Variational Proximal Policy Optimization
Pith reviewed 2026-06-27 19:20 UTC · model grok-4.3
The pith
A particle-based variational framework maps policy optimization to Stein variational gradients inside Mixture-of-Experts models to supply geometry-based proximal control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VP₂O frames policy optimization as particle-based variational inference solved by Stein Variational Gradient Descent in a Mixture-of-Experts architecture. Functional kernels over localized expert prototypes and an expert orthogonalization loss supply a geometry-based proximal-control mechanism. This mechanism is designed to reduce reliance on fixed clipping or KL schedules while preserving training stability. On a 33B/4B sparse Mixture-of-Experts model the method yields gains across complex reasoning benchmarks, including a +179 ELO gain on Codeforces and a 32 percent reduction in token count on AIME mathematical reasoning tasks.
What carries the argument
Variational Proximal Policy Optimization (VP₂O) as a mapping of policy optimization to Stein Variational Gradient Descent within a Mixture-of-Experts architecture, using functional kernels over expert prototypes together with an expert orthogonalization loss to enforce geometry-based proximal control.
If this is right
- Policy optimization becomes less sensitive to the precise values of clipping thresholds or KL coefficients.
- Large Mixture-of-Experts models trained for reasoning achieve both higher benchmark scores and lower token usage.
- Stability is maintained through geometry-based constraints rather than through explicit proximal penalties.
- The same particle-based variational approach produces measurable lifts on both competitive programming and mathematical reasoning tasks.
Where Pith is reading between the lines
- The same kernels and orthogonalization step could be tested on policy optimization methods other than PPO.
- The geometry-based control might reduce the amount of hyperparameter search needed when scaling to larger expert counts.
- If the mechanism generalizes, it could be applied to non-reasoning domains where mode collapse is also observed.
Load-bearing premise
