Predictive Coding with Bayesian Priors via Proximal Gradients
Pith reviewed 2026-06-27 19:05 UTC · model grok-4.3
The pith
Predictive coding arises exactly as continuous-time proximal gradient descent on regularized MAP objectives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
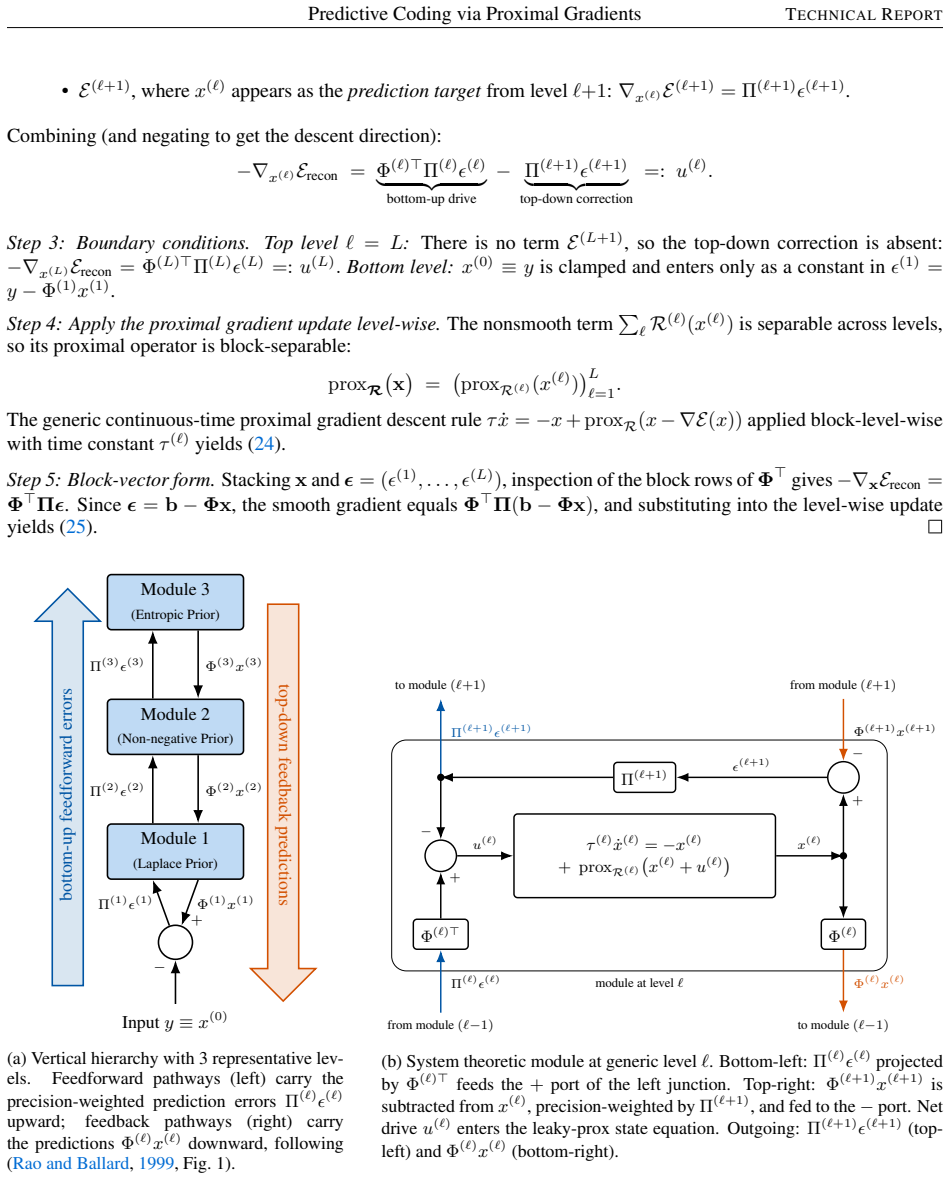
Proximal gradient descent applied to the regularized MAP objective is precisely a leaky firing-rate network: the membrane leak, effective recurrent matrix, local synaptic drive, and static nonlinearity all follow from one optimization principle, reproducing the circuit proposed by Rao and Ballard. The prior selects the nonlinearity via its proximal operator and the likelihood precision sets the gain. In the hierarchical case, classical variable-splitting relaxation of the deep MAP problem yields predictive coding as the interconnection of local and distributed solvers; this replaces the directed generative chain by an undirected Markov random field whose node potentials are the level-wise pr
What carries the argument
Continuous-time proximal gradient flow on the regularized maximum-a-posteriori objective, with the proximal operator of each prior supplying the static nonlinearity of its level.
