DyCo-RL: Dynamic Cross-Modal Coordination for Visual Reasoning
Pith reviewed 2026-06-27 20:06 UTC · model grok-4.3
The pith
DyCo-RL improves RLVR by reweighting advantages using each token's alignment between actual attention and its assigned visual or text role.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
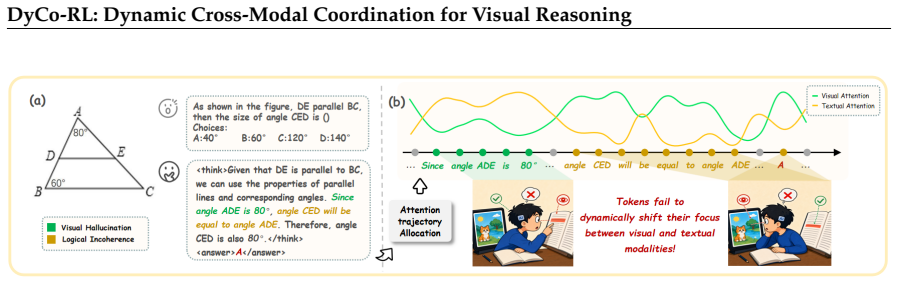
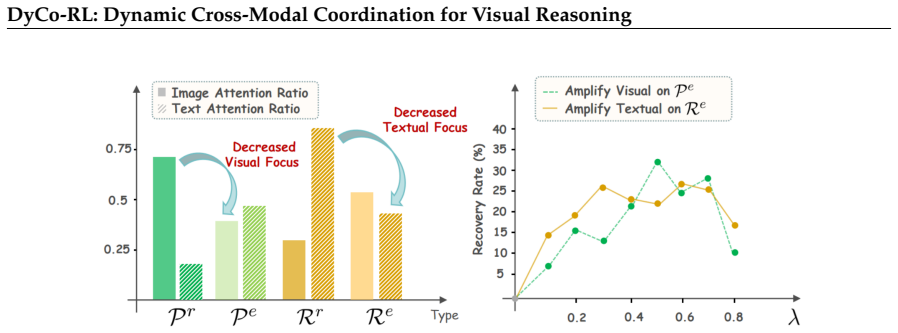
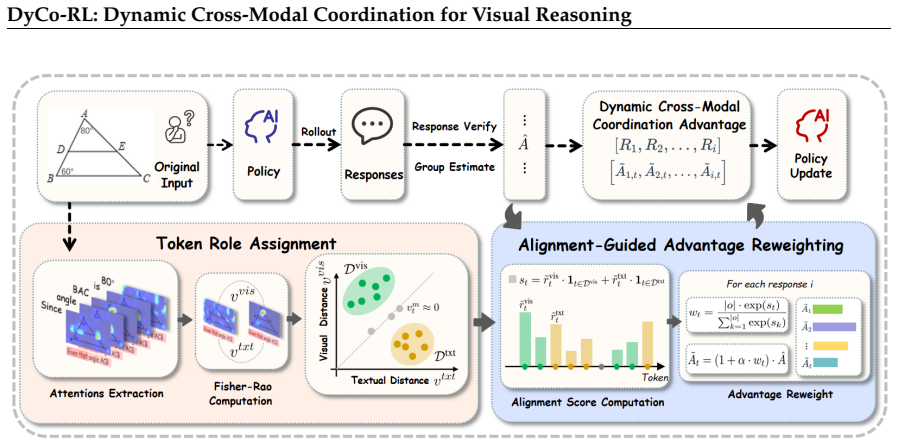
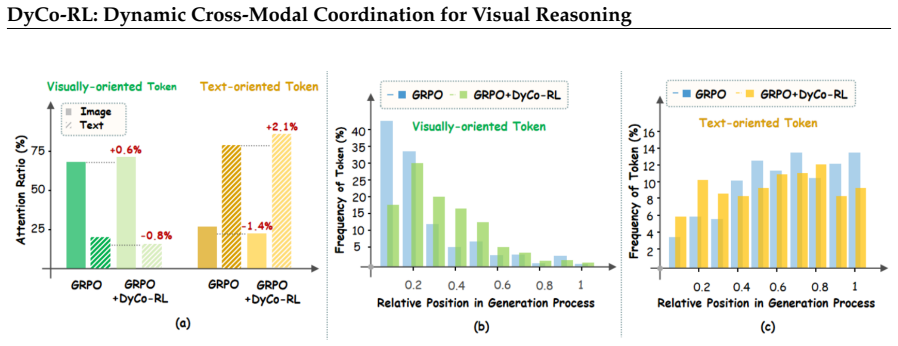
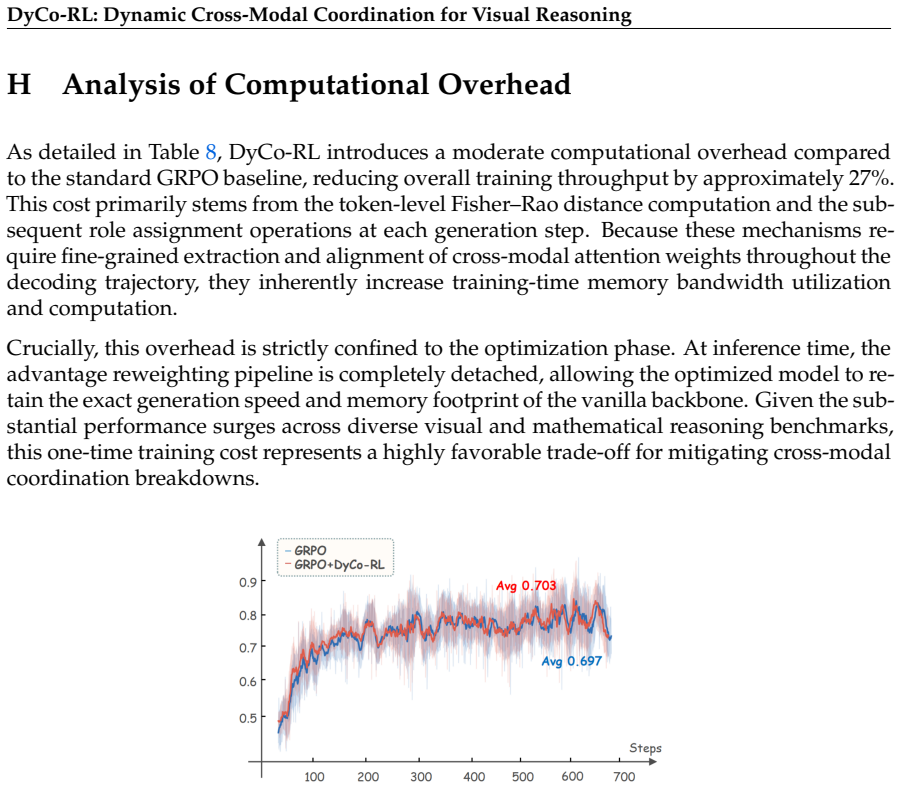
During CoT generation, MLLMs exhibit coordination failures where tokens do not match their functional roles in visual evidence extraction versus textual synthesis; DyCo-RL quantifies these failures with Fisher-Rao geodesic distance on attention shifts, assigns roles, computes alignment scores, and applies those scores to reweight advantages in the RLVR policy gradient, yielding consistent gains when plugged into existing algorithms.
What carries the argument
Alignment-guided advantage reweighting that uses Fisher-Rao geodesic distance to assign tokens to visually-oriented or text-oriented roles and score how well each token's attention matches its role.
If this is right
- The same DyCo-RL wrapper raises accuracy for four different RLVR algorithms on seven benchmarks covering visual-centric and mathematical reasoning.
- Gains appear for both the 3B and 7B versions of Qwen2.5-VL without architecture changes.
- The method remains algorithm-agnostic, so any future RLVR variant can adopt the reweighting step directly.
- Token-level role assignment derived from attention shifts provides a diagnostic that correlates with downstream reasoning failures.
Where Pith is reading between the lines
- The same attention-shift measurement could be tested as a training-free diagnostic to predict which prompts will cause coordination breakdowns before running RLVR.
- If the reweighting signal proves robust, it might transfer to supervised fine-tuning loops that lack explicit advantage estimates.
- Extending the role-assignment logic beyond vision and text to additional modalities would require only redefining the within-modality shift metric.
Load-bearing premise
The alignment score between a token's attention allocation and its assigned visual or text role supplies a causally useful signal that improves reasoning accuracy when used for advantage reweighting.
What would settle it
Training the same base RLVR runs with the alignment scores replaced by random numbers of equal magnitude and variance, then checking whether accuracy gains disappear or reverse.
