On Low-Bit Quantization Errors in Speaker Verification: Diagnostic and Mitigation
Pith reviewed 2026-06-27 19:31 UTC · model grok-4.3
The pith
A calibrated multi-precision cascade resolves most speaker verification trials at 2 bits and escalates only ambiguous cases to match FP32 performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Joint layer-wise and score-level analyses of quantized ResNet models identify fragile components and show that score degradation is not fully explained by weight distortion alone, with a knee point at 2 bits where larger score drift and harmful decision flips concentrate near the FP32 threshold. Building on these findings, the paper proposes a calibrated multi-precision cascade that resolves most trials at 2 bits and escalates only ambiguous cases, achieving performance close to FP32 while preserving the efficiency benefits of low-bit inference with substantially lower compute and memory costs.
What carries the argument
The calibrated multi-precision cascade, which uses score-level ambiguity detection to decide whether to resolve a trial at 2-bit precision or escalate it.
If this is right
- The majority of speaker verification trials can be handled at 2-bit precision without large accuracy loss when ambiguous cases are escalated.
- Score errors under extreme quantization concentrate near decision thresholds and can be mitigated by selective higher-precision handling.
- Layer-wise analysis can pinpoint fragile model components that require targeted quantization care beyond simple weight distortion metrics.
- Substantial compute and memory savings become available while keeping verification performance near floating-point levels.
Where Pith is reading between the lines
- The cascade approach could extend to other audio or biometric tasks where input difficulty varies and selective precision is feasible.
- Dynamic precision selection based on score confidence might further reduce average energy use on edge devices beyond static quantization.
- The finding that weight distortion does not fully explain score errors suggests similar diagnostic studies could benefit quantization efforts in other domains.
Load-bearing premise
Score-level ambiguity can be reliably detected at inference time without introducing new latency or accuracy trade-offs in real deployments.
What would settle it
A deployment test in which the cascade's ambiguity detector misses enough cases to produce overall verification accuracy significantly below the FP32 baseline.
Figures
read the original abstract
Although low-bit quantization provides practical means to deploy speaker verification on resource-constrained devices, its effects on speaker verification performance remain poorly understood. In this paper, we study uniform K-means quantization-aware training of ResNet-36 and ResNet-200 through joint layer-wise and score-level analyses. Our layer-wise analysis highlights fragile components and shows that score degradation is not fully explained by weight distortion alone. We identify a clear knee point at 2 bits, with larger score drift and harmful decision flips concentrated near the FP32 threshold. Our score-level analysis reveals where and how score errors emerge under extreme quantization. Building on these findings, we propose a calibrated multi-precision cascade that resolves most trials at 2 bits and escalates only ambiguous cases, achieving performance close to FP32 while preserving the efficiency benefits of low-bit inference with substantially lower compute and memory costs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the effects of uniform K-means quantization-aware training on ResNet-36 and ResNet-200 speaker verification models via joint layer-wise and score-level analyses. It identifies fragile components, a 2-bit knee point with concentrated score drift and decision flips near the FP32 threshold, and proposes a calibrated multi-precision cascade that resolves most trials at 2 bits while escalating only ambiguous cases to achieve near-FP32 performance with lower compute and memory costs.
Significance. If the cascade's efficiency claims hold with low escalation rates and negligible detector overhead, the work offers both diagnostic value on quantization-induced errors in speaker verification and a practical deployment strategy for resource-constrained devices, potentially improving the accuracy-efficiency tradeoff in real-world systems.
major comments (1)
- [Abstract] Abstract: The headline claim that the multi-precision cascade 'resolves most trials at 2 bits and escalates only ambiguous cases' while 'preserving the efficiency benefits of low-bit inference with substantially lower compute and memory costs' is load-bearing but unsupported by any reported escalation fraction, ambiguity-detector description, average-FLOPs/latency numbers, or comparisons to pure 2-bit and FP32 baselines. This quantification is required to substantiate the efficiency benefit.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. The single major comment highlights a need for quantitative support of the cascade's efficiency claims, which we address below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that the multi-precision cascade 'resolves most trials at 2 bits and escalates only ambiguous cases' while 'preserving the efficiency benefits of low-bit inference with substantially lower compute and memory costs' is load-bearing but unsupported by any reported escalation fraction, ambiguity-detector description, average-FLOPs/latency numbers, or comparisons to pure 2-bit and FP32 baselines. This quantification is required to substantiate the efficiency benefit.
