A Multi-modal Agentic Co-pilot for Evidence Grounded Computational Pathology
Pith reviewed 2026-06-27 19:30 UTC · model grok-4.3
The pith
PathPocket, a multi-agent AI co-pilot, outperforms prior methods on 200,000 pathology cases by retrieving evidence from a 4.55-million-entity hypergraph.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
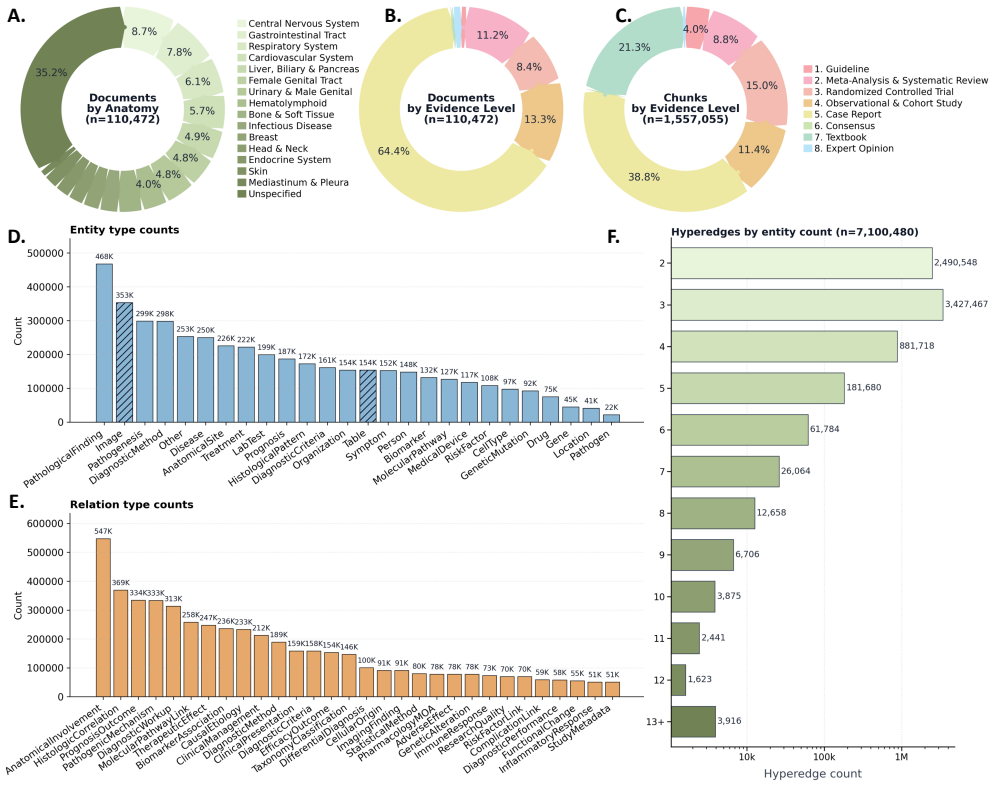
PathPocket is a multimodal AI agentic co-pilot that uses a rigorously graded pathology evidence corpus of 110,472 documents to construct a hypergraph containing 4.55 million entities and 7.10 million relations. This hypergraph serves as the foundation for a collaborative multi-agent reasoning framework that performs input understanding, evidence retrieval, filtering, and diagnosis generation, enabling solutions to clinical tasks ranging from text queries to complex multimodal diagnostics involving regions of interest and whole-slide images. The system is evaluated on over 200,000 real-world cases where it outperforms existing methods and, in user studies, improves pathologists' diagnostic ac
What carries the argument
The multimodal pathology hypergraph with over 4.55 million entities and 7.10 million relations, which acts as the knowledge engine for the multi-agent retrieval and diagnosis framework.
Load-bearing premise
The 110,472-document corpus and the 4.55-million-entity hypergraph are assumed to be sufficiently complete, accurately graded, and free of systematic bias.
