Voting Protocols as Coordination Mechanisms for Role-Constrained Multi-Agent Tutoring Systems
Pith reviewed 2026-06-27 19:10 UTC · model grok-4.3
The pith
Voting protocols among four role-constrained pedagogical agents determine which response is selected and produce distinct coordination patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
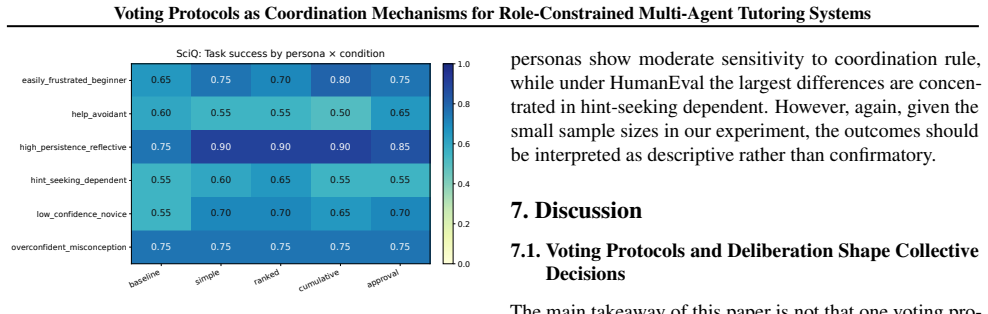
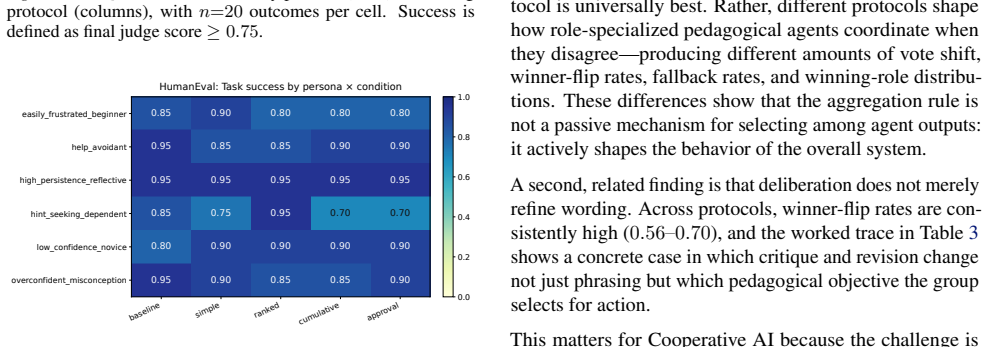
Across 1,200 simulated interactions, agent deliberation and voting protocol type frequently change which response ultimately wins, showing that both meaningfully shape the collective decision. Different voting rules also produce distinct coordination behaviors, and even brief tutoring turns show measurable learning gains in simulated students. Protocol choice is associated with distinct coordination patterns among role-specialized pedagogical agents.
What carries the argument
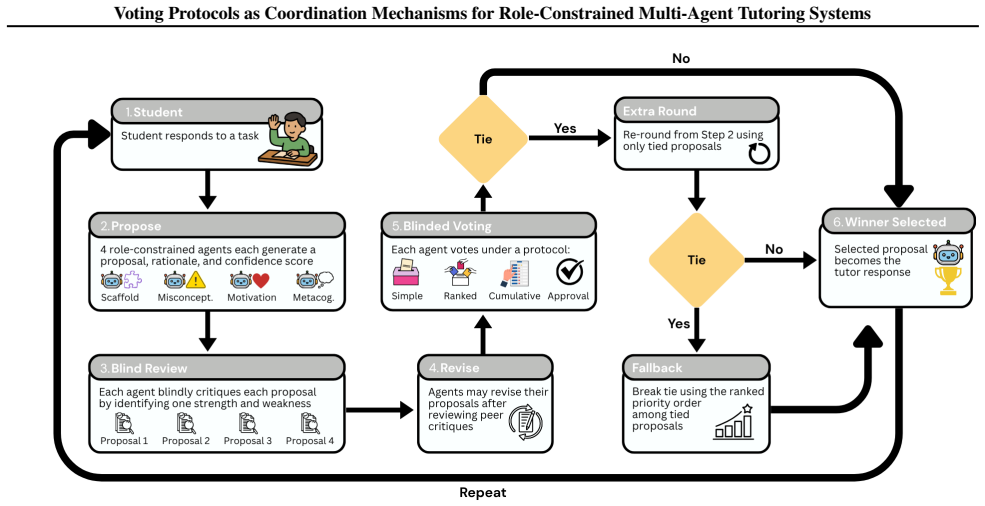
Four voting protocols (simple, ranked, cumulative, and approval) applied to resolve conflicts among four role-constrained pedagogical agents responsible for scaffolding, misconception correction, motivation, and metacognition.
