REACT 2026: The Fourth Multiple Appropriate Facial Reaction Generation Challenge: Personalised MAFRG and Appropriate EEG Reaction Prediction
Pith reviewed 2026-06-27 20:25 UTC · model grok-4.3
The pith
REACT 2026 extends the MARS dataset with Big-Five personality labels and EEG recordings to support one-to-many personalized facial reaction generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
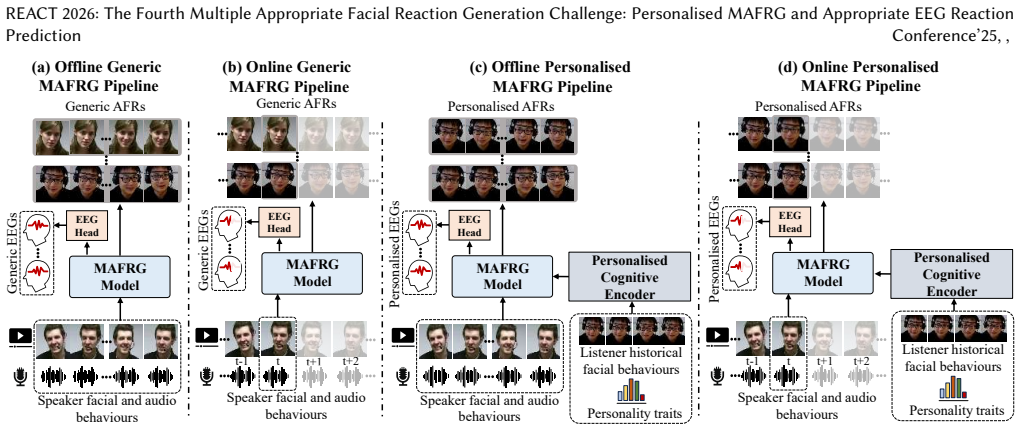
The central claim is that providing the MARS dataset together with Big-Five personality labels and EEG recordings creates a new one-to-many personalised facial reaction generation setting that combines human expressive behavioural, affective and neurophysiological signals and remains largely unexplored in current dyadic interaction modelling.
What carries the argument
The MARS dataset augmented with individual-level Big-Five personality labels and EEG recordings, which supplies the input signals for the one-to-many personalised MAFRG task.
If this is right
- Models can now be developed and benchmarked for offline generic MAFRG.
- Models can now be developed and benchmarked for offline personalised MAFRG.
- Models can now be developed and benchmarked for online generic MAFRG.
- Models can now be developed and benchmarked for online personalised MAFRG.
Where Pith is reading between the lines
- The same augmented signals could be tested for predicting listener EEG responses rather than only facial reactions.
- Personality and EEG features might be used to adapt reaction generation in real time during live conversations.
- The setting could be extended to other modalities such as voice or gesture to check whether the personalization benefit generalizes.
Load-bearing premise
That adding Big-Five personality labels and EEG recordings to the MARS dataset will enable models to produce personalised, appropriate, diverse, realistic and synchronised reactions.
What would settle it
A controlled experiment in which models trained with the added personality and EEG data show no measurable improvement in personalization or appropriateness metrics compared with models trained on the original MARS data alone.
Figures

read the original abstract
In dyadic interactions, various human facial reactions could be appropriate for responding to each human speaker behaviour. Following the successful organisation of the REACT 2023, 2024 and 2025 challenge series, a body of generative deep learning (DL) models have been developed for the problem of multiple appropriate facial reaction generation (MAFRG). This year, we propose the REACT 2026 challenge encouraging the development and benchmarking of Machine Learning (ML) models that can generate multiple personalised, appropriate, diverse, realistic and synchronised human-style facial reactions expressed by a specific human listener for responding to each given speaker behaviour. As a key of the challenge, we continuously provide challenge participants with MARS dataset introduced by REACT 2025 but additionally provide individual-level Big-Five personality labels and EEG recordings. This introduces a new one-to-many personalised facial reaction generation setting combining human expressive behavioural, affective and neurophysiological signals, which remains largely unexplored in current dyadic interaction modelling. This paper also presents the challenge guidelines and new baselines on the four proposed sub-challenges: Offline generic and personalised MAFRG as well as Online generic and personalised MAFRG, respectively, which are publicly available at https://github.com/reactmultimodalchallenge/baseline_react2026.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript announces the REACT 2026 challenge, the fourth in the series, which defines four sub-challenges (offline/online generic MAFRG and offline/online personalised MAFRG). It augments the prior MARS dataset with individual-level Big-Five personality labels and EEG recordings to support development of models generating multiple personalised, appropriate, diverse, realistic and synchronised facial reactions, supplies challenge guidelines, and releases baseline implementations on GitHub.
