The CIFAR Synthetic Evidence Corpus for Detecting AI-Generated Evidence
Pith reviewed 2026-06-27 20:11 UTC · model grok-4.3
The pith
A new corpus of synthetic evidentiary documents enables controlled testing of detectors for AI-generated legal evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
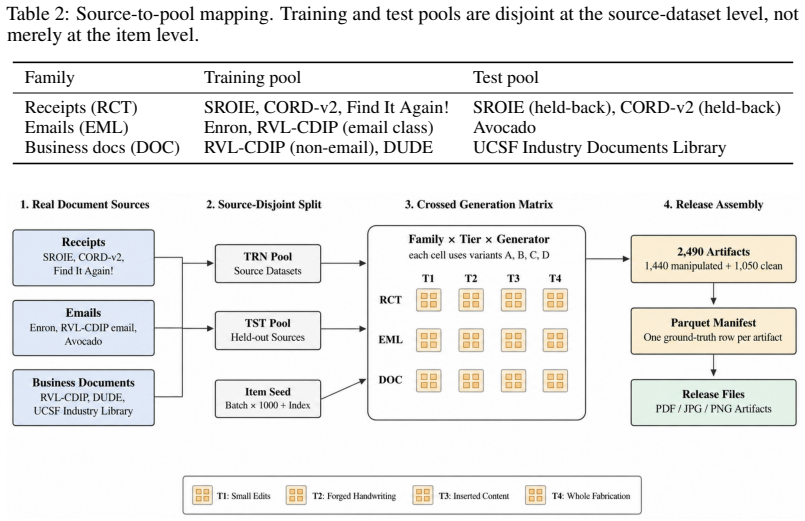
The central claim is that existing datasets do not match the structure, diversity, or manipulation patterns of real-world evidentiary data, so current detection systems do not learn meaningful signals for the justice system; the CIFAR Synthetic Evidence Corpus remedies this by spanning document families and manipulation strategies from small edits to complete fabrication, built with diverse generative tools, and organized to vary manipulation complexity and generation method with enforced source-level separation between training and test data.
What carries the argument
The CIFAR Synthetic Evidence Corpus, a dataset that systematically varies manipulation complexity and generation method while enforcing source-level separation between training and test sets.
If this is right
- Detectors can be evaluated under conditions that match the localized edits and preserved plausibility found in legal evidence.
- Training and test splits reflect real-world generalization requirements by keeping sources separate.
- Systems gain the ability to handle a spectrum of manipulation strategies across multiple document families.
- Progress on automated verification becomes possible for workflows that depend on the authenticity of administrative records and communications.
Where Pith is reading between the lines
- The corpus could serve as a benchmark to compare how well current detectors handle evidentiary versus non-evidentiary document types.
- Extending the corpus with additional document families or new generative methods would test whether the current coverage is sufficient.
- If detectors improve on this data, legal tech applications might incorporate them for preliminary authenticity checks before human review.
Load-bearing premise
That data produced by today's generative tools will capture the structure, diversity, and manipulation patterns of actual evidentiary documents used in courts closely enough for detectors to learn useful signals.
What would settle it
A test set of real court documents that have been subtly altered by hand or by other means, on which models trained on the corpus show no improvement over models trained on existing face or social-media datasets.
Figures

read the original abstract
The growing ability of generative models to produce realistic documents poses a direct challenge to evidentiary workflows in the justice system and the courts, where decisions increasingly depend on the authenticity of evidence such as receipts, communications, and administrative records. Unlike social media or academic settings, evidentiary documents are often only subtly altered, with small, localized edits that preserve overall plausibility while changing legal meaning. Yet progress on automated detection remains limited, largely due to the absence of suitable training and evaluation data especially suited for the justice system requirements. Existing resources are either focused on photos of human faces or natural scenery or on narrowly scoped academic or social media document types, and do not capture the structure, diversity, or manipulation patterns characteristic of real-world evidentiary data. As a result, current detection systems do not necessarily learn meaningful signals appropriate for the justice system. We introduce the CIFAR Synthetic Evidence Corpus, a dataset designed to enable rigorous evaluation of evidence verification under realistic and controlled conditions. The corpus spans multiple document families and a spectrum of manipulation strategies, from small field-level edits to complete document fabrication, and is constructed using a diverse set of state-of-the-art generative tools. It is organized to systematically vary both manipulation complexity and generation method, while enforcing source-level separation between training and test data to reflect real-world generalization challenges.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the CIFAR Synthetic Evidence Corpus, a synthetic dataset for training and evaluating detectors of AI-generated or manipulated evidentiary documents (receipts, communications, administrative records) in justice-system contexts. It claims the corpus spans multiple document families and manipulation strategies ranging from small field-level edits to complete fabrication, is constructed with diverse state-of-the-art generative tools, systematically varies manipulation complexity and generation method, and enforces source-level train/test separation to reflect real-world generalization challenges.
