PAFO: Pareto Fairness Optimization for Personalized Reward Modeling
Pith reviewed 2026-06-27 19:58 UTC · model grok-4.3
The pith
PAFO distills separate majority and minority reward models into one unified model that raises accuracy for both groups on imbalanced preference data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
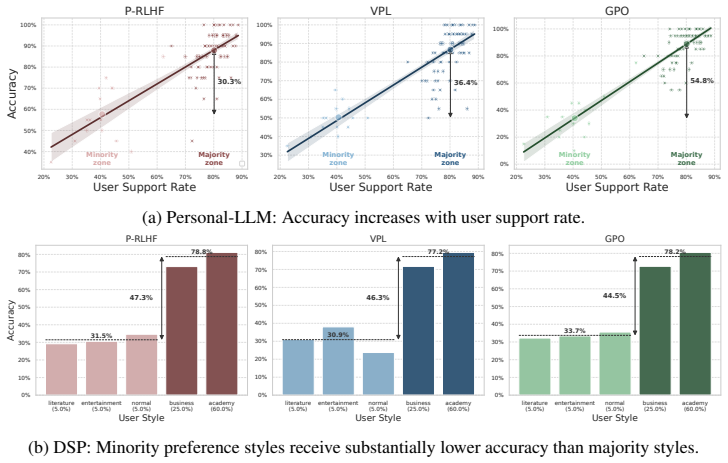
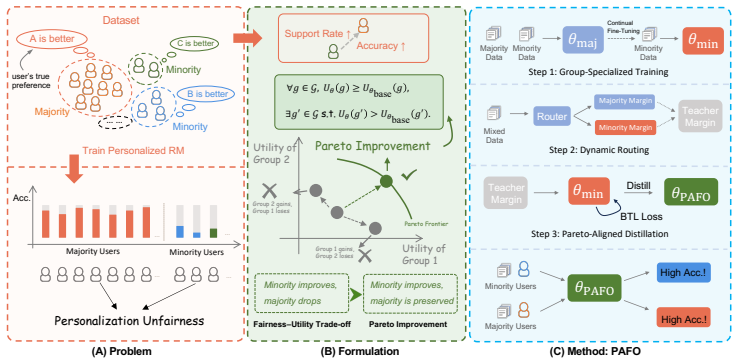
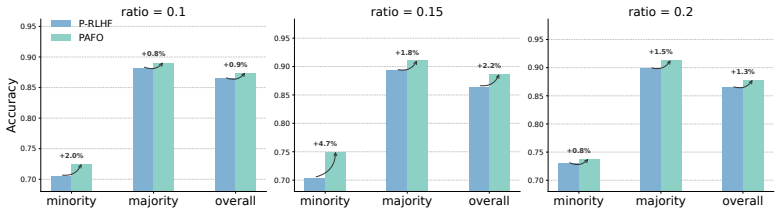
PAFO trains separate reward models on majority and minority preference groups, then constructs conditional margin-level supervision signals that embed the heterogeneous boundaries of those models into one unified reward model; the unified model improves accuracy on both groups and reduces multiple user-level unfairness metrics while requiring no group labels after training.
What carries the argument
Conditional margin-level supervision that transfers heterogeneous preference boundaries from group-specialized reward models into a single unified model.
If this is right
- Both minority-group and majority-group accuracy rise compared with standard training.
- Multiple user-level unfairness metrics fall while overall performance improves.
- The model operates at inference without any group label or demographic input.
Where Pith is reading between the lines
- The same distillation step could be applied to other preference-learning settings that face population imbalance.
- Removing the need for group labels at deployment may lower privacy and regulatory costs in production systems.
- If the Pareto step can be made differentiable end-to-end, the framework might extend to online preference collection loops.
Load-bearing premise
Group-specialized reward models can be trained on the given imbalanced data and their differing boundaries can be distilled into one model without creating new distortions.
What would settle it
On the Personal-LLM or DSP test sets, the final unified model shows either lower minority-group accuracy than a standard personalized baseline or lower majority-group accuracy than the same baseline.
