EditSR: Enhancing Neural Symbolic Regression via Edit-based Rectification
Pith reviewed 2026-06-27 20:13 UTC · model grok-4.3
The pith
A two-layer setup with a neural generator plus a pretrained edit rectifier recovers correct symbolic expressions more reliably than one-pass decoding alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
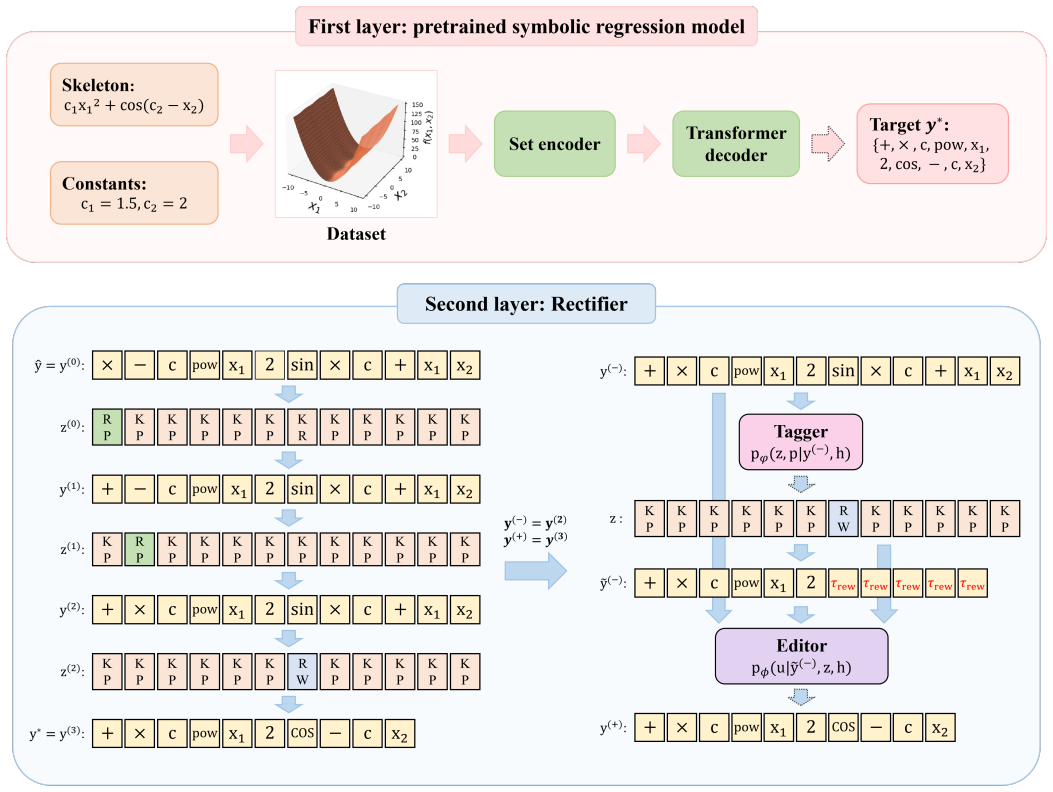
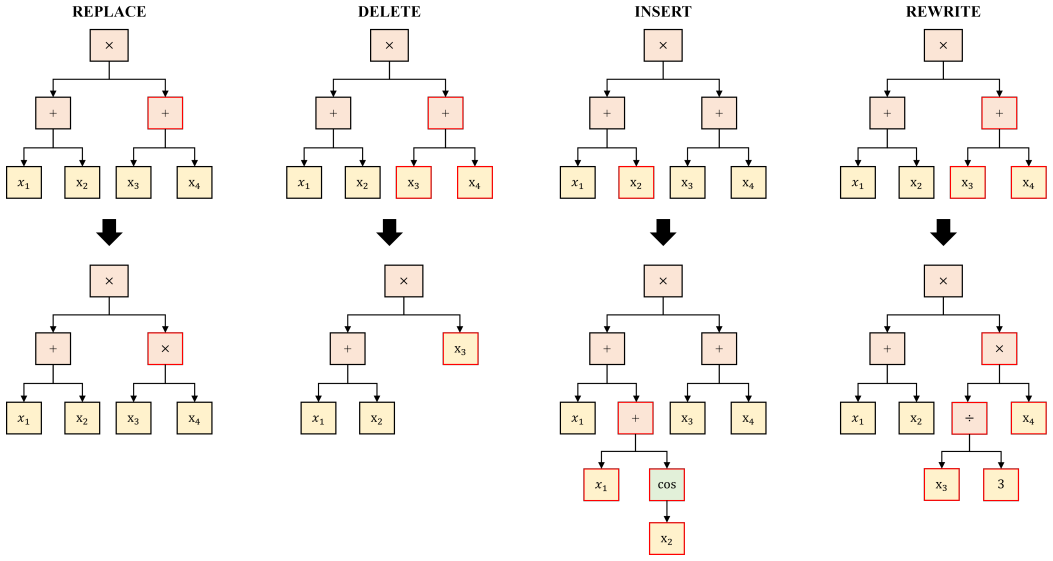
The paper claims that pretraining an edit-based Rectifier on supervised state-transition chains allows post-hoc correction of structurally invalid expressions produced by a first-layer neural symbolic regression model, while each edit stays inside a syntactically valid space and conditioning on the current state alone reduces error accumulation across the chain.
What carries the argument
The edit-based Rectifier, which learns to perform step-by-step state transitions that correct an expression using only the current state as input.