Figures


read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a leading paradigm for enhancing visual reasoning in Multimodal Large Language Models (MLLMs). However, existing RLVR methods optimize primarily for the reasoning outcome, fundamentally overlooking the fine-grained cross-modal coordination required during the generation process. Through token-level analyses and controlled interventions, we reveal that during Chain-of-Thought (CoT) reasoning, MLLMs frequently fail to dynamically alternate between extracting visual evidence and synthesizing textual context-a coordination breakdown that is causally linked to reasoning failures. Motivated by these findings, we propose DyCo-RL, which integrates dynamic cross-modal coordination into RLVR optimization. Specifically, DyCo-RL uses the Fisher-Rao geodesic distance to measure within-modality attention shifts, assigning tokens to either visually-oriented or text-oriented functional roles. It then evaluates the alignment between a token's actual attention allocation and its assigned role, leveraging this score for alignment-guided advantage reweighting during policy optimization. Extensive experiments demonstrate that the algorithm-agnostic DyCo-RL, when applied to Qwen2.5-VL-3B/7B, consistently improves four representative RLVR algorithms across seven benchmarks spanning visual-centric and mathematical reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that token-level analyses reveal coordination breakdowns between visual evidence extraction and textual synthesis during CoT reasoning in MLLMs, which are causally linked to failures; it proposes DyCo-RL to address this by using Fisher-Rao geodesic distance on within-modality attention shifts to assign visual/text roles to tokens, computing an alignment score between actual attention and assigned role, and applying this for alignment-guided advantage reweighting in RLVR. The method is presented as algorithm-agnostic and is claimed to yield consistent gains when applied to Qwen2.5-VL-3B/7B with four RLVR algorithms across seven visual-centric and mathematical reasoning benchmarks.
Significance. If the central empirical claim holds with proper isolation of the alignment score's causal contribution, the work could meaningfully advance RLVR for MLLMs by shifting focus from outcome-only optimization to process-level cross-modal coordination. The algorithm-agnostic framing and use of a standard geometric distance metric are positive features that could facilitate adoption if the gains are shown to be robust and attributable to the proposed signal.
major comments (2)
- [Abstract] Abstract: the claim that token-level analyses link coordination breakdown to failures and that DyCo-RL yields consistent gains provides no quantitative details on effect sizes, error bars, ablation controls, or the exact reweighting formula, leaving the central empirical claim under-supported.
- [Experiments] The experiments section (presumably §4) reports improvements on four RLVR algorithms but does not isolate whether the Fisher-Rao alignment score (versus other pipeline modifications) is the causal driver of accuracy gains; without such controls the reweighting step could be incidental rather than the source of the reported benefits.
minor comments (2)
- [Methods] Provide the precise mathematical definition of the alignment score and the advantage reweighting formula, including any hyperparameters, in the methods section.
- Clarify whether the role-assignment and alignment computation introduce any data-dependent fitting that could affect the interpretation of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that token-level analyses link coordination breakdown to failures and that DyCo-RL yields consistent gains provides no quantitative details on effect sizes, error bars, ablation controls, or the exact reweighting formula, leaving the central empirical claim under-supported.
Authors: We agree that the abstract is highly condensed and omits specific quantitative details. In the revised version we will expand the abstract to report average accuracy gains across the seven benchmarks, note the presence of error bars in the main results, and include a concise statement of the alignment-guided reweighting formula. Full numerical results, error bars, ablation tables, and the exact formula already appear in Sections 3 and 4; the abstract revision will simply surface the key numbers without exceeding length limits. revision: yes
-
Referee: [Experiments] The experiments section (presumably §4) reports improvements on four RLVR algorithms but does not isolate whether the Fisher-Rao alignment score (versus other pipeline modifications) is the causal driver of accuracy gains; without such controls the reweighting step could be incidental rather than the source of the reported benefits.
