AsyncLane: Decoupling Refinement from Advancement in Diffusion Language Model Decoding
Pith reviewed 2026-06-27 18:53 UTC · model grok-4.3
The pith
AsyncLane decouples block refinement from continuation advancement in diffusion language models by forking lanes at delimiter boundaries, raising throughput up to 3x while preserving output quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
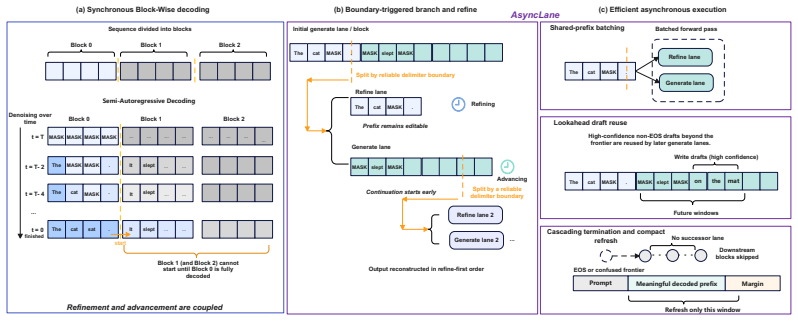
AsyncLane is a training-free scheduler that forks a generate lane at observed delimiter boundaries into a refine lane and a continuation generate lane; the prefix remains editable while the continuation advances before prefix refinement finishes. The resulting lane tree records decoding dependencies and output order, while execution proceeds over the active lane set. Shared-prefix lane batching, lookahead draft reuse, cascading termination, and compact cache refresh with refresh-logit reuse keep model-call cost from scaling directly with the number of lanes. On LLaDA and Dream backbones, this produces the highest TPS in all benchmark-length settings, with peak speedups of 2.95x and 3.04x rel
What carries the argument
AsyncLane lane-forking scheduler that creates a lane tree to record dependencies while allowing asynchronous execution over active lanes with shared-prefix batching and cache optimizations.
If this is right
- Tokens-per-second rises in every tested length regime on both LLaDA and Dream backbones.
- Relative speedups grow larger as generation budgets increase.
- The scheduler works as a drop-in replacement without any retraining.
- Output quality remains competitive with block-wise baselines on mathematical reasoning and code generation tasks.
Where Pith is reading between the lines
- The same lane-forking idea could be tested on other semi-autoregressive or iterative refinement models that expose early stopping signals.
- Longer sequences would likely see the largest absolute time savings, which matters for applications that already push context limits.
- If delimiter detection proves reliable across more domains, the approach might reduce the effective latency gap between diffusion and autoregressive LLMs.
Load-bearing premise
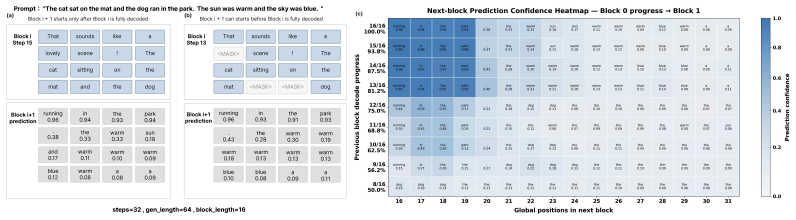
Once a block shows a reliable delimiter or stable semantic prefix, the model can safely generate the next block without waiting for every remaining token in the current block to be finalized.
What would settle it
A side-by-side run on the same prompts where AsyncLane outputs show measurably lower accuracy or coherence than standard block-wise decoding on the same total denoising budget.