If this is right
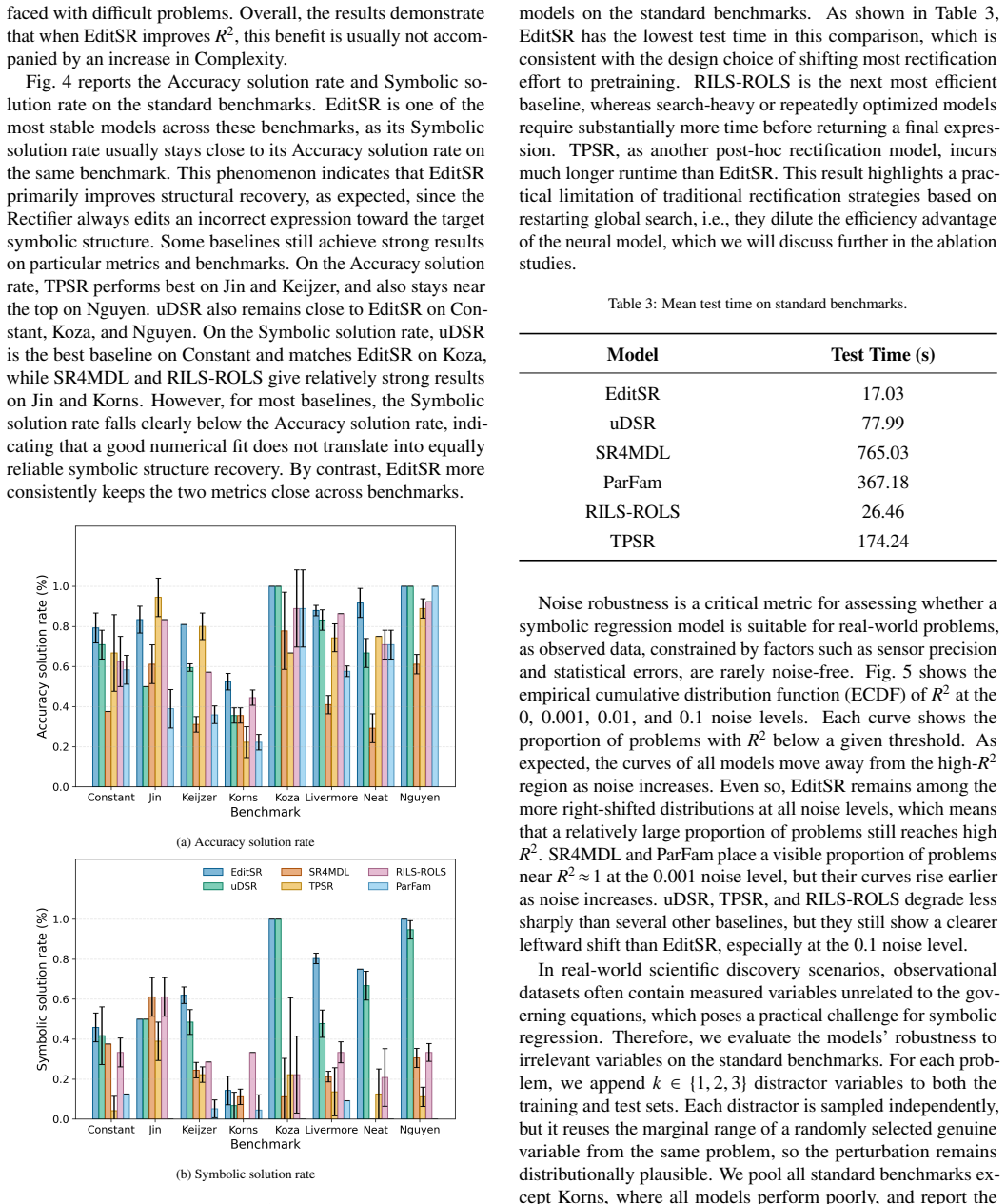
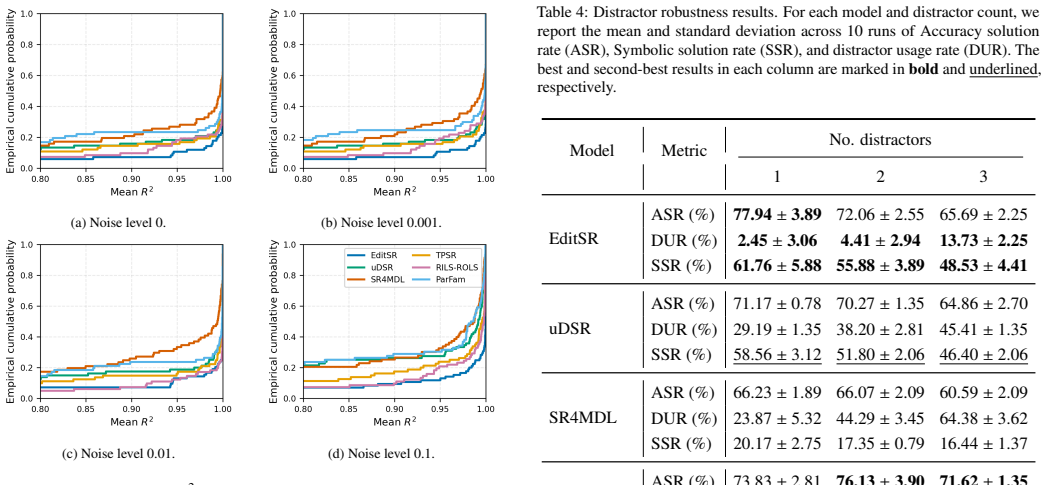
- Symbolic structure recovery rates rise compared with the base neural model alone.