What would settle it
A test set of pathology cases drawn exclusively from literature published after the corpus collection date, where PathPocket's diagnostic accuracy is measured against both human pathologists and non-evidence-based AI baselines.
Figures

read the original abstract
Pathology is the cornerstone of modern medicine, where accurate decision-making relies heavily on evidence-based practices. While artificial intelligence (AI) has the potential to transform clinical workflows, the intersection of AI and evidence-based medicine remains under-explored, with primitive attempts restricted to text-only general medicine. In this work, we present PathPocket, a multimodal AI agentic co-pilot designed specifically for evidence grounded pathology. We construct the most comprehensive pathology evidence corpus to date, encompassing approximately 110,472 public and authorized documents structured across a rigorous hierarchy of evidence from clinical guideline to expert opinion. From this meticulously graded foundation, we build a large-scale multimodal pathology hypergraph containing over 4.55 million entities and 7.10 million relations. Serving as a robust knowledge engine, this hypergraph provides traceable evidence for a collaborative multi-agent reasoning framework integrating input understanding, evidence retrieval, filtering, and diagnosis generation. This enables PathPocket to seamlessly resolve a wide spectrum of clinical tasks, ranging from text-only queries to complex multimodal diagnostics involving region-of-interest (ROI) and gigapixel whole-slide images (WSIs). We rigorously evaluate the system on a multidimensional benchmark of over 200,000 real-world cases, where it significantly outperforms existing state-of-the-arts. Crucially, extensive user studies demonstrate that PathPocket substantially improves the diagnostic accuracy and confidence of pathologists. By directly grounding pathology interpretations in verifiable literature, PathPocket offers a practical and scalable solution for the future of evidence grounded computational pathology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