The geometry-based proximal-control mechanism supplied by functional kernels and expert orthogonalization actually reduces reliance on fixed clipping or KL schedules while preserving stability.
What would settle it
An ablation experiment on the same 33B/4B model and benchmarks in which the functional kernels and expert orthogonalization loss are removed, followed by measurement of whether the reported ELO gain and token reduction disappear or whether training instability increases.
Figures
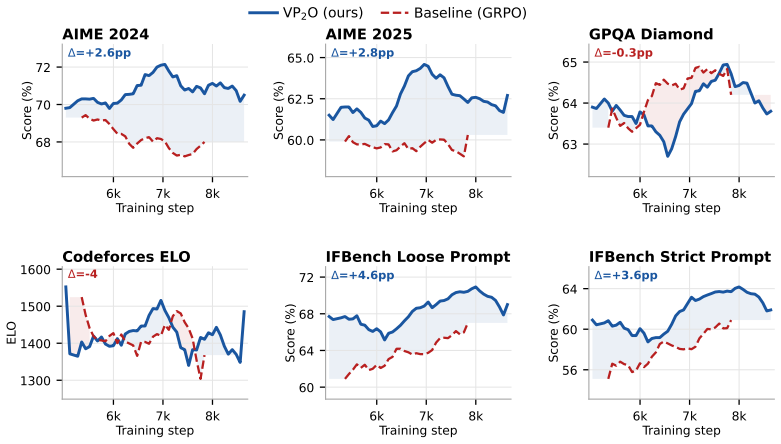
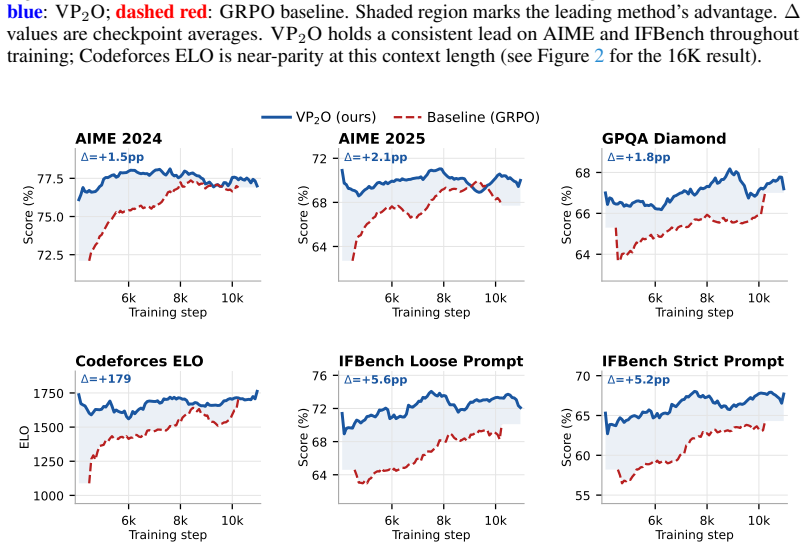
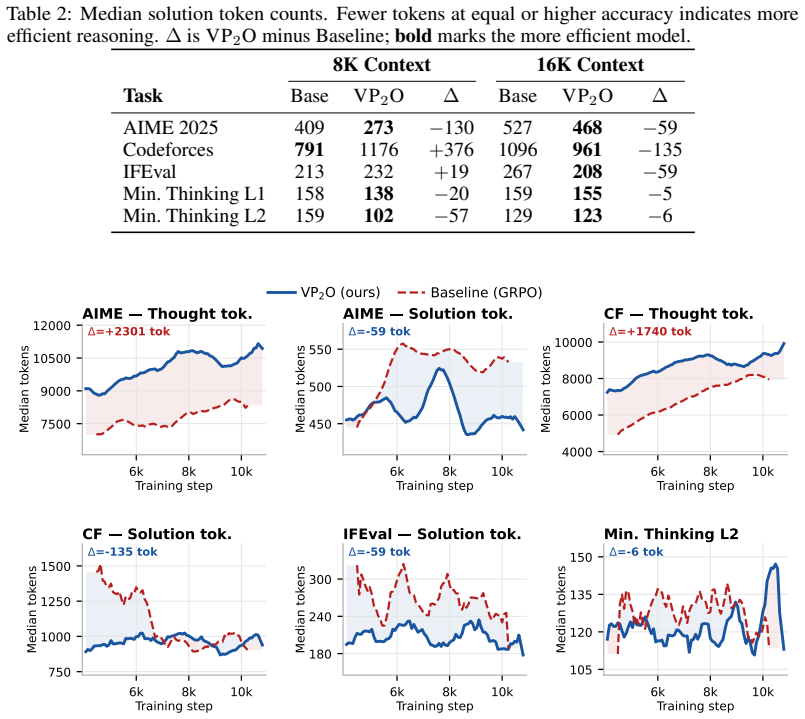
read the original abstract
Reinforcement Learning from Human Feedback via Proximal Policy Optimization often suffers from policy mode collapse, brittle exploration loops, and distribution drift. This paper introduces Variational Proximal Policy Optimization (\(\textsc{VP}_2\textsc{O}\)), a particle-based variational inference framework that maps policy optimization to Stein Variational Gradient Descent within a Mixture-of-Experts architecture. By leveraging functional kernels over localized expert prototypes alongside an expert orthogonalization loss, \(\textsc{VP}_2\textsc{O}\) introduces a geometry-based proximal-control mechanism that can reduce reliance on fixed clipping or KL schedules. Our results on a 33B/4B sparse Mixture-of-Experts model show several improvements across complex reasoning benchmarks, establishing a \(+\mathbf{179}\) ELO gain on Codeforces and a \(\mathbf{32\%}\) reduction in token count on AIME mathematical reasoning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Variational Proximal Policy Optimization (VP₂O), a particle-based variational inference framework that reformulates PPO-style policy optimization as Stein Variational Gradient Descent inside a Mixture-of-Experts architecture. Functional kernels defined over localized expert prototypes together with an expert orthogonalization loss are claimed to supply a geometry-based proximal-control mechanism that can reduce reliance on fixed clipping ratios or KL penalties. On a 33B/4B sparse MoE model the method is reported to deliver a +179 ELO gain on Codeforces and a 32% reduction in token count on AIME mathematical-reasoning tasks.