Significance. The public release of baselines and the multimodal extension of an existing dataset provide a concrete, reproducible starting point for exploring neurophysiological and personality-conditioned reaction generation, an area noted as largely unexplored. If the challenge attracts competitive submissions, it could help establish standardised evaluation protocols for one-to-many personalised dyadic modelling.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the REACT 2026 challenge manuscript, the recognition of its significance in providing reproducible baselines and multimodal extensions, and the recommendation to accept.
Circularity Check
No significant circularity identified
full rationale
The paper is a challenge organization document announcing four sub-challenges on the augmented MARS dataset. It contains no mathematical derivations, equations, fitted parameters, predictions, or uniqueness theorems. The text only defines tasks, supplies baselines, and states that the combined behavioural/affective/neurophysiological setting is provided for participants to explore; no claim reduces to a self-definition or self-citation chain. This matches the default non-circular case for dataset/challenge papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. 2020. wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in neural information processing systems33 (2020), 12449–12460
2020
-
[2]
Quang Tien Dam, Tri Tung Nguyen Nguyen, Dinh Tuan Tran, and Joo-Ho Lee. 2024. Finite Scalar Quantization as Facial Tokenizer for Dyadic Reaction Generation. In2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG). IEEE, 1–5
2024
-
[3]
Ulf Dimberg. 1982. Facial reactions to facial expressions.Psychophysiology19, 6 (1982), 643–647
1982
-
[4]
Evonne Ng et al. 2022. Learning to listen: Modeling non-deterministic dyadic facial motion. InIEEE/CVF CVPR 2022. 20395–20405
2022
-
[5]
Song et al. 2022. Learning Person-specific Cognition from Facial Reactions for Automatic Personality Recognition.IEEE Transactions on Affective Computing (2022)
2022
- [6]
-
[7]
Yuchi et al. 2017. Dyadgan: Generating facial expressions in dyadic interactions. InIEEE CVPR Workshops 2017. 11–18
2017
- [8]
-
[9]
Ursula Hess, Pierre Phillippot, and Sylvie Blairy. 1998. Facial reactions to emo- tional facial expressions: Affect or cognition?Cognition & Emotion12, 4 (1998), 509–531
1998
-
[10]
Ximi Hoque, Adamay Mann, Gulshan Sharma, and Abhinav Dhall. 2023. BEAMER: Behavioral Encoder to Generate Multiple Appropriate Facial Reactions. InProceedings of the ACM International Conference on Multimedia. 9536–9540
2023
-
[11]
Guanyu Hu, Jie Wei, Siyang Song, Dimitrios Kollias, Xinyu Yang, Zhonglin Sun, and Odysseus Kaloidas. 2024. Robust Facial Reactions Generation: An Emotion- Aware Framework with Modality Compensation. In2024 IEEE International Joint Conference on Biometrics (IJCB). IEEE, 1–10
2024
-
[12]
Jiajian Huang, Siyang Song, Xiangyu Kong, Weicheng Xie, Linlin Shen, and Zitong Yu. 2025. Online Emotion-Driven Generation of Multiple Appropriate Facial Reactions. InChinese Conference on Biometric Recognition. Springer, 183– 194
2025
-
[13]
Jiajian Huang and Zitong Yu. 2025. Multiple Appropriate Facial Reaction Gener- ation Based on Multi-View Transformation of Speaker Video. InProceedings of the 33rd ACM International Conference on Multimedia. 13992–13996