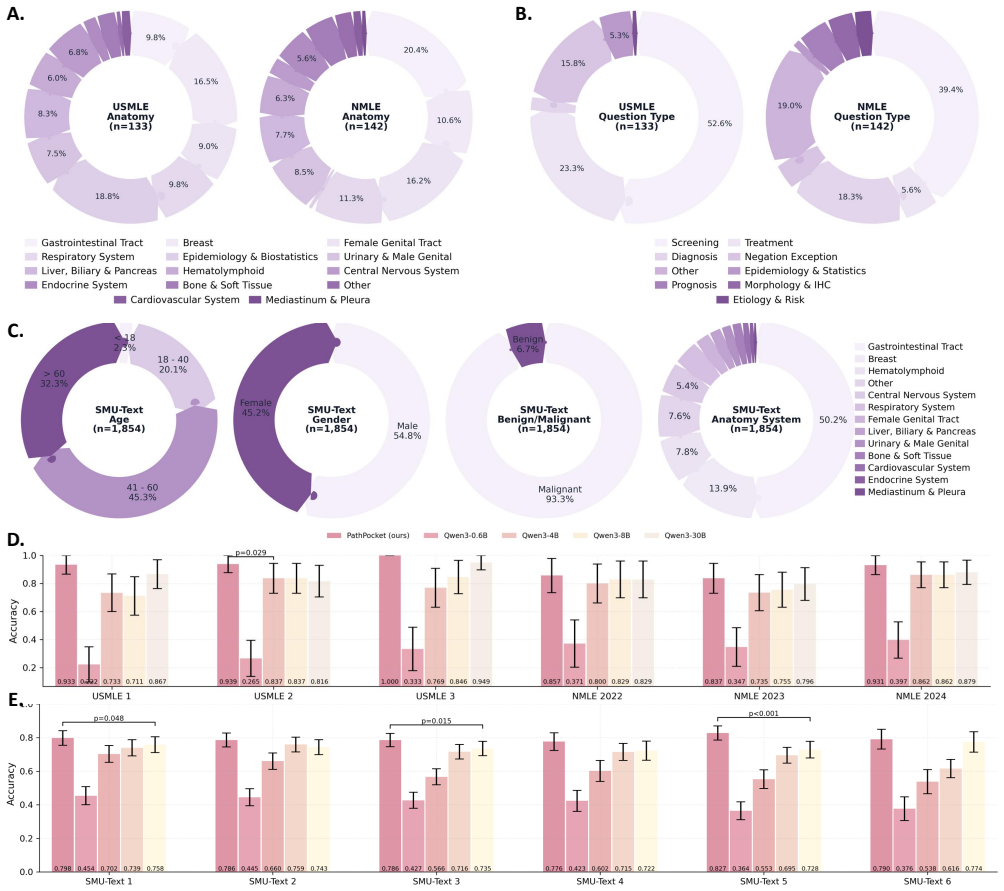
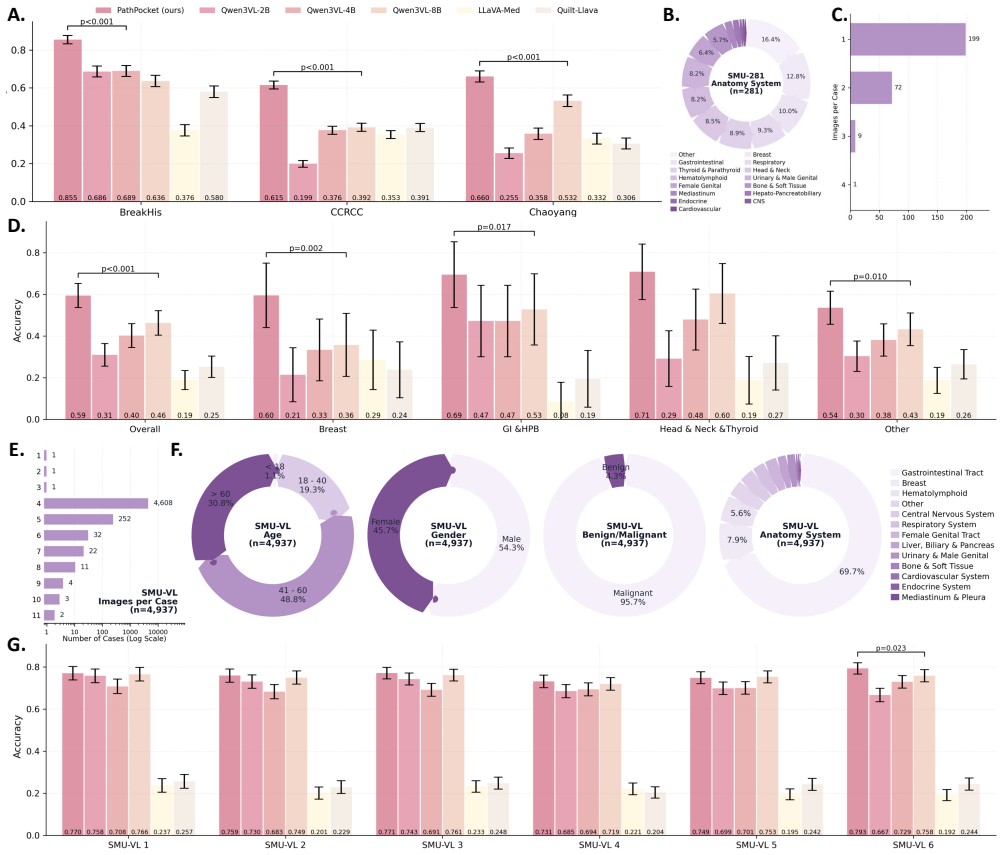
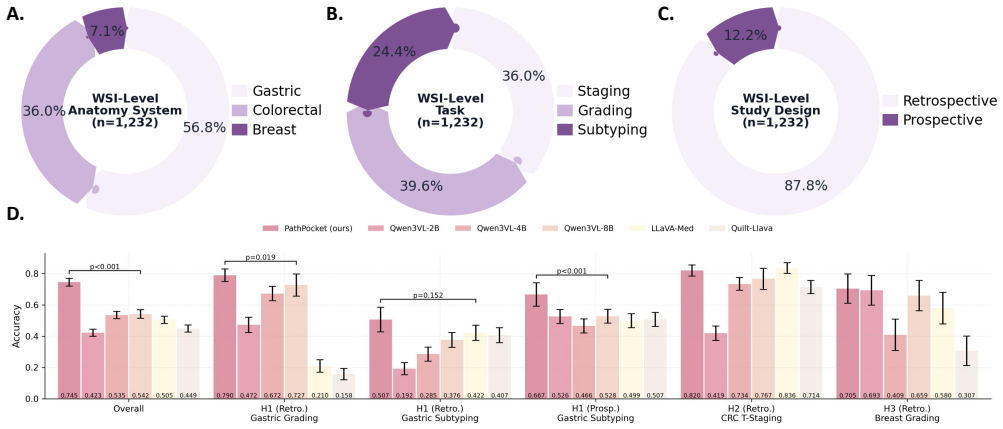
Summary. The paper presents PathPocket, a multimodal agentic co-pilot for evidence-grounded computational pathology. It constructs a corpus of ~110k graded documents, derives a 4.55M-entity/7.1M-relation multimodal hypergraph, and deploys a multi-agent framework (input understanding, retrieval, filtering, diagnosis) that handles text queries through ROI/WSI analysis. The central claims are significant outperformance versus SOTAs on a >200k-case real-world benchmark plus substantial gains in pathologist diagnostic accuracy and confidence in user studies.
Significance. If the core claims survive validation, the work would be a notable engineering contribution to evidence-based AI in pathology by supplying traceable literature grounding at scale. The corpus size and hypergraph construction are ambitious; successful integration of multi-agent reasoning with such a knowledge base could influence clinical decision-support systems. No machine-checked proofs or parameter-free derivations are present, but the scale of the artifact itself is a strength worth noting if the accuracy assumptions hold.
major comments (3)
- [Corpus and hypergraph construction] Corpus and hypergraph construction (described in the methods following the abstract): no inter-rater reliability, coverage statistics against reference pathology ontologies, or error rates for entity linking/relation typing/evidence grading are reported for the 110,472-document corpus or the resulting 