Figures
read the original abstract
Block-wise semi-autoregressive decoding is the standard inference paradigm for diffusion large language models (DLMs), but it imposes a strict dependency between blocks: the next block cannot begin until the current block is fully decoded or its denoising budget is exhausted. We observe that once a block exposes a reliable delimiter boundary or stable semantic prefix, continuation generation need not wait for every residual token to be resolved. We propose AsyncLane, a training-free decoding scheduler that decouples refinement from advancement. AsyncLane forks a generate lane at observed delimiter boundaries into a refine lane and a continuation generate lane: the prefix remains editable, while the continuation advances before prefix refinement finishes. The resulting lane tree records decoding dependencies and output order, while execution proceeds over the active lane set. To make this asynchronous schedule efficient under bidirectional attention, AsyncLane combines shared-prefix lane batching, lookahead draft reuse, cascading termination, and compact cache refresh with refresh-logit reuse, preventing model-call cost from scaling directly with the number of lanes. AsyncLane is a drop-in replacement for block-wise DLM samplers and requires no retraining. Experiments on mathematical reasoning and code generation show that AsyncLane consistently improves throughput while maintaining competitive quality. Across LLaDA and Dream backbones, AsyncLane achieves the highest TPS in all evaluated benchmark-length settings; relative to the fastest competing baseline, it reaches peak speedups of 2.95x on LLaDA and 3.04x on Dream, with especially large gains under longer generation budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AsyncLane, a training-free decoding scheduler for diffusion language models that decouples block refinement from continuation advancement. It forks lanes at observed delimiter boundaries or stable semantic prefixes into a refine lane (editable prefix) and a continuation generate lane, using a lane tree to track dependencies while employing shared-prefix batching, lookahead draft reuse, cascading termination, and compact cache refresh with refresh-logit reuse to control costs under bidirectional attention. Experiments on mathematical reasoning and code generation tasks across LLaDA and Dream backbones report that AsyncLane achieves the highest tokens-per-second in all settings, with peak speedups of 2.95× and 3.04× relative to the fastest baseline, especially under longer generation budgets, while maintaining competitive quality.
Significance. If the quality-maintenance claim holds under the asynchronous forking, AsyncLane would offer a practical, training-free route to higher inference throughput for diffusion LLMs, a growing class of models. The listed optimizations (shared-prefix batching, cascading termination, refresh-logit reuse) are concrete engineering contributions that prevent linear scaling of model calls with lane count. The drop-in nature and absence of new parameters or retraining are explicit strengths.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments: The central claim that AsyncLane 'maintains competitive quality' while achieving the reported speedups rests on the unverified assumption that forking at delimiter boundaries yields stable prefixes whose partial refinement does not alter downstream continuation outputs. No quantitative bound is given on the frequency with which the delimiter heuristic produces stable prefixes, nor are exact token-sequence comparisons or downstream metric differences reported between AsyncLane and the synchronous block-wise baseline on identical random seeds.
- [Method] The scheduler description states that 'the resulting lane tree records decoding dependencies and output order' and that the listed mechanisms 'prevent model-call cost from scaling directly with the number of lanes,' yet no ablation isolates the contribution of each mechanism (shared-prefix batching, lookahead draft reuse, cascading termination, compact cache refresh) to the observed 2.95–3.04× speedups, leaving unclear which component is load-bearing for the throughput result.
minor comments (2)
- [Method] Notation for the lane tree and active lane set is introduced without an accompanying diagram or pseudocode listing the fork/terminate conditions, which would clarify execution flow.
- [Abstract] The abstract claims 'consistent throughput gains' and 'highest TPS in all evaluated benchmark-length settings' but does not specify the exact quality metrics (e.g., exact match, pass@k) or statistical tests used to establish 'competitive quality.'
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the practical value of AsyncLane as a training-free scheduler. We address each major comment below with clarifications and commitments to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments: The central claim that AsyncLane 'maintains competitive quality' while achieving the reported speedups rests on the unverified assumption that forking at delimiter boundaries yields stable prefixes whose partial refinement does not alter downstream continuation outputs. No quantitative bound is given on the frequency with which the delimiter heuristic produces stable prefixes, nor are exact token-sequence comparisons or downstream metric differences reported between AsyncLane and the synchronous block-wise baseline on identical random seeds.
Authors: The manuscript supports the quality claim through downstream task metrics on mathematical reasoning and code generation benchmarks, where AsyncLane remains competitive with block-wise baselines. We acknowledge that direct token-sequence comparisons under identical random seeds and a quantitative bound on stable-prefix frequency are not reported. In revision we will add an analysis of prefix stability frequency across the evaluated tasks together with any measurable differences in output sequences or metrics under controlled seeding. revision: partial
-
Referee: [Method] The scheduler description states that 'the resulting lane tree records decoding dependencies and output order' and that the listed mechanisms 'prevent model-call cost from scaling directly with the number of lanes,' yet no ablation isolates the contribution of each mechanism (shared-prefix batching, lookahead draft reuse, cascading termination, compact cache refresh) to the observed 2.95–3.04× speedups, leaving unclear which component is load-bearing for the throughput result.
