"So There's a Catch-22 Here": How Early Adopters Who Build Multi-Agent LLM Systems Conceptualize Transparency
Pith reviewed 2026-06-27 19:04 UTC · model grok-4.3
The pith
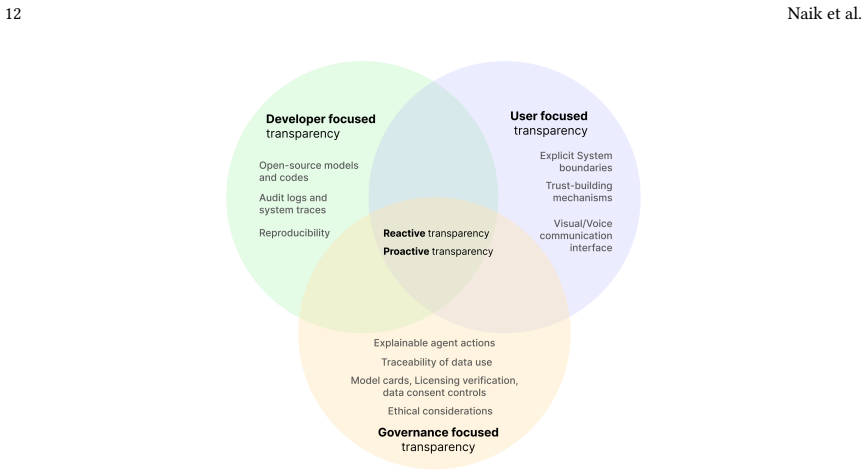
Early adopters of multi-agent LLM systems frame transparency through complementary lenses of reproducibility, debugging, boundary-setting, visualization, and auditing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We conducted semi-structured interviews with 13 early adopters in a large technology organization and applied thematic analysis to identify recurring patterns. Participants articulated divergent yet complementary framings of transparency, including reproducibility, debugging, boundary-setting, visualization, and auditing. These perspectives spanned questions of what transparency entails, why it matters, and how it is achieved. We synthesize these into a multidimensional framework, which is developer, user, and governance-focused positioning transparency as a situated socio-technical practice that informs future HCI and AI design and research around aligning expectations and capacities of the
What carries the argument
The multidimensional framework that organizes transparency framings into developer-focused, user-focused, and governance-focused dimensions and treats transparency as a situated socio-technical practice.
If this is right
- Transparency practices in multi-agent systems must address inter-agent coordination and orchestration in addition to single-model concerns.
- Design work should produce tools that support multiple framings simultaneously rather than a single definition.
- Governance mechanisms for these systems need to incorporate auditing and boundary-setting alongside technical reproducibility.
- Future research should test ways to align the differing expectations of developers, end users, and oversight bodies.
- Responsible AI guidelines for distributed LLM architectures should treat transparency as an ongoing, context-dependent activity rather than a fixed property.
Where Pith is reading between the lines
- The framework could be used to audit existing multi-agent platforms for coverage across all three focus areas.
- Organizations outside the study might discover gaps in their current transparency practices by mapping them against the five framings.
- Tool builders could prototype interfaces that let users switch between visualization, debugging, and audit modes depending on their role.
- Regulatory proposals for agentic AI might draw on the governance dimension to specify required documentation and oversight steps.
Load-bearing premise
The accounts of 13 early adopters drawn from one large technology organization are sufficient to represent how builders of multi-agent LLM systems generally conceptualize transparency.
What would settle it
A follow-up study interviewing early adopters outside the original organization or in different industries that finds substantially different or non-overlapping framings of transparency would undermine the framework's claimed scope.
