TICoder: A Repository-Level Code Generation Framework with Test-Driven Planning and Implementation-Aware Reuse
Pith reviewed 2026-06-27 19:32 UTC · model grok-4.3
The pith
TICoder improves repository-level code generation by 11.52% on average by adding test-driven iterative planning and implementation-aware reuse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
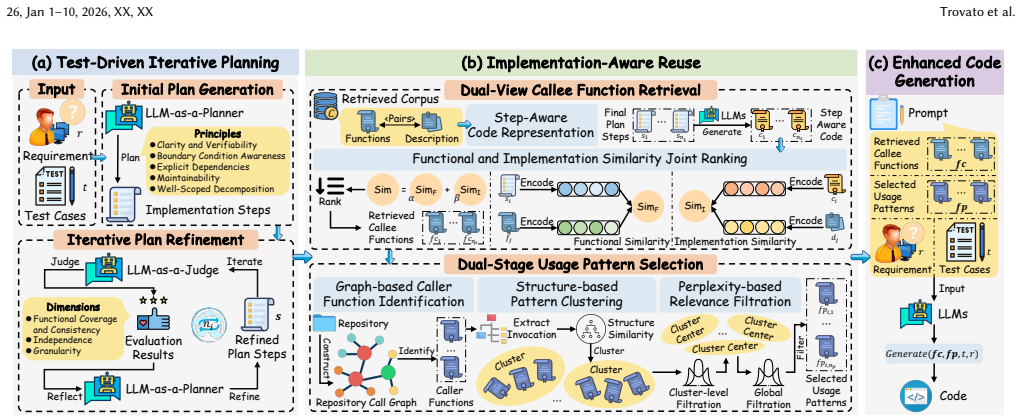
TICoder introduces a test-driven iterative planning mechanism that leverages test cases as behavioral specifications to refine implementation steps, together with an implementation-aware code reuse strategy that retrieves potential callee functions using dual-view similarity capturing both functional and implementation aspects and then identifies relevant usage patterns through a dual-stage selection strategy combining structure-based clustering and perplexity-based filtering.
What carries the argument
Test-driven iterative planning mechanism combined with dual-view similarity retrieval and dual-stage selection for implementation-aware code reuse.
If this is right
- Generated plans align more closely with the behaviors specified by the provided test cases.
- Functions retrieved from the repository are more likely to be integrated correctly because both purpose and implementation details are considered.
- Performance on repository-level code generation benchmarks rises by an average of 11.52% across the tested LLMs compared with prior retrieval-plus-planning methods.
- Complex inter-function dependencies become easier to satisfy because reuse decisions are guided by actual usage patterns inside the repository.
Where Pith is reading between the lines
- The same test-driven refinement loop could be applied to other LLM tasks that require step-by-step plans, such as API composition or test-case generation itself.
- If high-quality test cases are unavailable, the planning component would lose its main signal and the reported gains would likely shrink.
- Dual-view similarity retrieval might extend to other software-engineering retrieval problems where both intent and structural patterns matter.
Load-bearing premise
The approach assumes that test cases serve as reliable behavioral specifications that can iteratively refine plans and that the dual-view similarity plus dual-stage selection will surface genuinely reusable implementation patterns.
What would settle it
A controlled run on the same benchmarks with the test-driven planning loop removed or replaced by non-test planning, checking whether the 11.52% average gain disappears.