- Gains are larger for complex expressions where single-pass decoding tends to fail.
- The added computation stays limited because the rectifier is pretrained and runs without restarting global search.
- Every intermediate expression stays syntactically valid because edits are restricted to a valid action space.
- Conditioning each edit only on the current state allows later steps to override earlier mistakes.
Where Pith is reading between the lines
- The same state-transition rectification pattern could be applied to other autoregressive generation tasks that produce structured outputs such as mathematical proofs or code.
- Separating generation from correction might let smaller base models suffice if the rectifier handles most structural fixes.
- Extending the rectifier to handle expressions with more operators or variables would test whether the state-only conditioning continues to prevent accumulation.
Load-bearing premise
The supervised rectification chains built by the state-transition algorithm will train a rectifier that generalizes to correct the kinds of errors the base neural model actually makes on unseen data.
What would settle it
Running the trained rectifier on a held-out test set of expressions generated by the first-layer model and finding no measurable increase in the fraction of expressions that match the ground-truth symbolic structure.
Figures

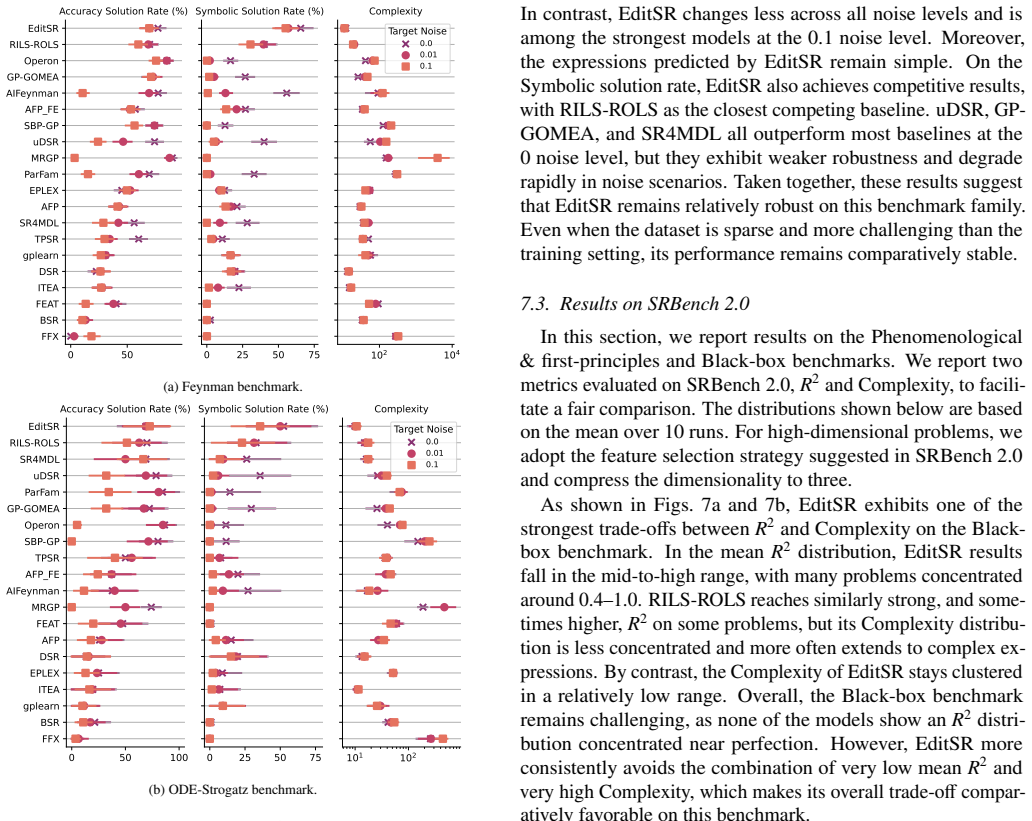
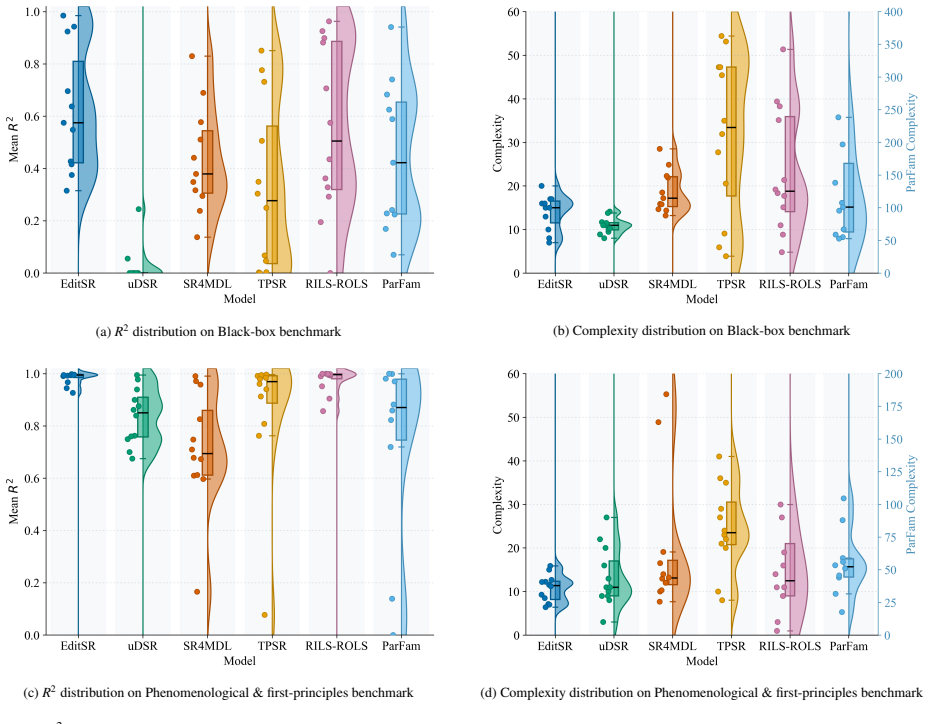
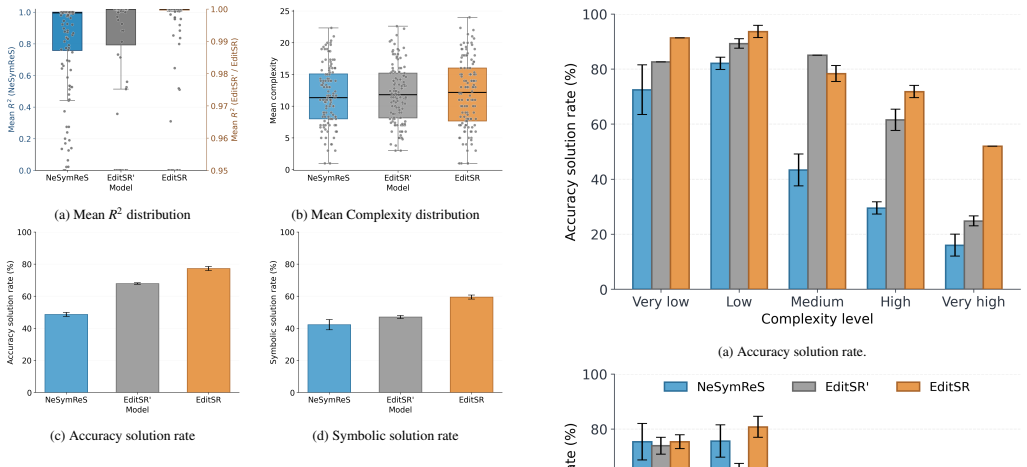

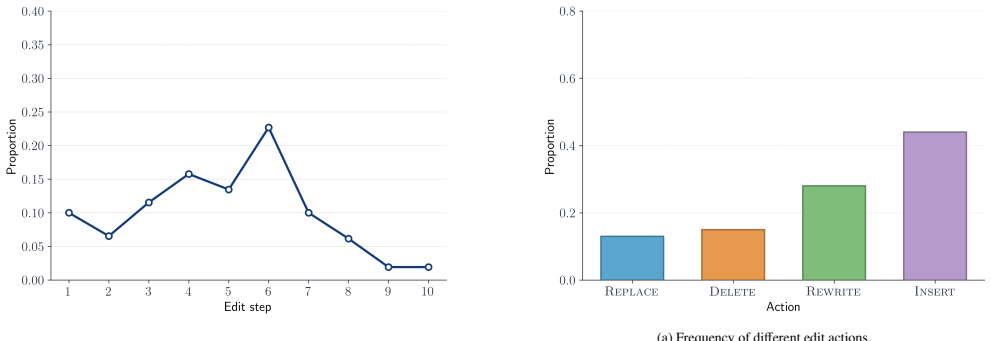
read the original abstract
Neural symbolic regression models improve inference efficiency by shifting structural search to pretraining, but their one-pass autoregressive decoding is prone to error accumulation, which may lead to generating structurally incorrect expressions, especially in complex expression generation scenarios. Existing rectification strategies can alleviate this issue, but they often depend on restarting global search, thereby weakening the efficiency advantage of neural models, and remain susceptible