Empowering Feed-Forward Reconstruction Models with Metric Scale via Satellite Images
Pith reviewed 2026-06-27 19:40 UTC · model grok-4.3
The pith
Satellite imagery supplies the missing global metric scale to feed-forward 3D reconstruction models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
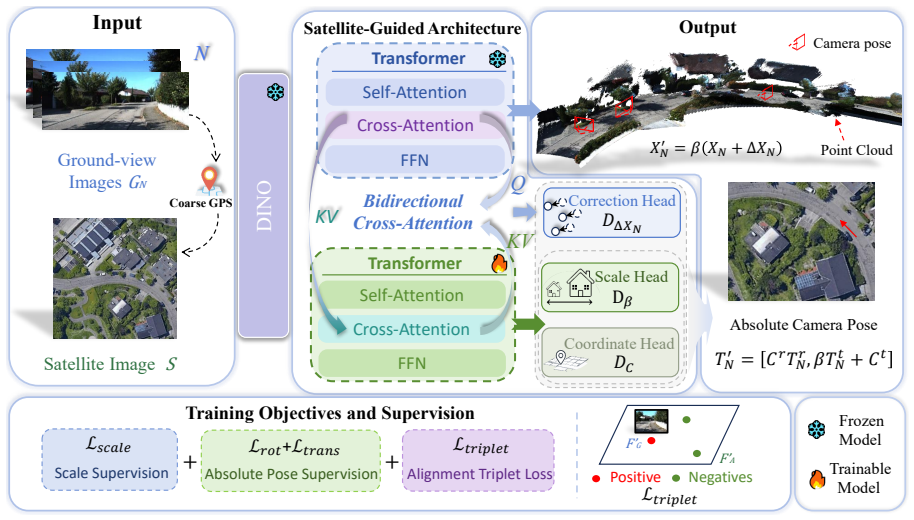
By retrieving a local satellite patch from a coarse pose and enforcing consistency with the feed-forward reconstruction output through bidirectional cross-view interaction, the model infers absolute scale, refines scene geometry, and produces camera poses in a metric coordinate frame without needing large-scale metric annotations or precise calibration.
What carries the argument
Bidirectional cross-view interaction between the feed-forward reconstruction backbone and the retrieved satellite patch that enforces geometric consistency to resolve scale.
If this is right
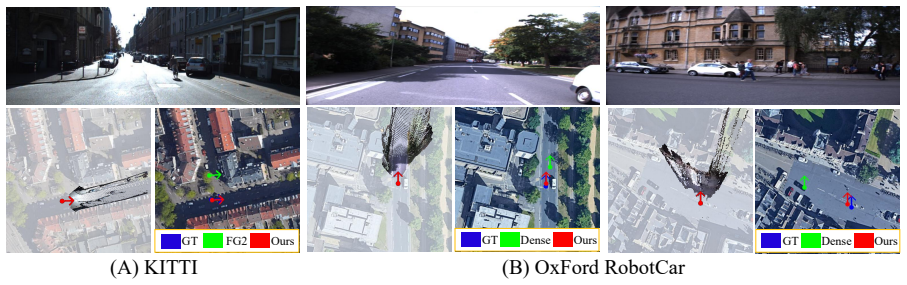
- Metric depth estimation improves on KITTI, nuScenes, and Oxford RobotCar.
- Multi-view point-cloud reconstruction gains accuracy in a metric frame.
- Cross-view camera localization performance increases while keeping strong generalization.
- The same backbone can now produce metric outputs across different datasets and regions without retraining on metric labels.
- Applications that need absolute distances become feasible without costly calibration or annotation pipelines.
Where Pith is reading between the lines
- The framework could be tested with other overhead references such as aerial or drone imagery when satellite coverage is sparse.
- In rapidly changing urban areas the method may need periodic satellite updates to avoid drift from outdated geometry.
- Combining the satellite consistency loss with additional sensors could further stabilize scale in low-texture or night scenes.
Load-bearing premise
The method needs a coarse camera pose to fetch the right satellite patch and assumes the satellite image supplies a reliable, up-to-date match to the ground-level scene geometry.
