AttentionCap: Transformer Based Capacitance Matrix Learning Toward Full-Chip Extraction
Pith reviewed 2026-06-27 20:21 UTC · model grok-4.3
The pith
A Transformer learns chip capacitance matrices from synthetic data and generalizes to real multi-node designs with under 4 percent error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
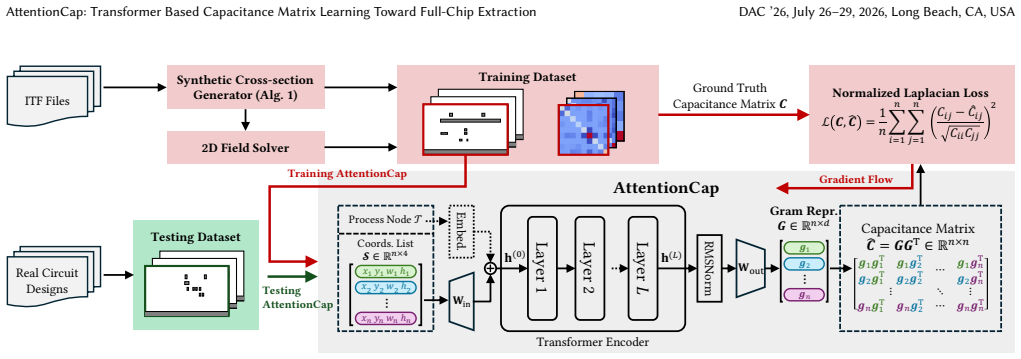
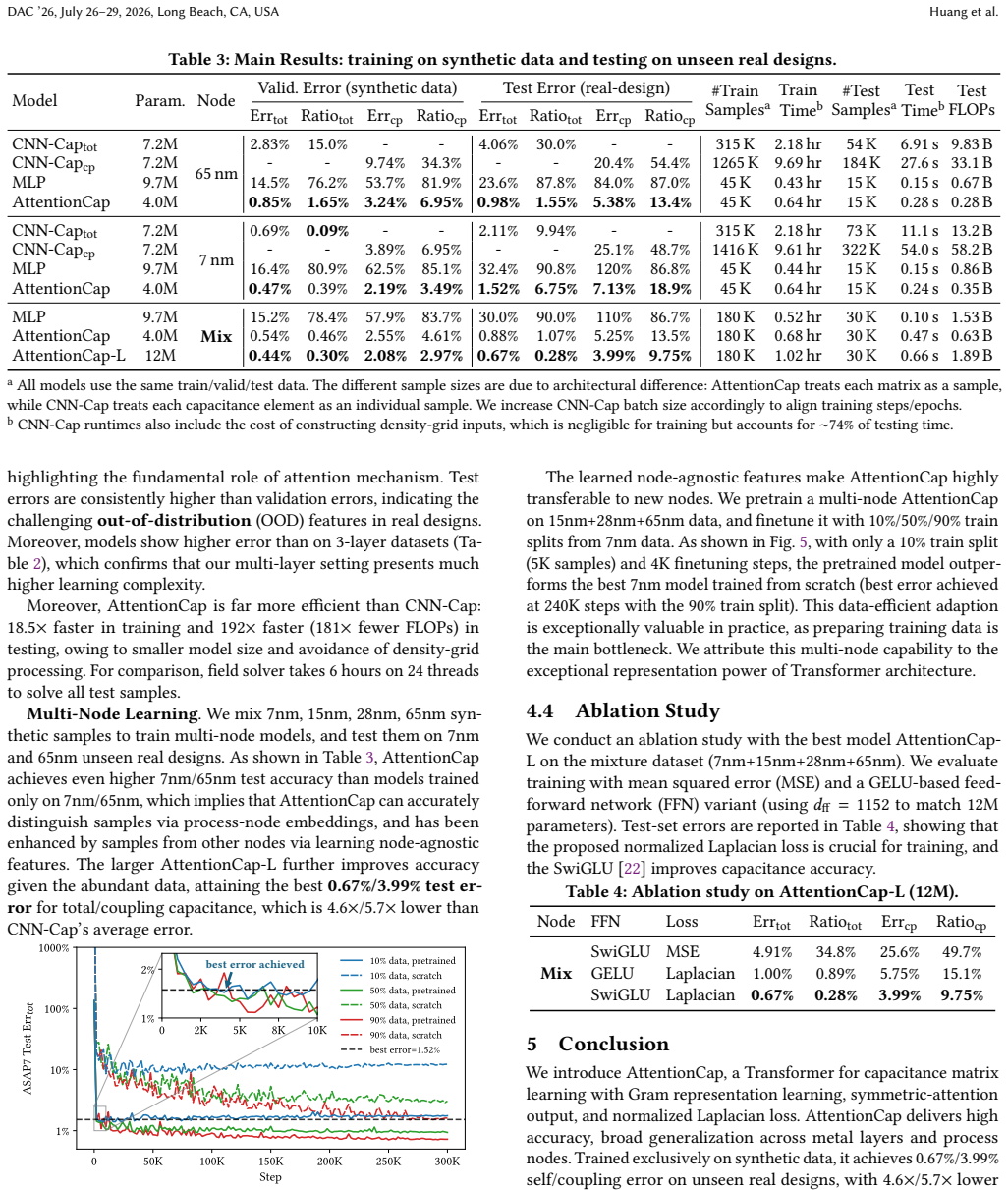
AttentionCap, a Transformer customized with Gram representation, physics-aligned symmetric-attention output, normalized Laplacian loss, and process-node embedding, attains 0.67 percent self-capacitance and 3.99 percent coupling-capacitance error on unseen real multi-layer multi-node designs after training on synthetic data, outperforming the CNN-Cap baseline by 4.6 times and 5.7 times in those respective errors while delivering 192 times faster inference and accurate transfer to an unseen node using only 5K samples and 4K fine-tuning steps.
What carries the argument
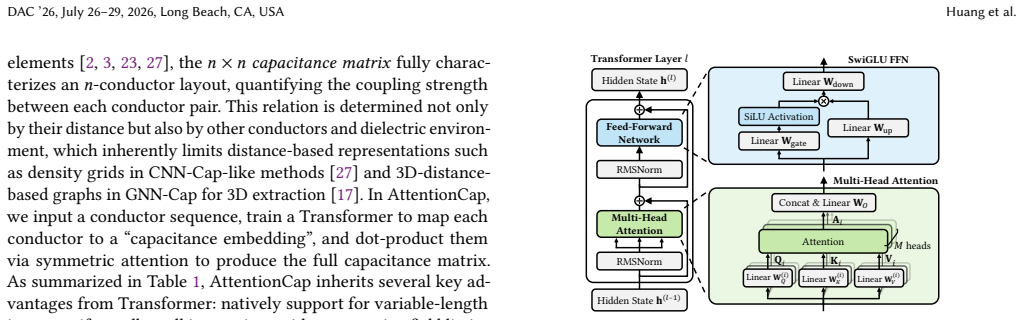
Symmetric-attention output layer together with normalized Laplacian loss that enforces the physical symmetry and positive-definiteness properties of the capacitance matrix inside the Transformer architecture.
If this is right
- Full-chip capacitance extraction can be performed with deep learning at speeds that support large-scale EDA flows.
- A single pretrained model can be adapted to new manufacturing nodes without collecting large new labeled datasets.
- Downstream timing and power analysis tools receive lower-error parasitic data at lower computational cost.
- Multi-layer and multi-node settings become practical without hand-crafted rules per layer combination.
Where Pith is reading between the lines
- The same attention-plus-physics-loss pattern could be tested on related parasitic extraction tasks such as inductance or resistance matrices.
- If transfer works across nodes, the approach may reduce the frequency of full electromagnetic field-solver runs during technology development.
- Embedding additional physical quantities such as temperature or frequency dependence could extend the model beyond static capacitance.
Load-bearing premise
Synthetic training layouts capture enough of the geometric and material variation present in real chip designs across different process nodes.
What would settle it
Run the pretrained model on a fresh collection of real layouts from a process node never seen during pretraining or fine-tuning and measure whether self-capacitance error stays below 1 percent and coupling error stays below 4 percent.