to error accumulation. In this paper, we propose EditSR, a two-layer framework that combines a neural symbolic regression model in the first layer with an edit-based Rectifier in the second layer to achieve efficient prediction and post-hoc rectification. Instead of restarting the global search, we maintain rectification efficiency by pretraining the Rectifier. Specifically, we formulate the rectification process as a step-by-step state-transition chain starting from an incorrect expression, and develop a state-transition algorithm to construct supervised rectification chains for training the Rectifier. To ensure syntactic validity throughout rectification, each edit action is restricted to a syntactically valid space so that every edited expression remains parseable. In addition, because each edit decision is conditioned on the current state rather than the history, the Rectifier allows errors made in earlier steps to be rectified by subsequent edits, thereby reducing the risk of error accumulation. Extensive experiments and ablation studies show that EditSR substantially improves symbolic structure recovery with limited extra cost, with more pronounced gains on complex expressions, where one-pass autoregressive decoding is more susceptible to error accumulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EditSR, a two-layer neural symbolic regression framework. A first-layer neural model performs one-pass autoregressive decoding to generate candidate expressions; a second-layer Rectifier, pretrained on supervised edit sequences, then performs step-by-step syntactic edits. Rectification chains are generated by a state-transition algorithm that starts from incorrect expressions and applies valid edits; each decision is conditioned only on the current syntactic state (not history) and restricted to the syntactically valid action space. The authors claim this yields substantially better symbolic structure recovery than the base neural model, at modest extra cost, with larger gains on complex expressions where error accumulation is pronounced.