What would settle it
Run the model on a scene where the retrieved satellite patch is deliberately taken from a different geographic location or an outdated capture and check whether metric scale, depth accuracy, or pose estimates collapse relative to ground truth.
Figures



read the original abstract
Feed-forward 3D reconstruction models have recently shown strong generalization across diverse scenes, yet most of them recover geometry only up to an unknown global scale. This scale ambiguity limits their use in applications that require metric understanding of the environment. Existing metric reconstruction methods commonly rely on large-scale metric annotations or accurate camera calibration, both of which are costly or unreliable in many real-world settings. We propose a satellite-guided framework for resolving scale ambiguity in feed-forward 3D reconstruction. The key idea is to use readily available satellite imagery as a global metric reference. Given a coarse camera pose, our method retrieves a local satellite patch and integrates it with a feed-forward reconstruction backbone through bidirectional cross-view interaction. By enforcing consistency between the reconstructed scene and the satellite reference, the model infers absolute scale, refines scene geometry, and estimates camera pose in a metric coordinate frame. Experiments on KITTI, nuScenes, and Oxford RobotCar show consistent improvements in metric depth estimation, multi-view point-cloud reconstruction, and cross-view camera localization, while preserving strong generalization across datasets and geographic regions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a satellite-guided framework to resolve scale ambiguity in feed-forward 3D reconstruction models. Given a coarse camera pose, it retrieves a local satellite patch as a global metric reference and integrates it with a feed-forward backbone via bidirectional cross-view interaction. Consistency enforcement between the reconstructed scene and satellite data is used to infer absolute scale, refine geometry, and estimate metric camera poses. Experiments on KITTI, nuScenes, and Oxford RobotCar report improvements in metric depth estimation, multi-view point-cloud reconstruction, and cross-view localization while preserving generalization.
Significance. If the consistency mechanism functions as described, the approach offers a practical route to metric-scale reconstruction that avoids costly metric annotations or precise calibration by leveraging ubiquitous satellite imagery, which could extend feed-forward models to applications requiring absolute scale such as robotics and mapping.
major comments (2)
- [Abstract and §3] Abstract and §3 (method overview): the central claim that consistency enforcement recovers absolute scale rests on retrieving a matching satellite patch, yet the manuscript provides no quantitative analysis of the required coarse-pose accuracy, sensitivity to pose error, or fallback when overlap fails due to temporal change or occlusion; this assumption is load-bearing because mismatch nullifies the metric reference signal.
- [§4] §4 (experiments): while improvements on KITTI, nuScenes, and Oxford RobotCar are reported, the evaluation does not include controlled tests of pose perturbation or geographic mismatch between ground and satellite views, leaving the robustness of the metric-scale claim unverified.
minor comments (2)
- [§3] Notation for the bidirectional cross-view interaction module should be defined explicitly with equations rather than prose description only.
- [Figures] Figure captions should state the exact satellite source and resolution used for each dataset to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of robustness in our satellite-guided approach. We address each major comment below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method overview): the central claim that consistency enforcement recovers absolute scale rests on retrieving a matching satellite patch, yet the manuscript provides no quantitative analysis of the required coarse-pose accuracy, sensitivity to pose error, or fallback when overlap fails due to temporal change or occlusion; this assumption is load-bearing because mismatch nullifies the metric reference signal.
Authors: We agree that the central claim depends on successful satellite patch retrieval and that the manuscript lacks explicit quantitative analysis of coarse-pose accuracy requirements, sensitivity to errors, and handling of mismatches (e.g., temporal change or occlusion). While the method description notes the use of a coarse pose and the experiments demonstrate gains on the evaluated datasets, we will add a dedicated sensitivity study in the revision. This will include controlled pose perturbations, performance curves under increasing error, and discussion of fallback mechanisms when overlap is insufficient. revision: yes
-
Referee: [§4] §4 (experiments): while improvements on KITTI, nuScenes, and Oxford RobotCar are reported, the evaluation does not include controlled tests of pose perturbation or geographic mismatch between ground and satellite views, leaving the robustness of the metric-scale claim unverified.