Authors: We agree that the abstract's efficiency claims require explicit supporting numbers to be substantiated. The full manuscript contains the cascade description and some related results, but does not report the specific escalation fraction, ambiguity-detector details, average-FLOPs/latency, or direct baseline comparisons requested. In the revised version we will add these quantifications to both the abstract and the experimental section (including tables comparing escalation rates, compute costs, and accuracy against pure 2-bit and FP32 models). revision: yes
Circularity Check
No circularity: purely empirical analysis with no derivation chain
full rationale
The paper conducts layer-wise and score-level empirical analyses of quantization effects on ResNet models for speaker verification, identifies patterns such as a knee point at 2 bits, and proposes a multi-precision cascade based on those observations. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. The central claim rests on experimental results rather than any reduction of outputs to inputs by construction. This is the expected outcome for an engineering/empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Speaker verification (SV) aims to verify a speaker’s claimed identity from their voice. Over the past decade, SV has largely shifted toward deep embedding systems, in which a neu- ral encoder maps variable-length speech utterances to fixed- dimensional speaker representations, referred to asspeaker embeddings, which are then compared by a sco...
Pith/arXiv arXiv 2026
-
[2]
The goal is to replace the FP32 weights of each layer by a small set of learned quantization levels while preserving the verification performance of the speaker embedding model
K-Means Quantization-Aware Training We build on the K-Means Quantization-Aware Training (KMQAT) framework introduced by Liuet al.[10], and use a uniform layer-wise version throughout this study. The goal is to replace the FP32 weights of each layer by a small set of learned quantization levels while preserving the verification performance of the speaker e...
-
[3]
Experimental Protocol We first describe the training setup used for both FP32 and quantized models (Section 3.1), then introduce the ResNet ar- chitectures considered in the study (Section 3.2), and finally present the evaluation protocol used for in-domain and out-of- domain assessment (Section 3.3). 3.1. Training setup All experiments are conducted usin...
-
[4]
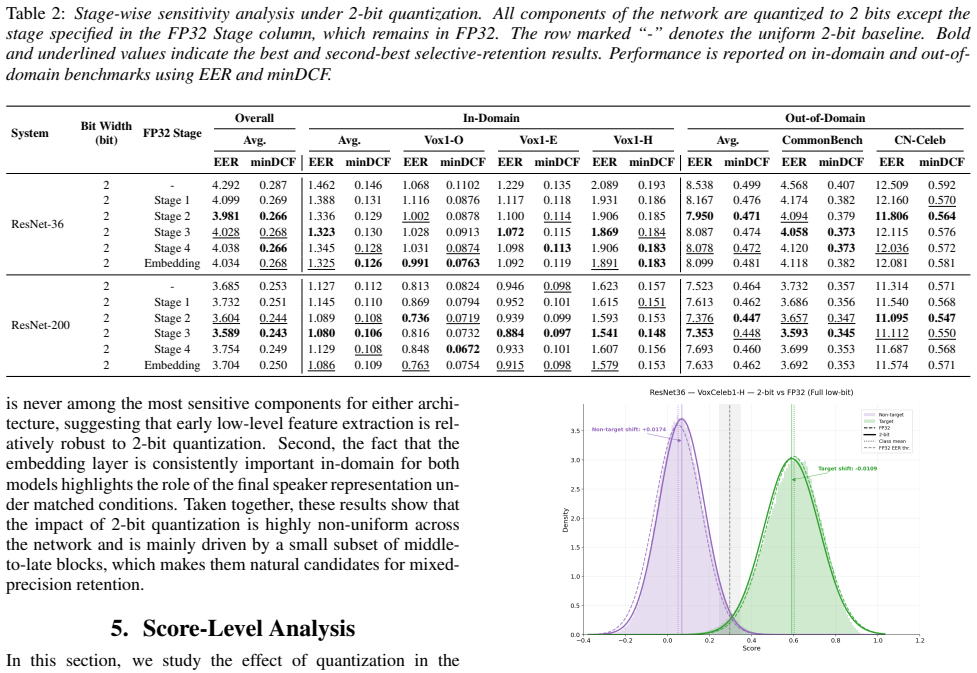
Layer-wise Analysis In this section, we first study the impact of uniform quantiza- tion across bit-widths to determine the regime in which perfor- mance loss becomes substantial (Section 4.1). We then focus on this regime and perform a stage-wise sensitivity analysis to identify the components that are most critical under aggressive quantization (Section...