4.55M-entity hypergraph. This is load-bearing for the central claim because the multi-agent retrieval, filtering, and diagnosis steps are driven by this hypergraph; systematic extraction or grading errors would directly undermine both the 200k-case benchmark results and the user-study gains.
- [Evaluation on 200,000-case benchmark] Evaluation section (benchmark of >200,000 cases): the abstract asserts significant outperformance over existing state-of-the-arts but supplies no baseline details, statistical tests, exclusion criteria, or error analysis. Without these elements the multidimensional performance claim cannot be assessed and the reported gains remain unverifiable from the given text.
- [User studies] User studies section: the reported improvements in diagnostic accuracy and confidence lack participant numbers, study design details, statistical analysis, or bias controls. These omissions make the user-study component of the central claim difficult to interpret or replicate.
minor comments (1)
- [Abstract] Abstract: 'state-of-the-arts' should read 'state-of-the-art'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to provide the requested details and validations.
read point-by-point responses
-
Referee: [Corpus and hypergraph construction] Corpus and hypergraph construction (described in the methods following the abstract): no inter-rater reliability, coverage statistics against reference pathology ontologies, or error rates for entity linking/relation typing/evidence grading are reported for the 110,472-document corpus or the resulting 4.55M-entity hypergraph. This is load-bearing for the central claim because the multi-agent retrieval, filtering, and diagnosis steps are driven by this hypergraph; systematic extraction or grading errors would directly undermine both the 200k-case benchmark results and the user-study gains.