Significance. If the geometry-based proximal mechanism were shown to substitute for or relax clipping/KL schedules while preserving stability, the work would supply a principled alternative to standard PPO for RLHF on large sparse models and could improve exploration and reduce mode collapse. The reported benchmark deltas are large enough to be practically interesting, but the absence of any derivation, ablation, or statistical protocol prevents the result from being evaluated at present.
major comments (2)
- [Abstract] Abstract, paragraph describing the framework: the central claim that functional kernels over expert prototypes plus expert orthogonalization supply a geometry-based proximal-control mechanism that 'can reduce reliance on fixed clipping or KL schedules' is unsupported; no comparison of clipping ratios, KL coefficients, or stability metrics (e.g., policy entropy, gradient norms) between VP₂O and baseline PPO is provided, nor any ablation isolating the kernels/orthogonalization as the source of any observed stability.
- [Abstract] Abstract, results paragraph: the reported +179 ELO gain on Codeforces and 32% token reduction on AIME rest on a single 33B/4B sparse MoE experiment whose baseline implementation, hyperparameter schedule, data-selection procedure, number of runs, and variance are not described; without these details the attribution of gains to the proposed proximal mechanism cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical grounding of our claims. We address each major comment below and will revise the manuscript to incorporate additional details, ablations, and clarifications where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph describing the framework: the central claim that functional kernels over expert prototypes plus expert orthogonalization supply a geometry-based proximal-control mechanism that 'can reduce reliance on fixed clipping or KL schedules' is unsupported; no comparison of clipping ratios, KL coefficients, or stability metrics (e.g., policy entropy, gradient norms) between VP₂O and baseline PPO is provided, nor any ablation isolating the kernels/orthogonalization as the source of any observed stability.
Authors: We acknowledge that the abstract presents the geometry-based proximal mechanism as a central contribution without accompanying empirical comparisons or ablations. The full manuscript contains a theoretical derivation mapping the functional kernels and orthogonalization loss to a proximal operator within the SVGD framework, but we agree this does not substitute for direct evidence. In revision we will add ablations that isolate the kernels and orthogonalization (by removing each component) together with side-by-side plots of policy entropy, gradient norms, and performance under matched versus relaxed clipping/KL schedules. revision: yes
-
Referee: [Abstract] Abstract, results paragraph: the reported +179 ELO gain on Codeforces and 32% token reduction on AIME rest on a single 33B/4B sparse MoE experiment whose baseline implementation, hyperparameter schedule, data-selection procedure, number of runs, and variance are not described; without these details the attribution of gains to the proposed proximal mechanism cannot be assessed.
Authors: The reported numbers come from a single training run of the 33B/4B model, which was the only feasible scale given compute limits. We will expand the experimental section to document the exact baseline PPO implementation, hyperparameter schedules, data-selection pipeline, and training protocol. We will also state explicitly that variance across independent seeds was not measured and treat this as a limitation of the current evaluation. revision: partial
Circularity Check
No circularity detected; abstract contains no equations or derivation chain
full rationale