Figures


read the original abstract
As capacitance extraction accuracy of rule-based pattern matching becomes difficult to sustain at advanced nodes, a growing trend emerges to develop deep-learning-based 2D capacitance models. However, existing MLP- and CNN-based methods constrain their input to fixed metal-layer combinations in a specific process node, limiting their usability in practice. Recognizing the inherent similarity between capacitance matrix and the prevailing attention mechanism, we propose AttentionCap, a customized Transformer for capacitance matrix learning, with a Gram representation framework, a physics-aligned symmetric-attention output layer, and a novel normalized Laplacian loss. We also introduce a process-node embedding to enable multi-node learning. Trained on synthetic data, AttentionCap attains 0.67\%/3.99\% self/coupling-capacitance error on unseen real designs under a multi-layer and multi-node setting, surpassing the CNN-Cap baseline with 4.6$\times$/5.7$\times$ lower self/coupling error and 192$\times$ faster inference speed. A pretrained AttentionCap accurately transfers to an unseen node with only 5K samples and 4K finetuning steps. With sufficient accuracy on unseen real designs and strong transferability to new process nodes, AttentionCap offers highly practical value for modern EDA workflows. Code and data are available at https://github.com/THU-numbda/AttentionCap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AttentionCap, a Transformer-based model for learning full-chip capacitance matrices. It introduces a Gram representation framework, physics-aligned symmetric-attention output layer, normalized Laplacian loss, and process-node embedding to support multi-layer and multi-node settings. Trained on synthetic data, the model reports 0.67%/3.99% self/coupling capacitance error on unseen real designs (outperforming CNN-Cap by 4.6×/5.7× with 192× faster inference) and demonstrates transfer to an unseen process node using only 5K samples and 4K finetuning steps.
Significance. If the synthetic-to-real generalization holds, the work provides a practical advance for EDA capacitance extraction by enabling accurate, fast inference across process nodes without per-node retraining from scratch. The availability of code and data strengthens reproducibility.
major comments (2)
- [abstract and §3 (data generation)] The central claim of 0.67%/3.99% error on unseen real designs (abstract) rests on the assumption that the synthetic training distribution matches the statistics of real multi-layer, multi-node layouts. No section details the synthetic generator's coverage of long-range coupling, irregular density gradients, or node-specific via/metal-stack variations; without this, the reported errors and 5K-sample transfer results are conditional on test designs lying inside the synthetic manifold.
- [abstract and transfer experiment section] The multi-node transfer experiment (abstract) uses a pretrained model with process-node embedding, but lacks explicit validation that the embedding dimensions capture node-specific variations rather than overfitting to the training nodes. The claim that it 'accurately transfers' with 5K samples requires quantitative comparison to training from scratch on the target node.
minor comments (2)
- [method section] Notation for the normalized Laplacian loss should be defined with an equation number for clarity.
- [figures] Figure captions should explicitly state whether error metrics are mean or median and over which capacitance types.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we address each major comment point by point, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [abstract and §3 (data generation)] The central claim of 0.67%/3.99% error on unseen real designs (abstract) rests on the assumption that the synthetic training distribution matches the statistics of real multi-layer, multi-node layouts. No section details the synthetic generator's coverage of long-range coupling, irregular density gradients, or node-specific via/metal-stack variations; without this, the reported errors and 5K-sample transfer results are conditional on test designs lying inside the synthetic manifold.
Authors: We agree that the current §3 description does not provide sufficient quantitative detail on the synthetic generator's coverage of long-range coupling, density gradients, and node-specific variations. In the revised manuscript we will expand §3 with a dedicated subsection that reports statistics on coupling distance distributions, density gradient histograms, and via/metal-stack configurations in the generated data, together with direct comparisons to the statistics of the real test designs. This addition will clarify the extent to which the reported errors rest on the synthetic manifold. revision: yes
-
Referee: [abstract and transfer experiment section] The multi-node transfer experiment (abstract) uses a pretrained model with process-node embedding, but lacks explicit validation that the embedding dimensions capture node-specific variations rather than overfitting to the training nodes. The claim that it 'accurately transfers' with 5K samples requires quantitative comparison to training from scratch on the target node.