Authors: We agree that these validation metrics are essential. In the revised manuscript we will add a new subsection reporting inter-rater reliability (Cohen’s kappa on a 1,000-document sample), coverage statistics versus SNOMED CT and ICD-O, and error rates for entity linking and evidence grading obtained from manual review of a held-out set. This will directly substantiate the hypergraph’s reliability for the downstream agents. revision: yes
-
Referee: [Evaluation on 200,000-case benchmark] Evaluation section (benchmark of >200,000 cases): the abstract asserts significant outperformance over existing state-of-the-arts but supplies no baseline details, statistical tests, exclusion criteria, or error analysis. Without these elements the multidimensional performance claim cannot be assessed and the reported gains remain unverifiable from the given text.
Authors: We will expand the evaluation section to list the exact SOTA baselines, report p-values from appropriate statistical tests, specify exclusion criteria applied to the >200k cases, and include a categorized error analysis. These additions will make the performance claims fully verifiable. revision: yes
-
Referee: [User studies] User studies section: the reported improvements in diagnostic accuracy and confidence lack participant numbers, study design details, statistical analysis, or bias controls. These omissions make the user-study component of the central claim difficult to interpret or replicate.
Authors: The revised user-studies section will report participant count, full study design (within-subject protocol), statistical tests used, and bias-control procedures (randomization and blinding). These details were collected during the studies and will now be included. revision: yes
Circularity Check
No circularity; engineering artifact on external corpus with no self-referential derivations.
full rationale
The paper presents PathPocket as a constructed system: a corpus of ~110k public documents is assembled into a graded hierarchy, from which a 4.55M-entity hypergraph is derived to support multi-agent retrieval and diagnosis. Evaluation occurs on a separate 200k-case benchmark and user studies. No equations, fitted parameters, predictions that reduce to inputs by construction, or load-bearing self-citations appear in the abstract or described chain. The central claims rest on external data sources and independent benchmarks rather than any loop where outputs are defined by or fitted to the same inputs. This is the expected non-finding for an applied engineering paper without mathematical derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Documents can be reliably graded into a strict hierarchy from clinical guidelines to expert opinion for pathology evidence.
invented entities (1)
-
Pathology hypergraph (4.55M entities, 7.10M relations)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
L., Rosenberg, W
Sackett, D. L., Rosenberg, W. M., Gray, J. M., Haynes, R. B. & Richardson, W. S. Evidence based medicine: what it is and what it isn’t.BMJ312, 71–72 (1996)
1996
-
[2]
H.et al.Grade: an emerging consensus on rating quality of evidence and strength of recommendations.Bmj 336, 924–926 (2008)
Guyatt, G. H.et al.Grade: an emerging consensus on rating quality of evidence and strength of recommendations.Bmj 336, 924–926 (2008). 3.Howick, J.et al.The oxford 2011 levels of evidence.Oxf. Centre for Evidence-Based Medicine(2011). 4.Hanahan, D. & Weinberg, R. A. The hallmarks of cancer.cell100, 57–70 (2000). 5.Hanahan, D. & Weinberg, R. A. Hallmarks o...
2008
-
[3]
Nowell, P. C. The clonal evolution of tumor cell populations: Acquired genetic lability permits stepwise selection of variant sublines and underlies tumor progression.Science194, 23–28 (1976)
1976
-
[4]
& Warren, J
Marshall, B. & Warren, J. R. Unidentified curved bacilli in the stomach of patients with gastritis and peptic ulceration.The lancet323, 1311–1315 (1984)
1984
-
[5]
K., Fausto, N
Kumar, V ., Abbas, A. K., Fausto, N. & Aster, J. C.Robbins and Cotran pathologic basis of disease, professional edition e-book(Elsevier health sciences, 2014). 9.Rosai, J.Rosai and Ackerman’s surgical pathology e-book(Elsevier Health Sciences, 2011). 10.Song, A. H.et al.Artificial intelligence for digital and computational pathology.Nat. Rev. Bioeng.1, 93...