Significance. If the rectifier demonstrably generalizes from the constructed training chains to the actual error distribution of the first-layer model on held-out data, the approach would provide a practical, efficiency-preserving way to mitigate autoregressive error accumulation in neural SR without reverting to global search restarts. The syntactic-validity constraint and history-free conditioning are technically attractive features that could be adopted more broadly.
major comments (2)
- [Methods section describing the state-transition algorithm and Rectifier training] The central claim that the pretrained Rectifier improves structure recovery on unseen expressions rests on the unverified assumption that the error distribution in the state-transition training chains matches the distribution of mistakes made by the first-layer neural model. The manuscript provides no comparison (e.g., statistics on error types, edit distances, or syntactic patterns) between the initial incorrect expressions used to build the chains and the actual outputs of the neural SR model on the test set; without such evidence the reported gains on complex expressions could be an artifact of mismatched training and test error statistics.
- [Abstract and Experiments section] The abstract states that 'extensive experiments and ablation studies show that EditSR substantially improves symbolic structure recovery,' yet the provided manuscript excerpt contains no quantitative results, baseline comparisons, dataset descriptions, or error metrics. This absence prevents assessment of whether the claimed improvements are load-bearing or merely incremental.
minor comments (2)
- [Methods] Notation for the state representation and edit actions should be formalized with explicit definitions (e.g., what constitutes the 'current syntactic state') to allow reproducibility.
- [Methods] The paper should clarify whether the state-transition algorithm uses random perturbations or model-generated errors when constructing the supervised chains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Methods section describing the state-transition algorithm and Rectifier training] The central claim that the pretrained Rectifier improves structure recovery on unseen expressions rests on the unverified assumption that the error distribution in the state-transition training chains matches the distribution of mistakes made by the first-layer neural model. The manuscript provides no comparison (e.g., statistics on error types, edit distances, or syntactic patterns) between the initial incorrect expressions used to build the chains and the actual outputs of the neural SR model on the test set; without such evidence the reported gains on complex expressions could be an artifact of mismatched training and test error statistics.
Authors: We agree that a direct comparison of error distributions would strengthen the generalization argument. The state-transition algorithm is designed to produce diverse invalid starting points and valid edit sequences that reflect common autoregressive failure modes, but the manuscript does not currently include explicit statistics matching these to the first-layer model's test outputs. In the revision we will add this analysis (error-type frequencies, edit-distance histograms, and syntactic-pattern overlap) to the Experiments section to verify alignment. revision: yes
-
Referee: [Abstract and Experiments section] The abstract states that 'extensive experiments and ablation studies show that EditSR substantially improves symbolic structure recovery,' yet the provided manuscript excerpt contains no quantitative results, baseline comparisons, dataset descriptions, or error metrics. This absence prevents assessment of whether the claimed improvements are load-bearing or merely incremental.
Authors: The full manuscript contains a complete Experiments section with quantitative results, baseline comparisons, dataset descriptions, and error metrics that support the abstract claims. The excerpt supplied to the referee appears to have been limited to the abstract; the full paper provides all requested details. No change to the manuscript text is required on this point. revision: no
Circularity Check
No circularity; derivation relies on independent supervised pretraining of rectifier
full rationale
The paper presents EditSR as a two-layer architecture with a first-layer neural SR model and a second-layer Rectifier pretrained on state-transition chains generated by an explicit algorithm. No equations, derivations, or claims reduce the reported gains in structure recovery to a fitted quantity by construction, a self-referential definition, or a load-bearing self-citation chain. The rectification process is motivated and trained separately from the base model, with syntactic validity enforced by construction in the action space. This is a standard empirical ML contribution whose central claims rest on external benchmarks rather than internal redefinition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Schmidt, H