Figures

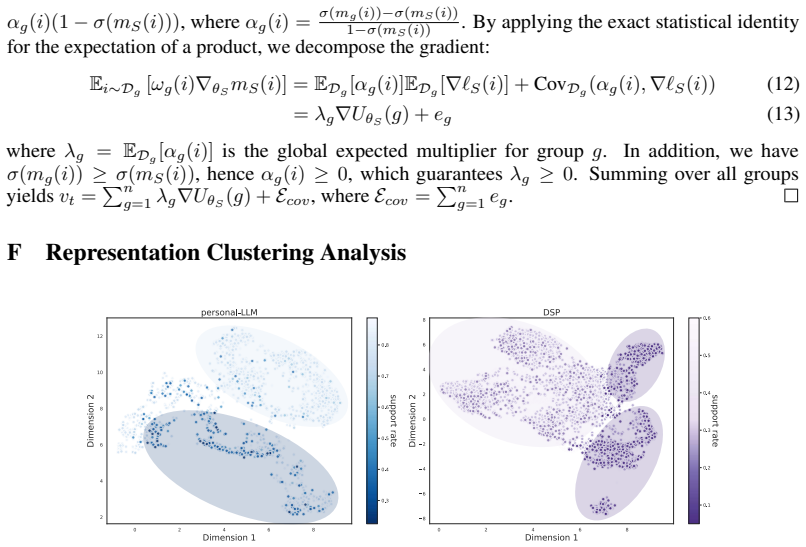
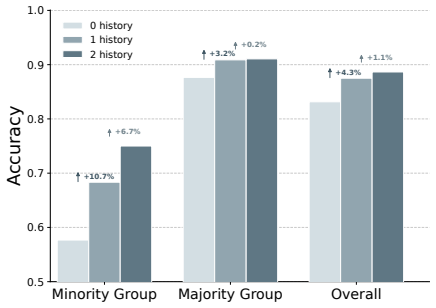
read the original abstract
Large language models (LLMs) increasingly rely on reward models to align their outputs with diverse user preferences. While personalized reward models aim to capture such heterogeneity, they are often trained on imbalanced user preference data and may therefore favor users whose preferences are more common in the training population. In this paper, we identify this failure mode as personalized reward bias, where reward modeling quality varies systematically with preference support rate. We formulate its mitigation as a Pareto fairness problem over group utilities, aiming to improve under-served users without degrading other user groups. To this end, we propose PAFO, a Pareto fairness optimization framework for personalized reward modeling. PAFO first trains group-specialized reward models for majority and minority preference groups, then constructs conditional margin-level supervision to distill their heterogeneous preference boundaries into a single unified model. The resulting model uses group information only during training and requires no explicit group labels at inference time. Experiments on Personal-LLM and DSP show that PAFO improves both minority-group and majority-group accuracy while reducing user-level unfairness across multiple metrics, demonstrating its effectiveness for fairer LLM personalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies 'personalized reward bias' in LLM reward models trained on imbalanced user preference data, where quality varies with preference support rate. It formulates mitigation as a Pareto fairness problem over group utilities and proposes PAFO: train separate group-specialized reward models on majority and minority groups, then distill their heterogeneous boundaries into one unified model via conditional margin-level supervision. The unified model requires no group labels at inference. Experiments on Personal-LLM and DSP datasets report simultaneous accuracy gains for both minority and majority groups plus reduced user-level unfairness across metrics.
Significance. If the central claim holds, the work addresses a practically important failure mode in personalized LLM alignment. The two-stage specialized-then-distill approach is a concrete attempt to achieve Pareto improvements without inference-time group information. Credit is due for evaluating on two distinct datasets and multiple fairness metrics rather than a single contrived setting.
major comments (2)
- [§3] §3 (method): The claim that conditional margin-level supervision successfully transfers heterogeneous boundaries from the two specialized models into a single model without new distortions or leakage is load-bearing for the Pareto claim, yet the manuscript provides no derivation, proof sketch, or formal statement showing that the supervision construction preserves the separate group utilities. The skeptic note correctly flags that minority models trained on low-support data may produce noisy boundaries that do not distill cleanly.