Authors: The current manuscript already contains controlled interventions that compare full DyCo-RL against the base RLVR algorithms and against variants that remove or randomize the alignment score; these results are presented in Section 4.3. Nevertheless, to make the isolation more explicit we will add a dedicated ablation table that directly substitutes the Fisher-Rao alignment score with alternative reweighting signals while keeping all other pipeline components fixed. This will strengthen the causal attribution in the revision. revision: partial
Circularity Check
No circularity: method uses external geometric distance on attention without reducing to fitted evaluation metrics
full rationale
The abstract describes computing Fisher-Rao geodesic distance on within-modality attention shifts to assign visual/text roles, then using the resulting alignment score for advantage reweighting. This construction relies on standard differential geometry and attention statistics rather than defining the score or reweighting in terms of the downstream accuracy that is later measured on the seven benchmarks. No equations or steps are shown that equate the coordination signal to the RLVR performance gains by construction, and the reader's assessment confirms the distance metric and role assignment are drawn from independent mathematics. The empirical improvements are therefore not forced by the input data used for evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention sinks and compression valleys in llms are two sides of the same coin, 2026
Enrique Queipo de Llano, Álvaro Arroyo, Federico Barbero, Xiaowen Dong, Michael Bronstein, Yann Le- Cun, and Ravid Shwartz-Ziv. Attention sinks and compression valleys in llms are two sides of the same coin, 2026. URLhttps://arxiv.org/abs/2510.06477
-
[2]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality mod- els
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality mod- els. InProceedings of the 32nd ACM International Conference on Multimedia, pages 11198–11201, 2024
2024
-
[3]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Soft Adaptive Policy Optimization
Chang Gao, Chujie Zheng, Xiong-Hui Chen, Kai Dang, Shixuan Liu, Bowen Yu, An Yang, Shuai Bai, Jingren Zhou, and Junyang Lin. Soft adaptive policy optimization, 2025. URLhttps://arxiv.org/abs/2511.20347
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InProceed- ings of the IEEE/CVF Conference on Computer Vision ...
2024
-
[6]
Martin, Ming-Ming Cheng, and Shi-Min Hu
Meng-Hao Guo, Tian-Xing Xu, Jiang-Jiang Liu, Zheng-Ning Liu, Peng-Tao Jiang, Tai-Jiang Mu, Song-Hai Zhang, Ralph R. Martin, Ming-Ming Cheng, and Shi-Min Hu. Attention mechanisms in computer vision: A survey.Computational Visual Media, 8(3):331–368, 2022. doi: 10.1007/s41095-022-0271-y
-
[7]
Visual attention methods in deep learning: An in-depth survey.Information Fusion, 108:102417, 2024
Mohammed Hassanin, Saeed Anwar, Ibrahim Radwan, Fahad Shahbaz Khan, and Ajmal Mian. Visual attention methods in deep learning: An in-depth survey.Information Fusion, 108:102417, 2024. ISSN 1566-
2024
-
[8]
URLhttps://www.sciencedirect.com/science/ article/pii/S1566253524001957
doi: https://doi.org/10.1016/j.inffus.2024.102417. URLhttps://www.sciencedirect.com/science/ article/pii/S1566253524001957
-
[9]
Interpretable visual reasoning: A survey.Image and Vision Computing, 112:104194, 2021
Feijuan He, Yaxian Wang, Xianglin Miao, and Xia Sun. Interpretable visual reasoning: A survey.Image and Vision Computing, 112:104194, 2021. ISSN 0262-8856. doi: https://doi.org/10.1016/j.imavis.2021.104194. URLhttps://www.sciencedirect.com/science/article/pii/S0262885621000998
-
[10]
Distill visual chart reasoning ability from llms to mllms
Wei He, Zhiheng Xi, Wanxu Zhao, Xiaoran Fan, Yiwen Ding, Zifei Shan, Tao Gui, Qi Zhang, and Xuan- Jing Huang. Distill visual chart reasoning ability from llms to mllms. InFindings of the Association for Computational Linguistics: EMNLP 2025, 2025. 13 DyCo-RL: Dynamic Cross-Modal Coordination for Visual Reasoning
2025
-
[11]
Siyuan Huang, Xiaoye Qu, Yafu Li, Yun Luo, Zefeng He, Daizong Liu, and Yu Cheng. Spotlight on token perception for multimodal reinforcement learning.arXiv preprint arXiv:2510.09285, 2025
