Some Inverse Problems in Particle Physics
Pith reviewed 2026-06-27 18:36 UTC · model grok-4.3
The pith
Inverse problems central to particle phenomenology are solved using Backus-Gilbert, Gaussian Processes, and neural network methods for PDFs and spectral functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Inverse problems play a central role in particle phenomenology, and the three approaches of Backus-Gilbert, Gaussian Processes and neural network parametrizations can be used to extract Parton Distribution Functions from data or lattice pseudo- and quasi-PDFs, and spectral functions from Euclidean time correlators.
What carries the argument
Backus-Gilbert method, Gaussian Processes, and neural network parametrizations for solving inverse problems in PDF and spectral function extraction.
Load-bearing premise
That the three named methods are the main relevant approaches and can be meaningfully compared without further data on their performance limitations.
What would settle it
A benchmark study on identical lattice ensembles revealing significant differences in accuracy or bias among the three methods would test the investigation's value.
Figures
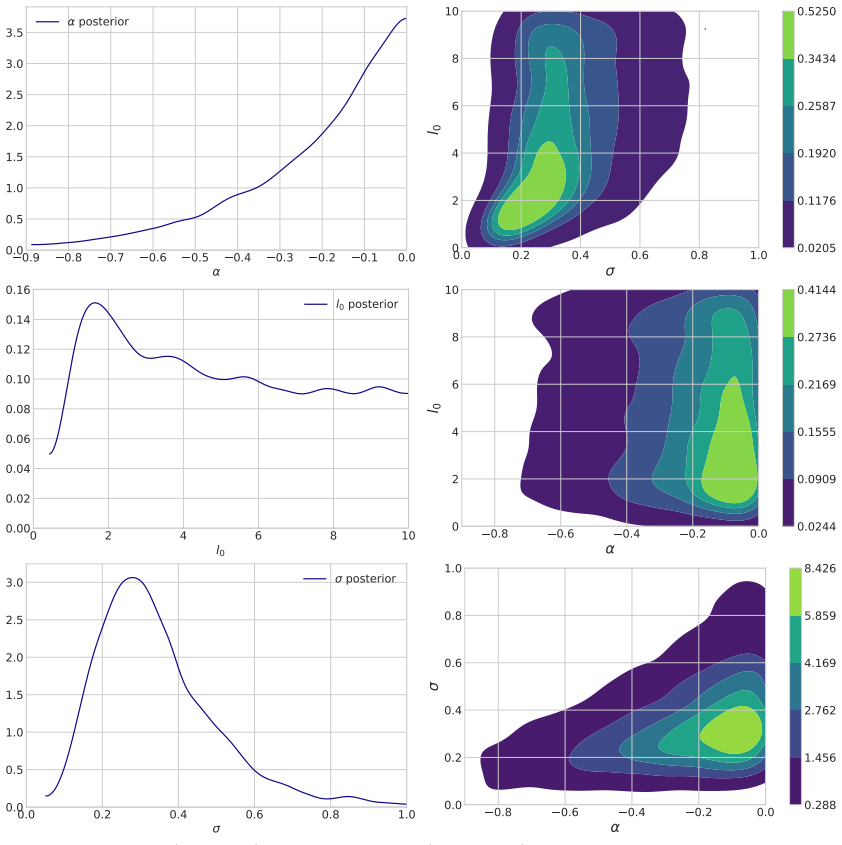
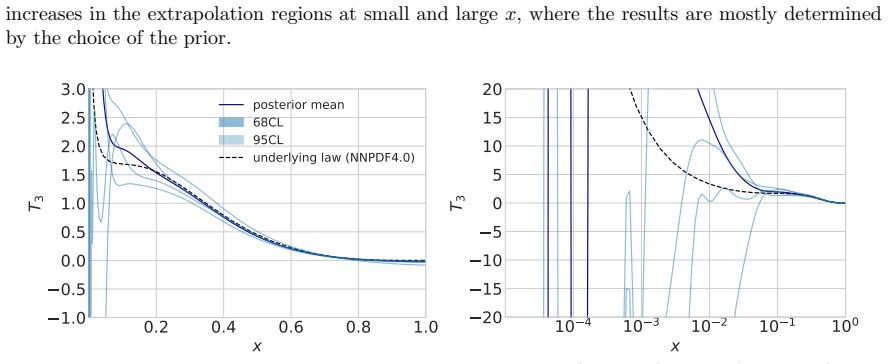