2025
-
[14]
Cong Liang, Jiahe Wang, Haofan Zhang, Bing Tang, Junshan Huang, Shangfei Wang, and Xiaoping Chen. 2023. UniFaRN: Unified Transformer for Facial Reaction Generation. InProceedings of the ACM International Conference on Multimedia. 9506–9510
2023
-
[15]
Zhenjie Liu, Cong Liang, Jiahe Wang, Haofan Zhang, Yadong Liu, Caichao Zhang, Jialin Gui, and Shangfei Wang. 2024. One-to-Many Appropriate Reaction Map- ping Modeling with Discrete Latent Variable. In2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG). IEEE, 1–5
2024
- [16]
-
[17]
Cheng Luo, Siyang Song, Weicheng Xie, Micol Spitale, Zongyuan Ge, Linlin Shen, and Hatice Gunes. 2024. ReactFace: Online Multiple Appropriate Facial Reaction Generation in Dyadic Interactions.IEEE Transactions on Visualization and Computer Graphics(2024)
2024
-
[18]
Cheng Luo, Siyang Song, Siyuan Yan, Zhen Yu, and Zongyuan Ge. 2025. Re- actDiff: Fundamental Multiple Appropriate Facial Reaction Diffusion Model. In Proceedings of the 33rd ACM International Conference on Multimedia. 5607–5616
2025
-
[19]
Qincheng Lv, Xiaofeng Liu, Jie Li, Rongrong Ni, Pujun Xue, and Siyang Song. 2025. Hierarchical Multimodal Decoupling-Fusion Framework for offline Multiple Appropriate Facial Reaction Generation. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2025
-
[20]
Qirong Mao, Qiwei Wu, Na Liu, Yakui Ding, and Lijian Gao. 2025. Scattering- Conditioned Diffusion Models for Multiple Appropriate Facial Reaction Gener- ation. InProceedings of the 33rd ACM International Conference on Multimedia. 13985–13991
2025
-
[21]
1974.An approach to environmental psychology.the MIT Press
Albert Mehrabian and James A Russell. 1974.An approach to environmental psychology.the MIT Press
1974
-
[22]
Dang-Khanh Nguyen, Prabesh Paudel, Seung-Won Kim, Ji-Eun Shin, Soo-Hyung Kim, and Hyung-Jeong Yang. 2024. Multiple Facial Reaction Generation Using Gaussian Mixture of Models and Multimodal Bottleneck Transformer. In2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG). IEEE, 1–5
2024
-
[23]
Minh-Duc Nguyen, Hyung-Jeong Yang, Ngoc-Huynh Ho, Soo-Hyung Kim, Se- ungwon Kim, and Ji-Eun Shin. 2024. Vector Quantized Diffusion Models for Multiple Appropriate Reactions Generation. In2024 IEEE 18th International Con- ference on Automatic Face and Gesture Recognition (FG). IEEE, 1–5
2024
-
[24]
Minh-Duc Nguyen, Hyung-Jeong Yang, Soo-Hyung Kim, Ji-Eun Shin, and Seung- Won Kim. 2025. Latent behaviour Diffusion for Sequential Reaction Generation in Dyadic Setting. InInternational Conference on Pattern Recognition. Springer, 233–248
2025
-
[25]
Zilong Shao, Siyang Song, Shashank Jaiswal, Linlin Shen, Michel Valstar, and Hatice Gunes. 2021. Personality recognition by modelling person-specific cog- nitive processes using graph representation. Inproceedings of the 29th ACM international conference on multimedia. 357–366
2021
-
[26]
Siyang Song, Yuxin Song, Cheng Luo, Zhiyuan Song, Selim Kuzucu, Xi Jia, Zhijiang Guo, Weicheng Xie, Linlin Shen, and Hatice Gunes. 2022. Gratis: Deep learning graph representation with task-specific topology and multi-dimensional edge features.arXiv preprint arXiv:2211.12482(2022)
-
[27]
