multi-second action horizons.
Load-bearing premise
Splitting action sequences into temporal blocks and applying masked diffusion inside them while keeping autoregression between blocks will preserve token dependencies without introducing new modeling failures.
What would settle it
A head-to-head evaluation on the paper's simulation and real-world manipulation benchmarks in which TBD-VLA shows neither higher task success rates nor lower inference latency than standard autoregressive discrete VLA baselines would falsify the performance claim.
Figures




read the original abstract
Discrete Vision-Language-Action (VLA) models typically formulate action generation as next-token prediction over discretized action spaces, conditioning each token autoregressively on prior context. While effective, this paradigm incurs high inference latency and largely ignores the temporal structure inherent in action trajectories. Recent efforts introduce parallel decoding to improve efficiency, enabling faster inference, but lack explicit mechanisms for modeling token dependencies. We introduce TBD-VLA, a discrete token-based VLA framework that incorporates block diffusion to enable temporal action generation. We partition action sequences into temporal blocks and perform masked discrete diffusion within each block, while maintaining autoregressive generation across blocks. This design unifies temporal autoregression and parallel action decoding, achieving both strong temporal coherence and improved inference speed. In addition, the explicit temporal modeling enables asynchronous execution of action chunks (e.g., Real-Time Chunking) via temporal in-painting. TBD-VLA significantly outperforms prior VLA approaches in both simulation and real-world manipulation tasks, offering a scalable path toward fast, temporally aware, discrete VLA models. Project webpage: https://tbd-vla.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TBD-VLA, a discrete VLA framework that partitions action sequences into temporal blocks, performs masked discrete diffusion within each block, and maintains autoregressive generation across blocks. This is claimed to unify temporal autoregression with parallel decoding for improved coherence and speed, while also enabling asynchronous execution via temporal in-painting. The abstract asserts that TBD-VLA significantly outperforms prior VLA approaches in both simulation and real-world manipulation tasks.
Significance. If the outperformance claims hold under rigorous evaluation, the block-diffusion design could offer a practical route to faster, temporally structured discrete VLA models, addressing a key tension between inference latency and action coherence in robotic control.
major comments (2)
- [Abstract] Abstract: the central claim that TBD-VLA 'significantly outperforms prior VLA approaches' is unsupported by any metrics, baselines, ablation studies, error analysis, or experimental details, preventing any assessment of the empirical contribution.
- [Abstract] Abstract: the design claim that intra-block masked diffusion plus inter-block autoregression will produce both strong temporal coherence and improved speed without new dependency failures is presented without equations, diffusion schedule, or coherence analysis, leaving the weakest modeling assumption untested.
Simulated Author's Rebuttal
We thank the referee for highlighting issues in the abstract. We agree that the abstract should better ground its claims and will revise it accordingly while preserving its concise nature. The full manuscript contains the supporting experiments, equations, and analyses referenced below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that TBD-VLA 'significantly outperforms prior VLA approaches' is unsupported by any metrics, baselines, ablation studies, error analysis, or experimental details, preventing any assessment of the empirical contribution.
Authors: We acknowledge that the abstract states the outperformance claim without quantitative details. The full manuscript (Sections 4 and 5) reports simulation and real-world results with metrics, baselines (including prior VLA models), ablations on block size and diffusion steps, and error analyses. To address the concern directly in the abstract, we will revise it to include key quantitative results (e.g., success rate improvements and latency reductions) and a brief reference to the evaluation protocol. revision: yes
-
Referee: [Abstract] Abstract: the design claim that intra-block masked diffusion plus inter-block autoregression will produce both strong temporal coherence and improved speed without new dependency failures is presented without equations, diffusion schedule, or coherence analysis, leaving the weakest modeling assumption untested.
Authors: The abstract summarizes the high-level design. The manuscript provides the full formulation in Section 3, including the masked discrete diffusion objective within blocks, the autoregressive conditioning across blocks, the diffusion schedule, and analysis of temporal coherence via dependency modeling. Experiments in Section 4 validate the coherence and speed claims through ablations. We will revise the abstract to more explicitly note that these elements are formalized and tested in the paper, without adding equations to the abstract itself. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper is an architectural proposal for TBD-VLA that partitions action sequences into temporal blocks, applies masked discrete diffusion intra-block, and autoregression inter-block. No equations, parameter-fitting steps, predictions, or self-citations appear in the provided text. Claims of unification and outperformance are presented as design consequences and empirical results rather than derivations that reduce to their own inputs by construction. The central description is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, b. ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Walke...