2014
-
[6]
& Kather, J
Shmatko, A., Ghaffari Laleh, N., Gerstung, M. & Kather, J. N. Artificial intelligence in histopathology: enhancing cancer research and clinical oncology.Nat. cancer3, 1026–1038 (2022). 12.Lu, M. Y .et al.A visual-language foundation model for computational pathology.Nat. Medicine30(2024)
2022
-
[7]
Wang, X.et al.A pathology foundation model for cancer diagnosis and prognosis prediction.Nature634, 970–978 (2024)
2024
-
[8]
Ma, J.et al.Towards a generalizable pathology foundation model via unified knowledge distillation.Nat. Biomed. Eng. (2025). 15.Xiang, J.et al.A vision–language foundation model for precision oncology.Nature1–10 (2025). 18/31
2025
- [9]
-
[10]
J.et al.Towards a general-purpose foundation model for computational pathology.Nat
Chen, R. J.et al.Towards a general-purpose foundation model for computational pathology.Nat. Medicine30, 850–862 (2024)
2024
-
[11]
medicine30, 2924–2935 (2024)
V orontsov, E.et al.A foundation model for clinical-grade computational pathology and rare cancers detection.Nat. medicine30, 2924–2935 (2024). 19.Xu, H.et al.A whole-slide foundation model for digital pathology from real-world data.Nature630, 181–188 (2024)
2024
-
[12]
Huang, Z., Bianchi, F., Yuksekgonul, M., Montine, T. J. & Zou, J. A visual–language foundation model for pathology image analysis using medical twitter.Nat. medicine29, 2307–2316 (2023)
2023
- [13]
-
[14]
Xu, Z., Jin, C., Wang, Y ., Liu, Z. & Chen, H. Discovering pathology rationale and token allocation for efficient multimodal pathology reasoning.arXiv preprint arXiv:2505.15687(2025). 23.Lu, M. Y .et al.A multimodal generative ai copilot for human pathology.Nature634, 466–473 (2024)
-
[15]
Chen, C.et al.Evidence-based diagnostic reasoning with multi-agent copilot for human pathology.arXiv preprint arXiv:2506.20964(2025). 25.Team, O. Openevidence: integrating medical evidence for clinical decision support.NEJM AI1, A156–165 (2024)
-
[16]
Linearly Multiplexed Photon Number Resolving Single-photon Detectors Array
Inc., B. Baichuan-m2 and m3: Large language models for medical evidence retrieval and synthesis.arXiv preprint arXiv:2408.12345(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Wang, L.et al.Ypathrag: A pathology retrieval-augmented generation framework with dual-channel hybrid retrieval.Chin. J. Pathol.(2024)
2024
-
[18]
AAAI Conf
Zhang, W.et al.Patho-agenticrag: Towards multimodal agentic retrieval-augmented generation for pathology via reinforcement learning.Proc. AAAI Conf. on Artif. Intell.(2026)
2026
-
[19]
MinerU: An Open-Source Solution for Precise Document Content Extraction
Wang, B.et al.Mineru: An open-source solution for precise document content extraction.arXiv preprint arXiv:2409.18839 (2024). 30.Stonebraker, M. & Rowe, L. A. The design of postgres.ACM Sigmod Rec.15, 340–355 (1986). 31.Ding, T.et al.A multimodal whole-slide foundation model for pathology.Nat. Medicine1–13 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Chen, J.et al.Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self- knowledge distillation (2024). 2402.03216
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [21]
-
[22]
Zhang, Y .et al.Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
A., Oliveira, L