- [§5] §5 (experiments): The reported simultaneous gains for both groups rest on the distillation step, but the manuscript contains no ablation that isolates the contribution of the conditional margin supervision (e.g., comparison against a single model trained with standard loss or with group labels at inference). Without such controls it is impossible to confirm that the observed improvements are attributable to PAFO rather than other modeling choices.
minor comments (2)
- Notation for the margin-level supervision (how the conditioning variable is constructed and fed to the unified model) is introduced without an explicit equation or pseudocode; a small diagram or algorithm box would improve clarity.
- The definition of 'user-level unfairness' metrics should be stated explicitly in the main text rather than deferred entirely to the appendix, as these are central to the fairness claims.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting areas where the manuscript can be strengthened. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [§3] §3 (method): The claim that conditional margin-level supervision successfully transfers heterogeneous boundaries from the two specialized models into a single model without new distortions or leakage is load-bearing for the Pareto claim, yet the manuscript provides no derivation, proof sketch, or formal statement showing that the supervision construction preserves the separate group utilities. The skeptic note correctly flags that minority models trained on low-support data may produce noisy boundaries that do not distill cleanly.
Authors: We agree that the manuscript would benefit from a more formal treatment of the supervision construction. The conditional margin-level supervision is intended to distill heterogeneous boundaries by applying group-specific margin adjustments during the distillation phase, with the goal of preserving the specialized utilities in a single model that does not require group labels at inference. However, no derivation or proof sketch is provided, and the approach relies on empirical results. In the revision we will expand §3 with a detailed description of the supervision mechanism and add a proof sketch (under the assumption of accurate specialized models) together with a discussion of how noise in low-support minority boundaries may affect distillation quality. revision: yes
-
Referee: [§5] §5 (experiments): The reported simultaneous gains for both groups rest on the distillation step, but the manuscript contains no ablation that isolates the contribution of the conditional margin supervision (e.g., comparison against a single model trained with standard loss or with group labels at inference). Without such controls it is impossible to confirm that the observed improvements are attributable to PAFO rather than other modeling choices.
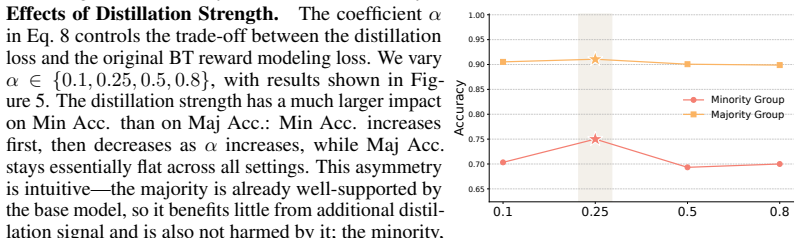
Authors: We acknowledge that the current experimental section does not contain the requested ablations to isolate the distillation component. While the reported results show simultaneous gains for both groups relative to standard personalized reward models on two datasets, they do not directly compare against a single model trained with standard loss or against an oracle with group labels at inference. In the revised manuscript we will add these controls in §5 to better attribute performance improvements to the conditional margin supervision step. revision: yes
Circularity Check
PAFO framework is self-contained; no derivation reduces to its inputs by construction
full rationale