Significance. If the corpus reproduces the statistical, structural, and semantic properties of authentic evidentiary data, it would address a documented gap in resources for justice-system document verification, where existing datasets focus on faces or social media and current detectors may learn irrelevant signals. The source-level separation and controlled variation of complexity are explicit strengths for testing generalization. The manuscript supplies no empirical validation or benchmarks.
major comments (1)
- [Abstract] Abstract: The claim that the corpus 'capture[s] the structure, diversity, or manipulation patterns characteristic of real-world evidentiary data' and thereby enables 'rigorous evaluation ... under realistic and controlled conditions' is unsupported; the text provides no statistical comparisons to authentic court records, no expert review of legal semantics, and no mechanism ensuring generative artifacts do not dominate the learned signals.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need to align claims with the evidence presented. The manuscript introduces a new corpus without performing direct validation against real court records; we address this below by committing to a revision of the abstract language.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the corpus 'capture[s] the structure, diversity, or manipulation patterns characteristic of real-world evidentiary data' and thereby enables 'rigorous evaluation ... under realistic and controlled conditions' is unsupported; the text provides no statistical comparisons to authentic court records, no expert review of legal semantics, and no mechanism ensuring generative artifacts do not dominate the learned signals.
Authors: We agree that the abstract's wording overstates the corpus's fidelity to real-world data. The construction draws on publicly available examples of evidentiary documents and consultation with domain experts during design, but the manuscript contains no quantitative statistical comparisons, formal expert semantic review, or explicit controls for generative artifacts. We will revise the abstract to describe the corpus as a synthetic resource that systematically varies document families, manipulation strategies, and generation methods with source-level train/test separation, while removing the claim that it captures 'characteristic' real-world patterns. The revised text will instead position the corpus as a controlled testbed for studying detector generalization, explicitly noting the absence of direct real-data validation. revision: yes
Circularity Check
No circularity: dataset introduction paper with no derivations or self-referential claims
full rationale
The paper introduces the CIFAR Synthetic Evidence Corpus as a new resource for evaluation. It contains no equations, fitted parameters, predictions, or derivation chains. Claims about the corpus spanning document families and manipulation strategies are descriptive of its construction method rather than derived from any internal logic that reduces to its own inputs. No self-citations are load-bearing, and the contribution does not rely on renaming known results or smuggling ansatzes. The skeptic concern about real-world match is a validity issue, not circularity.
Axiom & Free-Parameter Ledger
invented entities (1)
-
CIFAR Synthetic Evidence Corpus
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URLhttps://ieeexplore.ieee.org/document/8545428
doi: 10.1109/ICPR.2018.8545428. URLhttps://ieeexplore.ieee.org/document/8545428. ISSN: 1051-4651. Sergi D Bray, Shane D Johnson, and Bennett Kleinberg. Testing human ability to detect ‘deepfake’ images of human faces.Journal of Cybersecurity, 9(1):tyad011, January
-
[2]
ISSN 2057-2085. doi: 10.1093/cybsec/tyad011. URLhttps://doi.org/10.1093/cybsec/tyad011. Nuria Alina Chandra, Ryan Murtfeldt, Lin Qiu, Arnab Karmakar, Hannah Lee, Emmanuel Tanumi- hardja, Kevin Farhat, Ben Caffee, Sejin Paik, Changyeon Lee, Jongwook Choi, Aerin Kim, and Oren Etzioni. Deepfake-Eval-2024: A Multi-Modal In-the-Wild Benchmark of Deepfakes Cir-...
-
[3]
arXiv:2503.02857 [cs] version:
URL http://arxiv.org/abs/2503.02857. arXiv:2503.02857 [cs] version:
-
[4]
URLhttp://arxiv.org/abs/2211.00680. arXiv:2211.00680 [cs]. Abhishek Dalal, Chongyang Gao, Hon Paul Grimm, Maura Grossman, Daniel Linna Jr, Chiara Pulice, V . S. Subrahmanian, and Hon John Tunheim. Deepfakes in Court: How Judges Can Proactively Manage Alleged AI-Generated Material in National Security Cases.University of Chicago Legal Forum, 2024(1), January
arXiv 2024
-
[5]
URL http://arxiv.org/abs/2006.07397. arXiv:2006.07397 [cs]. Jing Dong, Wei Wang, and Tieniu Tan. CASIA Image Tampering Detection Evaluation Database. In 2013 IEEE China Summit and International Conference on Signal and Information Processing, pages 422–426, July
Pith/arXiv arXiv 2006
-
[6]
doi: 10.1109/ChinaSIP.2013.6625374. URL https://ieeexplore. ieee.org/document/6625374. Paul Grimm, Maura Grossman, and Gordon Cormack. Artificial Intelligence as Evidence.Northwest- ern Journal of Technology and Intellectual Property, 19(1):9, December
-
[7]
Science and Technology Law Review , author =
ISSN 1938-0976. doi: 10.52214/stlr.v26i2.13890. URL https://journals.library.columbia.edu/index. php/stlr/article/view/13890. 10 Haiying Guan, Mark Kozak, Eric Robertson, Yooyoung Lee, Amy Yates, Andrew Del- gado, Daniel F. Zhou, Timothée N. Kheyrkhah, Jeff Smith, and Jonathan G. Fis- cus. MFC Datasets: Large-Scale Benchmark Datasets for Media Forensic Ch...