-
[2]
URLhttps://proceedings.mlr.press/v305/black25a
PMLR, 27–30 Sep 2025. URLhttps://proceedings.mlr.press/v305/black25a. html
2025
-
[3]
Bjorck, N
NVIDIA, J. Bjorck, N. C. Fernando Casta ˜neda, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Yu, ...
2025
-
[4]
Pertsch, K
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. FAST: Efficient action tokenization for vision-language-action models. InRobotics: Science and Systems, 2025. URLhttps://roboticsconference.org/program/papers/ 12/
2025
-
[5]
Y . Wang, H. Zhu, M. Liu, J. Yang, H.-S. Fang, and T. He. VQ-VLA: Improving vision- language-action models via scaling vector-quantized action tokenizers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11089–11099, 2025
2025
-
[6]
C. Liu, X. Han, J. Gao, Y . Zhao, H. Chen, and Y . Du. OAT: Ordered action tokenization. In Robotics: Science and Systems, 2026. URLhttps://github.com/Chaoqi-LIU/oat
2026
-
[7]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Opti- mizing speed and success. InRobotics: Science and Systems, 2025. URLhttps:// roboticsconference.org/program/papers/22/
2025
-
[8]
Liang, Y
Z. Liang, Y . Li, T. Yang, C. Wu, S. Mao, L. Pei, X. Yang, J. Pang, Y . Mu, and P. Luo. Discrete diffusion VLA: Bringing discrete diffusion to action decoding in vision-language-action poli- cies. InThe F ourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=YWeNCMxdhM
2026
-
[9]
Arriola, A
M. Arriola, A. Gokaslan, J. Chiu, Z. Yang, Z. Qi, J. Han, S. Sahoo, and V . Kuleshov. Block dif- fusion: Interpolating between autoregressive and diffusion language models. InInternational Conference on Learning Representations, volume 2025, pages 50726–50753, 2025
2025
-
[10]
C. Wu, H. Zhang, S. Xue, S. Diao, Y . Fu, Z. Liu, P. Molchanov, P. Luo, S. Han, and E. Xie. Fast-dLLM v2: Efficient block-diffusion LLM. InThe F ourteenth International Con- ference on Learning Representations, 2026. URLhttps://openreview.net/forum?id= 1NZ3DHF9nT
2026
-
[11]
Black, M
K. Black, M. Y . Galliker, and S. Levine. Real-time execution of action chunking flow policies. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=UkR2zO5uww
2026
-
[12]
Sohl-Dickstein, E
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In F. Bach and D. Blei, editors,Proceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pages 2256–2265, Lille, France, 07–09 Jul 2015. PMLR. URLhttps: //procee...
2015
-
[13]
S. Nie, F. Zhu, Z. You, X. Zhang, J. Ou, J. Hu, J. Zhou, Y . Lin, J.-R. Wen, and C. Li. Large language diffusion models.Advances in Neural Information Processing Systems, 38:50608– 50646, 2026
2026
-
[14]
S. S. Sahoo, M. Arriola, Y . Schiff, A. Gokaslan, E. Marroquin, J. T. Chiu, A. Rush, and V . Kuleshov. Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
2024
-
[15]
A. Swerdlow, M. Prabhudesai, S. Gandhi, D. Pathak, and K. Fragkiadaki. Unified multimodal discrete diffusion.arXiv preprint arXiv:2503.20853, 2025
arXiv 2025
-
[16]
L. Yang, Y . Tian, B. Li, X. Zhang, K. Shen, Y . Tong, and M. Wang. Mmada: Multimodal large diffusion language models.Advances in Neural Information Processing Systems, 38: 138867–138907, 2026
2026
-
[17]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. In P. Agrawal, O. Kroe- mer, and W. Burgard, editors,Proceedings of The 8th Conference on Robot L...