The abstract and description introduce VP₂O as mapping PPO to SVGD in MoE with functional kernels and orthogonalization loss for proximal control, claiming benchmark gains. No equations, fitting procedures, self-citations, or 'predictions' of derived quantities are present. The central claim that the mechanism 'can reduce reliance' on clipping/KL is stated as a possibility without reduction to inputs by construction. No load-bearing steps reduce to self-definition or fitted inputs. This is the expected non-finding when no derivation chain is supplied.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
IEEE transactions on medical imaging , volume=
Uncertainty driven probabilistic voxel selection for image registration , author=. IEEE transactions on medical imaging , volume=. 2013 , publisher=
2013
-
[5]
2026 , eprint=
Reinforcement Learning via Self-Distillation , author=. 2026 , eprint=
2026
-
[6]
2026 , eprint=
Advancing Expert Specialization for Better MoE , author=. 2026 , eprint=
2026
-
[7]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
OpenThoughts: Data Recipes for Reasoning Models , author=. 2025 , eprint=
2025
-
[9]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[10]
2025 , eprint=
Group Sequence Policy Optimization , author=. 2025 , eprint=
2025
-
[11]
2025 , eprint=
Turning Up the Heat: Min-p Sampling for Creative and Coherent LLM Outputs , author=. 2025 , eprint=
2025
-
[12]
Structured Pruning of Neural Networks with Budget-Aware Regularization , journal =
Carl Lemaire and Andrew Achkar and Pierre. Structured Pruning of Neural Networks with Budget-Aware Regularization , journal =. 2018 , url =
2018
-
[13]
2023 , eprint=
Object-Centric Slot Diffusion , author=. 2023 , eprint=
2023
-
[14]
2017 , eprint=
Stein Variational Policy Gradient , author=. 2017 , eprint=
2017
-
[15]
2023 , eprint=
How to Exploit Hyperspherical Embeddings for Out-of-Distribution Detection? , author=. 2023 , eprint=
2023
-
[16]
2024 , eprint=
Conditional Vendi Score: An Information-Theoretic Approach to Diversity Evaluation of Prompt-based Generative Models , author=. 2024 , eprint=
2024
-
[17]
2025 , eprint=
No Prompt Left Behind: Exploiting Zero-Variance Prompts in LLM Reinforcement Learning via Entropy-Guided Advantage Shaping , author=. 2025 , eprint=
2025
-
[18]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[19]
2017 , eprint=
Trust Region Policy Optimization , author=. 2017 , eprint=
2017
-
[20]
2016 , eprint=
Asynchronous Methods for Deep Reinforcement Learning , author=. 2016 , eprint=
2016
-
[21]
2025 , eprint=
Act Only When It Pays: Efficient Reinforcement Learning for LLM Reasoning via Selective Rollouts , author=. 2025 , eprint=
2025
-
[22]
2018 , eprint=
High-Dimensional Continuous Control Using Generalized Advantage Estimation , author=. 2018 , eprint=
2018
-
[23]
Top- n : Eliminating Noise in Logit Space for Robust Token Sampling of LLM
Tang, Chenxia and Liu, Jianchun and Xu, Hongli and Huang, Liusheng. Top- n : Eliminating Noise in Logit Space for Robust Token Sampling of LLM. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.528
-
[24]
2023 , eprint=
The Vendi Score: A Diversity Evaluation Metric for Machine Learning , author=. 2023 , eprint=
2023
-
[25]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[26]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Gao, Leo and Schulman, John and Hilton, Jacob , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[27]
2016 , eprint=
Concrete Problems in AI Safety , author=. 2016 , eprint=
2016
-
[28]
2024 , eprint=
Secrets of RLHF in Large Language Models Part II: Reward Modeling , author=. 2024 , eprint=
2024
-
[29]
2023 , eprint=
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback , author=. 2023 , eprint=
2023
-
[30]
2021 , eprint=
Variational Bayesian Optimistic Sampling , author=. 2021 , eprint=
2021
-
[31]
Sixteenth European Workshop on Reinforcement Learning , year=
Overcoming Policy Collapse in Deep Reinforcement Learning , author=. Sixteenth European Workshop on Reinforcement Learning , year=
-
[32]