M. Schmidt, H. Lipson, Distilling free-form natural laws from experimental data, science 324 (5923) (2009) 81–85
2009
-
[2]
Udrescu, M
S.-M. Udrescu, M. Tegmark, Ai feynman: A physics- inspired method for symbolic regression, Science advances 6 (16) (2020) eaay2631
2020
-
[3]
J. R. Koza, Genetic programming as a means for program- ming computers by natural selection, Statistics and com- puting 4 (2) (1994) 87–112
1994
-
[4]
O’Neill, Riccardo poli, william b
M. O’Neill, Riccardo poli, william b. langdon, nicholas f. mcphee: A field guide to genetic programming: Lulu. com, 2008, 250 pp, isbn 978-1-4092-0073-4 (2009)
2008
-
[5]
R. Poli, N. F. McPhee, Parsimony pressure made easy, in: Proceedings of the 10th annual conference on Genetic and evolutionary computation, 2008, pp. 1267–1274
2008
-
[6]
Poli, A simple but theoretically-motivated method to control bloat in genetic programming, in: European Con- ference on Genetic Programming, Springer, 2003, pp
R. Poli, A simple but theoretically-motivated method to control bloat in genetic programming, in: European Con- ference on Genetic Programming, Springer, 2003, pp. 204– 217
2003
-
[7]
S. Luke, L. Panait, Lexicographic parsimony pressure, in: Proceedings of the 4th Annual Conference on Genetic and Evolutionary Computation, 2002, pp. 829–836
2002
-
[9]
Moraglio, K
A. Moraglio, K. Krawiec, C. G. Johnson, Geometric se- mantic genetic programming, in: International Conference on Parallel Problem Solving from Nature, Springer, 2012, pp. 21–31
2012
-
[10]
Kommenda, M
M. Kommenda, M. Affenzeller, G. Kronberger, S. M. Win- kler, Nonlinear least squares optimization of constants in symbolic regression, in: International Conference on Com- puter Aided Systems Theory, Springer, 2013, pp. 420–427
2013
-
[11]
Burlacu, G
B. Burlacu, G. Kronberger, M. Kommenda, Operon c++ an efficient genetic programming framework for symbolic regression, in: Proceedings of the 2020 genetic and evo- lutionary computation conference companion, 2020, pp. 1562–1570
2020
-
[12]
La Cava, B
W. La Cava, B. Burlacu, M. Virgolin, M. Kommenda, P. Orzechowski, F. O. de França, Y . Jin, J. H. Moore, Con- temporary symbolic regression methods and their relative performance, Advances in neural information processing systems 2021 (DB1) (2021) 1
2021
-
[13]
F. O. de Franca, M. Virgolin, M. Kommenda, M. Ma- jumder, M. Cranmer, G. Espada, L. Ingelse, A. Fonseca, M. Landajuela, B. Petersen, et al., Srbench++: principled benchmarking of symbolic regression with domain-expert interpretation, IEEE transactions on evolutionary computa- tion (2024)
2024
- [14]
-
[15]
Extrapolation and learning equations
G. Martius, C. H. Lampert, Extrapolation and learning equations, arXiv preprint arXiv:1610.02995 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [16]
-
[17]
Mundhenk, M
T. Mundhenk, M. Landajuela, R. Glatt, C. P. Santiago, B. K. Petersen, et al., Symbolic regression via deep rein- forcement learning enhanced genetic programming seed- ing, Advances in Neural Information Processing Systems 34 (2021) 24912–24923
2021
-
[18]
Biggio, T
L. Biggio, T. Bendinelli, A. Neitz, A. Lucchi, G. Paras- candolo, Neural symbolic regression that scales, in: Inter- national conference on machine learning, Pmlr, 2021, pp. 936–945
2021
-
[19]
M. Valipour, B. You, M. Panju, A. Ghodsi, Symbolicgpt: A generative transformer model for symbolic regression, arXiv preprint arXiv:2106.14131 (2021). 22
-
[20]
Kamienny, S
P.-A. Kamienny, S. d’Ascoli, G. Lample, F. Charton, End- to-end symbolic regression with transformers, Advances in Neural Information Processing Systems 35 (2022) 10269– 10281
2022
-
[21]
Vastl, J
M. Vastl, J. Kulhánek, J. Kubalík, E. Derner, R. Babuška, Symformer: End-to-end symbolic regression using transformer-based architecture, IEEE Access 12 (2024) 37840–37849
2024
-
[22]
Landajuela, C
M. Landajuela, C. S. Lee, J. Yang, R. Glatt, C. P. San- tiago, I. Aravena, T. Mundhenk, G. Mulcahy, B. K. Pe- tersen, A unified framework for deep symbolic regression, Advances in Neural Information Processing Systems 35 (2022) 33985–33998
2022
-
[23]
Shojaee, K
P. Shojaee, K. Meidani, A. Barati Farimani, C. Reddy, Transformer-based planning for symbolic regression, Ad- vances in Neural Information Processing Systems 36 (2023) 45907–45919
2023
-
[24]
K. Meidani, P. Shojaee, C. K. Reddy, A. B. Farimani, Snip: Bridging mathematical symbolic and numeric realms with unified pre-training, arXiv preprint arXiv:2310.02227 (2023)
-
[25]
J. Gu, C. Wang, J. Zhao, Levenshtein transformer, Ad- vances in neural information processing systems 32 (2019) 11179–11189
2019
-
[26]