If this is right
- Agent deliberation before voting alters the selected tutoring response.
- Each voting protocol generates its own pattern of coordination among the four roles.
- Measurable learning gains appear in simulated students after short tutoring sequences.
- Protocol selection influences how pedagogical conflict is resolved when multiple agents propose interventions.
Where Pith is reading between the lines
- Designers of multi-agent tutoring systems could tune the voting rule to favor particular coordination styles such as consensus or specialization.
- The same voting mechanisms might apply to other role-specialized agent teams outside education where only one action can be taken.
- Testing the protocols with human learners could reveal whether simulated coordination patterns hold when student responses are unpredictable.
- Protocol effects might vary with the difficulty or domain of the tutoring task beyond the two benchmarks examined.
Load-bearing premise
The simulated tutoring environments and role-constrained agent behaviors on SciQ and HumanEval benchmarks sufficiently capture the coordination challenge and pedagogical dynamics of real multi-agent tutoring systems.
What would settle it
A real multi-agent tutoring deployment in which switching between the four voting protocols produces no measurable change in which response is ultimately selected across repeated interactions.
Figures
read the original abstract
Agentic tutoring systems introduce a coordination challenge: multiple agents may propose different but reasonable interventions, yet only one response can be delivered to the learner. In this paper, we study how voting protocols shape cooperation among four role-constrained pedagogical agents responsible for scaffolding, misconception, motivation, and metacognition. We compare four voting protocols -- simple, ranked, cumulative, and approval voting -- across two simulated tutoring environments on SciQ and HumanEval benchmarks. Rather than using voting as a simple aggregation step, we use it to analyze how collective decision rules shape coordination under partial pedagogical conflict. Across 1,200 simulated interactions, we find that agent deliberation and voting protocol type frequently change which response ultimately wins, showing that both meaningfully shape the collective decision. Different voting rules also produce distinct coordination behaviors, and even brief tutoring turns show measurable learning gains in simulated students. Overall, we show that protocol choice is associated with distinct coordination patterns among role-specialized pedagogical agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that voting protocols serve as coordination mechanisms in multi-agent tutoring systems with four role-constrained agents (scaffolding, misconception correction, motivation, metacognition). Using simulations on SciQ and HumanEval benchmarks across 1,200 interactions, it reports that agent deliberation and protocol type (simple, ranked, cumulative, approval voting) frequently alter the winning response, produce distinct coordination behaviors, and yield measurable learning gains in simulated students.
Significance. If the simulation results hold under rigorous implementation details, the work could offer a concrete demonstration that voting rules are not neutral aggregators but active shapers of collective pedagogical decisions under role conflict. This would be relevant for multi-agent system design in education, provided the benchmarks are shown to capture the claimed dynamics.
major comments (2)
- [Abstract] Abstract: the central empirical claim rests on outcomes from 1,200 simulated interactions, yet the abstract (and by extension the reported results) supplies no details on agent implementation, proposal generation, vote-casting mechanics, statistical tests, or controls for confounding factors. This absence is load-bearing because it prevents verification that the reported changes in winning responses are attributable to deliberation and protocol type rather than artifacts of the simulation procedure.
- [Abstract] Simulation environments: the use of static, single-turn SciQ and HumanEval tasks without student state evolution, persistent errors, or multi-turn scaffolding dynamics is load-bearing for the claim that protocols shape 'pedagogical coordination.' If agent responses are generated independently or with synthetic conflict, the observed effects may not generalize to the interactive tutoring setting described in the introduction.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the two major comments below, clarifying the scope of our simulation study while acknowledging its limitations. We have revised the manuscript to improve transparency on methodological details and to explicitly discuss the single-turn design.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim rests on outcomes from 1,200 simulated interactions, yet the abstract (and by extension the reported results) supplies no details on agent implementation, proposal generation, vote-casting mechanics, statistical tests, or controls for confounding factors. This absence is load-bearing because it prevents verification that the reported changes in winning responses are attributable to deliberation and protocol type rather than artifacts of the simulation procedure.
Authors: The abstract is intentionally concise due to length constraints, but the full manuscript details agent role definitions and proposal generation from SciQ/HumanEval in Section 3, the four voting protocols and vote-casting rules in Section 4, chi-square and effect-size tests in Section 5, and controls including fixed seeds, independent proposal sampling, and synthetic conflict injection to isolate protocol effects. We will expand the abstract with one additional sentence summarizing the simulation controls and statistical approach. revision: partial
-
Referee: [Abstract] Simulation environments: the use of static, single-turn SciQ and HumanEval tasks without student state evolution, persistent errors, or multi-turn scaffolding dynamics is load-bearing for the claim that protocols shape 'pedagogical coordination.' If agent responses are generated independently or with synthetic conflict, the observed effects may not generalize to the interactive tutoring setting described in the introduction.