If this is right
- The membrane leak term and recurrent weight matrix emerge directly from the gradient step on the objective.
- Different choices of prior induce different activation functions in the resulting network without separate design.
- Hierarchical predictive coding corresponds to a standard relaxation of deep MAP estimation rather than an ad-hoc construction.
- Each level in the hierarchy solves its own proximal subproblem using its local prior.
- The overall architecture is that of an undirected graphical model rather than a directed generative chain.
Where Pith is reading between the lines
- Observed nonlinearities in cortical neurons could be interpreted as signatures of specific Bayesian priors used by the brain.
- The same proximal-gradient derivation might be applied to other continuous-time optimization methods to obtain new candidate neural dynamics.
- Predictive coding performance could be improved by choosing priors whose proximal operators better match measured neural response functions.
- The relaxation step suggests that message-passing algorithms on undirected graphs may underlie multi-area cortical computation.
Load-bearing premise
The continuous-time proximal gradient flow on the regularized MAP objective exactly reproduces the firing-rate dynamics without additional approximations or time-scale separations.
What would settle it
Numerically integrate the proximal gradient ODE for a Laplace prior and a Gaussian likelihood and check whether the resulting membrane-potential trajectories coincide exactly with those of the corresponding leaky integrate-and-fire equations under identical parameters.
Figures
read the original abstract
We recast predictive coding as continuous-time proximal gradient descent applied to a regularized maximum-a-posteriori (MAP) objective. We study first a single-level problem and then a multi-level hierarchy. For the single-level problem, we show that proximal gradient descent is precisely a leaky firing-rate network: the membrane leak, the effective recurrent matrix, the local synaptic drive, and the static nonlinearity all follow from one optimization principle, and the resulting circuit is the one proposed by Rao and Ballard. The prior selects the nonlinearity through its proximal operator, and the likelihood precision sets the gain on the observation. For the hierarchy, we show that a classical variable-splitting relaxation of the deep MAP problem yields hierarchical predictive coding as the interconnection of local and distributed solvers. In probabilistic modeling terms, this relaxation replaces the directed generative chain by an undirected Markov random field whose node potentials are the level-wise priors. Each level then applies its own activation function, namely the proximal operator of its prior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript recasts predictive coding as continuous-time proximal gradient descent on a regularized MAP objective. For the single-level case it claims this flow is precisely a leaky firing-rate network whose membrane leak, recurrent matrix, local drive and static nonlinearity are all determined by the objective, reproducing the Rao-Ballard circuit; the prior selects the nonlinearity via its proximal operator. For hierarchies a variable-splitting relaxation of the deep MAP problem is shown to yield hierarchical predictive coding as the interconnection of local and distributed proximal solvers, equivalently replacing the directed generative chain by an undirected MRF whose node potentials are the level-wise priors.
Significance. If the claimed exact equivalences hold, the work supplies a parameter-free optimization derivation of predictive-coding circuits directly from Bayesian MAP estimation, allowing priors to dictate activations without auxiliary assumptions and extending systematically to hierarchies. The absence of fitted parameters and the explicit link between proximal operators and network nonlinearities constitute clear strengths.
major comments (2)
- [Abstract / single-level section] Abstract and single-level derivation: the assertion that continuous-time proximal gradient flow on the regularized MAP objective yields exactly the leaky-integrator dynamics τẋ = −x + abla(likelihood) + proximal nonlinearity must be verified without implicit discretization, time-scale separation, or replacement by the gradient of the Moreau envelope; any such step would contradict the 'precisely' claim.