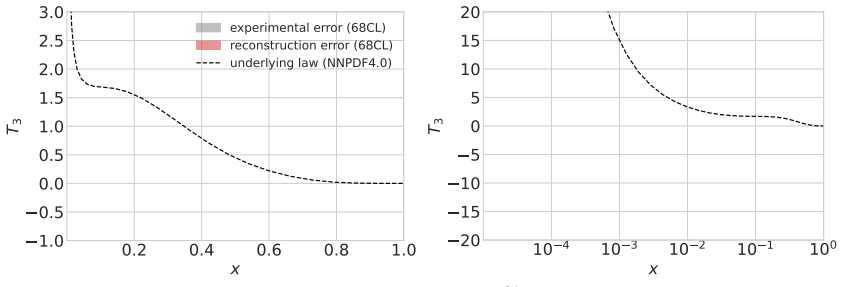
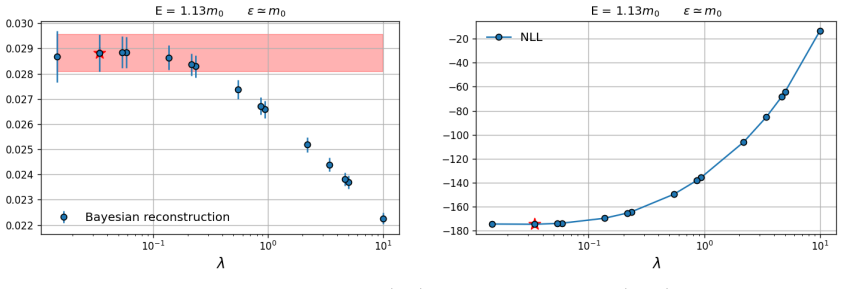
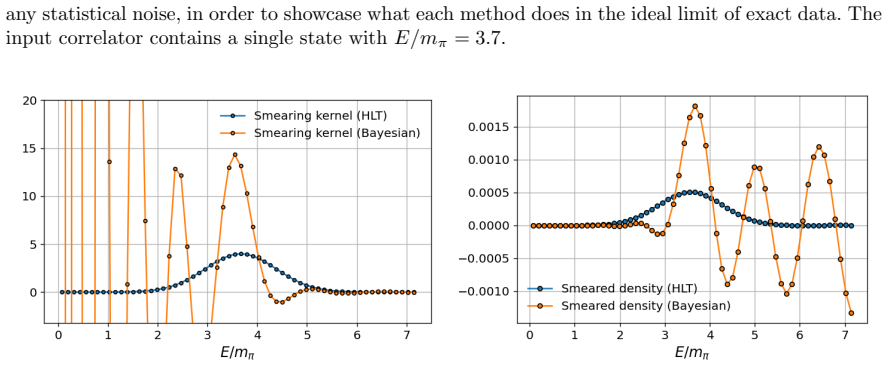

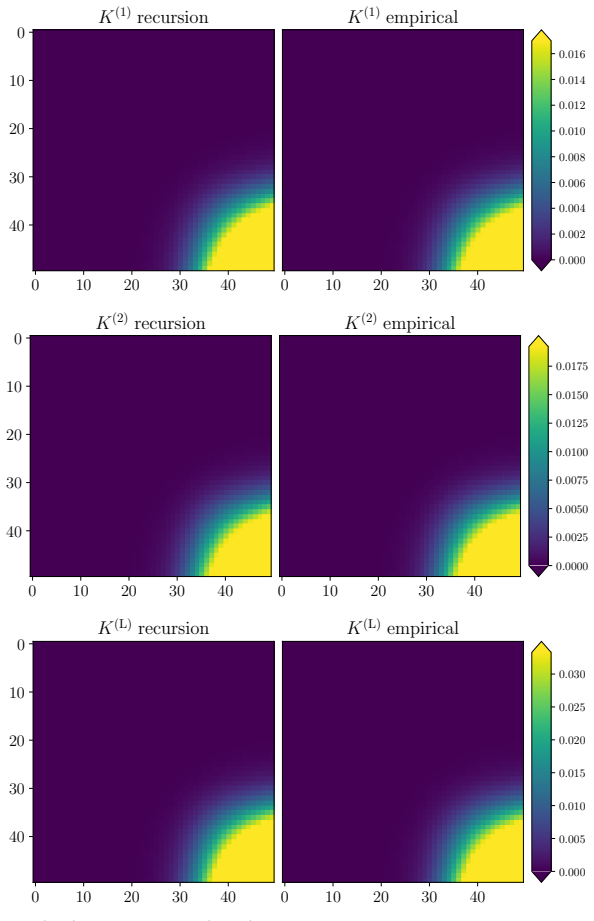
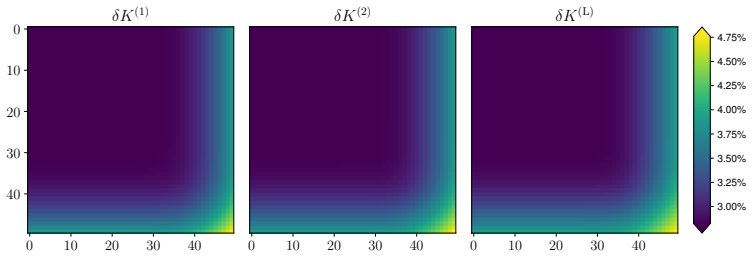
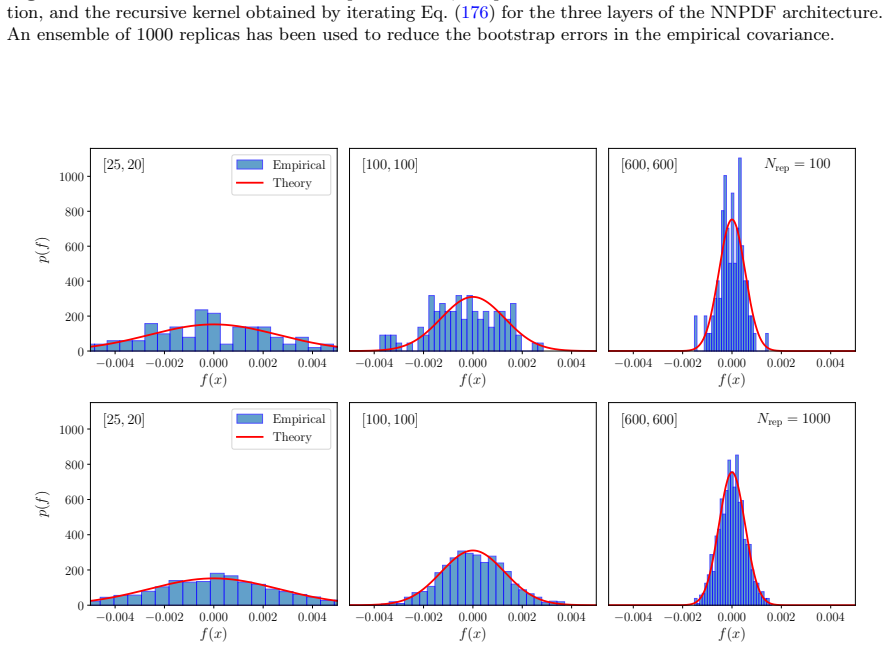
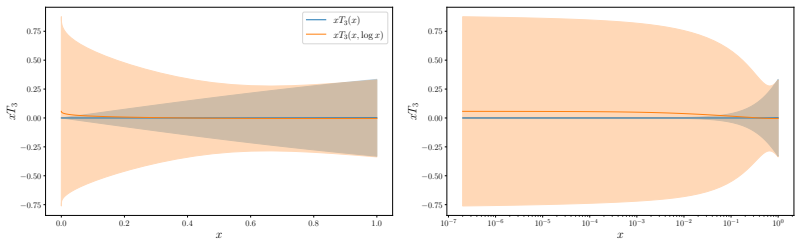
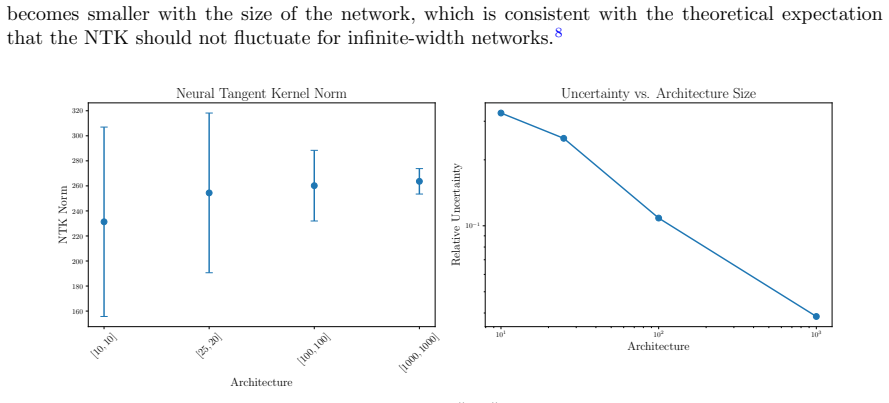
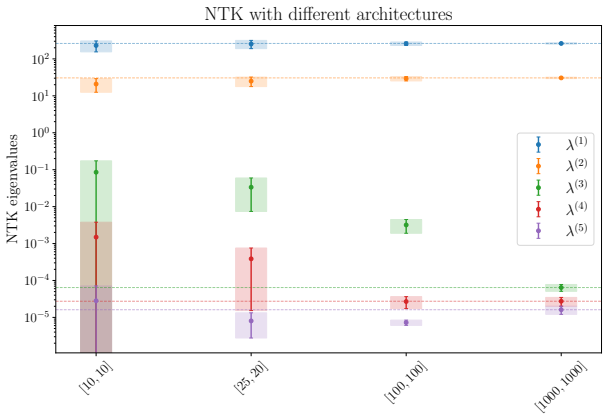
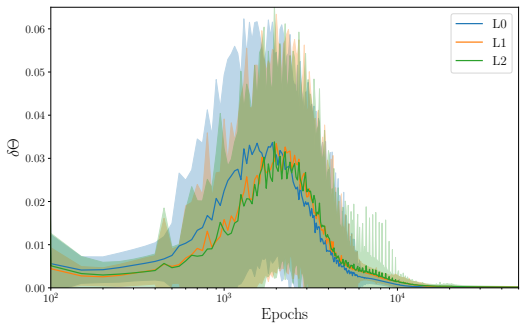

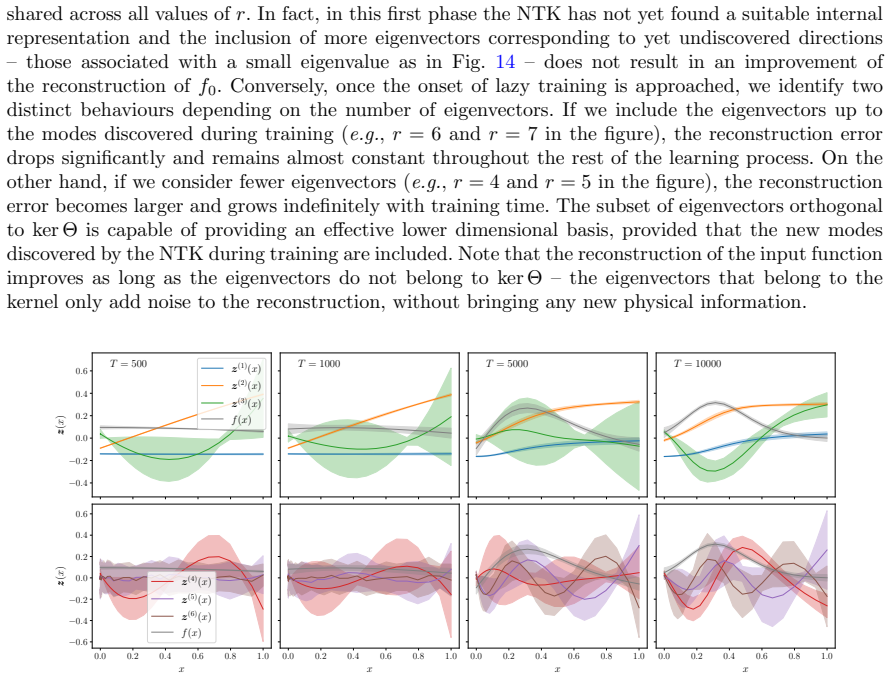
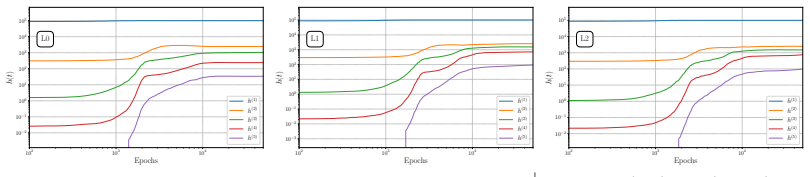
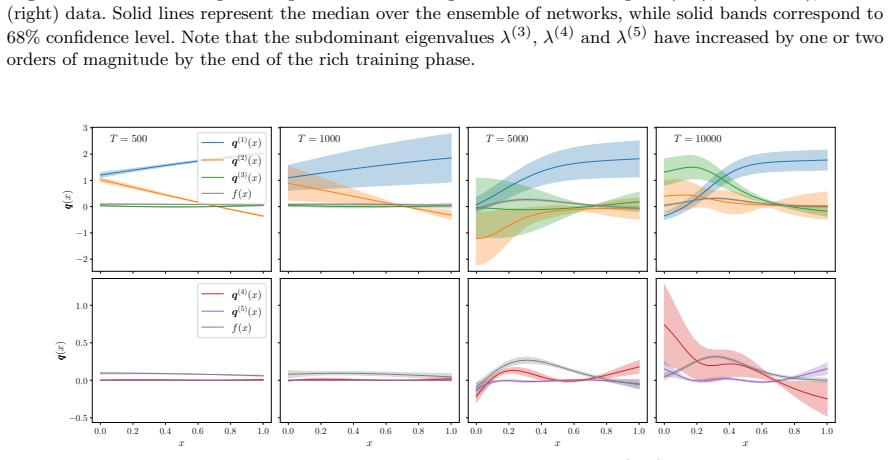
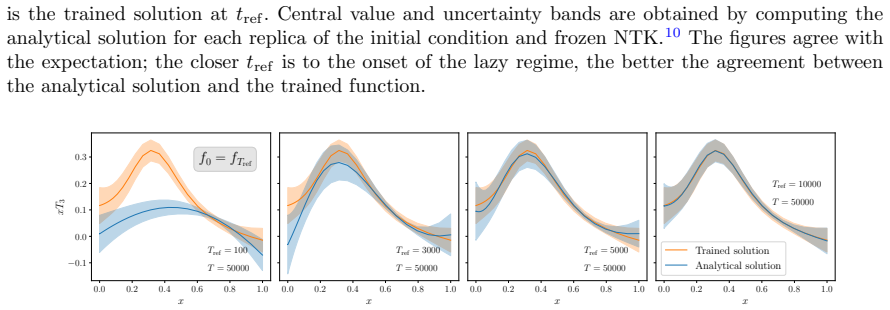
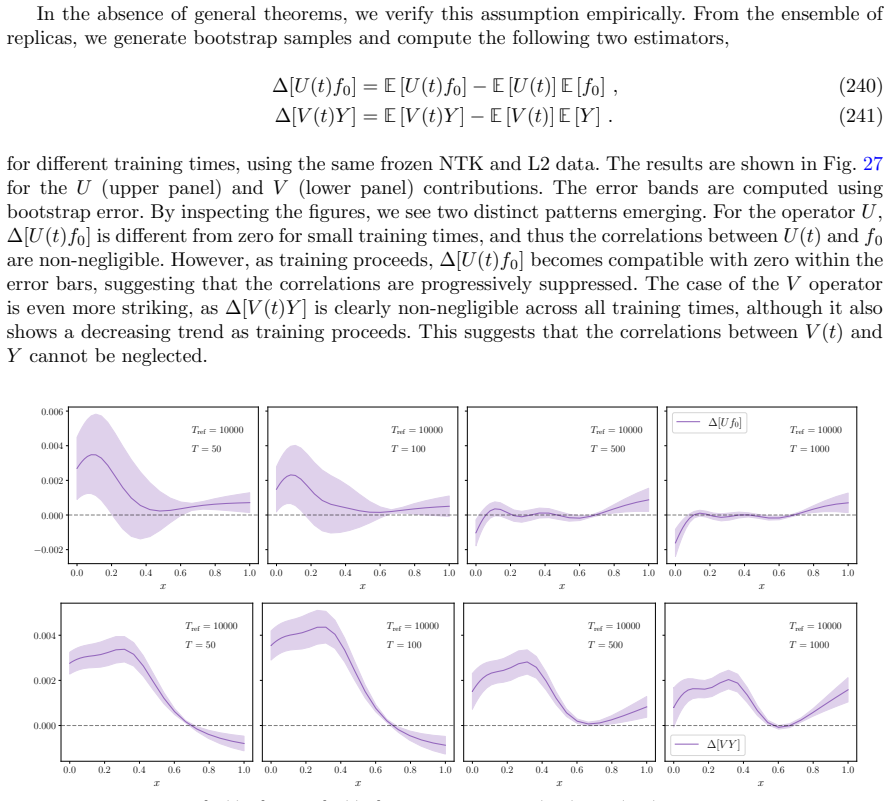
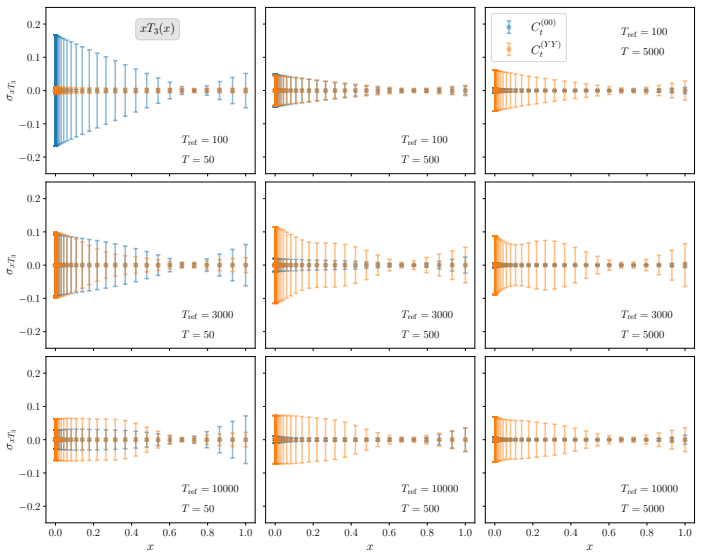