-
[5]
We first characterize the global score drift in- duced by quantization and analyze how its magnitude evolves as the bit-width decreases (Section 5.1)
Score-Level Analysis In this section, we study the effect of quantization in the score space. We first characterize the global score drift in- duced by quantization and analyze how its magnitude evolves as the bit-width decreases (Section 5.1). We then examine how these score perturbations affect decision robustness by study- ing harmful decision flips wi...
2043
-
[6]
Calibrated Multi-Precision Cascade In this section, we introduce a multi-precision cascade where trials are first handled at at 2 bits and only ambiguous cases are escalated to higher precision. First we present a calibrated gat- ing rule based on the distance of low-bit scores to the FP32 threshold (Section 6.1), then evaluate its verification perfor- ma...
-
[7]
The results show that 2-bit quantization causes the largest performance drop, while 3- and 4-bit models remain close to FP32
Conclusion This paper examines low-bit KMQAT for speaker verification on ResNet-36 and ResNet-200 with uniform 4-bit, 3-bit, and 2-bit quantization, across in-domain and out-of-domain bench- marks. The results show that 2-bit quantization causes the largest performance drop, while 3- and 4-bit models remain close to FP32. Stage-wise retention experiments ...
-
[8]
Acknowledgements This project was provided with computing HPC and stor- age resources by GENCI at IDRIS thanks to the grant 2026- AD011016050R1 on the supercomputer Jean Zay V100 parti- tion
2026
-
[9]
But system description to voxceleb speaker recognition chal- lenge 2019,
H. Zeinali, S. Wang, A. Silnova, P. Mat ˇejka, and O. Plchot, “But system description to voxceleb speaker recognition chal- lenge 2019,”arXiv preprint arXiv:1910.12592, 2019
arXiv 2019
-
[10]
ECAPA- TDNN: Emphasized Channel Attention, Propagation and Ag- gregation in TDNN Based Speaker Verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA- TDNN: Emphasized Channel Attention, Propagation and Ag- gregation in TDNN Based Speaker Verification,” inInterspeech, 2020, pp. 3830–3834
2020
-
[11]
ECAPA2: A hybrid neural net- work architecture and training strategy for robust speaker embed- dings,
J. Thienpondt and K. Demuynck, “ECAPA2: A hybrid neural net- work architecture and training strategy for robust speaker embed- dings,” in2023 IEEE automatic speech recognition and under- standing workshop (ASRU). IEEE, 2023, pp. 1–8
2023
-
[12]
Reshape dimensions network for speaker recognition,
I. Yakovlev, R. Makarov, A. Balykin, P. Malov, A. Okhotnikov, and N. Torgashov, “Reshape dimensions network for speaker recognition,” inInterspeech 2024, 2024, pp. 3235–3239
2024
-
[13]
Towards lightweight applications: Asymmetric enroll-verify structure for speaker verification,
Q. Lin, L. Yang, X. Wang, X. Qin, J. Wang, and M. Li, “Towards lightweight applications: Asymmetric enroll-verify structure for speaker verification,” 2022. [Online]. Available: https://arxiv.org/abs/2110.04438
arXiv 2022
-
[14]
Knowledge dis- tillation for small foot-print deep speaker embedding,
S. Wang, Y . Yang, T. Wang, Y . Qian, and K. Yu, “Knowledge dis- tillation for small foot-print deep speaker embedding,” inICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019, pp. 6021–6025
2019
-
[15]
Self-knowledge distillation via feature enhancement for speaker verification,
B. Liu, H. Wang, Z. Chen, S. Wang, and Y . Qian, “Self-knowledge distillation via feature enhancement for speaker verification,” in ICASSP 2022 - 2022 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2022, pp. 7542– 7546