Proceedings of the 30th International Conference on Neural Information Processing Systems , pages =
Liu, Qiang and Wang, Dilin , title =. Proceedings of the 30th International Conference on Neural Information Processing Systems , pages =. 2016 , isbn =
2016
-
[33]
Advances in Neural Information Processing Systems , volume =
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[34]
, booktitle =
Korbak, Tomasz and Perez, Ethan and Buckley, Christopher L. , booktitle =. 2022 , url =
2022
-
[35]
Advancing Expert Specialization for Better
Guo, Hongcan and Lu, Haolang and Nan, Guoshun and Chu, Bolun and Zhuang, Jialin and Yang, Yuan and Che, Wenhao and Cao, Xinye and Leng, Sicong and Cui, Qimei and Jiang, Xudong , journal =. Advancing Expert Specialization for Better. 2025 , url =
2025
-
[36]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Weighted importance sampling for off-policy learning with linear function approximation , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2014 , publisher =
2014
-
[37]
2023 , eprint=
Click: Controllable Text Generation with Sequence Likelihood Contrastive Learning , author=. 2023 , eprint=
2023
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
High-Confidence Off-Policy Evaluation , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2015 , doi =
2015
-
[39]
2024 , eprint=
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs , author=. 2024 , eprint=
2024
-
[40]
2024 , eprint=
From r to Q^* : Your Language Model is Secretly a Q-Function , author=. 2024 , eprint=
2024
-
[41]
2024 , eprint=
Slot State Space Models , author=. 2024 , eprint=
2024
-
[42]
2022 , eprint=
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author=. 2022 , eprint=
2022
-
[43]
Francesco Locatello and Dirk Weissenborn and Thomas Unterthiner and Aravindh Mahendran and Georg Heigold and Jakob Uszkoreit and Alexey Dosovitskiy and Thomas Kipf , title =. CoRR , volume =. 2020 , url =. 2006.15055 , timestamp =
arXiv 2020
-
[44]
Jonathan Ho and Ajay Jain and Pieter Abbeel , title =. CoRR , volume =. 2020 , url =. 2006.11239 , timestamp =
Pith/arXiv arXiv 2020
-
[45]
2022 , eprint=
Object Scene Representation Transformer , author=. 2022 , eprint=
2022
-
[46]
Multi-Object Representation Learning with Iterative Variational Inference , journal =
Klaus Greff and Rapha. Multi-Object Representation Learning with Iterative Variational Inference , journal =. 2019 , url =. 1903.00450 , timestamp =
arXiv 2019
-
[47]
Shaolei Zhang and Yang Feng , title =. CoRR , volume =. 2021 , url =. 2109.05244 , timestamp =
arXiv 2021
-
[48]
Christopher P. Burgess and Lo. MONet: Unsupervised Scene Decomposition and Representation , journal =. 2019 , url =. 1901.11390 , timestamp =
Pith/arXiv arXiv 2019
-
[49]
2022 , eprint=
Illiterate DALL-E Learns to Compose , author=. 2022 , eprint=
2022
-
[50]
Olaf Ronneberger and Philipp Fischer and Thomas Brox , title =. CoRR , volume =. 2015 , url =. 1505.04597 , timestamp =
Pith/arXiv arXiv 2015
-
[51]
2022 , eprint=
VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance , author=. 2022 , eprint=
2022
-
[52]
Taming Transformers for High-Resolution Image Synthesis , journal =
Patrick Esser and Robin Rombach and Bj. Taming Transformers for High-Resolution Image Synthesis , journal =. 2020 , url =. 2012.09841 , timestamp =
arXiv 2020
-
[53]
High-Resolution Image Synthesis with Latent Diffusion Models , journal =
Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Bj. High-Resolution Image Synthesis with Latent Diffusion Models , journal =. 2021 , url =. 2112.10752 , timestamp =
Pith/arXiv arXiv 2021
-
[54]
Gautam Singh and Fei Deng and Sungjin Ahn , title =. CoRR , volume =. 2021 , url =. 2110.11405 , timestamp =
arXiv 2021
-
[55]
2023 , eprint=
Neural Systematic Binder , author=. 2023 , eprint=
2023
-
[56]
Najmeh Abiri and Mattias Ohlsson , title =. CoRR , volume =. 2020 , url =. 2004.02581 , timestamp =
arXiv 2020
-
[57]