W. Xu, M. Carpuat, Editor: An edit-based transformer with repositioning for neural machine translation with soft lexical constraints, Transactions of the Association for Computational Linguistics 9 (2021) 311–328
2021
-
[27]
M. Reid, G. Neubig, Learning to model editing processes, in: Findings of the Association for Computational Linguis- tics: EMNLP 2022, 2022, pp. 3822–3832
2022
- [28]
-
[29]
arXiv preprint arXiv:2506.09018 , year=
M. Havasi, B. Karrer, I. Gat, R. T. Chen, Edit flows: Flow matching with edit operations, arXiv preprint arXiv:2506.09018 (2025)
-
[30]
Austin, D
J. Austin, D. D. Johnson, J. Ho, D. Tarlow, R. Van Den Berg, Structured denoising diffusion models in dis- crete state-spaces, Advances in neural information process- ing systems 34 (2021) 17981–17993
2021
-
[31]
J. Liu, W. Li, L. Yu, M. Wu, L. Sun, W. Li, Y . Li, Snr: Symbolic network-based rectifiable learning framework for symbolic regression, Neural networks 165 (2023) 1021– 1034
2023
-
[32]
Karras, M
T. Karras, M. Aittala, T. Aila, S. Laine, Elucidating the design space of diffusion-based generative models, Ad- vances in neural information processing systems 35 (2022) 26565–26577
2022
-
[33]
Chang, H
H. Chang, H. Zhang, L. Jiang, C. Liu, W. T. Freeman, Maskgit: Masked generative image transformer, in: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11315–11325
2022
- [34]
-
[35]
Z. Bastiani, R. M. Kirby, J. Hochhalter, S. Zhe, Diffusion-based symbolic regression, arXiv preprint arXiv:2505.24776 (2025)
-
[36]
J. Ho, A. Jain, P. Abbeel, Denoising diffusion probabilis- tic models, Advances in neural information processing systems 33 (2020) 6840–6851
2020
-
[37]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, B. Poole, Score-based generative modeling through stochastic differential equations, arXiv preprint arXiv:2011.13456 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[38]
Hoogeboom, D
E. Hoogeboom, D. Nielsen, P. Jaini, P. Forré, M. Welling, Argmax flows and multinomial diffusion: Learning cate- gorical distributions, Advances in neural information pro- cessing systems 34 (2021) 12454–12465
2021
-
[39]
McConaghy, Ffx: Fast, scalable, deterministic symbolic regression technology, in: Genetic Programming Theory and Practice IX, Springer, 2011, pp
T. McConaghy, Ffx: Fast, scalable, deterministic symbolic regression technology, in: Genetic Programming Theory and Practice IX, Springer, 2011, pp. 235–260
2011
-
[40]
F. O. de Franca, G. S. I. Aldeia, Interaction–transformation evolutionary algorithm for symbolic regression, Evolution- ary computation 29 (3) (2021) 367–390
2021
-
[41]
Arnaldo, K
I. Arnaldo, K. Krawiec, U.-M. O’Reilly, Multiple regres- sion genetic programming, in: Proceedings of the 2014 annual conference on genetic and evolutionary computa- tion, 2014, pp. 879–886
2014
-
[42]
Virgolin, T
M. Virgolin, T. Alderliesten, C. Witteveen, P. A. Bosman, Improving model-based genetic programming for symbolic regression of small expressions, Evolutionary computation 29 (2) (2021) 211–237
2021
-
[43]
Cranmer, Pysr: high-performance symbolic regression in python and julia, Astrophysics Source Code Library (2024) ascl–2409
M. Cranmer, Pysr: high-performance symbolic regression in python and julia, Astrophysics Source Code Library (2024) ascl–2409
2024
-
[44]
Sahoo, C
S. Sahoo, C. Lampert, G. Martius, Learning equations for extrapolation and control, in: International conference on machine learning, Pmlr, 2018, pp. 4442–4450
2018
-
[45]
Y . Tian, W. Zhou, M. Viscione, H. Dong, D. S. Kammer, O. Fink, Interactive symbolic regression with co-design mechanism through offline reinforcement learning, Nature Communications 16 (1) (2025) 3930. 23
2025
-
[46]
Y . Li, W. Li, L. Yu, M. Wu, J. Liu, W. Li, M. Hao, Dis- covering mathematical formulas from data via gpt-guided monte carlo tree search, Expert Systems with Applications 281 (2025) 127591
2025
-
[47]
Xiang, K
Z. Xiang, K. Ashen, X. Qian, X. Qian, Graph-based sym- bolic regression with invariance and constraint encoding, in: The Thirty-ninth Annual Conference on Neural Infor- mation Processing Systems, 2025
2025
- [48]
-
[49]
K. Ruan, Y . Xu, Z.-F. Gao, Y . Liu, Y . Guo, J.-R. Wen, H. Sun, Discovering physical laws with parallel symbolic enumeration, Nature Computational Science 6 (1) (2026) 53–66
2026
-
[50]
Y . Li, J. Liu, M. Wu, L. Yu, W. Li, X. Ning, W. Li, M. Hao, Y . Deng, S. Wei, Mmsr: symbolic regression is a multi- modal information fusion task, Information Fusion 114 (2025) 102681
2025
-
[51]
D. Li, J. Yin, J. Xu, X. Li, J. Zhang, Visymre: Vision multimodal symbolic regression, Neural Networks (2026) 109017
2026
-
[52]
Llm -sr: Scientific equation discovery via programming with large language models,
P. Shojaee, K. Meidani, S. Gupta, A. B. Farimani, C. K. Reddy, Llm-sr: Scientific equation discovery via pro- gramming with large language models, arXiv preprint arXiv:2404.18400 (2024)