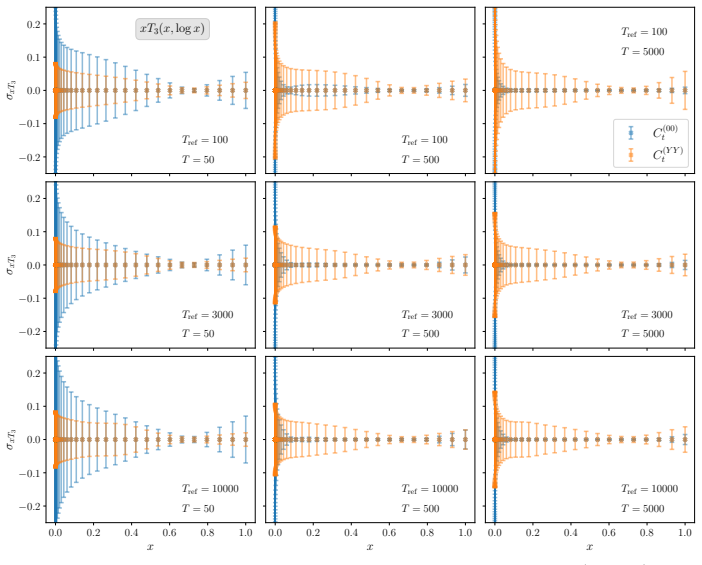
read the original abstract
Inverse problems play a central role in current areas of research in particle phenomenology. In these lectures we focus on two examples, the extraction of Parton Distribution Functions (PDFs) from experimental data (or, equivalently, from pseudo- and quasi-PDFs computed in lattice QCD), and the extraction of spectral functions from lattice Euclidean time correlators. We investigate in detail three different approaches, namely Backus-Gilbert, Gaussian Processes and fits based on Neural Network parametrizations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript consists of lecture notes reviewing inverse problems in particle phenomenology. It focuses on two standard examples—the extraction of parton distribution functions (PDFs) from experimental data or lattice QCD pseudo-/quasi-PDFs, and the extraction of spectral functions from Euclidean correlators—and examines three established methods in detail: the Backus-Gilbert approach, Gaussian processes, and neural-network parametrizations.
Significance. If the descriptions are accurate, the notes could serve as a pedagogical compilation of known techniques for lattice practitioners and phenomenologists. However, the text advances no new derivations, performance benchmarks, validation data, or falsifiable predictions, limiting its significance to exposition rather than original research.
minor comments (1)
- [Abstract] The abstract states that the three methods are 'investigated in detail,' yet the overall presentation remains at the level of known techniques without new quantitative comparisons or error analyses on specific lattice ensembles.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript and the recommendation to accept. The work is explicitly presented as lecture notes reviewing established methods, with no claim to new derivations or benchmarks.