-
[12]
Zhengbo Jiao, Shaobo Wang, Zifan Zhang, Wei Wang, Bing Zhao, Hu Wei, and Linfeng Zhang. Credit where it is due: Cross-modality connectivity drives precise reinforcement learning for mllm reasoning, 2026. URL https://arxiv.org/abs/2602.11455
-
[13]
Explain before you answer: A survey on compositional visual reasoning, 2025
Fucai Ke, Joy Hsu, Zhixi Cai, Zixian Ma, Xin Zheng, Xindi Wu, Sukai Huang, Weiqing Wang, Pari Delir Haghighi, Gholamreza Haffari, Ranjay Krishna, Jiajun Wu, and Hamid Rezatofighi. Explain before you answer: A survey on compositional visual reasoning, 2025. URLhttps://arxiv.org/abs/2508.17298
-
[14]
Weijie Li, Jin Wang, Liang-Chih Yu, and Xuejie Zhang. Step-grpo: Enhancing reasoning quality and ef- ficiency via structured prm-based reinforcement learning.Proceedings of the AAAI Conference on Artificial Intelligence, 40(37):31734–31742, Mar. 2026. doi: 10.1609/aaai.v40i37.40441. URLhttps://ojs.aaai.org/ index.php/AAAI/article/view/40441
-
[15]
What does rl improve for visual reasoning? a frankenstein-style analysis,
Xirui Li, Ming Li, and Tianyi Zhou. What does rl improve for visual reasoning? a frankenstein-style analysis,
- [16]
-
[17]
Critical tokens matter: Token-level contrastive estimation enhances LLM’s reasoning capability
Zicheng Lin, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xing Wang, Ruilin Luo, Chufan Shi, Siheng Li, Yujiu Yang, and Zhaopeng Tu. Critical tokens matter: Token-level contrastive estimation enhances LLM’s reasoning capability. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Pro...
2025
-
[18]
Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
2024
-
[19]
Runqi Qiao, Qiuna Tan, Guanting Dong, MinhuiWu MinhuiWu, Chong Sun, Xiaoshuai Song, Jiapeng Wang, Zhuoma GongQue, Shanglin Lei, Yifan Zhang, et al. We-math: Does your large multimodal model achieve human-like mathematical reasoning? InProceedings of the 63rd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), pages 2...
2025
-
[20]
Cppo: Contrastive perception for vision language policy optimization.arXiv preprint arXiv:XXXX.XXXXX, 2026
Ahmad Rezaei, Mohsen Gholami, Saeed Ranjbar Alvar, Kevin Cannons, Mohammad Asiful Hossain, Zhou Weimin, Shunbo Zhou, Yong Zhang, and Mohammad Akbari. Cppo: Contrastive perception for vision language policy optimization.arXiv preprint arXiv:XXXX.XXXXX, 2026
2026
-
[21]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URLhttps://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, and Tiancheng Zhao. Vlm-r1: A stable and generalizable r1-style large vision-language model.arXiv preprint arXiv:2504.07615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Fleming-vl: Towards universal medical visual reasoning with multimodal llms, 2025
Yan Shu, Chi Liu, Robin Chen, Derek Li, and Bryan Dai. Fleming-vl: Towards universal medical visual reasoning with multimodal llms, 2025. URLhttps://arxiv.org/abs/2511.00916
-
[24]
Terrascope: Pixel-grounded visual reasoning for earth observation
Yan Shu, Bin Ren, Zhitong Xiong, Xiao Xiang Zhu, Begüm Demir, Nicu Sebe, and Paolo Rota. Terrascope: Pixel-grounded visual reasoning for earth observation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16712–16722, 2026. 14 DyCo-RL: Dynamic Cross-Modal Coordination for Visual Reasoning
2026
-
[25]
Kimi Team, Guangyu Chen, Yu Zhang, Jianlin Su, Weixin Xu, Siyuan Pan, Yaoyu Wang, Yucheng Wang, Guanduo Chen, Bohong Yin, Yutian Chen, Junjie Yan, Ming Wei, Y. Zhang, Fanqing Meng, Chao Hong, Xiaotong Xie, Shaowei Liu, Enzhe Lu, Yunpeng Tai, Yanru Chen, Xin Men, Haiqing Guo, Y. Charles, Haoyu Lu, Lin Sui, Jinguo Zhu, Zaida Zhou, Weiran He, Weixiao Huang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Mllm can see? dynamic correction decoding for hallucination mitigation
Chenxi Wang, Xiang Chen, Ningyu Zhang, Bozhong Tian, Haoming Xu, Shumin Deng, and Hua- jun Chen. Mllm can see? dynamic correction decoding for hallucination mitigation. In Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Representations, vol- ume 2025, pages 13712–13736, 2025. URLhttps://proceedings.iclr.cc/paper_f...
