Uncertainty-Aware Intention Prediction for Human-to-Robot Assembly Teleoperation
Pith reviewed 2026-06-27 19:19 UTC · model grok-4.3
The pith
Human hand demonstrations pretrain models that fine-tune on robot teleoperation data to raise Edit score from 70.50 to 80.70 with only 16 examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
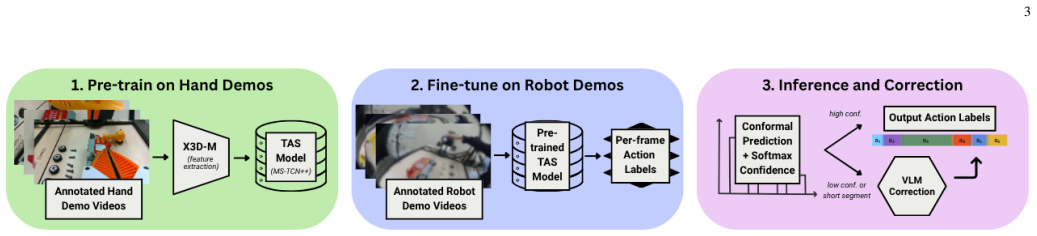
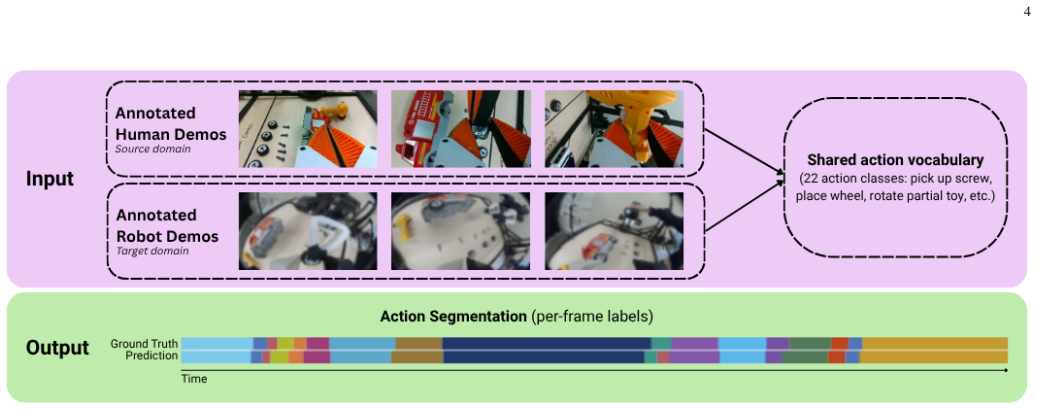
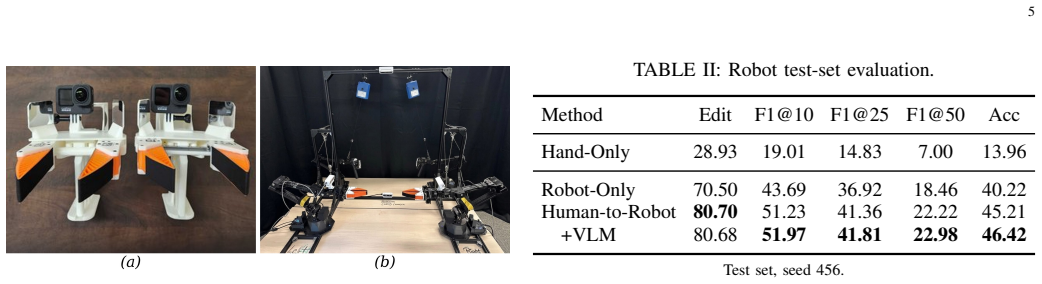
The central claim is that hierarchical transfer learning, where MS-TCN++ is first trained on human hand demonstrations and then fine-tuned on robot teleoperation data for the same 22-class assembly task, produces an Edit score of 80.70 on the robot test set using only 16 robot demonstrations, compared with 70.50 without the human pretraining step; adding edit-safe VLM correction on uncertain segments further raises frame accuracy from 45.21 percent to 46.42 percent and improves F1 at 25 percent and 50 percent overlap while leaving the Edit score unchanged.
What carries the argument
Hierarchical transfer learning that pretrains MS-TCN++ on human hand demonstrations before fine-tuning on robot teleoperation data, augmented by conformal prediction sets for frame-level uncertainty and VLM-guided correction of low-confidence segments.