Authors: The single-turn static design isolates the impact of deliberation and voting rules on response selection under fixed role conflict, enabling direct attribution of coordination patterns to protocol choice rather than student-model dynamics. Proposals are generated independently per role with controlled synthetic disagreement. We agree this limits generalization to multi-turn tutoring and will add an explicit limitations paragraph plus future-work discussion on extending to persistent student states. revision: yes
Circularity Check
No circularity: empirical simulation results are independent of inputs
full rationale
The paper reports empirical outcomes from 1,200 simulated interactions comparing four voting protocols among role-constrained agents on SciQ and HumanEval benchmarks. Central claims (deliberation and protocol type changing winning responses, distinct coordination behaviors, measurable learning gains) are presented as direct observations from these runs rather than derived via equations, fitted parameters renamed as predictions, or self-citation chains. No load-bearing steps reduce by construction to the simulation setup itself; the derivation chain consists of running the described environments and tallying results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate , author=. arXiv preprint arXiv:2305.19118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Educational Researcher , volume=
The 2 sigma problem: The search for methods of group instruction as effective as one-to-one tutoring , author=. Educational Researcher , volume=
-
[3]
Puech, Romain and Macina, Jakub and Chatain, Julia and Sachan, Mrinmaya and Kapur, Manu. Towards the Pedagogical Steering of Large Language Models for Tutoring: A Case Study with Modeling Productive Failure. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1348
-
[4]
Voting or Consensus? Decision-Making in Multi-Agent Debate , url=
Kaesberg, Lars Benedikt and Becker, Jonas and Wahle, Jan Philip and Ruas, Terry and Gipp, Bela , year=. Voting or Consensus? Decision-Making in Multi-Agent Debate , url=. doi:10.18653/v1/2025.findings-acl.606 , booktitle=
-
[5]
2023 , eprint=
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation , author=. 2023 , eprint=
2023
-
[6]
2023 , eprint=
CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society , author=. 2023 , eprint=
2023
-
[7]
Educational Psychologist , volume =
KURT VanLEHN , title =. Educational Psychologist , volume =. 2011 , publisher =. doi:10.1080/00461520.2011.611369 , URL =
-
[8]
International Journal of Artificial Intelligence in Education , volume=
Implementation and use of Simulated Students for Test and Validation of new Adaptive Educational Systems: a Practical Insight , author=. International Journal of Artificial Intelligence in Education , volume=. 2015 , URL=
2015
-
[9]
International Conference on Artificial Intelligence in Education , pages=
Domain-general tutoring authoring with apprentice learner models , author=. International Conference on Artificial Intelligence in Education , pages=
-
[10]
Proceedings of the 3rd Workshop on Noisy User-generated Text , pages=
Crowdsourcing Multiple Choice Science Questions , author=. Proceedings of the 3rd Workshop on Noisy User-generated Text , pages=
-
[11]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[12]
Open Problems in Cooperative
Dafoe, Allan and Hughes, Edward and Bachrach, Yoram and Collins, Tantum and McKee, Kevin R and Leibo, Joel Z and Larson, Kate and Graepel, Thore , year=. Open Problems in Cooperative
-
[13]
Jin, Hyoungwook and Yoo, Minju and Park, Jeongeon and Lee, Yokyung and Wang, Xu and Kim, Juho , title =. 2025 , isbn =. doi:10.1145/3706598.3714054 , booktitle =
-
[14]
Park, Joon Sung and O'Brien, Joseph and Cai, Carrie Jun and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S. , title =. 2023 , isbn =. doi:10.1145/3586183.3606763 , articleno =
-
[15]
2023 , eprint=
Improving Factuality and Reasoning in Language Models through Multiagent Debate , author=. 2023 , eprint=
2023
-
[16]
2025 , eprint=
Embracing Imperfection: Simulating Students with Diverse Cognitive Levels Using LLM-based Agents , author=. 2025 , eprint=
2025
-
[17]
A Transparency Index Framework for AI in Education
Chaudhry, Muhammad Ali and Cukurova, Mutlu and Luckin, Rose. A Transparency Index Framework for AI in Education. Artificial Intelligence in Education. Posters and Late Breaking Results, Workshops and Tutorials, Industry and Innovation Tracks, Practitioners' and Doctoral Consortium. 2022
2022
-
[18]
Trustworthy artificial intelligence: a review
Kaur, Davinder and Uslu, Suleyman and Rittichier, Kaley J. and Durresi, Arjan , title =. 2022 , issue_date =. doi:10.1145/3491209 , journal =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.