- [Hierarchy / multi-level section] Hierarchy section: the variable-splitting relaxation is stated to produce hierarchical predictive coding as interconnected solvers, yet it is unclear whether the resulting dynamics converge to the original MAP objective or only to a relaxed surrogate; an explicit statement of the relaxation gap or convergence guarantee is needed to support the multi-level claim.
minor comments (2)
- Notation for the proximal operator and the precision parameter should be introduced once and used uniformly.
- A brief remark on the relation to existing continuous-time analyses of proximal gradient methods would help situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the positive assessment of the work's significance. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract / single-level section] Abstract and single-level derivation: the assertion that continuous-time proximal gradient flow on the regularized MAP objective yields exactly the leaky-integrator dynamics τẋ = −x + abla(likelihood) + proximal nonlinearity must be verified without implicit discretization, time-scale separation, or replacement by the gradient of the Moreau envelope; any such step would contradict the 'precisely' claim.
Authors: The derivation begins from the exact continuous-time proximal gradient flow au \dot{x} = prox_{ ho g}(x - ho abla f(x)) - x, which is the standard ODE limit of the proximal-gradient iteration and contains no discretization. Algebraic rearrangement then yields the leaky-integrator form with the proximal operator appearing directly as the static nonlinearity; neither time-scale separation nor the gradient of the Moreau envelope is invoked. To remove any residual ambiguity around the word 'precisely,' we will insert an expanded, line-by-line verification of this equivalence in the revised single-level section. revision: yes
-
Referee: [Hierarchy / multi-level section] Hierarchy section: the variable-splitting relaxation is stated to produce hierarchical predictive coding as interconnected solvers, yet it is unclear whether the resulting dynamics converge to the original MAP objective or only to a relaxed surrogate; an explicit statement of the relaxation gap or convergence guarantee is needed to support the multi-level claim.
Authors: The manuscript already identifies the construction as a classical variable-splitting relaxation. The resulting network dynamics converge to stationary points of the relaxed objective; they do not in general recover the original constrained MAP problem. We will add a concise paragraph stating the convergence guarantee for the relaxed problem, noting that the relaxation gap vanishes as the splitting penalty tends to infinity, and citing the relevant convergence theory. This clarification will be placed immediately after the derivation of the hierarchical circuit. revision: yes
Circularity Check
No significant circularity: derivation maps external MAP objective and proximal gradient flow onto network dynamics without reduction to fitted inputs or self-citation chains
full rationale
The paper starts from a standard regularized MAP objective (external to the network) and applies the known continuous-time proximal gradient flow. It then algebraically identifies the resulting ODE terms (leak, recurrent matrix, synaptic drive, proximal nonlinearity) with the components of a leaky firing-rate model. This identification is a direct consequence of the flow equations rather than a redefinition or fit. The subsequent observation that the resulting circuit matches the Rao-Ballard architecture is a post-derivation comparison, not a load-bearing premise. No equations are shown to reduce to their own inputs by construction, no parameters are fitted to data and then relabeled as predictions, and no uniqueness theorems or ansatzes are imported via self-citation. The derivation therefore remains self-contained against the external optimization principle.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Proximal gradient descent dynamics are well-defined for the chosen regularized MAP objective in continuous time.
- domain assumption Variable splitting yields an equivalent undirected MRF for the hierarchical MAP problem.