Figures

read the original abstract
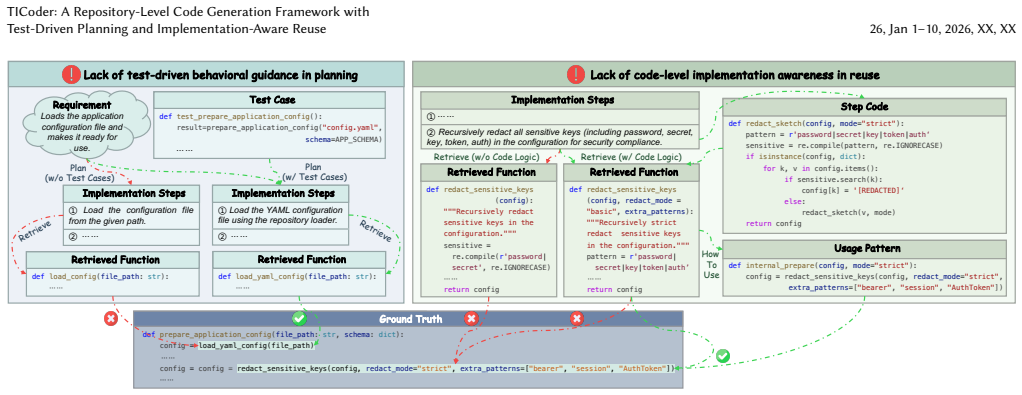
Repository-level code generation with Large Language Models (LLMs) remains challenging, primarily due to complex dependencies and limited context windows. Recent approaches adopt retrieval-augmented generation (RAG) and the planning mechanism to reuse potential callee functions in the repository. However, these approaches often suffer from two limitations: lack of test-driven behavioral guidance during planning and overlooking the implementation logic embedded in repository code during reuse. As a result, generated plans may not align with expected behaviors, and retrieved functions may not be effectively reused. In this paper, we propose TICoder, a novel repository-level code generation framework that improves both planning and reuse. TICoder introduces a test-driven iterative planning mechanism that leverages test cases as behavioral specifications to refine implementation steps. Furthermore, TICoder employs an implementation-aware code reuse strategy, which retrieves potential callee functions using a dual-view similarity that captures both functional and implementation aspects. We then identify relevant usage patterns through a dual-stage selection strategy, combining structure-based clustering and perplexity-based filtering. We conduct extensive experiments on widely used repository-level code generation benchmarks with various LLMs. Experimental results demonstrate that TICoder outperforms state-of-the-art (SOTA) methods, achieving an average improvement of 11.52%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TICoder, a repository-level code generation framework for LLMs. It addresses limitations in prior RAG and planning methods by introducing test-driven iterative planning that uses test cases as behavioral specifications to refine steps, and an implementation-aware reuse strategy that retrieves callee functions via dual-view similarity (functional and implementation aspects) followed by dual-stage selection (structure-based clustering and perplexity-based filtering). Experiments on standard benchmarks with multiple LLMs are reported to yield an average 11.52% improvement over SOTA baselines.
Significance. If the performance gains are robustly demonstrated and causally linked to the two proposed mechanisms via appropriate controls, the work could meaningfully extend RAG-based repository code generation by incorporating behavioral test guidance during planning and implementation-level signals during reuse. These ideas build directly on existing retrieval and planning literature in software engineering and could inform future systems that treat tests as first-class planning artifacts.
major comments (2)
- [Abstract and Experimental Results section] Abstract and Experimental Results section: The central claim of an average 11.52% improvement over SOTA is presented without any mention of ablation studies, component-wise breakdowns, statistical significance tests, variance across runs, or controls that isolate the contribution of test-driven iterative planning versus the dual-view/dual-stage reuse strategy. This absence directly undermines attribution of the reported gains to the novel mechanisms rather than prompt variations, model differences, or baseline RAG enhancements.
- [Methodology (planning and reuse subsections)] Methodology (planning and reuse subsections): The assumption that test cases reliably serve as behavioral specifications for iterative plan refinement, and that dual-view similarity plus dual-stage selection will surface genuinely reusable implementation patterns, is stated without empirical isolation or counter-example analysis. If these assumptions fail on the evaluated benchmarks, the headline performance delta cannot be confidently linked to the proposed components.
minor comments (1)
- [Abstract] The abstract would be strengthened by naming the specific benchmarks, metrics (e.g., pass@k), and SOTA baselines used to compute the 11.52% figure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the empirical attribution of our results. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and Experimental Results section] Abstract and Experimental Results section: The central claim of an average 11.52% improvement over SOTA is presented without any mention of ablation studies, component-wise breakdowns, statistical significance tests, variance across runs, or controls that isolate the contribution of test-driven iterative planning versus the dual-view/dual-stage reuse strategy. This absence directly undermines attribution of the reported gains to the novel mechanisms rather than prompt variations, model differences, or baseline RAG enhancements.
Authors: We agree that the abstract and experimental results section do not include ablation studies, component-wise breakdowns, statistical significance tests, variance across runs, or explicit controls isolating the two proposed mechanisms. The reported 11.52% figure reflects end-to-end comparisons against baselines. In the revised manuscript we will add a dedicated ablation subsection, report run-to-run variance, include statistical significance tests, and provide controls that separate the contribution of test-driven iterative planning from the dual-view/dual-stage reuse strategy. revision: yes
-
Referee: [Methodology (planning and reuse subsections)] Methodology (planning and reuse subsections): The assumption that test cases reliably serve as behavioral specifications for iterative plan refinement, and that dual-view similarity plus dual-stage selection will surface genuinely reusable implementation patterns, is stated without empirical isolation or counter-example analysis. If these assumptions fail on the evaluated benchmarks, the headline performance delta cannot be confidently linked to the proposed components.