-
[8]
Last Modified: 2019-12-31T06:12-05:00
URL https://www.nist.gov/publications/ mfc-datasets-large-scale-benchmark-datasets-media-forensic-challenge-evaluation . Last Modified: 2019-12-31T06:12-05:00. Adam W. Harley, Alex Ufkes, and Konstantinos G. Derpanis. Evaluation of Deep Convolutional Nets for Document Image Classification and Retrieval, February
2019
-
[9]
URL http://arxiv.org/ abs/1502.07058. arXiv:1502.07058 [cs]. Yinan He, Bei Gan, Siyu Chen, Yichun Zhou, Guojun Yin, Luchuan Song, Lu Sheng, Jing Shao, and Ziwei Liu. ForgeryNet: A Versatile Benchmark for Comprehensive Forgery Analysis, July
-
[10]
URLhttp://arxiv.org/abs/2103.05630. arXiv:2103.05630 [cs]. Guanhua Huang, Yuchen Zhang, Zhe Li, Yongjian You, Mingze Wang, and Zhouwang Yang. Are AI-Generated Text Detectors Robust to Adversarial Perturbations?, June
-
[11]
URL http: //arxiv.org/abs/2406.01179. arXiv:2406.01179 [cs]. Zheng Huang, Kai Chen, Jianhua He, Xiang Bai, Dimosthenis Karatzas, Shjian Lu, and C. V . Jawahar. ICDAR2019 Competition on Scanned Receipt OCR and Information Extraction. In 2019 International Conference on Document Analysis and Recognition (ICDAR), pages 1516– 1520, September
arXiv 2019
-
[12]
doi: 10.1109/ICDAR.2019.00244. URL http://arxiv.org/abs/2103. 10213. arXiv:2103.10213 [cs]. Trung-Nghia Le, Huy H. Nguyen, Junichi Yamagishi, and Isao Echizen. OpenForensics: Large-Scale Challenging Dataset for Multi-Face Forgery Detection and Segmentation In-the-Wild. pages 10117–10127,
-
[13]
URL http://arxiv.org/abs/1909.12962. arXiv:1909.12962 [cs]. Sina Mavali, Jonas Ricker, David Pape, Asja Fischer, and Lea Schönherr. Adversarial Robustness of AI-Generated Image Detectors in the Real World, June
arXiv 1909
-
[14]
URL http://arxiv.org/abs/ 2410.01574. arXiv:2410.01574 [cs]. Seunghyun Park, Seung Shin, Bado Lee, Junyeop Lee, Jaeheung Surh, Minjoon Seo, and Hwalsuk Lee. CORD: A Consolidated Receipt Dataset for Post-OCR Parsing. InWorkshop on Document Intelligence at NeurIPS 2019, Vancouver, Canada,
Pith/arXiv arXiv 2019
-
[15]
arXiv:2507.18640 [cs] version:
URL http://arxiv.org/abs/2507.18640. arXiv:2507.18640 [cs] version:
-
[16]
URL http://arxiv.org/abs/1901.08971. arXiv:1901.08971 [cs]. Nicolas Sidere, Francisco Cruz, Mickal Coustaty, and Jean-Marc Ogier. A dataset for forgery detection and spotting in document images. In2017 Seventh International Conference on Emerging Security Technologies (EST), pages 26–31, September
arXiv 1901
-
[17]
URL https://ieeexplore.ieee.org/document/8090394
doi: 10.1109/EST.2017.8090394. URL https://ieeexplore.ieee.org/document/8090394. ISSN: 2472-7601. Beatriz Martínez Tornés, Théo Taburet, Emanuela Boros, Kais Rouis, Antoine Doucet, Petra Gomez- Krämer, Nicolas Sidere, and Vincent Poulain d’Andecy. Receipt Dataset for Document Forgery Detection. InDocument Analysis and Recognition - ICDAR 2023: 17th Intern...
-
[18]
Springer-Verlag. ISBN 978-3-031-41681-1. doi: 10.1007/978-3-031-41682-8_28. URLhttps://doi.org/10.1007/978-3-031-41682-8_28. 11 Jordy Van Landeghem, Rubèn Tito, Łukasz Borchmann, Michał Pietruszka, Dawid Jurkiewicz, Rafał Powalski, Paweł Józiak, Sanket Biswas, Mickaël Coustaty, and Tomasz Stanisławek. ICDAR 2023 Competition on Document UnderstanDing of Ev...
-
[19]
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A
URL https: //link.springer.com/10.1007/978-3-031-41679-8_24. Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A. Efros. CNN-generated images are surprisingly easy to spot... for now, April
-
[20]
URL http://arxiv.org/abs/1912. 11035. arXiv:1912.11035 [cs]. A Generator Configuration and Pinned Versions The generation pipeline reads its configuration from a single tools.yaml file released alongside the corpus. Every manifest entry records the tool_specific string of the variant that produced it, so any future drift in the underlying APIs is recovera...
arXiv 1912
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.