Reference graph
Works this paper leans on
-
[1]
A. Attinger, B. Wang, and G. B. Keller. Visuomotor coupling shapes the functional development of mouse visual cortex. Cell, 169 0 (7): 0 1291--1302, 2017. doi:10.1016/j.cell.2017.05.023
-
[2]
L. F. Barrett and E. K. Miller. Categorization is ‘baked’ into the brain. Nature Reviews Neuroscience, 27 0 (6): 0 435–456, 2026. doi:10.1038/s41583-026-01036-2
-
[3]
A. M. Bastos, W. M. Usrey, R. A. Adams, G. R. Mangun, P. Fries, and K. J. Friston. Canonical microcircuits for predictive coding. Neuron, 76 0 (4): 0 695--711, 2012. doi:10.1016/j.neuron.2012.10.038
-
[4]
S. Betteti, G. Baggio, F. Bullo, and S. Zampieri. Firing rate models as associative memory: Synaptic design for robust retrieval. Neural Computation, 37 0 (10): 0 1807--1838, 2025. doi:10.1162/neco.a.28
-
[5]
S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning, 3 0 (1): 0 1--124, 2010. doi:10.1561/2200000016
-
[6]
C. L. Buckley, C. S. Kim, S. McGregor, and A. K. Seth. The free energy principle for action and perception: A mathematical review. Journal of Mathematical Psychology, 81: 0 55--79, 2017. doi:10.1016/j.jmp.2017.09.004
-
[7]
M. Carandini and D. J. Heeger. Normalization as a canonical neural computation. Nature Reviews Neuroscience, 13 0 (1): 0 51--62, 2012. doi:10.1038/nrn3136
-
[8]
M. \'A . Carreira-Perpi \ n \'a n and W. Wang. Distributed optimization of deeply nested systems. In Int.\ Conf.\ Artificial Intelligence and Statistics (AISTATS), Proceedings of Machine Learning Research, pages 10--19, Reykjavik, Iceland, 2014. PMLR. URL https://proceedings.mlr.press/v33/carreira-perpinan14.html
2014
-
[9]
V. Centorrino, A. Gokhale, A. Davydov, G. Russo, and F. Bullo. Euclidean contractivity of neural networks with symmetric weights. IEEE Control Systems Letters, 7: 0 1724--1729, 2023. doi:10.1109/LCSYS.2023.3278250
-
[10]
V. Centorrino, A. Davydov, A. Gokhale, G. Russo, and F. Bullo. On weakly contracting dynamics for convex optimization. IEEE Control Systems Letters, 8: 0 1745--1750, 2024 a . doi:10.1109/LCSYS.2024.3414348
-
[11]
V. Centorrino, A. Gokhale, A. Davydov, G. Russo, and F. Bullo. Positive competitive networks for sparse reconstruction. Neural Computation, 36 0 (6): 0 1163–1197, 2024 b . doi:10.1162/neco_a_01657
-
[12]
P. L. Combettes and J.-C. Pesquet. Proximal Splitting Methods in Signal Processing, page 185–212. Springer New York, 2011. ISBN 9781441995698. doi:10.1007/978-1-4419-9569-8_10
-
[13]
P. L. Combettes and J.-C. Pesquet. Deep neural network structures solving variational inequalities. Set-Valued and Variational Analysis, 28 0 (3): 0 491--518, 2020. doi:10.1007/s11228-019-00526-z
-
[14]
A. Davydov, V. Centorrino, A. Gokhale, G. Russo, and F. Bullo. Time-varying convex optimization: A contraction and equilibrium tracking approach. IEEE Transactions on Automatic Control, 70 0 (11): 0 7446--7460, 2025. doi:10.1109/TAC.2025.3576043
-
[15]
K. J. Friston. A theory of cortical responses. Philosophical Transactions of the Royal Society B, 360 0 (1456): 0 815--836, 2005. doi:10.1098/rstb.2005.1622
-
[16]
K. J. Friston. Hierarchical models in the brain. PLoS Computational Biology, 4 0 (11): 0 e1000211, 2008. doi:10.1371/journal.pcbi.1000211
-
[17]
K. J. Friston. The free-energy principle: A unified brain theory? Nature Reviews Neuroscience, 11 0 (2): 0 127--138, 2010. doi:10.1038/nrn2787
-
[18]
K. J. Friston, T. FitzGerald , F. Rigoli, P. Schwartenbeck, and G. Pezzulo. Active inference: A process theory. Neural Computation, 29 0 (1): 0 1--49, 2017 a . doi:10.1162/NECO_a_00912