Authors: We acknowledge that the current experimental section reports improvements on the three datasets but does not include controlled tests for pose perturbation or geographic mismatch. These additional evaluations would better substantiate the robustness of the metric-scale recovery. We will incorporate such controlled experiments in the revised manuscript, including synthetic pose noise injection and tests across geographic regions with varying satellite-ground alignment. revision: yes
Circularity Check
No circularity; method relies on external satellite reference rather than internal fits or self-citations
full rationale
The paper proposes integrating external satellite imagery as a global metric reference with a feed-forward reconstruction backbone via bidirectional cross-view interaction and consistency enforcement. No equations, parameter fittings to data subsets, or self-citation chains are described in the provided text that would reduce the claimed metric scale inference to a tautology or renamed input. The approach is self-contained against external benchmarks (satellite data), with the central claim depending on the validity of the external reference rather than any self-definitional or fitted-input reduction. This is the normal honest finding for papers without visible internal circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Accurate 3-d reconstruc- tion under iot environments and its applications to augmented reality.IEEE Transactions on Industrial Informatics, 17(3):2090–2100, 2020
Mingwei Cao, Liping Zheng, Wei Jia, Huimin Lu, and Xiaoping Liu. Accurate 3-d reconstruc- tion under iot environments and its applications to augmented reality.IEEE Transactions on Industrial Informatics, 17(3):2090–2100, 2020
2090
-
[2]
Learning-based 3d reconstruction in autonomous driving: A comprehensive survey.IEEE Transactions on Intelligent Transportation Systems, 2025
Liewen Liao, Weihao Yan, Wang Xu, Ming Yang, Songan Zhang, and Hongtei Eric Tseng. Learning-based 3d reconstruction in autonomous driving: A comprehensive survey.IEEE Transactions on Intelligent Transportation Systems, 2025. 10
2025
-
[3]
A survey of embodied ai: From simulators to research tasks.IEEE Transactions on Emerging Topics in Computational Intelligence, 6(2):230–244, 2022
Jiafei Duan, Samson Yu, Hui Li Tan, Hongyuan Zhu, and Cheston Tan. A survey of embodied ai: From simulators to research tasks.IEEE Transactions on Emerging Topics in Computational Intelligence, 6(2):230–244, 2022
2022
-
[4]
A survey of structure from motion*.Acta Numerica, 26:305–364, 2017
Onur ¨Ozye¸ sil, Vladislav Voroninski, Ronen Basri, and Amit Singer. A survey of structure from motion*.Acta Numerica, 26:305–364, 2017
2017
-
[5]
Multi-view stereo: A tutorial.Foundations and Trends in Computer Graphics and Vision, 9(1-2):1–148, 2015
Yasutaka Furukawa and Carlos Hern´ andez. Multi-view stereo: A tutorial.Foundations and Trends in Computer Graphics and Vision, 9(1-2):1–148, 2015
2015
-
[6]
Mast3r-slam: Real-time dense slam with 3d reconstruction priors
Riku Murai, Eric Dexheimer, and Andrew J Davison. Mast3r-slam: Real-time dense slam with 3d reconstruction priors. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16695–16705, 2025
2025
-
[7]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[8]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. π3: Permutation-equivariant visual geometry learning.arXiv preprint arXiv:2507.13347, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Unidepthv2: Universal monocular metric depth estimation made simpler
Luigi Piccinelli, Christos Sakaridis, Yung-Hsu Yang, Mattia Segu, Siyuan Li, Wim Abbeloos, and Luc Van Gool. Unidepthv2: Universal monocular metric depth estimation made simpler. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[10]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details.arXiv preprint arXiv:2507.02546, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Chunpu Liu, Guanglei Yang, Wangmeng Zuo, and Tianyi Zan. Metricdepth: Enhancing monocular depth estimation with deep metric learning.arXiv preprint arXiv:2412.20390, 2024
-
[13]