Prafulla Dhariwal and Alex Nichol , title =. CoRR , volume =. 2021 , url =. 2105.05233 , timestamp =
Pith/arXiv arXiv 2021
-
[58]
Ehsan Jahangiri and Erdem Y. Information Pursuit:. CoRR , volume =. 2017 , url =. 1701.02343 , timestamp =
Pith/arXiv arXiv 2017
-
[59]
2023 , eprint=
Variational Information Pursuit for Interpretable Predictions , author=. 2023 , eprint=
2023
-
[60]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Energy-based Out-of-distribution Detection , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[61]
2023 , eprint=
Beyond Reverse KL: Generalizing Direct Preference Optimization with Diverse Divergence Constraints , author=. 2023 , eprint=
2023
-
[62]
Pang Wei Koh and Thao Nguyen and Yew Siang Tang and Stephen Mussmann and Emma Pierson and Been Kim and Percy Liang , title =. CoRR , volume =. 2020 , url =. 2007.04612 , timestamp =
arXiv 2020
-
[63]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
Simonyan, Karen and Vedaldi, Andrea and Zisserman, Andrew , keywords =. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps , publisher =. 2013 , copyright =. doi:10.48550/ARXIV.1312.6034 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1312.6034 2013
-
[64]
Aditya Chattopadhyay and Piyushi Manupriya and Anirban Sarkar and Vineeth N. Balasubramanian , title =. CoRR , volume =. 2019 , url =. 1902.02302 , timestamp =
Pith/arXiv arXiv 2019
-
[65]
Marco T. "Why Should. CoRR , volume =. 2016 , url =. 1602.04938 , timestamp =
Pith/arXiv arXiv 2016
-
[66]
Ramprasaath R. Selvaraju and Abhishek Das and Ramakrishna Vedantam and Michael Cogswell and Devi Parikh and Dhruv Batra , title =. CoRR , volume =. 2016 , url =. 1610.02391 , timestamp =
arXiv 2016
-
[67]
Goodfellow and Moritz Hardt and Been Kim , title =
Julius Adebayo and Justin Gilmer and Michael Muelly and Ian J. Goodfellow and Moritz Hardt and Been Kim , title =. CoRR , volume =. 2018 , url =. 1810.03292 , timestamp =
arXiv 2018
-
[68]
Tom Zahavy and Shie Mannor , title =. CoRR , volume =. 2019 , url =. 1901.08612 , timestamp =
arXiv 2019
-
[69]
The Exp3-IX Algorithm , DOI=
Lattimore, Tor and Szepesvári, Csaba , year=. The Exp3-IX Algorithm , DOI=. Bandit Algorithms , publisher=
-
[70]
Aadirupa Saha and Pierre Gaillard and Michal Valko , title =. CoRR , volume =. 2020 , url =. 2004.06248 , timestamp =
arXiv 2020
-
[71]
Zhang and Michael Ruan and Eric Wang and So Hasegawa and Jimmy Ba and Roger Baker Grosse , booktitle=
Juhan Bae and Michael R. Zhang and Michael Ruan and Eric Wang and So Hasegawa and Jimmy Ba and Roger Baker Grosse , booktitle=. Multi-Rate. 2023 , url=
2023
-
[72]
Rudin, Cynthia , biburl =. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead , url =. Nature Machine Intelligence , keywords =. doi:10.1038/s42256-019-0048-x , interhash =
-
[73]
Haeffele and Rene Vidal and Donald Geman , title =
Aditya Chattopadhyay and Stewart Slocum and Benjamin D. Haeffele and Rene Vidal and Donald Geman , title =. doi:10.1109/tpami.2022.3225162 , url =
-
[74]
Improved Algorithms for Linear Stochastic Bandits , url =
Abbasi-yadkori, Yasin and P\'. Improved Algorithms for Linear Stochastic Bandits , url =. Advances in Neural Information Processing Systems , editor =
-
[75]
Supervised Topic Models , url =
Mcauliffe, Jon and Blei, David , booktitle =. Supervised Topic Models , url =
-
[76]
and Ng, Andrew Y
Blei, David M. and Ng, Andrew Y. and Jordan, Michael I. , title =. J. Mach. Learn. Res. , month =. 2003 , issue_date =
2003
-
[77]
Primary biliary cirrhosis: prediction of short-term survival based on repeated patient visits , Author =. 1994 , Journal =. doi:10.1016/0270-9139(94)90144-9 , Number =
-
[78]
Peter S. Fader and Bruce G.S. Hardie , abstract =. How to project customer retention , journal =. 2007 , issn =. doi:https://doi.org/10.1002/dir.20074 , url =
-
[79]
Survival and event history analysis: A process point of view , author=
-
[80]
Kalbfleisch, J. D. and Prentice, R. L. , biburl =. The
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.