-
[18]
URLhttps://proceedings.mlr.press/v270/kim25c.html
-
[19]
W. Song, J. Chen, S. Chen, J. Wang, P. Ding, H. Zhao, Y . Qin, X. Zheng, D. Wang, Y . Wang, et al. Fast-dvla: Accelerating discrete diffusion vla to real-time performance.arXiv preprint arXiv:2603.25661, 2026
Pith/arXiv arXiv 2026
-
[20]
J. Chen, W. Song, P. Ding, Z. Zhou, H. Zhao, F. Tang, D. Wang, and H. Li. Unified diffusion VLA: Vision-language-action model via joint discrete denoising diffusion process. InThe F ourteenth International Conference on Learning Representations, 2026. URLhttps:// openreview.net/forum?id=a4487c0ccbdde853b9fe256554903e70db5f15e2
2026
-
[21]
Y . Wen, H. Li, K. Gu, Y . Zhao, T. Wang, and X. Sun. LLaDA-VLA: Vision language diffusion action models.arXiv preprint arXiv:2509.06932, 2025
arXiv 2025
-
[22]
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, et al. Smolvla: A vision-language-action model for afford- able and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
Pith/arXiv arXiv 2025
-
[23]
J. Lee, J. Duan, H. Fang, Y . Deng, S. Liu, B. Li, B. Fang, J. Zhang, Y . R. Wang, S. Lee, et al. Molmoact: Action reasoning models that can reason in space.arXiv preprint arXiv:2508.07917, 2025
Pith/arXiv arXiv 2025
- [24]
-
[25]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[26]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. InAdvances in Neural Information Processing Systems, volume 36, pages 44776–44791, 2023. URLhttps://proceedings.neurips.cc/paper_files/paper/2023/hash/ 8c3c666820ea055a77726d66fc7d447f-Abstract-Datasets_and_Benchmarks.html
2023
-
[27]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, J. Fu, J. Gong, and X. Qiu. LIBERO-Plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025. 11
Pith/arXiv arXiv 2025
-
[28]
X. Li, K. Hsu, J. Gu, O. Mees, K. Pertsch, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kir- mani, S. Levine, J. Wu, C. Finn, H. Su, Q. Vuong, and T. Xiao. Evaluating real-world robot manipulation policies in simulation. In P. Agrawal, O. Kroemer, and W. Burgard, editors,Proceedings of The 8th Conference on Robot Learning, volume 270 ofProceed- ings of Mac...
2025
-
[29]
Y . Wang, X. Li, W. Wang, J. Zhang, Y . Li, Y . Chen, X. Wang, and Z. Zhang. Unified vision- language-action model.arXiv preprint arXiv:2506.19850, 2025
arXiv 2025
-
[30]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
2024
-
[31]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and RT-X models. In2024 IEEE International Conference on Robotics and Automation, pages 6892–6903. IEEE, 2024
2024
-
[32]
Kumar, R
V . Kumar, R. Shah, G. Zhou, V . Moens, V . Caggiano, A. Gupta, and A. Ra- jeswaran. RoboHive: A unified framework for robot learning. InAdvances in Neural Information Processing Systems, volume 36, pages 44323–44340,
-
[33]
URLhttps://papers.neurips.cc/paper_files/paper/2023/hash/ 8a84a4341c375b8441b36836bb343d4e-Abstract-Datasets_and_Benchmarks.html
2023
-
[34]
K. Wu, C. Hou, J. Liu, Z. Che, X. Ju, Z. Yang, M. Li, Y . Zhao, Z. Xu, G. Yang, et al. RoboMIND: Benchmark on multi-embodiment intelligence normative data for robot manip- ulation. InRobotics: Science and Systems, 2025. URLhttps://roboticsconference. org/program/papers/152/
2025
-
[35]
H.-S. Fang, H. Fang, Z. Tang, J. Liu, C. Wang, J. Wang, H. Zhu, and C. Lu. RH20T: A com- prehensive robotic dataset for learning diverse skills in one-shot. In2024 IEEE International Conference on Robotics and Automation. IEEE, 2024. URLhttps://rh20t.github.io/
2024
-
[36]
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen-Estruch, A. W. He, V . Myers, M. J. Kim, M. Du, A. Lee, K. Fang, C. Finn, and S. Levine. BridgeData v2: A dataset for robot learning at scale. In J. Tan, M. Toussaint, and K. Darvish, ed- itors,Proceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning ...
2023
-
[37]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. J. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Manju- nath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsc...