Authors: We agree that isolating the contribution of each optimization would improve clarity. The reported speedups reflect the full system; we will add a component-wise ablation study in the revised manuscript that quantifies the incremental effect of shared-prefix batching, lookahead draft reuse, cascading termination, and compact cache refresh on throughput. revision: yes
Circularity Check
No circularity: empirical scheduler with external validation
full rationale
The paper introduces AsyncLane as a training-free decoding scheduler whose core claims rest on measured throughput and quality against external baselines (LLaDA, Dream, competing methods). No equations, fitted parameters, or self-citations are presented as load-bearing derivations; the method is described as a drop-in replacement whose benefits are demonstrated experimentally rather than derived by construction from its own inputs. The delimiter-forking heuristic is an engineering assumption whose validity is tested via benchmarks, not presupposed by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bidirectional attention in DLMs permits the described shared-prefix batching and compact cache refresh without correctness loss.
invented entities (2)
-
lane tree
no independent evidence
-
refine lane and continuation generate lane
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
-
[2]
Wenrui Bao, Zhiben Chen, Dan Xu, and Yuzhang Shang. Learning to parallel: Accelerating diffusion large language models via learnable parallel decoding.arXiv preprint arXiv:2509.25188,
-
[3]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
-
[4]
Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
-
[5]
Abdelfattah, Jae-sun Seo, Zhiru Zhang, and Udit Gupta
Zhanqiu Hu, Jian Meng, Yash Akhauri, Mohamed S. Abdelfattah, Jae-sun Seo, Zhiru Zhang, and Udit Gupta. Flashdlm: Accelerating diffusion language model inference via efficient kv caching and guided diffusion.arXiv preprint arXiv:2505.21467,
-
[6]
Accelerating diffusion llms via adaptive parallel decoding.arXiv preprint arXiv:2506.00413,
Daniel Israel, Guy Van den Broeck, and Aditya Grover. Accelerating diffusion llms via adaptive parallel decoding.arXiv preprint arXiv:2506.00413,
-
[7]
Yuchu Jiang, Yue Cai, Xiangzhong Luo, Jiale Fu, Jiarui Wang, Chonghan Liu, and Xu Yang. d2cache: Accelerating diffusion-based llms via dual adaptive caching.arXiv preprint arXiv:2509.23094,
- [8]
-
[9]
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834,
-
[10]
Guanxi Lu, Hao Chen, Yuto Karashima, Zhican Wang, Daichi Fujiki, and Hongxiang Fan. Adablock-dllm: Semantic-aware diffusion llm inference via adaptive block size.arXiv preprint arXiv:2509.26432,
-
[11]
dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781,
Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781,
-
[12]
Attention is all you need for kv cache in diffusion llms.arXiv preprint arXiv:2510.14973,
Quan Nguyen-Tri, Mukul Ranjan, and Zhiqiang Shen. Attention is all you need for kv cache in diffusion llms.arXiv preprint arXiv:2510.14973,
-
[13]
Large language diffusion models.arXiv preprint arXiv:2502.09992,
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji- Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992,
-
[14]
Large Language Diffusion Models
doi: 10.48550/arXiv.2502.09992. 10 Yu-Yang Qian, Junda Su, Lanxiang Hu, Peiyuan Zhang, Zhijie Deng, Peng Zhao, and Hao Zhang. d3llm: Ultra-fast diffusion llm using pseudo-trajectory distillation.arXiv preprint arXiv:2601.07568,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.09992
-
[15]
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T
doi: 10.48550/arXiv.2601.07568. Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T. Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models.arXiv preprint arXiv:2406.07524,
-
[16]
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding.arXiv preprint arXiv:2505.22618,
-
[17]
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
doi: 10.48550/arXiv.2505.22618. Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.22618
-
[18]
doi: 10.48550/arXiv.2508.15487. 11
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.15487
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.