Spanhol, F. A., Oliveira, L. S., Petitjean, C. & Heutte, L. A dataset for breast cancer histopathological image classification. Ieee transactions on biomedical engineering63, 1455–1462 (2015)
2015
-
[24]
& Brück, O
Brummer, O., Pölönen, P., Mustjoki, S. & Brück, O. Computational textural mapping harmonises sampling variation and reveals multidimensional histopathological fingerprints.Br. J. Cancer129, 683–695 (2023)
2023
-
[25]
Zhu, C., Chen, W., Peng, T., Wang, Y . & Jin, M. Hard sample aware noise robust learning for histopathology image classification.IEEE transactions on medical imaging41, 881–894 (2021). 38.Yang, A.et al.Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025). 39.Bai, S.et al.Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
Neural Inf
Li, C.et al.Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Adv. Neural Inf. Process. Syst.36, 28541–28564 (2023)
2023
-
[27]
S., Ikezogwo, W
Seyfioglu, M. S., Ikezogwo, W. O., Ghezloo, F., Krishna, R. & Shapiro, L. Quilt-llava: Visual instruction tuning by extracting localized narratives from open-source histopathology videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13183–13192 (2024)
2024
-
[28]
InAdvances in Neural Information Processing Systems, 8026–8037 (2019)
Paszke, A.et al.Pytorch: An imperative style, high-performance deep learning library. InAdvances in Neural Information Processing Systems, 8026–8037 (2019). 19/31 Appendix Table 1.Sources and URLs for the Pathology Evidence Corpus.Documents were stratified into an 8-tier evidence hierarchy adapted from standard evidence-based medicine frameworks (e.g., GR...
2019
-
[29]
Renal Cell Carcinoma
**Entity Extraction:** * ** Identification:** Identify clinically and pathologically significant entities.,→ * ** Entity Details:** * `entity_name`: Use standard medical terminology. Capitalize Title Case. Ensure consistency (e.g., use "Renal Cell Carcinoma" consistently). ,→ ,→ * `entity_type`: Categorize using:`{entity_types}`. If none apply, use`Other`...
-
[30]
Drug X combined with Drug Y treats Disease Z in Organ W
**Relationship Extraction:** * ** Identification:** Identify objective, factual connections such as etiology, pathogenesis, diagnostic criteria, treatment efficacy, or prognosis. ,→ ,→ * ** Multi-Entity Relations:** Capture relationships involving two or more entities (e.g., "Drug X combined with Drug Y treats Disease Z in Organ W" should be a single rela...
-
[31]
treats,"
**General Protocols:** * ** Delimiter:** Use`{tuple_delimiter}`strictly as a separator. * ** Directionality:** Relationships like "treats," "causes," or "indicates" are directed. Ensure logical flow.,→ 21/31 * ** Objectivity:** Use third-person medical language. No pronouns. * ** Language:** Output in {language}. Keep proper nouns (e.g., gene names like *...
-
[32]
,→ ,→ ,→
**Strict Adherence to System Format:** Strictly adhere to all format requirements for entity and relationship lists, including output order, field delimiters, and proper noun handling, as specified in the system instructions. ,→ ,→ ,→
-
[33]
**Focus on Corrections/Additions:** * ** Do NOT** re-output entities and relationships that were **correctly and fully** extracted in the last task.,→ * If an entity or relationship was **missed** in the last task, extract and output it now according to the system format.,→ * If an entity or relationship was **truncated, had missing fields, or was otherwi...