2023
-
[38]
Ghosh, H
D. Ghosh, H. R. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, J. Luo, Y . L. Tan, L. Y . Chen, Q. Vuong, T. Xiao, P. R. Sanketi, D. Sadigh, C. Finn, and S. Levine. Octo: An open-source generalist robot policy. InRobotics: Science and Systems,
-
[39]
URLhttps://www.roboticsproceedings.org/ rss20/p090.pdf
doi:10.15607/RSS.2024.XX.090. URLhttps://www.roboticsproceedings.org/ rss20/p090.pdf
-
[40]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, J. Gu, Z. Wang, Y . Ding, B. Zhao, D. Wang, and X. Li. SpatialVLA: Exploring spatial representations for visual-language-action models. In Robotics: Science and Systems, 2025. doi:10.15607/RSS.2025.XXI.011. URLhttps://www. roboticsproceedings.org/rss21/p011.pdf
-
[41]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410....
Pith/arXiv arXiv 2024
-
[42]
X. Chen, Y . Chen, Y . Fu, N. Gao, J. Jia, W. Jin, H. Li, Y . Mu, J. Pang, Y . Qiao, Y . Tian, B. Wang, B. Wang, F. Wang, H. Wang, T. Wang, Z. Wang, X. Wei, C. Wu, S. Yang, J. Ye, J. Yu, J. Zeng, J. Zhang, J. Zhang, S. Zhang, F. Zheng, B. Zhou, and Y . Zhu. Internvla-m1: A spatially guided vision-language-action framework for generalist robot policy.arXiv...
Pith/arXiv arXiv 2025
-
[43]
Cadene, S
R. Cadene, S. Alibert, A. Soare, Q. Gallouedec, A. Zouitine, S. Palma, P. Kooijmans, M. Ar- actingi, M. Shukor, D. Aubakirova, M. Russi, F. Capuano, C. Pascal, J. Choghari, J. Moss, and T. Wolf. Lerobot: State-of-the-art machine learning for real-world robotics in pytorch. https://github.com/huggingface/lerobot, 2024
2024
-
[44]
E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn. BC-z: Zero-shot task generalization with robotic imitation learning. In5th Annual Conference on Robot Learning, 2021. URLhttps://openreview.net/forum?id=8kbp23tSGYv
2021
-
[45]
R. Shah, R. Mart ´ın-Mart´ın, and Y . Zhu. Mutex: Learning unified policies from multimodal task specifications. In7th Annual Conference on Robot Learning, 2023. URLhttps:// openreview.net/forum?id=PwqiqaaEzJ
2023
-
[46]
Belkhale, Y
S. Belkhale, Y . Cui, and D. Sadigh. Hydra: Hybrid robot actions for imitation learning. In Proceedings of the 7th Conference on Robot Learning (CoRL), 2023
2023
-
[47]
Nasiriany, T
S. Nasiriany, T. Gao, A. Mandlekar, and Y . Zhu. Learning and retrieval from prior data for skill-based imitation learning. InConference on Robot Learning (CoRL), 2022
2022
-
[48]
G. Zhou, V . Dean, M. K. Srirama, A. Rajeswaran, J. Pari, K. Hatch, A. Jain, T. Yu, P. Abbeel, L. Pinto, C. Finn, and A. Gupta. Train offline, test online: A real robot learning benchmark. In 2023 IEEE International Conference on Robotics and Automation (ICRA), 2023
2023
-
[49]
L. Y . Chen, S. Adebola, and K. Goldberg. Berkeley UR5 demonstration dataset.https: //sites.google.com/view/berkeley-ur5/home
-
[50]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[51]
X. Kang, T. Tian, S.-W. Lee, B. Huang, Y . Li, and Y .-L. Kuo. Learning force-regulated ma- nipulation with a low-cost tactile-force-controlled gripper.arXiv preprint arXiv:2602.10013, 2026. 13 A Training Details We use the LeRobot framework [39] for TBD-VLA training and policy deployment. This provides a unified pipeline for dataset loading, pre-processi...
arXiv 2026
-
[52]
Transfer the Liquid
for real-world manipulation. We control the gripper using width commands [47], which are needed for precise manipulation in the “Transfer the Liquid” task. 17 Figure 8:Visualization of Real-world Task Progress.For each task, the task progress is visualized at uniform time intervals during data collection. C.2 Task Descriptions and Success Condition For re...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.