Figures
read the original abstract
Multi-agent large language model (LLM) systems are rapidly emerging, yet transparency, a cornerstone of responsible AI, remains under-defined in these distributed architectures, which have complexities of inter-agent coordination and orchestration. In this paper, we present one of the first empirical study of how early adopters of multi-agent LLM systems, who are both the builders and users, understand and practice transparency. We conducted semi-structured interviews with 13 early adopters in [Large Technology Organization] and applied thematic analysis to identify recurring patterns. Participants articulated divergent yet complementary framings of transparency, including reproducibility, debugging, boundary-setting, visualization, and auditing. These perspectives spanned questions of what transparency entails, why it matters, and how it is achieved. We synthesize these into a multidimensional framework, which is developer, user, and governance-focused positioning transparency as a situated socio-technical practice that informs future HCI and AI design and research around aligning expectations and capacities of their intended audiences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents findings from semi-structured interviews with 13 early adopters of multi-agent LLM systems within a single large technology organization. Using thematic analysis, it identifies framings of transparency such as reproducibility, debugging, boundary-setting, visualization, and auditing. These are synthesized into a multidimensional framework that is developer-, user-, and governance-focused, positioning transparency as a situated socio-technical practice to inform future HCI and AI design.
Significance. If the identified patterns hold beyond the studied organization, the multidimensional framework could provide valuable insights for designing transparent multi-agent LLM systems by highlighting complementary perspectives on what transparency entails, why it matters, and how it is achieved. The work is notable as one of the first empirical studies in this area, employing standard qualitative methods to ground the framework in practitioner conceptualizations.
major comments (2)
- [Methods] Methods section: The participant sample consists exclusively of 13 individuals from a single large technology organization. This limitation undermines the generalizability of the synthesized multidimensional framework, as the framings may reflect organization-specific tooling, culture, and coordination practices rather than broader early-adopter conceptualizations. This is load-bearing for the claim that the framework informs future HCI and AI design and research.
- [Methods] Methods section: The thematic analysis lacks reported details on inter-rater reliability or member-checking procedures, which are important for establishing the trustworthiness of the identified themes and the resulting framework.
minor comments (2)
- [Abstract] Abstract: The abstract could benefit from a brief mention of the study's limitations regarding sample size and scope to provide a more balanced overview.
- The presentation of the multidimensional framework would be strengthened by a figure or table explicitly mapping the framings (reproducibility, debugging, etc.) to the developer/user/governance perspectives.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below and outline proposed revisions to the methods and discussion sections.
read point-by-point responses
-
Referee: [Methods] Methods section: The participant sample consists exclusively of 13 individuals from a single large technology organization. This limitation undermines the generalizability of the synthesized multidimensional framework, as the framings may reflect organization-specific tooling, culture, and coordination practices rather than broader early-adopter conceptualizations. This is load-bearing for the claim that the framework informs future HCI and AI design and research.
Authors: We agree that the single-organization sample constitutes a genuine limitation for broad generalizability, as the framings could be shaped by internal tooling and practices. The manuscript already positions the work as one of the first empirical studies in this emerging area and presents the framework as a starting point rather than a definitive model. We will revise the limitations and discussion sections to more explicitly state the scope, avoid overclaiming generalizability, and frame the contribution as informing future HCI and AI design through transferable insights from early adopters. We cannot expand the participant pool without new data collection. revision: partial
-
Referee: [Methods] Methods section: The thematic analysis lacks reported details on inter-rater reliability or member-checking procedures, which are important for establishing the trustworthiness of the identified themes and the resulting framework.
Authors: We will revise the methods section to provide additional detail on the thematic analysis process, including the iterative coding approach, team discussions for consensus on themes, and how coding disagreements were resolved through deliberation. As is common in interpretive qualitative HCI research, formal inter-rater reliability statistics were not computed; we will explicitly note this and discuss the rationale. Member checking was not conducted owing to participant availability constraints in this exploratory study, and we will add this to the limitations section. revision: yes
Circularity Check
No circularity: empirical qualitative study rests on interview data
full rationale
The paper conducts semi-structured interviews with 13 early adopters and applies thematic analysis to identify framings of transparency (reproducibility, debugging, etc.), synthesizing them into a multidimensional framework. No mathematical derivations, parameter fitting, predictions, or self-citation chains exist; all load-bearing claims trace directly to the collected interview data rather than reducing to internal definitions or prior author work by construction. The single-organization sample raises external generalizability questions but does not create circularity within the derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Thematic analysis reliably surfaces recurring conceptual patterns from semi-structured interview transcripts.