Load-bearing premise
Features and temporal patterns learned from human hand demonstrations remain aligned enough with robot teleoperation kinematics and sensing to support effective fine-tuning on the identical 22-class assembly task.
What would settle it
A controlled comparison in which a model trained only on the 16 robot demonstrations achieves an Edit score at least as high as the human-pretrained and fine-tuned model on the same robot test set.
Figures

read the original abstract
In assisted teleoperation for human-robot collaboration, accurate intention prediction is critical for enabling timely and reliable robotic assistance during long-horizon manipulation and assembly tasks. These systems require continuous understanding of user behavior to recognize actions, anticipate intentions, and detect mistakes in real time. However, robot teleoperation demonstrations are costly and hardware-limited, whereas human demonstrations are easier to collect and provide rich temporal structure. To address this challenge, we propose an uncertainty-aware human-to-robot intention prediction framework that combines: (1) hierarchical transfer learning, where MS-TCN++ is pretrained on human hand demonstrations and fine-tuned on limited robot teleoperation data to capture low-level actions and high-level task intentions; (2) a conformal prediction module that provides frame-level prediction sets with statistical coverage guarantees for reliable uncertainty quantification and early intention estimation; and (3) VLM-guided segment correction, which selectively reviews low-confidence or temporally uncertain segments using visual and temporal context. The framework supports action recognition, temporal segmentation, intention anticipation, and mistake detection for assisted teleoperation. Experiments on robot assembly demonstrations with 22 action classes show that human-to-robot fine-tuning improves the robot test-set Edit score from 70.50 to 80.70 using only 16 robot demonstrations. Edit-safe VLM correction further improves frame accuracy from 45.21% to 46.42% and increases F1@25 and F1@50 while preserving the Edit score. These results show that human demonstrations provide scalable pretraining data for robust, uncertainty-aware robot action segmentation. Code and data: project website.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an uncertainty-aware framework for intention prediction in human-to-robot assembly teleoperation. It combines hierarchical transfer learning (pretrain MS-TCN++ on human hand demonstrations, fine-tune on limited robot data), conformal prediction for frame-level prediction sets with coverage guarantees, and VLM-guided correction for low-confidence segments. On a 22-class robot assembly task, it claims human-to-robot fine-tuning raises Edit score from 70.50 to 80.70 using 16 robot demonstrations, while Edit-safe VLM correction raises frame accuracy from 45.21% to 46.42% and improves F1@25/F1@50 while preserving Edit score.
Significance. If the results hold, the work is significant because it shows human demonstrations can serve as scalable pretraining for robot teleoperation intention prediction, substantially reducing the number of costly robot demonstrations needed. The conformal module adds statistical reliability and the VLM component provides a practical correction mechanism. Public code and data release is a clear strength for reproducibility.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: the headline claims (Edit 70.50→80.70 with 16 demonstrations; frame accuracy 45.21%→46.42%) are presented without any description of data splits, number of random seeds/trials, statistical significance tests, or full baseline tables, rendering the numerical improvements unverifiable from the given text.
- [Hierarchical Transfer Learning] Hierarchical transfer learning description: the central transfer claim requires that MS-TCN++ features pretrained on human hands remain aligned with robot teleoperation kinematics for the 22-class task, yet no zero-shot robot performance, feature-space distance, or ablation against non-human pretraining is reported; without these diagnostics the observed gain cannot be attributed to hierarchical transfer rather than fine-tuning alone.