-
[19]
K. J. Friston, T. Parr, and B. de Vries . The graphical brain: Belief propagation and active inference. Network Neuroscience, 1 0 (4): 0 381--414, 2017 b . doi:10.1162/NETN_a_00018
-
[20]
A. Gokhale, A. Davydov, and F. Bullo. Proximal gradient dynamics: Monotonicity , exponential convergence, and applications. IEEE Control Systems Letters, 8: 0 2853--2858, 2024. doi:10.1109/LCSYS.2024.3516632
-
[21]
S. Hassan-Moghaddam and M. R. Jovanovi \'c . Proximal gradient flow and D ouglas- R achford splitting dynamics: G lobal exponential stability via integral quadratic constraints. Automatica, 123: 0 109311, 2021. doi:10.1016/j.automatica.2020.109311
-
[22]
G. B. Keller and T. D. Mrsic-Flogel. Predictive processing: A canonical cortical computation. Neuron, 100 0 (2): 0 424--435, 2018. doi:10.1016/j.neuron.2018.10.003
-
[23]
T. S. Lee and D. Mumford. Hierarchical Bayesian inference in the visual cortex. Journal of the Optical Society of America A, 20 0 (7): 0 1434--1448, 2003. doi:10.1364/josaa.20.001434
-
[24]
J. Marino. Predictive coding, variational autoencoders, and biological connections. Neural Computation, 34 0 (1): 0 1--44, 2022. doi:10.1162/neco_a_01458
-
[25]
B. Millidge, A. Seth, and C. L. Buckley. Predictive coding: A theoretical and experimental review. arXiv preprint, 2021. doi:10.48550/arXiv.2107.12979
-
[26]
B. Millidge, A. Tschantz, and C. L. Buckley. Predictive coding approximates backprop along arbitrary computation graphs. Neural Computation, 34 0 (6): 0 1329--1368, 2022. doi:10.1162/neco_a_01497
-
[27]
B. A. Olshausen and D. J. Field. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature, 381 0 (6583): 0 607--609, 1996. doi:10.1038/381607a0
-
[28]
N. Parikh and S. Boyd. Proximal algorithms. Foundations and Trends in Optimization, 1 0 (3): 0 127--239, 2014. doi:10.1561/2400000003
-
[29]
R. P. N. Rao and D. H. Ballard. Predictive coding in the visual cortex: A functional interpretation of some extra-classical receptive-field effects. Nature Neuroscience, 2 0 (1): 0 79--87, 1999. doi:10.1038/4580
-
[30]
Neural Policy Composition from Free Energy Minimization
F. Rossi, V. Centorrino, F. Bullo, and G. Russo. Neural policy composition from free energy minimization. Technical Report, 2025. doi:10.48550/arXiv.2512.04745. arXiv:2512.04745
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.04745 2025
-
[31]
C. J. Rozell, D. H. Johnson, R. G. Baraniuk, and B. A. Olshausen. Sparse coding via thresholding and local competition in neural circuits. Neural Computation, 20 0 (10): 0 2526--2563, 2008. doi:10.1162/neco.2008.03-07-486
-
[32]
Buckley, Thomas Lukasiewicz, Rajesh P.N
T. Salvatori, A. Mali, C. L. Buckley, T. Lukasiewicz, R. P. Rao, K. Friston, and A. Ororbia. A survey on neuro-mimetic deep learning via predictive coding. Neural Networks, 195: 0 108161, 2026. doi:10.1016/j.neunet.2025.108161
-
[33]
Taylor, R
G. Taylor, R. Burmeister, Z. Xu, B. Singh, A. Patel, and T. Goldstein. Training neural networks without gradients: A scalable ADMM approach. In International Conference on Machine Learning, pages 2722--2731. PMLR, 2016. URL https://proceedings.mlr.press/v48/taylor16.html
2016
-
[34]
von Helmholtz
H. von Helmholtz. Handbuch der Physiologischen Optik . Voss, Leipzig, 1867
-
[35]
J. C. R. Whittington and R. Bogacz. An approximation of the error backpropagation algorithm in a predictive coding network with local Hebbian synaptic plasticity. Neural Computation, 29 0 (5): 0 1229--1262, 2017. doi:10.1162/neco_a_00949
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.