-
[53]
Grayeli, A
A. Grayeli, A. Sehgal, O. Costilla-Reyes, M. Cranmer, S. Chaudhuri, Symbolic regression with a learned con- cept library, Advances in Neural Information Processing Systems 37 (2024) 44678–44709
2024
-
[54]
arXiv preprint arXiv:2504.10415 , year=
P. Shojaee, N.-H. Nguyen, K. Meidani, A. B. Farimani, K. D. Doan, C. K. Reddy, Llm-srbench: A new bench- mark for scientific equation discovery with large language models, arXiv preprint arXiv:2504.10415 (2025)
- [55]
-
[56]
Scholl, K
P. Scholl, K. Bieker, H. Hauger, G. Kutyniok, Parfam– (neural guided) symbolic regression via continuous global optimization, in: The Thirteenth International Conference on Learning Representations, 2025
2025
-
[57]
J. Liu, M. Wu, L. Yu, W. Li, W. Li, Y . Li, M. Hao, Y . Deng, S. Wei, Camo: Capturing the modularity by end-to-end models for symbolic regression, Knowledge-Based Sys- tems 309 (2025) 112747
2025
-
[58]
Plug and play language models: A simple approach to controlled text generation,
S. Dathathri, A. Madotto, J. Lan, J. Hung, E. Frank, P. Molino, J. Yosinski, R. Liu, Plug and play language models: A simple approach to controlled text generation, arXiv preprint arXiv:1912.02164 (2019)
-
[59]
L. Qin, S. Welleck, D. Khashabi, Y . Choi, Cold decoding: Energy-based constrained text generation with langevin dynamics, Advances in Neural Information Processing Systems 35 (2022) 9538–9551
2022
-
[60]
Kumagai, I
K. Kumagai, I. Kobayashi, D. Mochihashi, H. Asoh, T. Nakamura, T. Nagai, Human-like natural language gen- eration using monte carlo tree search, in: Proceedings of the INLG 2016 Workshop on Computational Creativity in Natural Language Generation, 2016, pp. 11–18
2016
-
[61]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, Advances in neural information processing systems 30 (2017)
2017
-
[62]
J. Lee, Y . Lee, J. Kim, A. Kosiorek, S. Choi, Y . W. Teh, Set transformer: A framework for attention-based permutation- invariant neural networks, in: International conference on machine learning, PMLR, 2019, pp. 3744–3753
2019
-
[63]
C. R. Qi, H. Su, K. Mo, L. J. Guibas, Pointnet: Deep learn- ing on point sets for 3d classification and segmentation, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 652–660
2017
-
[64]
F. Lalande, Y . Matsubara, N. Chiba, T. Taniai, R. Igarashi, Y . Ushiku, A transformer model for symbolic re- gression towards scientific discovery, arXiv preprint arXiv:2312.04070 (2023)
-
[65]
S. H. Strogatz, Nonlinear dynamics and chaos: with ap- plications to physics, biology, chemistry, and engineering (studies in nonlinearity), V ol. 1, Westview press, 2001
2001
-
[66]
G. S. Imai Aldeia, H. Zhang, G. Bomarito, M. Cranmer, A. Fonseca, B. Burlacu, W. G. La Cava, F. O. de França, Call for action: towards the next generation of symbolic regression benchmark, in: Proceedings of the Genetic and Evolutionary Computation Conference Companion, 2025, pp. 2529–2538
2025
-
[67]
Kartelj, M
A. Kartelj, M. Djukanovi´c, Rils-rols: robust symbolic re- gression via iterated local search and ordinary least squares, Journal of Big Data 10 (1) (2023) 71
2023
-
[68]
McDermott, D
J. McDermott, D. R. White, S. Luke, L. Manzoni, M. Castelli, L. Vanneschi, W. Jaskowski, K. Krawiec, R. Harper, K. De Jong, et al., Genetic programming needs better benchmarks, in: Proceedings of the 14th annual con- ference on Genetic and evolutionary computation, 2012, pp. 791–798
2012
-
[69]
Matsubara, N
Y . Matsubara, N. Chiba, R. Igarashi, Y . Ushiku, Srsd: Re- thinking datasets of symbolic regression for scientific dis- covery, in: NeurIPS 2022 AI for Science: Progress and Promises, 2022. 24
2022
-
[70]
N. Q. Uy, N. X. Hoai, M. O’Neill, R. I. McKay, E. Galván- López, Semantically-based crossover in genetic program- ming: application to real-valued symbolic regression, Ge- netic Programming and Evolvable Machines 12 (2) (2011) 91–119
2011
-
[71]
Keijzer, Improving symbolic regression with interval arithmetic and linear scaling, in: European conference on genetic programming, Springer, 2003, pp
M. Keijzer, Improving symbolic regression with interval arithmetic and linear scaling, in: European conference on genetic programming, Springer, 2003, pp. 70–82
2003
-
[72]
M. F. Korns, Accuracy in symbolic regression, in: Genetic Programming Theory and Practice IX, Springer, 2011, pp. 129–151
2011
-
[73]
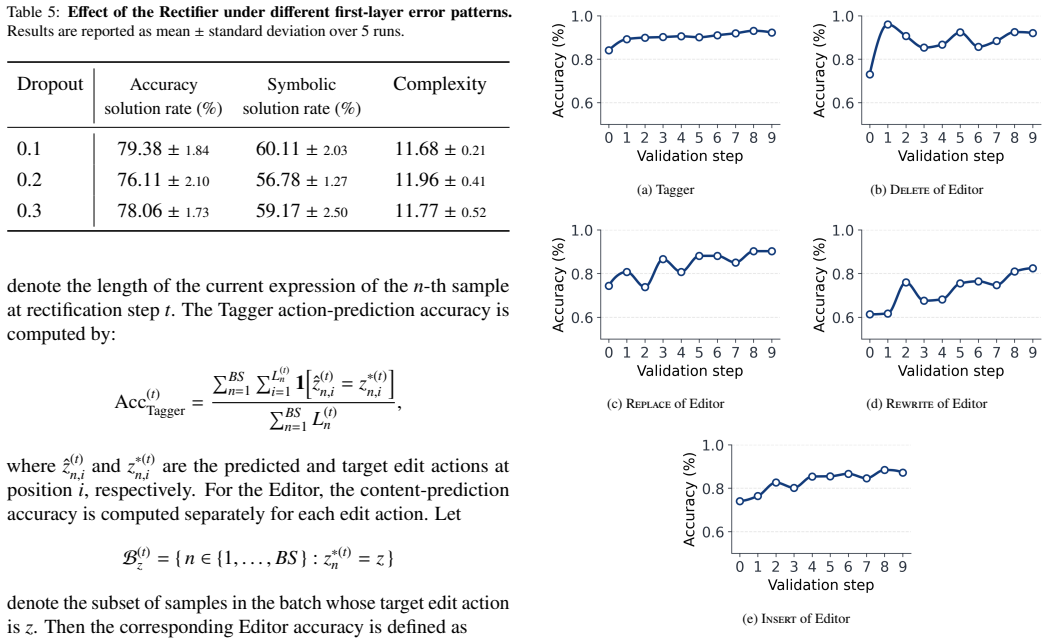
Y . Jin, W. Fu, J. Kang, J. Guo, J. Guo, Bayesian symbolic regression, arXiv preprint arXiv:1910.08892 (2019). 25 Appendix A. Details of Tagger and Editor The Tagger and Editor share the same dataset encoding h, but they play different roles in the rectification loop. The Tagger is responsible for predicting the edit position and action. Given the current...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.