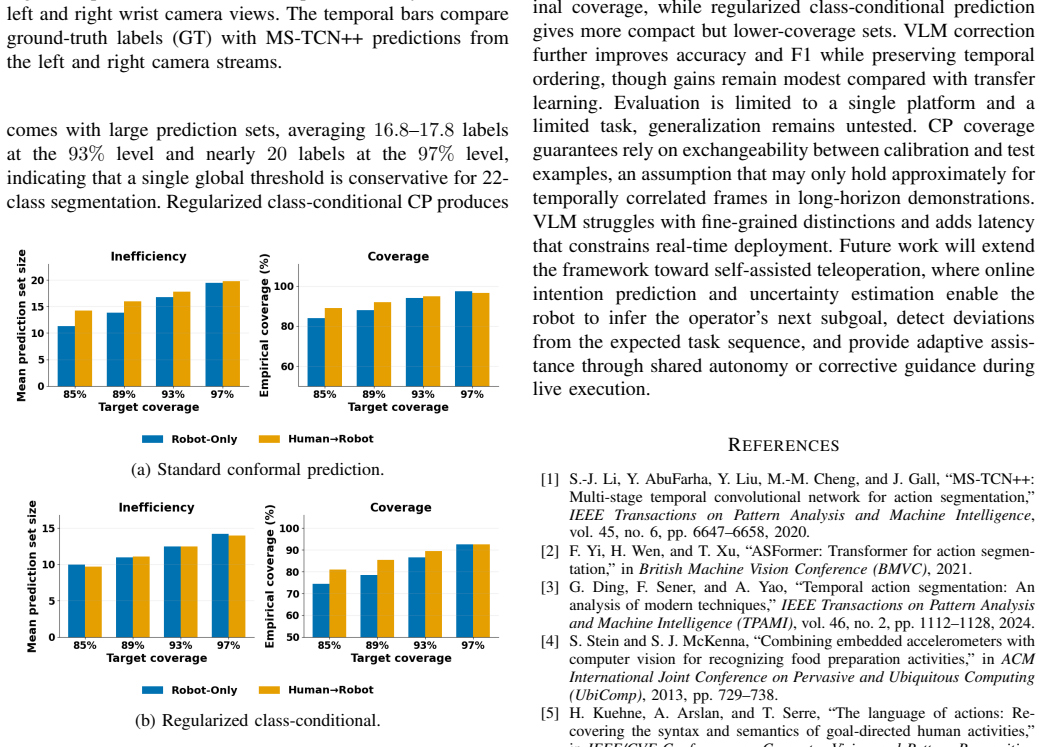
- [Conformal Prediction Module] Conformal prediction module: the procedure is described at a high level but supplies no concrete definition of the nonconformity score, calibration-set construction, or empirical coverage verification on the robot test data, so the claim of “statistical coverage guarantees” cannot be assessed.
minor comments (2)
- [Abstract] The abstract states “Code and data: project website” but provides no URL or DOI; this should be added for immediate accessibility.
- [Methods] Notation for Edit score, F1@25, and F1@50 is used without an explicit reference or short definition in the methods; a one-sentence reminder would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the verifiability of our results. We address each major comment below and will revise the manuscript to incorporate the requested details and diagnostics.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the headline claims (Edit 70.50→80.70 with 16 demonstrations; frame accuracy 45.21%→46.42%) are presented without any description of data splits, number of random seeds/trials, statistical significance tests, or full baseline tables, rendering the numerical improvements unverifiable from the given text.
Authors: We acknowledge that the abstract and experiments summary would benefit from greater explicitness. The full Experiments section describes the 22-class robot assembly dataset, the use of 16 robot demonstrations for fine-tuning, and the train/test splits, but we agree these elements should be stated more prominently. In revision we will add: (i) explicit description of the data splits, (ii) results reported as mean ± std over 5 random seeds, (iii) paired statistical significance tests, and (iv) expanded baseline tables. These changes will be made. revision: yes
-
Referee: [Hierarchical Transfer Learning] Hierarchical transfer learning description: the central transfer claim requires that MS-TCN++ features pretrained on human hands remain aligned with robot teleoperation kinematics for the 22-class task, yet no zero-shot robot performance, feature-space distance, or ablation against non-human pretraining is reported; without these diagnostics the observed gain cannot be attributed to hierarchical transfer rather than fine-tuning alone.
Authors: The manuscript reports the gain from human-pretrained + fine-tuned (80.70) versus robot-only training (70.50), providing an implicit comparison. However, we agree that direct evidence of transfer is strengthened by additional diagnostics. We will add: zero-shot performance of the human-pretrained model on robot data, feature-space alignment (e.g., average cosine similarity between human and robot embeddings), and an ablation using unrelated pretraining data. These will appear in the revised Experiments section. revision: yes
-
Referee: [Conformal Prediction Module] Conformal prediction module: the procedure is described at a high level but supplies no concrete definition of the nonconformity score, calibration-set construction, or empirical coverage verification on the robot test data, so the claim of “statistical coverage guarantees” cannot be assessed.