Circularity Check
No significant circularity; review of established methods
full rationale
The paper consists of lecture notes reviewing three established methods (Backus-Gilbert, Gaussian Processes, neural-network parametrizations) for two standard inverse problems in particle physics. No new derivations, predictions, or central claims are advanced that could reduce by construction to fitted inputs or self-citations. All content is expository of known techniques, with no load-bearing steps that equate outputs to inputs via definition or self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rothkopf, A.: Tackling inverse problems for PDFs from lattice QCD. (2026)
2026
-
[2]
Ball, R.D.,et al.: The path to proton structure at 1% accuracy. Eur. Phys. J. C82(5), 428 (2022) https://doi.org/10.1140/epjc/s10052-022-10328-7 arXiv:2109.02653 [hep-ph]
-
[3]
Bailey, S., Cridge, T., Harland-Lang, L.A., Martin, A.D., Thorne, R.S.: Parton distributions from LHC, HERA, Tevatron and fixed target data: MSHT20 PDFs. Eur. Phys. J. C81(4), 341 (2021) https://doi.org/10.1140/epjc/s10052-021-09057-0 arXiv:2012.04684 [hep-ph]
-
[4]
Hou, T.-J.,et al.: New CTEQ global analysis of quantum chromodynamics with high-precision data from the LHC. Phys. Rev. D103(1), 014013 (2021) https://doi.org/10.1103/PhysRevD. 103.014013 arXiv:1912.10053 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1103/physrevd 2021
-
[5]
Salg, M., Romero-L´ opez, F., Jay, W.I.: Bayesian analysis and analytic continuation of scattering amplitudes from lattice QCD. Phys. Rev. D112(11), 114502 (2025) https://doi.org/10.1103/ ty19-xvvw arXiv:2506.16161 [hep-lat]
arXiv 2025
-
[6]
Penrose, R.: A generalized inverse for matrices. Mathematical Proceedings of the Cambridge Philosophical Society51(3), 406–413 (1955) https://doi.org/10.1017/S0305004100030401
-
[7]
Backus, G.E., Gilbert, J.F.: Numerical applications of a formalism for geophysical inverse problems. Geophysical Journal International13(1-3), 247–276 (1967) https://doi.org/10.1111/j. 1365-246X.1967.tb02159.x https://academic.oup.com/gji/article-pdf/13/1-3/247/2722726/13-1- 3-247.pdf
work page doi:10.1111/j 1967
-
[9]
Hansen, M., Lupo, A., Tantalo, N.: Extraction of spectral densities from lattice correlators. Phys. Rev. D99(9), 094508 (2019) https://doi.org/10.1103/PhysRevD.99.094508 arXiv:1903.06476 [hep-lat]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1103/physrevd.99.094508 2019
-
[10]
Candido, A., Del Debbio, L., Giani, T., Petrillo, G.: Bayesian inference with Gaussian processes for the determination of parton distribution functions. Eur. Phys. J. C84(7), 716 (2024) https: //doi.org/10.1140/epjc/s10052-024-13100-1 arXiv:2404.07573 [hep-ph]
-
[11]
Benvenuti, A.C.,et al.: A High Statistics Measurement of the Proton Structure Functions F(2) (x, Q**2) and R from Deep Inelastic Muon Scattering at High Q**2. Phys. Lett. B223, 485–489 (1989) https://doi.org/10.1016/0370-2693(89)91637-7
-
[12]
Del Debbio, L., Lupo, A., Panero, M., Tantalo, N.: Bayesian solution to the inverse problem and its relation to Backus–Gilbert methods. Eur. Phys. J. C85(2), 185 (2025) https://doi.org/10. 1140/epjc/s10052-025-13885-9 arXiv:2409.04413 [hep-lat] 71
arXiv 2025
-
[13]
Horak, J., Pawlowski, J.M., Rodr´ ıguez-Quintero, J., Turnwald, J., Urban, J.M., Wink, N., Zafeiropoulos, S.: Reconstructing QCD spectral functions with Gaussian processes. Phys. Rev. D 105(3), 036014 (2022) https://doi.org/10.1103/PhysRevD.105.036014 arXiv:2107.13464 [hep-ph]
-
[14]
A framework for probabilistic continuous inverse theory
Valentine, A.P., Sambridge, M.: Gaussian process models—I. A framework for probabilistic continuous inverse theory. Geophysical Journal International220(3), 1632–1647 (2019) https://doi.org/10.1093/gji/ggz520 https://academic.oup.com/gji/article- pdf/220/3/1632/31578341/ggz520.pdf
-
[15]
JHEP07, 034 (2022) https: //doi.org/10.1007/JHEP07(2022)034 arXiv:2111.12774 [hep-lat]
Bulava, J., Hansen, M.T., Hansen, M.W., Patella, A., Tantalo, N.: Inclusive rates from smeared spectral densities in the two-dimensional O(3) non-linearσ-model. JHEP07, 034 (2022) https: //doi.org/10.1007/JHEP07(2022)034 arXiv:2111.12774 [hep-lat]
-
[16]
Del Debbio, L., Lupo, A., Panero, M., Tantalo, N.: Multi-representation dynamics of SU(4) composite Higgs models: chiral limit and spectral reconstructions. Eur. Phys. J. C83(3), 220 (2023) https://doi.org/10.1140/epjc/s10052-023-11363-8 arXiv:2211.09581 [hep-lat]
-
[17]
Alexandrou, C.,et al.: Probing the Energy-Smeared R Ratio Using Lattice QCD. Phys. Rev. Lett.130(24), 241901 (2023) https://doi.org/10.1103/PhysRevLett.130.241901 arXiv:2212.08467 [hep-lat]
-
[18]
Bennett, E., et al.: Meson spectroscopy from spectral densities in lattice gauge theories (2024) arXiv:2405.01388 [hep-lat]
arXiv 2024
-
[19]
Backus, G., Gilbert, F.: The Resolving Power of Gross Earth Data. Geophysical Jour- nal International16(2), 169–205 (1968) https://doi.org/10.1111/j.1365-246X.1968.tb00216.x https://academic.oup.com/gji/article-pdf/16/2/169/5891044/16-2-169.pdf
-
[20]
In: Teh, Y.W., Titterington, M
Glorot, X., Bengio, Y.: Understanding the difficulty of training deep feedforward neural networks. In: Teh, Y.W., Titterington, M. (eds.) Proceedings of the Thirteenth Interna- tional Conference on Artificial Intelligence and Statistics. Proceedings of Machine Learn- ing Research, vol. 9, pp. 249–256. PMLR, Chia Laguna Resort, Sardinia, Italy (2010). http...