Reference graph
Works this paper leans on
-
[1]
Amina Adadi and Mohammed Berrada. 2018. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI).IEEE Access6 (2018), 52138–52160. https://doi.org/10.1109/ACCESS.2018.2870052 Conference Name: IEEE Access
-
[2]
Guidelines for Human-AI Interaction,
Saleema Amershi, Dan Weld, Mihaela Vorvoreanu, Adam Fourney, Besmira Nushi, Penny Collisson, Jina Suh, Shamsi Iqbal, Paul N. Bennett, Kori Inkpen, Jaime Teevan, Ruth Kikin-Gil, and Eric Horvitz. 2019. Guidelines for Human-AI Interaction. InProceedings of the 2019 CHI Conference on Human Factors in Computing Systems (CHI ’19). Association for Computing Mac...
-
[3]
Indradip Banerjee and Siddhartha Bhattacharyya. 2022. Introduction to Multi-agent Systems. InMulti Agent Systems: Technologies and Applications towards Human-Centered, Shibakali Gupta, Indradip Banerjee, and Siddhartha Bhattacharyya (Eds.). Springer Nature, Singapore, 1–4. https: //doi.org/10.1007/978-981-19-0493-6_1
-
[4]
Gagan Bansal, Besmira Nushi, Ece Kamar, Walter S. Lasecki, Daniel S. Weld, and Eric Horvitz. 2019. Beyond Accuracy: The Role of Mental Models in Human-AI Team Performance.Proceedings of the AAAI Conference on Human Computation and Crowdsourcing7 (Oct. 2019), 2–11. https://doi.org/10.1609/hcomp.v7i1.5285
-
[5]
Gagan Bansal, Jennifer Wortman Vaughan, Saleema Amershi, Eric Horvitz, Adam Fourney, Hussein Mozannar, Victor Dibia, and Daniel S. Weld
-
[6]
Challenges in Human-Agent Communication. (Dec. 2024). https://www.microsoft.com/en-us/research/publication/human-agent-interaction- challenges/
2024
-
[7]
Virginia Braun and Victoria Clarke. 2012. Thematic analysis. InAPA handbook of research methods in psychology, Vol 2: Research designs: Quantitative, qualitative, neuropsychological, and biological. American Psychological Association, Washington, DC, US, 57–71. https://doi.org/10.1037/13620-004 Manuscript submitted to ACM Transparency Practices in Multi-A...
-
[8]
Sabrina Caldwell, Penny Sweetser, Nicholas O’Donnell, Matthew J. Knight, Matthew Aitchison, Tom Gedeon, Daniel Johnson, Margot Brereton, Marcus Gallagher, and David Conroy. 2022. An Agile New Research Framework for Hybrid Human-AI Teaming: Trust, Transparency, and Transferability.ACM Trans. Interact. Intell. Syst.12, 3 (July 2022), 17:1–17:36. https://doi...
-
[9]
Lee, Bongshin Lee, Wanda Pratt, and Julie A
Eun Kyoung Choe, Nicole B. Lee, Bongshin Lee, Wanda Pratt, and Julie A. Kientz. 2014. Understanding quantified-selfers’ practices in collecting and exploring personal data. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’14). Association for Computing Machinery, New York, NY, USA, 1143–1152. https://doi.org/10.1145/25562...
-
[10]
Creswell and Cheryl N
John W. Creswell and Cheryl N. Poth. 2018.Qualitative inquiry & research design: choosing among five approaches(fourth edition. ed.). SAGE, Thousand Oaks, CA
2018
-
[11]
Victor Dibia. 2023. Multi-Agent LLM Applications | A Review of Current Research, Tools, and Challenges. https://newsletter.victordibia.com/p/multi- agent-llm-applications-a-review
2023
-
[12]
Vera Liao, Elizabeth Anne Watkins, Carina Manger, Hal Daumé III, Andreas Riener, and Mark O Riedl
Upol Ehsan, Philipp Wintersberger, Q. Vera Liao, Elizabeth Anne Watkins, Carina Manger, Hal Daumé III, Andreas Riener, and Mark O Riedl. 2022. Human-Centered Explainable AI (HCXAI): Beyond Opening the Black-Box of AI. InExtended Abstracts of the 2022 CHI Conference on Human Factors in Computing Systems (CHI EA ’22). Association for Computing Machinery, Ne...