Siyang Song, Micol Spitale, Xiangyu Kong, Hengde Zhu, Cheng Luo, Cristina Palmero, German Barquero, Sergio Escalera, Michel Valstar, Mohamed Daoudi, et al. 2025. React 2025: the third multiple appropriate facial reaction generation challenge. InProceedings of the 33rd ACM International Conference on Multimedia. 13979–13984
2025
-
[28]
Siyang Song, Micol Spitale, Cheng Luo, Germán Barquero, Cristina Palmero, Sergio Escalera, Michel Valstar, Tobias Baur, Fabien Ringeval, Elisabeth André, et al. 2023. React2023: The first multiple appropriate facial reaction generation challenge. InProceedings of the 31st ACM International Conference on Multimedia. 9620–9624
2023
-
[29]
Siyang Song, Micol Spitale, Cheng Luo, Cristina Palmero, German Barquero, Hengde Zhu, Sergio Escalera, Michel Valstar, Tobias Baur, Fabien Ringeval, et al
- [30]
-
[31]
Antoine Toisoul and et al. 2021. Estimation of continuous valence and arousal levels from faces in naturalistic conditions.Nature Machine Intelligence3, 1 (2021), 42–50
2021
-
[32]
Minh Tran, Di Chang, Maksim Siniukov, and Mohammad Soleymani. 2024. DIM: Dyadic Interaction Modeling for Social Behavior Generation. InEuropean Con- ference on Computer Vision. Springer, 484–503
2024
-
[33]
Lizhen Wang, Zhiyuan Chen, Tao Yu, Chenguang Ma, Liang Li, and Yebin Liu
-
[34]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Faceverse: a fine-grained and detail-controllable 3d face morphable model from a hybrid dataset. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 20333–20342
-
[35]
Peng Wang, Pujun Xue, Xiaofeng Liu, and Tongjuan Ji. 2025. Explaining Listener Reactions: Personality-Guided Facial Response Generation with Cross-Modal Attention. InProceedings of the 33rd ACM International Conference on Multimedia. 13997–14003
2025
-
[36]
Weicheng Xie, Chunlin Yan, Siyang Song, Zitong Yu, Linlin Shen, and Laizhong Cui. 2025. Smooth Online Multiple Appropriate Facial Reaction Generation. In Proceedings of the 33rd ACM International Conference on Multimedia. 5804–5813
2025
-
[37]
Tong Xu, Micol Spitale, Hao Tang, Lu Liu, Hatice Gunes, and Siyang Song
-
[38]
Reversible graph neural network-based reaction distribution learning for multiple appropriate facial reactions generation.IEEE Transactions on Affective Computing(2026)
2026
-
[39]
Jun Yu, Ji Zhao, Guochen Xie, Fengxin Chen, Ye Yu, Liang Peng, Minglei Li, and Zonghong Dai. 2023. Leveraging the Latent Diffusion Models for Offline Facial Multiple Appropriate Reactions Generation. InProceedings of the ACM International Conference on Multimedia. 9561–9565
2023
-
[40]
Mohan Zhou, Yalong Bai, Wei Zhang, Ting Yao, Tiejun Zhao, and Tao Mei. 2022. Responsive listening head generation: a benchmark dataset and baseline. In European conference on computer vision. Springer, 124–142
2022
-
[41]
Hengde Zhu, Xiangyu Kong, Weicheng Xie, Xin Huang, Xilin He, Lu Liu, Linlin Shen, Wei Zhang, Hatice Gunes, and Siyang Song. 2025. PerReactor: Offline Personalised Multiple Appropriate Facial Reaction Generation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 1665–1673
2025
-
[42]
Hengde Zhu, Xiangyu Kong, Weicheng Xie, Xin Huang, Linlin Shen, Lu Liu, Hatice Gunes, and Siyang Song. 2024. Perfrdiff: Personalised weight editing for multiple appropriate facial reaction generation. InProceedings of the 32nd ACM International Conference on Multimedia. 9495–9504
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.