2010
-
[21]
Cambridge University Press, ??? (2022)
Roberts, D.A., Yaida, S., Hanin, B.: The Principles of Deep Learning Theory: An Effective Theory Approach to Understanding Neural Networks. Cambridge University Press, ??? (2022). https://doi.org/10.1017/9781009023405 .http://dx.doi.org/10.1017/9781009023405
-
[22]
Chiefa, A., Del Debbio, L., Kenway, R.: Quantitative Understanding of PDF Fits and their Uncertainties (2025) arXiv:2512.24116 [hep-ph]
arXiv 2025
-
[23]
Barrett, D.G.T., Dherin, B.: Implicit gradient regularization (2022) arXiv:2009.11162 [cs.LG]
arXiv 2022
-
[24]
Advances in neural information processing systems31(2018) arXiv:1806.07572 [cs.LG] 72
Jacot, A., Gabriel, F., Hongler, C.: Neural Tangent Kernel: Convergence and Generalization in Neural Networks. Advances in neural information processing systems31(2018) arXiv:1806.07572 [cs.LG] 72
arXiv 2018
-
[25]
Parton distributions for the LHC Run II
Ball, R.D.,et al.: Parton distributions for the LHC Run II. JHEP04, 040 (2015) https://doi. org/10.1007/JHEP04(2015)040 arXiv:1410.8849 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/jhep04(2015)040 2015
-
[26]
Lee, J., Xiao, L., Schoenholz, S., Bahri, Y., Novak, R., Sohl-Dickstein, J., Pennington, J.: Wide neural networks of any depth evolve as linear models under gradient descent. Journal of Sta- tistical Mechanics: Theory and Experiment2020(12), 124002 (2020) https://doi.org/10.1088/ 1742-5468/abc62b arXiv:1902.06720 [stat.ML]
arXiv 2020
-
[27]
Advances in Neural Information Processing Systems33, 5850–5861 (2020) arXiv:2010.15110 [cs.LG]
Fort, S., Dziugaite, G.K., Paul, M., Kharaghani, S., Roy, D.M., Ganguli, S.: Deep learning versus kernel learning: an empirical study of loss landscape geometry and the time evolution of the neural tangent kernel. Advances in Neural Information Processing Systems33, 5850–5861 (2020) arXiv:2010.15110 [cs.LG]
arXiv 2020
-
[28]
Ablat, A.,et al.: New results in the CTEQ-TEA global analysis of parton distributions in the nucleon. Eur. Phys. J. Plus139(11), 1063 (2024) https://doi.org/10.1140/epjp/ s13360-024-05865-x arXiv:2406.10260 [hep-ph]
-
[29]
Alekhin, S., Bl¨ umlein, J., Moch, S., Placakyte, R.: Parton distribution functions,α s, and heavy- quark masses for LHC Run II. Phys. Rev. D96(1), 014011 (2017) https://doi.org/10.1103/ PhysRevD.96.014011 arXiv:1701.05838 [hep-ph]
Pith/arXiv arXiv 2017
-
[30]
Costantini, M.N., Mantani, L., Moore, J.M., Ubiali, M.: A linear PDF model for Bayesian inference (2025) arXiv:2507.16913 [hep-ph] Data Availability Statement: No new data were created or analysed in this study. 73
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.