Authors: We acknowledge that the methodology subsections present the design rationale without dedicated empirical isolation of the assumptions or counter-example analysis. The current results show overall gains but do not directly demonstrate where the assumptions hold or break. We will add targeted analysis in the revised version, including counter-examples on the evaluated benchmarks, to better link the assumptions to the observed performance improvements. revision: yes
Circularity Check
No circularity: empirical performance claim rests on benchmark evaluation, not self-referential derivation
full rationale
The paper describes an engineering framework (test-driven iterative planning plus dual-view/dual-stage reuse) and reports an empirical 11.52% average improvement on repository-level code generation benchmarks. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim is an experimental delta, not a derivation that reduces to its own inputs by construction; therefore the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Maha Alharbi and Mohammad Alshayeb. 2026. Automatic Code Generation Techniques: A Systematic Literature Review.Automated Software Engineering33, 1 (2026), 4
2026
-
[3]
Ingeol Baek, Hwan Chang, ByeongJeong Kim, Jimin Lee, and Hwanhee Lee. 2025. Probing-RAG: Self-Probing to Guide Language Models in Selective Document Retrieval. InFindings of the Association for Computational Linguistics: NAACL 2025, Luis Chiruzzo, Alan Ritter, and Lu Wang (Eds.). 3287–3304
2025
-
[4]
Ramakrishna Bairi, Atharv Sonwane, Aditya Kanade, Vageesh D C, Arun Iyer, Suresh Parthasarathy, Sriram Rajamani, Balasubramanyan Ashok, and Shashank Shet. 2024. Codeplan: Repository-level coding using llms and planning.Proceed- ings of the ACM on Software Engineering1, FSE (2024), 675–698
2024
-
[5]
Zhangqian Bi, Yao Wan, Zheng Wang, Hongyu Zhang, Batu Guan, Fangxin Lu, Zili Zhang, Yulei Sui, Hai Jin, and Xuanhua Shi. 2024. Iterative Refinement of Project-Level Code Context for Precise Code Generation with Compiler Feedback. InFindings of the Association for Computational Linguistics: ACL 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). 2336–2353
2024
-
[6]
Yujia Chen, Yang Ye, Zhongqi Li, Yuchi Ma, and Cuiyun Gao. 2025. Smaller but Better: Self-Paced Knowledge Distillation for Lightweight yet Effective LCMs. Proceedings of the ACM on Software Engineering2, FSE (2025), 3057–3080
2025
- [7]
-
[8]
Yangruibo Ding, Zijian Wang, Wasi Ahmad, Murali Krishna Ramanathan, Ramesh Nallapati, Parminder Bhatia, Dan Roth, and Bing Xiang. 2024. Cocomic: Code completion by jointly modeling in-file and cross-file context. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 3433–3445
2024
- [9]
- [10]
-
[11]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
2024
-
[12]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [13]
-
[14]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A survey on large language models for code generation.arXiv preprint arXiv:2406.00515 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Xue Jiang, Yihong Dong, Lecheng Wang, Zheng Fang, Qiwei Shang, Ge Li, Zhi Jin, and Wenpin Jiao. 2024. Self-Planning Code Generation with Large Language Models.ACM Trans. Softw. Eng. Methodol.33, 7, Article 182 (2024), 30 pages
2024
-
[16]
Jia Li, Ge Li, Yunfei Zhao, Yongmin Li, Huanyu Liu, Hao Zhu, Lecheng Wang, Kaibo Liu, Zheng Fang, Lanshen Wang, et al . 2024. Deveval: A manually- annotated code generation benchmark aligned with real-world code repositories. InFindings of the Association for Computational Linguistics: ACL 2024. 3603–3614
2024
-
[17]
Dianshu Liao, Shidong Pan, Xiaoyu Sun, Xiaoxue Ren, Qing Huang, Zhenchang Xing, Huan Jin, and Qinying Li. 2024. A 3-CodGen: A Repository-Level Code Generation Framework for Code Reuse With Local-A ware, Global-A ware, and Third-Party-Library-A ware.IEEE Transactions on Software Engineering50, 12 (2024), 3369–3384
2024
-