2025
-
[27]
Measuring multimodal mathematical reasoning with math-vision dataset
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URLhttps://openreview.net/ forum?id=QWTCcxMpPA
2024
-
[28]
Xiyao Wang, Zhengyuan Yang, Chao Feng, Hongjin Lu, Linjie Li, Chung-Ching Lin, Kevin Lin, Furong Huang, and Lijuan Wang. Sota with less: Mcts-guided sample selection for data-efficient visual reasoning self-improvement.arXiv preprint arXiv:2504.07934, 2025
-
[29]
Yiming Wang, Pei Zhang, Baosong Yang, Derek F. Wong, and Rui Wang. Latent space chain-of-embedding enables output-free llm self-evaluation, 2025. URLhttps://arxiv.org/abs/2410.13640
-
[30]
Perception-Aware Policy Optimization for Multimodal Reasoning
Zhenhailong Wang, Xuehang Guo, Sofia Stoica, Haiyang Xu, Hongru Wang, Hyeonjeong Ha, Xiusi Chen, Yangyi Chen, Ming Yan, Fei Huang, et al. Perception-aware policy optimization for multimodal reasoning. arXiv preprint arXiv:2507.06448, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
arXiv preprint arXiv:2504.15279 , year=
Weiye Xu, Jiahao Wang, Weiyun Wang, Zhe Chen, Wengang Zhou, Aijun Yang, Lewei Lu, Houqiang Li, Xiaohua Wang, Xizhou Zhu, Wenhai Wang, Jifeng Dai, and Jinguo Zhu. Visulogic: A benchmark for eval- uating visual reasoning in multi-modal large language models.arXiv preprint arXiv:2504.15279, 2025. URL https://arxiv.org/abs/2504.15279
-
[32]
Look-back:implicit visual re-focusing in mllm reasoning, 2025
Shuo Yang, Yuwei Niu, Yuyang Liu, Yang Ye, Bin Lin, and Li Yuan. Look-back:implicit visual re-focusing in mllm reasoning, 2025. URLhttps://arxiv.org/pdf/2505.07889
-
[33]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Token-level direct preference optimization.arXiv preprint arXiv:2404.11999, 2024
Yongcheng Zeng, Guoqing Liu, Weiyu Ma, Ning Yang, Haifeng Zhang, and Jun Wang. Token-level direct preference optimization.arXiv preprint arXiv:2404.11999, 2024
-
[35]
arXiv preprint arXiv:2511.18437 , year=
Chi Zhang, Haibo Qiu, Qiming Zhang, Yufei Xu, Zhixiong Zeng, Siqi Yang, Peng Shi, Lin Ma, and Jing Zhang. Perceptual-evidence anchored reinforced learning for multimodal reasoning.arXiv preprint arXiv:2511.18437, 2025
-
[36]
arXiv preprint arXiv:2508.04416 , year=
Haoji Zhang, Xin Gu, Jiawen Li, Chixiang Ma, Sule Bai, Chubin Zhang, Bowen Zhang, Zhichao Zhou, Dongliang He, and Yansong Tang. Thinking with videos: Multimodal tool-augmented reinforcement learn- ing for long video reasoning.arXiv preprint arXiv:2508.04416, 2025. 15 DyCo-RL: Dynamic Cross-Modal Coordination for Visual Reasoning
-
[37]
MLLMs know where to look: Training-free perception of small visual details with multimodal LLMs
Jiarui Zhang, Mahyar Khayatkhoei, Prateek Chhikara, and Filip Ilievski. MLLMs know where to look: Training-free perception of small visual details with multimodal LLMs. InThe Thirteenth International Con- ference on Learning Representations, 2025. URLhttps://arxiv.org/abs/2502.17422
-
[38]
MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems?
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Peng Gao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems?arXiv preprint arXiv:2403.14624, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization, 2025. URL https://arxiv.org/abs/2507.18071. 16 DyCo-RL: Dynamic Cross-Modal Coordination for Visual Reasoning A Overview of Appendix • B:LLM Usage Statement. • C:Broader Impa...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
since angle ADE is 80 ◦
The entire training pipeline is deployed on a single server equipped with 8×NVIDIA A100 (80GB) GPUs. The training requires approximately 48 GPU-hours for the 3B model and 72 GPU-hours for the 7B model , averaged per algorithm. F Diagnostic Annotation Protocol To ground our analysis of visual reasoning breakdowns in concrete model behavior, we con- struct ...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.