-
[13]
Eva Eigner and Thorsten Händler. 2024. Determinants of LLM-assisted Decision-Making. https://arxiv.org/abs/2402.17385v1
arXiv 2024
-
[14]
Motahhare Eslami, Kristen Vaccaro, Min Kyung Lee, Amit Elazari Bar On, Eric Gilbert, and Karrie Karahalios. 2019. User Attitudes towards Algorithmic Opacity and Transparency in Online Reviewing Platforms. InProceedings of the 2019 CHI Conference on Human Factors in Computing Systems. ACM, Glasgow Scotland Uk, 1–14. https://doi.org/10.1145/3290605.3300724
-
[15]
Hoffman, Shane T
R. Hoffman, Shane T. Mueller, Gary Klein, and Jordan Litman. 2018. Metrics for Explainable AI: Challenges and Prospects.ArXiv(Dec. 2018). https://www.semanticscholar.org/paper/be711f681580d3a02c8bc4c4dab0c7a043f4e1d2
2018
-
[16]
Todd Kulesza, Simone Stumpf, Margaret Burnett, and Irwin Kwan. 2012. Tell me more?: the effects of mental model soundness on personalizing an intelligent agent. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems. ACM, Austin Texas USA, 1–10. https: //doi.org/10.1145/2207676.2207678
-
[17]
Tianyi Li, Mihaela Vorvoreanu, Derek Debellis, and Saleema Amershi. 2023. Assessing Human-AI Interaction Early through Factorial Surveys: A Study on the Guidelines for Human-AI Interaction.ACM Transactions on Computer-Human Interaction30, 5 (Oct. 2023), 1–45. https://doi.org/10. 1145/3511605
2023
-
[18]
Vera Liao, Hariharan Subramonyam, Jennifer Wang, and Jennifer Wortman Vaughan
Q. Vera Liao, Hariharan Subramonyam, Jennifer Wang, and Jennifer Wortman Vaughan. 2023. Designerly Understanding: Information Needs for Model Transparency to Support Design Ideation for AI-Powered User Experience. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. ACM, Hamburg Germany, 1–21. https://doi.org/10.1145/3544548.3580652
-
[19]
Katelyn Morrison, Philipp Spitzer, Violet Turri, Michelle Feng, Niklas Kühl, and Adam Perer. 2024. The Impact of Imperfect XAI on Human-AI Decision-Making.Proceedings of the ACM on Human-Computer Interaction8, CSCW1 (April 2024), 1–39. https://doi.org/10.1145/3641022
-
[20]
Toombs, Scott Saponas, and Amanda K Hall
Suchismita Naik, Amanda Snellinger, Austin L. Toombs, Scott Saponas, and Amanda K Hall. 2025. Exploring Early Adopters’ Use of AI Driven Multi-Agent Systems to Inform Human-Agent Interaction Design: Insights from Industry Practice. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI EA ’25). Association...