The abstract and described procedure introduce a training pipeline (specialized models followed by conditional margin distillation) that operates on external datasets and standard supervised learning steps. No equations, fitted parameters, or uniqueness claims are presented that loop back to the target result by definition. The central claim of Pareto improvement rests on empirical validation rather than self-referential definitions or self-citation chains. This matches the reader's assessment that the abstract contains no fitted quantities or circular indicators, confirming the derivation chain is independent.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[2]
Learning to summarize with human feedback
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. Advances in neural information processing systems, 33:3008–3021, 2020
2020
-
[3]
Rethinking the role of proxy rewards in language model alignment
Sungdong Kim and Minjoon Seo. Rethinking the role of proxy rewards in language model alignment. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 20656–20674, 2024
2024
-
[4]
Pairwise rm: Perform best-of-n sampling with knockout tournament.arXiv e-prints, pages arXiv–2501, 2025
Yantao Liu, Zijun Yao, Rui Min, Yixin Cao, Lei Hou, and Juanzi Li. Pairwise rm: Perform best-of-n sampling with knockout tournament.arXiv e-prints, pages arXiv–2501, 2025
2025
-
[5]
Reward-guided tree search for inference time alignment of large language models
Chia-Yu Hung, Navonil Majumder, Ambuj Mehrish, and Soujanya Poria. Reward-guided tree search for inference time alignment of large language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 12575–12593, 2025
2025
-
[6]
Post-hoc reward calibration: A case study on length bias.arXiv preprint arXiv:2409.17407, 2024
Zeyu Huang, Zihan Qiu, Zili Wang, Edoardo M Ponti, and Ivan Titov. Post-hoc reward calibration: A case study on length bias.arXiv preprint arXiv:2409.17407, 2024
-
[7]
Bias and fairness in large language models: A survey.Computational linguistics, 50(3):1097–1179, 2024
Isabel O Gallegos, Ryan A Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, and Nesreen K Ahmed. Bias and fairness in large language models: A survey.Computational linguistics, 50(3):1097–1179, 2024
2024
-
[8]
A long way to go: Investigating length correlations in rlhf.arXiv preprint arXiv:2310.03716,
Prasann Singhal, Tanya Goyal, Jiacheng Xu, and Greg Durrett. A long way to go: Investigating length correlations in rlhf.arXiv preprint arXiv:2310.03716, 2023
-
[9]
Large language models are biased reinforcement learners.arXiv preprint arXiv:2405.11422, 2024
William M Hayes, Nicolas Yax, and Stefano Palminteri. Large language models are biased reinforcement learners.arXiv preprint arXiv:2405.11422, 2024
-
[10]
Rewardbench: Evaluating reward models for language modeling
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, et al. Rewardbench: Evaluating reward models for language modeling. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 1755–1797, 2025
2025
-
[11]
Towards understanding sycophancy in language models
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, Esin Durmus, Zac Hatfield-Dodds, Scott R Johnston, Shauna M Kravec, et al. Towards understanding sycophancy in language models. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[12]
Jiancong Xiao, Ziniu Li, Xingyu Xie, Emily Getzen, Cong Fang, Qi Long, and Weijie J Su. On the algorithmic bias of aligning large language models with rlhf: Preference collapse and matching regularization.arXiv preprint arXiv:2405.16455, 2024. 10
-
[13]
Kefan Song, Jin Yao, Runnan Jiang, Rohan Chandra, and Shangtong Zhang. Towards large language models that benefit for all: Benchmarking group fairness in reward models.arXiv preprint arXiv:2503.07806, 2025
-
[14]
Nextquill: Causal preference modeling for enhancing llm personalization
Xiaoyan Zhao, Juntao You, Yang Zhang, Wenjie Wang, Hong Cheng, Fuli Feng, See-Kiong Ng, and Tat-Seng Chua. Nextquill: Causal preference modeling for enhancing llm personalization. ICLR, 2026
2026
-
[15]
Reinforced latent reasoning for llm-based recommendation.ICLR, 2026