Authors: We agree that the conformal prediction description requires more concrete specification for full assessment. In the revised manuscript we will define the nonconformity score explicitly (1 − softmax probability of the true label), detail calibration-set construction (held-out subset of robot training demonstrations), and report empirical coverage results on the robot test set to verify the claimed guarantees. These additions will be included. revision: yes
Circularity Check
No circularity: empirical results from distinct pretraining and fine-tuning datasets
full rationale
The paper presents an empirical framework with reported performance metrics (Edit score 70.50 to 80.70, frame accuracy improvements) obtained by pretraining MS-TCN++ on one dataset of human hand demonstrations and fine-tuning on a separate set of 16 robot teleoperation demonstrations, then evaluating on held-out robot test data. No equations define any quantity in terms of the reported metrics, no fitted parameters are relabeled as predictions, and no self-citations are invoked as load-bearing justifications for the transfer claim. The derivation chain consists of standard supervised learning steps whose outputs are measured outcomes rather than identities of the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Number of robot demonstrations for fine-tuning
axioms (1)
- domain assumption Human hand demonstrations contain temporal structure that transfers to robot teleoperation actions for the same assembly task
Reference graph
Works this paper leans on
-
[1]
MS-TCN++: Multi-stage temporal convolutional network for action segmentation,
S.-J. Li, Y . AbuFarha, Y . Liu, M.-M. Cheng, and J. Gall, “MS-TCN++: Multi-stage temporal convolutional network for action segmentation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 6, pp. 6647–6658, 2020
2020
-
[2]
ASFormer: Transformer for action segmen- tation,
F. Yi, H. Wen, and T. Xu, “ASFormer: Transformer for action segmen- tation,” inBritish Machine Vision Conference (BMVC), 2021
2021
-
[3]
Temporal action segmentation: An analysis of modern techniques,
G. Ding, F. Sener, and A. Yao, “Temporal action segmentation: An analysis of modern techniques,”IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 46, no. 2, pp. 1112–1128, 2024
2024
-
[4]
Combining embedded accelerometers with computer vision for recognizing food preparation activities,
S. Stein and S. J. McKenna, “Combining embedded accelerometers with computer vision for recognizing food preparation activities,” inACM International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp), 2013, pp. 729–738
2013
-
[5]
The language of actions: Re- covering the syntax and semantics of goal-directed human activities,
H. Kuehne, A. Arslan, and T. Serre, “The language of actions: Re- covering the syntax and semantics of goal-directed human activities,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 780–787
2014
-
[6]
Hierarchical deep learning for intention estimation of teleoperation manipulation in assembly tasks,
M. Cai, K. Patel, S. Iba, and S. Li, “Hierarchical deep learning for intention estimation of teleoperation manipulation in assembly tasks,” inProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 17 814–17 820
2024
-
[7]
A probabilistic programming approach to intention estimation in human- robot teleoperated assembly tasks,
A. Xu, S. Li, P. Baskaran, K. Patel, S. Iba, and B. Dariush, “A probabilistic programming approach to intention estimation in human- robot teleoperated assembly tasks,” inProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
2025
-
[8]
explainable intention esti- mation in teleoperated manipulation using deep dynamic graph neural networks,
P. Baskaran, X. Liu, S. Li, and S. Iba, “explainable intention esti- mation in teleoperated manipulation using deep dynamic graph neural networks,” inProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025, pp. 16 551–16 558
2025
-
[9]
Hierarchical intention tracking for robust human-robot collaboration in industrial assembly tasks,
Z. Huang, Y .-J. Mun, X. Li, Y . Xie, N. Zhong, W. Liang, J. Geng, T. Chen, and K. Driggs-Campbell, “Hierarchical intention tracking for robust human-robot collaboration in industrial assembly tasks,” in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 9821–9828. 7
2023
-
[10]
R3M: A universal visual representation for robot manipulation,
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta, “R3M: A universal visual representation for robot manipulation,” inConference on Robot Learning (CoRL), 2022
2022
-
[11]
Real-world robot learning with masked visual pre-training,
I. Radosavovic, B. Shi, L. Fu, K. Goldberg, T. Darrell, and J. Malik, “Real-world robot learning with masked visual pre-training,” inConfer- ence on Robot Learning (CoRL), 2023
2023
-
[12]
MS-TCN: Multi-stage temporal convolutional network for action segmentation,
Y . A. Farha and J. Gall, “MS-TCN: Multi-stage temporal convolutional network for action segmentation,” inIEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2019, pp. 3575–3584