-
[34]
The first field *must* be the literal string`entity`
**Output Format - Entities:** Output a total of 4 fields for each entity, delimited by`{tuple_delimiter}`, on a single line. The first field *must* be the literal string`entity`. ,→ ,→
-
[35]
The first field *must* be the literal string`relation`
**Output Format - Relations:** Output at least 5 fields for each relation, delimited by`{tuple_delimiter}`, on a single line. The first field *must* be the literal string`relation`. The last two fields are always keywords and description. All fields in between are entity names (2 or more entities). ,→ ,→ ,→ ,→
-
[36]
Do not include any introductory or concluding remarks, explanations, or additional text before or after the list
**Output Content Only:** Output *only* the extracted list of entities and relationships. Do not include any introductory or concluding remarks, explanations, or additional text before or after the list. ,→ ,→
-
[37]
**Completion Signal:** Output`{completion_delimiter}`as the final line after all relevant missing or corrected entities and relationships have been extracted and presented. ,→ ,→
-
[38]
Proper nouns (e.g., personal names, place names, organization names) must be kept in their original language and not translated
**Output Language:** Ensure the output language is {language}. Proper nouns (e.g., personal names, place names, organization names) must be kept in their original language and not translated. ,→ ,→ <Output> 22/31 Pathology Reasoning: Query Parsing Agent ---Role--- You are an expert pathology query analyzer for a multimodal pathology knowledge hypergraph R...
-
[39]
**Output**: Valid JSON only -- no markdown fences, no text before/after
-
[40]
Do NOT use the MCQ options to invent or supplement these fields
**Source split (CRITICAL)**: - **Stem-only**: You MUST derive **site**, **gross_entities**, **gross_description**, **morphology_entities**, **morphology_description**, **marker_entities**, **marker_description**, **clinical_entities**, **clinical_description**, **other_entities** ONLY from the **stem**. Do NOT use the MCQ options to invent or supplement t...
-
[41]
Use`""`when empty
**Types**:`site`,`gross_description`,`morphology_description`, `marker_description`, and`clinical_description`must be **strings** (never JSON arrays). Use`""`when empty. ,→ ,→ 23/31
-
[42]
**Concise** for`site`and` *_entities`; description fields may stay close to full original sentences where helpful.,→
-
[43]
Your primary function is to answer user queries accurately by ONLY using the information within the provided **Context**
**Non-pathology / garbage queries**: Return all keys with`[]`or`""`as appropriate.,→ ---Examples--- {examples} ---Real Data--- User Query: {query} ---Output--- Output: Pathology Reasoning: Dianosis Agent ---Role--- You are an expert AI assistant specializing in synthesizing information from a provided knowledge base. Your primary function is to answer use...
-
[44]
Identify and extract all pieces of information that are directly relevant to answering the user query
Step-by-Step Instruction: - Carefully determine the user's query intent in the context of the conversation history to fully understand the user's information need.,→ - Scrutinize both`Knowledge Graph Data`,`Document Chunks`, and`Retrieved Similar Images`in the **Context**. Identify and extract all pieces of information that are directly relevant to answer...
-
[45]
Content & Grounding: - Strictly adhere to the provided context from the **Context**; DO NOT invent, assume, or infer any information not explicitly stated.,→ - When multiple sources conflict, rely on those with higher evidence level (smaller number), higher image similarity, and higher anatomical structure match degree. ,→ ,→
-
[46]
Formatting & Language: - The response MUST be in the same language as the user query. - The response MUST utilize Markdown formatting for enhanced clarity and structure (e.g., headings, bold text, bullet points).,→ - The response should be presented in {response_type}
-
[47]
Do not include a caret (`^`) after opening square bracket (`[`).,→ - The Document Title in the citation must retain its original language
References Section Format: - The References section should be under heading:`### References` - Reference list entries should adhere to the format:` * [n] Document Title`. Do not include a caret (`^`) after opening square bracket (`[`).,→ - The Document Title in the citation must retain its original language. - Output each citation on an individual line - ...
-
[48]
Reference Section Example: ``` ### References - [1] Document Title One - [2] Document Title Two - [3] Document Title Three ```
-
[49]
discovery of a right breast mass for 1 month
Additional Instructions: {user_prompt} ---Context--- {context_data} 25/31 Table 2.Overview of the Comprehensive Pathology Evaluation Benchmark.The benchmark is categorized into three categories. The public datasets represent strictly the test subsets evaluated. The WSI-level tasks are derived entirely from private hospital cohorts, including a rare prospe...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.