2022
-
[16]
Model Compres- sion for DNN-based Speaker Verification Using Weight Quantiza- tion,
W. L. Jingyu Li, Z. Zhang, J. Wang, and T. Lee, “Model Compres- sion for DNN-based Speaker Verification Using Weight Quantiza- tion,” inInterspeech 2023, 2023, pp. 1988–1992
2023
-
[17]
Adaptive Neural Net- work Quantization For Lightweight Speaker Verification,
H. Wang, B. Liu, Y . Wu, and Y . Qian, “Adaptive Neural Net- work Quantization For Lightweight Speaker Verification,” inIn- terspeech 2023, 2023, pp. 5331–5335
2023
-
[18]
Towards lightweight speaker verification via adaptive neural network quantization,
B. Liu, H. Wang, and Y . Qian, “Towards lightweight speaker verification via adaptive neural network quantization,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 3771—-3784, 2024. [Online]. Available: http://dx.doi.org/10.1109/TASLP.2024.3437237
-
[19]
Estimating or propagating gradients through stochastic neurons for conditional computation,
Y . Bengio, N. L ´eonard, and A. Courville, “Estimating or propagating gradients through stochastic neurons for conditional computation,” 2013. [Online]. Available: https://arxiv.org/abs/ 1308.3432
Pith/arXiv arXiv 2013
-
[20]
Kiwano: A Cutting-Edge Open- Source Toolkit for Speaker Verification,
M. Rouvier and P.-M. Bousquet, “Kiwano: A Cutting-Edge Open- Source Toolkit for Speaker Verification,” inOdyssey 2026, 2026
2026
-
[21]
V oxCeleb2: Deep speaker recognition,
J. S. Chung, A. Nagrani, and A. Zisserman, “V oxCeleb2: Deep speaker recognition,” inInterspeech, 2018, arXiv:1806.05622
arXiv 2018
-
[22]
X-Vectors: Robust dnn embeddings for speaker recogni- tion,
D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khu- danpur, “X-Vectors: Robust dnn embeddings for speaker recogni- tion,” in2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018, pp. 5329–5333
2018
-
[23]
MUSAN: A music, speech, and noise corpus,
D. Snyder, G. Chen, and D. Povey, “MUSAN: A music, speech, and noise corpus,” 2015. [Online]. Available: https: //arxiv.org/abs/1510.08484
Pith/arXiv arXiv 2015
-
[24]
A study on data augmentation of reverberant speech for robust speech recognition,
T. Ko, V . Peddinti, D. Povey, M. L. Seltzer, and S. Khudanpur, “A study on data augmentation of reverberant speech for robust speech recognition,” inInternational Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 5220–5224
2017
-
[25]
Studying squeeze-and- excitation used in cnn for speaker verification,
M. Rouvier and P.-M. Bousquet, “Studying squeeze-and- excitation used in cnn for speaker verification,” 2021. [Online]. Available: https://arxiv.org/abs/2109.05977
arXiv 2021
-
[26]
V oxCeleb: a large- scale speaker identification dataset,
A. Nagrani, J. S. Chung, and A. Zisserman, “V oxCeleb: a large- scale speaker identification dataset,” inInterspeech, 2017
2017
-
[27]
CommonBench: A larger scale speaker verification benchmark,
J. Hintz and I. Siegert, “CommonBench: A larger scale speaker verification benchmark,” in4th Symposium on Security and Pri- vacy in Speech Communication, 2024, pp. 17–20
2024
-
[28]
CN-Celeb: A challenging chinese speaker recognition dataset,
Y . Fan, L. Chen, S. Kang, and et al., “CN-Celeb: A challenging chinese speaker recognition dataset,” inProc. Interspeech, 2019
2019
-
[29]
V oxTube: a multilingual speaker recognition dataset,
I. Yakovlev, A. Okhotnikov, N. Torgashov, R. Makarov, Y . V o- evodin, and K. Simonchik, “V oxTube: a multilingual speaker recognition dataset,” inInterspeech 2023, 2023, pp. 2238–2242
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.