2019
-
[13]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 36, 2023
2023
-
[14]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Geet al., “Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification
A. N. Angelopoulos and S. Bates, “A gentle introduction to conformal prediction and distribution-free uncertainty quantification,”CoRR, vol. abs/2107.07511, 2021. [Online]. Available: https://arxiv.org/abs/2107. 07511
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Learning optimal conformal classifiers,
D. Stutz, A. T. Cemgil, A. Doucetet al., “Learning optimal conformal classifiers,”arXiv preprint arXiv:2110.09192, 2021
-
[17]
Universal manipulation interface: In-the-wild robot teach- ing without in-the-wild robots,
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song, “Universal manipulation interface: In-the-wild robot teach- ing without in-the-wild robots,” inRobotics: Science and Systems (RSS), 2024
2024
-
[18]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” inRobotics: Science and Systems (RSS), 2023
2023
-
[19]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
O. X.-E. Collaboration, “Open x-embodiment: Robotic learning datasets and rt-x models,”arXiv preprint arXiv:2310.08864, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Tempo- ral convolutional networks for action segmentation and detection,
C. Lea, M. D. Flynn, R. Vidal, A. Reiter, and G. D. Hager, “Tempo- ral convolutional networks for action segmentation and detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
2017
-
[21]
Diffusion action segmentation,
D. Liu, Q. Li, A. Dinh, T. Jiang, M. Shah, and C. Xu, “Diffusion action segmentation,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 10 139–10 149
2023
-
[22]
Learning to recognize objects in egocentric activities,
A. Fathi, X. Ren, and J. M. Rehg, “Learning to recognize objects in egocentric activities,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2011, pp. 3281–3288
2011
-
[23]
Assembly101: A large-scale multi-view video dataset for understanding procedural activities,
F. Sener, D. Chatterjee, D. Shelepov, K. He, D. Singhania, R. Wang, and A. Yao, “Assembly101: A large-scale multi-view video dataset for understanding procedural activities,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 21 096– 21 106
2022
-
[24]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning,
Y . Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” ininternational conference on machine learning. PMLR, 2016, pp. 1050–1059
2016
-
[25]
V ovk, A
V . V ovk, A. Gammerman, and G. Shafer,Algorithmic learning in a random world. Springer, 2005
2005
-
[26]
Classification with valid and adaptive coverage,
Y . Romano, M. Sesia, and E. Candes, “Classification with valid and adaptive coverage,”Advances in neural information processing systems, vol. 33, pp. 3581–3591, 2020
2020
-
[27]
Uncertainty sets for image classifiers using conformal prediction,
A. Angelopoulos, S. Bates, J. Malik, and M. I. Jordan, “Uncertainty sets for image classifiers using conformal prediction,”arXiv preprint arXiv:2009.14193, 2020
-
[28]
Con- formal prediction under covariate shift,
R. J. Tibshirani, R. Foygel Barber, E. Candes, and A. Ramdas, “Con- formal prediction under covariate shift,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[29]
Conformalized signal temporal logic inference under covariate shift,
Y . Wang, D. Li, M. Cleaveland, R. Tron, and M. Cai, “Conformalized signal temporal logic inference under covariate shift,” 2026. [Online]. Available: https://arxiv.org/abs/2603.27062
-
[30]
Distribution-free uncertainty quantifi- cation for classification under label shift,
A. Podkopaev and A. Ramdas, “Distribution-free uncertainty quantifi- cation for classification under label shift,” inUncertainty in artificial intelligence. PMLR, 2021, pp. 844–853
2021
-
[31]
OpenAI, “GPT-4 technical report,” OpenAI, Tech. Rep., 2023. [Online]. Available: https://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Do as I can, not as I say: Grounding language in robot affordances,
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausmanet al., “Do as I can, not as I say: Grounding language in robot affordances,” inConference on Robot Learning (CoRL), 2022
2022
-
[33]
RT-2: Vision- language-action models transfer web knowledge to robotic control,
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choro- manski, T. Ding, D. Driess, A. Dubey, C. Finnet al., “RT-2: Vision- language-action models transfer web knowledge to robotic control,” in Conference on Robot Learning (CoRL), 2023
2023
-
[34]
X3D: Expanding architectures for efficient video recognition,
C. Feichtenhofer, “X3D: Expanding architectures for efficient video recognition,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 203–213
2020
-
[35]
Quo vadis, action recognition? A new model and the kinetics dataset,
J. Carreira and A. Zisserman, “Quo vadis, action recognition? A new model and the kinetics dataset,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 6299–6308
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.