Authors: We concur that an explicit comparison to training from scratch on the target node with the same 5K samples, as well as validation that the process-node embedding captures node-specific features, would strengthen the transfer claims. In the revised version we will add (i) a side-by-side accuracy comparison of the fine-tuned pretrained model versus a model trained from scratch on the target node and (ii) an analysis of the learned embeddings (e.g., pairwise distances or ablation removing the embedding) to demonstrate that they encode node-specific information rather than overfitting. revision: yes
Circularity Check
No circularity; training on synthetic data and evaluation on independent real designs are externally verifiable.
full rationale
The paper trains a Transformer model (AttentionCap) on synthetic layouts and reports quantitative errors (0.67%/3.99% self/coupling) plus transfer metrics on unseen real chip designs. These benchmarks are measured against external ground truth and are not derived from the model's own fitted parameters or self-citations. No equations reduce by construction to inputs, no uniqueness theorems are imported from prior author work, and the central claims rest on standard supervised learning plus independent test sets rather than self-referential definitions.
Axiom & Free-Parameter Ledger
free parameters (1)
- process-node embedding dimensions
axioms (1)
- domain assumption The capacitance matrix is symmetric and positive semi-definite as per physics.
Reference graph
Works this paper leans on
-
[1]
CNN-Cap Official Implmentation
2023. CNN-Cap Official Implmentation. https://github.com/ydc123/CNNCap
2023
-
[2]
Mohamed Saleh Abouelyazid, Sherif Hammouda, and Yehea Ismail. 2022. Accuracy-Based Hybrid Parasitic Capacitance Extraction Using Rule-Based, Neural-Networks, and Field-Solver Methods.IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst.41, 12 (2022), 5681–5694
2022
-
[3]
Mohamed Saleh Abouelyazid, Sherif Hammouda, and Yehea Ismail. 2022. Fast and accurate machine learning compact models for interconnect parasitic ca- pacitances considering systematic process variations.IEEE Access10 (2022), 7533–7553
2022
-
[4]
Kirti Bhanushali and W Rhett Davis. 2015. FreePDK15: An open-source predic- tive process design kit for 15nm FinFET technology. InProceedings of the 2015 Symposium on International Symposium on Physical Design. 165–170
2015
-
[5]
James Hsueh-Chung Chen, Theodorus E Standaert, Emre Alptekin, Terry A Spooner, and Vamsi Paruchuri. 2014. Interconnect performance and scaling strategy at 7 nm node. InIEEE International Interconnect Technology Conference. 93–96
2014
-
[6]
Giordano Cicchetti, Eleonora Grassucci, Luigi Sigillo, and Danilo Comminiello
-
[7]
InInterna- tional Conference on Learning Representations (ICLR)
Gramian Multimodal Representation Learning and Alignment. InInterna- tional Conference on Learning Representations (ICLR)
-
[8]
Lawrence T Clark, Vinay Vashishtha, Lucian Shifren, Aditya Gujja, Saurabh Sinha, Brian Cline, Chandarasekaran Ramamurthy, and Greg Yeric. 2016. ASAP7: A 7-nm finFET predictive process design kit.Microelectronics Journal53 (2016), 105–115
2016
-
[9]
Kahng, David Noice, Nagesh Shirali, and Steve H.- C
Jason Cong, Lei He, Andrew B. Kahng, David Noice, Nagesh Shirali, and Steve H.- C. Yen. 1997. Analysis and justification of a simple, practical 2 1/2-D capacitance extraction methodology. InDesign Automation Conference (DAC). 627–632
1997
-
[10]
Martin Courtois, Malte Ostendorff, Leonhard Hennig, and Georg Rehm. 2024. Symmetric Dot-Product Attention for Efficient Training of BERT Language Mod- els. InFindings of the Association for Computational Linguistics (ACL). 8002–8011
2024
-
[11]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Conference of the North American Chapter of the Association for Computational Linguistics (NAACL). 4171–4186
2019
-
[12]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInternational Conference on Learning Representations (ICLR)
2021
-
[13]
Horn and Charles R
Roger A. Horn and Charles R. Johnson. 2013. Positive Definite and Semidefi- nite Matrices. InMatrix Analysis, Second Edition. Cambridge University Press, Chapter 7