Yang Zhang, Wenxin Xu, Xiaoyan Zhao, Wenjie Wang, Fuli Feng, Xiangnan He, and Tat-Seng Chua. Reinforced latent reasoning for llm-based recommendation.ICLR, 2026
2026
-
[16]
Steerx: Disentangled steering for llm personalization.arXiv preprint arXiv:2510.22256, 2025
Xiaoyan Zhao, Ming Yan, Yilun Qiu, Haoting Ni, Yang Zhang, Fuli Feng, Hong Cheng, and Tat-Seng Chua. Steerx: Disentangled steering for llm personalization.arXiv preprint arXiv:2510.22256, 2025
-
[17]
Latent inter-user difference modeling for llm personalization
Yilun Qiu, Tianhao Shi, Xiaoyan Zhao, Fengbin Zhu, Yang Zhang, and Fuli Feng. Latent inter-user difference modeling for llm personalization. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 10610–10628, 2025
2025
-
[18]
When personalization meets reality: A multi-faceted analysis of personalized preference learning
Yijiang River Dong, Tiancheng Hu, Yinhong Liu, Ahmet Üstün, and Nigel Collier. When personalization meets reality: A multi-faceted analysis of personalized preference learning. arXiv preprint arXiv:2502.19158, 2025
-
[19]
Fairness aware reward optimization.arXiv preprint arXiv:2602.07799, 2026
Ching Lam Choi, Vighnesh Subramaniam, Phillip Isola, Antonio Torralba, and Stefanie Jegelka. Fairness aware reward optimization.arXiv preprint arXiv:2602.07799, 2026
-
[20]
https://arxiv.org/abs/2409.20296
Thomas P Zollo, Andrew Wei Tung Siah, Naimeng Ye, Ang Li, and Hongseok Namkoong. Personalllm: Tailoring llms to individual preferences.arXiv preprint arXiv:2409.20296, 2024
-
[21]
Pengyu Cheng, Jiawen Xie, Ke Bai, Yong Dai, and Nan Du. Everyone deserves a reward: Learning customized human preferences.arXiv preprint arXiv:2309.03126, 2023
-
[22]
Towards reward fairness in rlhf: From a resource allocation perspective
Sheng Ouyang, Yulan Hu, Ge Chen, Qingyang Li, Fuzheng Zhang, and Yong Liu. Towards reward fairness in rlhf: From a resource allocation perspective. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3247–3259, 2025
2025
-
[23]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[24]
Multi-task learning as multi-objective optimization.Advances in neural information processing systems, 31, 2018
Ozan Sener and Vladlen Koltun. Multi-task learning as multi-objective optimization.Advances in neural information processing systems, 31, 2018
2018
-
[25]
Multiple-gradient descent algorithm (mgda) for multiobjective opti- mization.Comptes Rendus
Jean-Antoine Désidéri. Multiple-gradient descent algorithm (mgda) for multiobjective opti- mization.Comptes Rendus. Mathématique, 350(5-6):313–318, 2012
2012
-
[26]
Xinyu Li, Ruiyang Zhou, Zachary C Lipton, and Liu Leqi. Personalized language modeling from personalized human feedback.arXiv preprint arXiv:2402.05133, 2024
-
[27]
Per- sonalizing reinforcement learning from human feedback with variational preference learning
Sriyash Poddar, Yanming Wan, Hamish Ivison, Abhishek Gupta, and Natasha Jaques. Per- sonalizing reinforcement learning from human feedback with variational preference learning. Advances in Neural Information Processing Systems, 37:52516–52544, 2024
2024
-
[28]
Siyan Zhao, John Dang, and Aditya Grover. Group preference optimization: Few-shot alignment of large language models.arXiv preprint arXiv:2310.11523, 2023
-
[29]
Reinforced strategy optimization for conversational recommender systems via network-of-experts.arXiv e-prints, pages arXiv–2509, 2025
Xiaoyan Zhao, Ming Yan, Yang Zhang, Yang Deng, Jian Wang, Fengbin Zhu, Yilun Qiu, Hong Cheng, and Tat-Seng Chua. Reinforced strategy optimization for conversational recommender systems via network-of-experts.arXiv e-prints, pages arXiv–2509, 2025
2025
-
[30]
Lore: Personalizing llms via low-rank reward modeling.arXiv preprint arXiv:2504.14439, 2025
Avinandan Bose, Zhihan Xiong, Yuejie Chi, Simon Shaolei Du, Lin Xiao, and Maryam Fazel. Lore: Personalizing llms via low-rank reward modeling.arXiv preprint arXiv:2504.14439, 2025. 11
-
[31]