Resolving scale ambiguity in multi-view 3d reconstruction using dual-pixel sensors
Kohei Ashida, Hiroaki Santo, Fumio Okura, and Yasuyuki Matsushita. Resolving scale ambiguity in multi-view 3d reconstruction using dual-pixel sensors. InEuropean Conference on Computer Vision, pages 162–178. Springer, 2024
2024
-
[14]
Convolutional cross-view pose estimation
Zimin Xia, Olaf Booij, and Julian FP Kooij. Convolutional cross-view pose estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5):3813–3831, 2023
2023
-
[15]
Pixelwise view selection for unstructured multi-view stereo
Johannes L Sch¨ onberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. InEuropean conference on computer vision, pages 501–518. Springer, 2016
2016
-
[16]
Structure from motion photogrammetry in forestry: A review.Current Forestry Reports, 5(3):155–168, 2019
Jakob Iglhaut, Carlos Cabo, Stefano Puliti, Livia Piermattei, James OConnor, and Jacque- line Rosette. Structure from motion photogrammetry in forestry: A review.Current Forestry Reports, 5(3):155–168, 2019
2019
-
[17]
Cambridge university press, 2003
Richard Hartley and Andrew Zisserman.Multiple view geometry in computer vision. Cambridge university press, 2003. 11
2003
-
[18]
Multi-view stereo revisited
Michael Goesele, Brian Curless, and Steven M Seitz. Multi-view stereo revisited. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), volume 2, pages 2402–2409. IEEE, 2006
2006
-
[19]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
2024
-
[20]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and J´ erˆ ome Revaud. Grounding image matching in 3d with mast3r. InEuropean conference on computer vision, pages 71–91. Springer, 2024
2024
-
[21]
Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
Brandon Smart, Chuanxia Zheng, Iro Laina, and Victor Adrian Prisacariu. Splatt3r: Zero- shot gaussian splatting from uncalibrated image pairs.arXiv preprint arXiv:2408.13912, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
3d reconstruction with spatial memory
Hengyi Wang and Lourdes Agapito. 3d reconstruction with spatial memory. In2025 International Conference on 3D Vision (3DV), pages 78–89. IEEE, 2025
2025
-
[23]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21924–21935, 2025
2025
-
[24]
Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views
Shangzhan Zhang, Jianyuan Wang, Yinghao Xu, Nan Xue, Christian Rupprecht, Xiaowei Zhou, Yujun Shen, and Gordon Wetzstein. Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21936–21947, 2025
2025
-
[25]
Block-Sparse Global Attention for Efficient Multi-View Geometry Transformers
Chung-Shien Brian Wang, Christian Schmidt, Jens Piekenbrinck, and Bastian Leibe. Faster vggt with block-sparse global attention.arXiv preprint arXiv:2509.07120, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Vigor: Cross-view image geo-localization beyond one-to-one retrieval
Sijie Zhu, Taojiannan Yang, and Chen Chen. Vigor: Cross-view image geo-localization beyond one-to-one retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3640–3649, 2021
2021
-
[27]
Geoclip: Clip-inspired alignment between locations and images for effective worldwide geo-localization.Advances in Neural Information Processing Systems, 36:8690–8701, 2023
Vicente Vivanco Cepeda, Gaurav Kumar Nayak, and Mubarak Shah. Geoclip: Clip-inspired alignment between locations and images for effective worldwide geo-localization.Advances in Neural Information Processing Systems, 36:8690–8701, 2023
2023
-
[28]
Gama: Cross-view video geo-localization
Shruti Vyas, Chen Chen, and Mubarak Shah. Gama: Cross-view video geo-localization. In European Conference on Computer Vision, pages 440–456. Springer, 2022
2022
-
[29]
Cvlnet: Cross-view semantic corre- spondence learning for video-based camera localization
Yujiao Shi, Xin Yu, Shan Wang, and Hongdong Li. Cvlnet: Cross-view semantic corre- spondence learning for video-based camera localization. InAsian Conference on Computer Vision, pages 123–141. Springer, 2022
2022
-
[30]
Where am i looking at? joint location and orientation estimation by cross-view matching