2013
-
[14]
Jiechen Huang, Shuailong Liu, and Wenjian Yu. 2025. A Parallel Floating Random Walk Solver for Reproducible and Reliable Capacitance Extraction. In2025 Design, Automation & Test in Europe Conference (DATE). IEEE, 1–7
2025
-
[15]
Jiechen Huang and Wenjian Yu. 2024. Enhancing 3-D Random Walk Capacitance Solver with Analytic Surface Green’s Functions of Transition Cubes. InProc. DAC
2024
-
[16]
Doyun Kim, Jaemin Park, Youngmin Oh, and Bosun Hwang. 2024. TraceFormer: s-parameter prediction framework for PCB traces based on graph transformer. InACM/IEEE Design Automation Conference (DAC)
2024
-
[17]
Zhixing Li and Weiping Shi. 2020. Layout capacitance extraction using automatic pre-characterization and machine learning. InInternational Symposium on Quality Electronic Design (ISQED). 457–464
2020
-
[18]
Lihao Liu, Fan Yang, Li Shang, and Xuan Zeng. 2023. GNN-Cap: Chip-Scale interconnect capacitance extraction using graph neural network.IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst.43, 4 (2023), 1206–1217
2023
-
[19]
Yaoyao Ma, Xiaoyu Xu, Shuai Yan, Yaxing Zhou, Tianyu Zheng, Zhuoxiang Ren, and Lan Chen. 2023. Extraction of interconnect parasitic capacitance matrix based on deep neural network.Electronics12, 6 (2023), 1440
2023
-
[20]
J.C. Maxwell. 1873.A Treatise on Electricity and Magnetism
-
[21]
Russell Merris. 1994. Laplacian matrices of graphs: a survey.Linear algebra and its applications197 (1994), 143–176
1994
-
[22]
OpenAI. 2023. GPT-4 technical report.arXiv preprint arXiv:2303.08774(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Noam Shazeer. 2020. GLU variants improve transformer.arXiv preprint arXiv:2002.05202(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[24]
Jiun-Cheng Tsai, Hsuan-Ming Huang, Wei-Min Hsu, Pei-Ting Lee, Jen-Hang Yang, Heng-Liang Huang, Yen-Ju Su, and Charles H-P Wen. 2025. ResCap: Fast-yet-Accurate Capacitance Extraction for Standard Cell Design by Physics- Guided Machine Learning. InAsia and South Pacific Design Automation Conference (ASPDAC). 1243–1250
2025
-
[25]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in Neural Information Processing Systems (NeurIPS)30 (2017)
2017
-
[26]
Liangjian Wen, Yi Zhu, Lei Ye, Guojin Chen, Bei Yu, Jianzhuang Liu, and Chunjing Xu. 2022. Layoutransformer: Generating layout patterns with transformer via sequential pattern modeling. InIEEE/ACM International Conference on Computer- Aided Design (ICCAD)
2022
-
[27]
Dingcheng Yang, Haoyuan Li, Wenjian Yu, Yuanbo Guo, and Wenjie Liang. 2023. CNN-Cap: Effective convolutional neural network-based capacitance models for interconnect capacitance extraction.ACM Transactions on Design Automation of Electronic Systems28, 4 (2023), 1–22
2023
-
[28]
Dingcheng Yang, Wenjian Yu, Yuanbo Guo, and Wenjie Liang. 2021. CNN-Cap: Effective convolutional neural network based capacitance models for full-chip parasitic extraction. InIEEE/ACM International Conference On Computer Aided Design (ICCAD)
2021
-
[29]
Wenjian Yu, Chao Hu, and Wangyang Zhang. 2009. Variational capacitance extraction of on-chip interconnects based on continuous surface model. InPro- ceedings of the 46th Annual Design Automation Conference. 758–763
2009
-
[30]
Wenjian Yu, Shan Shen, Dingcheng Yang, Haoyuan Li, Jiechen Huang, and Chun- yan Pei. 2025. Deep Learning Inspired Capacitance Extraction Techniques. In Asia and South Pacific Design Automation Conference (ASPDAC). 106–112
2025
-
[31]
W. Yu, M. Song, and M. Yang. 2021. Advancements and challenges on parasitic extraction for advanced process technologies. InAsia and South Pacific Design Automation Conference (ASPDAC). 841–846
2021
-
[32]
Ziwei Yu, Shuai Yan, Yaxing Zhou, Xiaoyu Xu, and Zhuoxiang Ren. 2025. AIL DNN: Modeling of IC Interconnect Parasitic Capacitances Based on Adaptive Incremental Learning.IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst.(2025)
2025
-
[33]
Biao Zhang and Rico Sennrich. 2019. Root mean square layer normalization. Advances in neural information processing systems32 (2019)
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.