-
[21]
Suchismita Naik, Austin L. Toombs, Amanda Snellinger, Scott Saponas, and Amanda K Hall. 2025. Designing with Multi-Agent Generative AI: Insights from Industry Early Adopters. InProceedings of the 2025 ACM Designing Interactive Systems Conference. ACM, Madeira Portugal, 1961–1972. https://doi.org/10.1145/3715336.3735823
-
[22]
Thao Ngo, Johannes Kunkel, and Jürgen Ziegler. 2020. Exploring Mental Models for Transparent and Controllable Recommender Systems: A Qualitative Study. InProceedings of the 28th ACM Conference on User Modeling, Adaptation and Personalization (UMAP ’20). Association for Computing Machinery, New York, NY, USA, 183–191. https://doi.org/10.1145/3340631.3394841
-
[23]
2024.Appropriate reliance on Generative AI: Research synthesis
Samir Passi, Shipi Dhanorkar, and Mihaela Vorvoreanu. 2024.Appropriate reliance on Generative AI: Research synthesis. Technical Report MSR-TR- 2024-7. Microsoft. https://www.microsoft.com/en-us/research/publication/appropriate-reliance-on-generative-ai-research-synthesis/
2024
-
[24]
Bo Qiao, Liqun Li, Xu Zhang, Shilin He, Yu Kang, Chaoyun Zhang, Fangkai Yang, Hang Dong, Jue Zhang, Lu Wang, Minghua Ma, Pu Zhao, Si Qin, Xiaoting Qin, Chao Du, Yong Xu, Qingwei Lin, Saravan Rajmohan, and Dongmei Zhang. 2023. TaskWeaver: A Code-First Agent Framework. https://arxiv.org/abs/2311.17541v3
arXiv 2023
-
[25]
Jean-Charles Rochet and Jean Tirole
Inioluwa Deborah Raji, Andrew Smart, Rebecca N. White, Margaret Mitchell, Timnit Gebru, Ben Hutchinson, Jamila Smith-Loud, Daniel Theron, and Parker Barnes. 2020. Closing the AI accountability gap: defining an end-to-end framework for internal algorithmic auditing. InProceedings of the 2020 Conference on Fairness, Accountability, and Transparency. ACM, Ba...
-
[26]
Robert Soden, Austin Toombs, and Michaelanne Thomas. 2024. Evaluating Interpretive Research in HCI.Interactions31, 1 (Jan. 2024), 38–42. https://doi.org/10.1145/3633200
-
[27]
Mihaela Vorvoreanu. 2023. Create Effective and Responsible AI User Experiences with The Human-AI Experience (HAX) Toolkit. InExtended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems. ACM, Hamburg Germany, 1–2. https://doi.org/10.1145/3544549.3574191
-
[28]
Michael Vössing, Niklas Kühl, Matteo Lind, and Gerhard Satzger. 2022. Designing Transparency for Effective Human-AI Collaboration.Information Systems Frontiers24, 3 (June 2022), 877–895. https://doi.org/10.1007/s10796-022-10284-3 Company: Springer Distributor: Springer Institution: Springer Label: Springer Number: 3 Publisher: Springer US. Manuscript subm...
-
[29]
Ruotong Wang, Ruijia Cheng, Denae Ford, and Thomas Zimmermann. 2024. Investigating and Designing for Trust in AI-powered Code Generation Tools. InThe 2024 ACM Conference on Fairness, Accountability, and Transparency. ACM, Rio de Janeiro Brazil, 1475–1493. https://doi.org/10.1145/ 3630106.3658984
arXiv 2024
-
[30]
Xinru Wang and Ming Yin. 2021. Are Explanations Helpful? A Comparative Study of the Effects of Explanations in AI-Assisted Decision-Making. In Proceedings of the 26th International Conference on Intelligent User Interfaces (IUI ’21). Association for Computing Machinery, New York, NY, USA, 318–328. https://doi.org/10.1145/3397481.3450650
-
[31]
Weisz, Jessica He, Michael Muller, Gabriela Hoefer, Rachel Miles, and Werner Geyer
Justin D. Weisz, Jessica He, Michael Muller, Gabriela Hoefer, Rachel Miles, and Werner Geyer. 2024. Design Principles for Generative AI Applications. InProceedings of the CHI Conference on Human Factors in Computing Systems. ACM, Honolulu HI USA, 1–22. https://doi.org/10.1145/3613904.3642466
-
[32]
White, Doug Burger, and Chi Wang
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. 2023. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. http://arxiv.org/abs/2308.08155 arXiv:2308.08155 [cs]
Pith/arXiv arXiv 2023
-
[33]
Rui Zhang, Christopher Flathmann, Geoff Musick, Beau Schelble, Nathan J. McNeese, Bart Knijnenburg, and Wen Duan. 2024. I Know This Looks Bad, But I Can Explain: Understanding When AI Should Explain Actions In Human-AI Teams.ACM Trans. Interact. Intell. Syst.14, 1 (Feb. 2024), 6:1–6:23. https://doi.org/10.1145/3635474 Manuscript submitted to ACM Transpare...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.