Yujiao Shi, Xin Yu, Dylan Campbell, and Hongdong Li. Where am i looking at? joint location and orientation estimation by cross-view matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4064–4072, 2020
2020
-
[31]
Beyond cross-view image retrieval: Highly accurate vehicle localization using satellite image
Yujiao Shi and Hongdong Li. Beyond cross-view image retrieval: Highly accurate vehicle localization using satellite image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17010–17020, 2022
2022
-
[32]
Boosting 3-dof ground-to-satellite camera localization accuracy via geometry-guided cross-view transformer
Yujiao Shi, Fei Wu, Akhil Perincherry, Ankit Vora, and Hongdong Li. Boosting 3-dof ground-to-satellite camera localization accuracy via geometry-guided cross-view transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21516–21526, 2023. 12
2023
-
[33]
Slicematch: Geometry-guided aggregation for cross-view pose estimation
Ted Lentsch, Zimin Xia, Holger Caesar, and Julian FP Kooij. Slicematch: Geometry-guided aggregation for cross-view pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17225–17234, 2023
2023
-
[34]
Geodistill: Geometry-guided self-distillation for weakly supervised cross-view localization
Shaowen Tong, Zimin Xia, Alexandre Alahi, Xuming He, and Yujiao Shi. Geodistill: Geometry-guided self-distillation for weakly supervised cross-view localization. InProceed- ings of the IEEE/CVF International Conference on Computer Vision, pages 25357–25366, 2025
2025
-
[35]
Learning dense flow field for highly-accurate cross-view camera localization.Advances in Neural Information Processing Systems, 36:70612–70625, 2023
Zhenbo Song, Jianfeng Lu, Yujiao Shi, et al. Learning dense flow field for highly-accurate cross-view camera localization.Advances in Neural Information Processing Systems, 36:70612–70625, 2023
2023
-
[36]
Fine-grained cross- view geo-localization using a correlation-aware homography estimator.Advances in Neural Information Processing Systems, 36:5301–5319, 2023
Xiaolong Wang, Runsen Xu, Zhuofan Cui, Zeyu Wan, and Yu Zhang. Fine-grained cross- view geo-localization using a correlation-aware homography estimator.Advances in Neural Information Processing Systems, 36:5301–5319, 2023
2023
-
[37]
F G2: Fine-grained cross-view localization by fine-grained feature matching
Zimin Xia and Alexandre Alahi. F G2: Fine-grained cross-view localization by fine-grained feature matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6362–6372, 2025
2025
-
[38]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Aleksei Bochkovskii, Ama˜ aG ¸l Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second.arXiv preprint arXiv:2410.02073, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Grounding image matching in 3d with mast3r, 2024
Vincent Leroy, Yohann Cabon, and Jerome Revaud. Grounding image matching in 3d with mast3r, 2024
2024
-
[40]
Vision meets robotics: The kitti dataset.The International Journal of Robotics Research, 32(11):1231–1237, 2013
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The International Journal of Robotics Research, 32(11):1231–1237, 2013
2013
-
[41]
nuScenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving.arXiv preprint arXiv:1903.11027, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[42]
Whye Kit Fong, Rohit Mohan, Juana Valeria Hurtado, Lubing Zhou, Holger Caesar, Oscar Beijbom, and Abhinav Valada. Panoptic nuscenes: A large-scale benchmark for lidar panoptic segmentation and tracking.arXiv preprint arXiv:2109.03805, 2021
-
[43]
https://developers.google.com/maps/documentation/mapsstatic/intro
-
[44]
Qiwei Wang, Shaoxun Wu, and Yujiao Shi. Bevsplat: Resolving height ambiguity via feature-based gaussian primitives for weakly-supervised cross-view localization.arXiv preprint arXiv:2502.09080, 2025
-
[45]
Visual cross-view metric localization with dense uncertainty estimates
Zimin Xia, Olaf Booij, Marco Manfredi, and Julian FP Kooij. Visual cross-view metric localization with dense uncertainty estimates. InComputer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXIX, pages 90–106. Springer, 2022. 13
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.