[18]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Wei Liu, Ailun Yu, Daoguang Zan, Bo Shen, Wei Zhang, Haiyan Zhao, Zhi Jin, and Qianxiang Wang. 2024. GraphCoder: Enhancing Repository-Level Code Completion via Coarse-to-fine Retrieval Based on Code Context Graph. InPro- ceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 570–581
2024
- [20]
-
[21]
Noble Saji Mathews and Meiyappan Nagappan. 2024. Test-Driven Develop- ment and LLM-based Code Generation. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1583–1594
2024
-
[22]
Fangwen Mu, Lin Shi, Song Wang, Zhuohao Yu, Binquan Zhang, ChenXue Wang, Shichao Liu, and Qing Wang. 2024. Clarifygpt: A framework for enhancing llm-based code generation via requirements clarification.Proceedings of the ACM on Software Engineering1, FSE (2024), 2332–2354
2024
-
[23]
Amirkia Rafiei Oskooei, Selcan Yukcu, Mehmet Cevheri Bozoglan, and Mehmet S Aktas. 2025. Repository-Level Code Understanding by LLMs via Hierarchical Summarization: Improving Code Search and Bug Localization. InInternational Conference on Computational Science and Its Applications. 88–105
2025
- [24]
-
[25]
Zhiyuan Pan, Xing Hu, Xin Xia, and Xiaohu Yang. 2025. CATCODER: Repository- Level Code Generation with Relevant Code and Type Context.ACM Transactions on Software Engineering and Methodology(2025)
2025
-
[26]
Huy N Phan, Hoang N Phan, Tien N Nguyen, and Nghi DQ Bui. 2025. Repohyper: Search-expand-refine on semantic graphs for repository-level code completion. In2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge). IEEE, 14–25
2025
-
[27]
Sanyogita Piya and Allison Sullivan. 2024. LLM4TDD: Best Practices for Test Driven Development Using Large Language Models. InProceedings of the 1st International Workshop on Large Language Models for Code. 14–21
2024
-
[28]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, Vol. 36. 8634–8652
2023
-
[29]
Yicheng Tao, Yao Qin, and Yepang Liu. 2025. Retrieval-Augmented Code Gen- eration: A Survey with Focus on Repository-Level Approaches.arXiv preprint arXiv:2510.04905(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Chong Wang, Jian Zhang, Yebo Feng, Tianlin Li, Weisong Sun, Yang Liu, and Xin Peng. 2025. Teaching code llms to use autocompletion tools in repository-level code generation.ACM Transactions on Software Engineering and Methodology34, 7 (2025), 1–27
2025
-
[31]
Xin Wang, Xiao Liu, Pingyi Zhou, Qixia Liu, Jin Liu, Hao Wu, and Xiaohui Cui. 2023. Test-Driven Multi-Task Learning with Functionally Equivalent Code 26, Jan 1–10, 2026, XX, XX Trovato et al. Transformation for Neural Code Generation. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering (ASE ’22). Article 188, 6 pages
2023
-
[32]
Yanlin Wang, Yanli Wang, Daya Guo, Jiachi Chen, Ruikai Zhang, Yuchi Ma, and Zibin Zheng. 2025. RLCoder: Reinforcement Learning for Repository-Level Code Completion. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 1140–1152
2025
- [33]
-
[34]
Di Wu, Wasi Uddin Ahmad, Dejiao Zhang, Murali Krishna Ramanathan, and Xiaofei Ma. 2024. REPOFORMER: selective retrieval for repository-level code completion. InProceedings of the 41st International Conference on Machine Learn- ing. Article 2183, 21 pages
2024
-
[35]
Hao Yu, Bo Shen, Dezhi Ran, Jiaxin Zhang, Qi Zhang, Yuchi Ma, Guangtai Liang, Ying Li, Qianxiang Wang, and Tao Xie. 2024. Codereval: A benchmark of prag- matic code generation with generative pre-trained models. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. 1–12
2024
-
[36]
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. 2023. RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2471–2484
2023
-
[37]
Zibin Zheng, Kaiwen Ning, Qingyuan Zhong, Jiachi Chen, Wenqing Chen, Lianghong Guo, Weicheng Wang, and Yanlin Wang. 2025. Towards an under- standing of large language models in software engineering tasks.Empirical Software Engineering30, 2 (2025), 50. Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.