Think-while-generating: On-the-fly reasoning for personalized long-form generation.ICLR, 2026
Chengbing Wang, Yang Zhang, Wenjie Wang, Xiaoyan Zhao, Fuli Feng, Xiangnan He, and Tat-Seng Chua. Think-while-generating: On-the-fly reasoning for personalized long-form generation.ICLR, 2026
2026
-
[32]
arXiv preprint arXiv:2503.06358 (2025)
Idan Shenfeld, Felix Faltings, Pulkit Agrawal, and Aldo Pacchiano. Language model personal- ization via reward factorization.arXiv preprint arXiv:2503.06358, 2025
-
[33]
Pad: Personalized alignment of llms at decoding-time.arXiv preprint arXiv:2410.04070, 2024
Ruizhe Chen, Xiaotian Zhang, Meng Luo, Wenhao Chai, and Zuozhu Liu. Pad: Personalized alignment of llms at decoding-time.arXiv preprint arXiv:2410.04070, 2024
-
[34]
Maxmin-rlhf: Towards equitable alignment of large language models with diverse human preferences
Souradip Chakraborty, Jiahao Qiu, Hui Yuan, Alec Koppel, Furong Huang, Dinesh Manocha, Amrit Bedi, and Mengdi Wang. Maxmin-rlhf: Towards equitable alignment of large language models with diverse human preferences. InICML 2024 Workshop on Models of Human Feedback for AI Alignment, 2024
2024
-
[35]
Hannah R Kirk, Alexander Whitefield, Paul Röttger, Andrew Bean, Katerina Margatina, Juan Ciro, Rafael Mosquera, Max Bartolo, Adina Williams, He He, et al. The prism alignment dataset: What participatory, representative and individualised human feedback reveals about the subjective and multicultural alignment of large language models.Advances in Neural Inf...
2024
-
[36]
Group robust preference optimization in reward-free rlhf.Advances in Neural Information Processing Systems, 37:37100–37137, 2024
Shyam Sundhar Ramesh, Yifan Hu, Iason Chaimalas, Viraj Mehta, Pier Giuseppe Sessa, Haitham Bou Ammar, and Ilija Bogunovic. Group robust preference optimization in reward-free rlhf.Advances in Neural Information Processing Systems, 37:37100–37137, 2024
2024
-
[37]
Jialu Wang, Heinrich Peters, Asad A Butt, Navid Hashemi, Alireza Hashemi, Pouya M Ghari, Joseph Hoover, James Rae, and Morteza Dehghani. Personalized group relative policy optimiza- tion for heterogenous preference alignment.arXiv preprint arXiv:2603.10009, 2026
-
[38]
arXiv preprint arXiv:2405.00254 , year=
Chanwoo Park, Mingyang Liu, Dingwen Kong, Kaiqing Zhang, and Asuman Ozdaglar. Rlhf from heterogeneous feedback via personalization and preference aggregation.arXiv preprint arXiv:2405.00254, 2024
-
[39]
Direct alignment with heterogeneous preferences.arXiv preprint arXiv:2502.16320, 2025
Ali Shirali, Arash Nasr-Esfahany, Abdullah Alomar, Parsa Mirtaheri, Rediet Abebe, and Ariel Procaccia. Direct alignment with heterogeneous preferences.arXiv preprint arXiv:2502.16320, 2025
-
[40]
Beyond one-preference-for-all: Multi-objective direct preference optimization
Zhanhui Zhou, Jie Liu, Chao Yang, Jing Shao, Yu Liu, Xiangyu Yue, Wanli Ouyang, and Yu Qiao. Beyond one-preference-for-all: Multi-objective direct preference optimization. 2023
2023
-
[41]
Arithmetic control of llms for diverse user preferences: Directional preference alignment with multi-objective rewards
Haoxiang Wang, Yong Lin, Wei Xiong, Rui Yang, Shizhe Diao, Shuang Qiu, Han Zhao, and Tong Zhang. Arithmetic control of llms for diverse user preferences: Directional preference alignment with multi-objective rewards. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8642–8655, 2024
2024
-
[42]
Rui Yang, Xiaoman Pan, Feng Luo, Shuang Qiu, Han Zhong, Dong Yu, and Jianshu Chen. Rewards-in-context: Multi-objective alignment of foundation models with dynamic preference adjustment.arXiv preprint arXiv:2402.10207, 2024
-
[43]
Metaaligner: Towards generalizable multi-objective alignment of language models.Advances in Neural Information Processing Systems, 37:34453–34486, 2024
Kailai Yang, Zhiwei Liu, Qianqian Xie, Jimin Huang, Tianlin Zhang, and Sophia Ananiadou. Metaaligner: Towards generalizable multi-objective alignment of language models.Advances in Neural Information Processing Systems, 37:34453–34486, 2024
2024
-
[44]
Panacea: Pareto alignment via preference adaptation for llms
Yifan Zhong, Chengdong Ma, Xiaoyuan Zhang, Ziran Yang, Haojun Chen, Qingfu Zhang, Siyuan Qi, and Yaodong Yang. Panacea: Pareto alignment via preference adaptation for llms. Advances in Neural Information Processing Systems, 37:75522–75558, 2024
2024
-
[45]
Interpretable prefer- ences via multi-objective reward modeling and mixture-of-experts
Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, and Tong Zhang. Interpretable prefer- ences via multi-objective reward modeling and mixture-of-experts. InFindings of the Associa- tion for Computational Linguistics: EMNLP 2024, pages 10582–10592, 2024
2024
-
[46]
Multi-objective alignment of large language models through hypervolume maximization
Subhojyoti Mukherjee, Anusha Lalitha, Sailik Sengupta, Aniket Deshmukh, and Branislav Kve- ton. Multi-objective alignment of large language models through hypervolume maximization. arXiv preprint arXiv:2412.05469, 2024. 12
-
[47]
Baijiong Lin, Weisen Jiang, Yuancheng Xu, Hao Chen, and Ying-Cong Chen. Parm: Multi- objective test-time alignment via preference-aware autoregressive reward model.arXiv preprint arXiv:2505.06274, 2025
-
[48]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[50]
Synthesizeme! inducing persona-guided prompts for personalized reward models in llms
Michael J Ryan, Omar Shaikh, Aditri Bhagirath, Daniel Frees, William Barr Held, and Diyi Yang. Synthesizeme! inducing persona-guided prompts for personalized reward models in llms. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8045–8078, 2025
2025
-
[51]
Measuring what makes you unique: Difference-aware user modeling for enhancing llm personalization
Yilun Qiu, Xiaoyan Zhao, Yang Zhang, Yimeng Bai, Wenjie Wang, Hong Cheng, Fuli Feng, and Tat-Seng Chua. Measuring what makes you unique: Difference-aware user modeling for enhancing llm personalization. InFindings of the Association for Computational Linguistics: ACL 2025, pages 21258–21277, 2025
2025
-
[52]
Fair recommendation with biased-limited sensitive attribute
Jizhi Zhang, Haoyu Shen, Tianhao Shi, Keqin Bao, Xin Chen, Yang Zhang, and Fuli Feng. Fair recommendation with biased-limited sensitive attribute. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1717– 1727, 2025
2025
-
[53]
Fair recommendations with limited sensitive attributes: A distributionally robust optimization approach
Tianhao Shi, Yang Zhang, Jizhi Zhang, Fuli Feng, and Xiangnan He. Fair recommendations with limited sensitive attributes: A distributionally robust optimization approach. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 448–457, 2024. A Case Study To more intuitively illustrate the ef...
2024
-
[54]
A clear understanding of their career goals and aspirations: Having clarity about the type of job, industry, company, and role they want to pursue will help individuals target their job search efforts and tailor their applications accordingly
-
[55]
Hence, it is important to invest time in crafting these documents
A professional and well-crafted resume/CV and cover letter: A well-prepared resume/CV and cover letter perfectly tailored to the job of interest can significantly increase the chances of getting shortlisted for an interview. Hence, it is important to invest time in crafting these documents
-
[56]
role": "user
Networking: While submitting online applications is an essential component of a job search, networking with industry professionals and building relationships with potential employers (through events, social media, etc.) can help individuals learn about job openings that may not be publicly advertised, and also get insider information about the company cul...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.