CACR:Reinforcing Temporal Answer Grounding in Instructional Video via Candidate-Aware Causal Reasoning
Pith reviewed 2026-06-27 18:55 UTC · model grok-4.3
The pith
Candidate-aware causal reasoning locates answer segments in instructional videos by first selecting K candidates then applying logic reasoning with rejection rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The CACR framework first applies a Visual-Language Pre-training based Candidate Selection algorithm to produce K candidate segments, then feeds them to a temporal logic reasoning module that uses a rejection reward mechanism and is optimized with Group Relative Policy Optimization to perform robust causal inference for temporal answer grounding.
What carries the argument
The two-stage CACR pipeline: visual-language pre-training candidate selection to produce K segments, followed by temporal logic reasoning with rejection reward and GRPO optimization.
If this is right
- The method reaches state-of-the-art mIoU on six benchmarks for temporal answer grounding.
- It supplies a new perspective on reasoning-based retrieval from long videos.
- It reduces sensitivity to irrelevant content by narrowing options before reasoning.
- It improves handling of length mismatch and semantic complexity through the two-stage design.
Where Pith is reading between the lines
- The rejection reward component might transfer to other reinforcement-learning setups that involve selecting from noisy video candidates.
- Replacing the pre-training candidate selector with a stronger model could be tested as a direct extension without changing the reasoning stage.
- The framework's emphasis on causal logic after candidate filtering could apply to non-instructional video question-answering domains.
Load-bearing premise
The initial candidate selection step will reliably place the true answer segment among the small set of K candidates it produces.
What would settle it
An experiment that replaces the candidate selection step with random segments and measures whether the reasoning module alone can still reach the reported mIoU levels on the benchmarks.
Figures
read the original abstract
The task of temporal answer grounding in instructional video (TAGV), which aims to locate precise video segments that respond to natural language queries, is increasingly important for direct video answer retrieval. This task remains challenging due to the need to comprehend semantically complex questions and to address the significant length mismatch between untrimmed videos and short target moments. Existing methods often suffer from sensitivity to irrelevant content or insufficient visual reasoning capabilities. To tackle these limitations, we propose a Candidate-Aware Causal Reasoning (CACR) framework. Our approach first employs a Visual-Language Pre-training based Candidate Selection (VBCS) algorithm to efficiently generate K candidate segments, then applies a temporal logic reasoning module enhanced by a rejection reward mechanism and optimized via Group Relative Policy Optimization (GRPO) for robust inference. Extensive experiments on six benchmarks demonstrate that our method achieves state-of-the-art performance in terms of mean Intersection-over-Union (mIoU), providing a new perspective for reasoning-based retrieval in long videos.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Candidate-Aware Causal Reasoning (CACR) framework for temporal answer grounding in instructional videos (TAGV). It first applies a Visual-Language Pre-training based Candidate Selection (VBCS) module to produce a small set of K candidate segments, then performs temporal logic reasoning augmented by a rejection reward and optimized with Group Relative Policy Optimization (GRPO). The central empirical claim is that this pipeline attains state-of-the-art mean Intersection-over-Union (mIoU) across six benchmarks and supplies a new perspective on reasoning-based retrieval for long videos.
Significance. If the reported gains are reproducible and the candidate-selection assumption holds, the separation of efficient candidate generation from subsequent causal reasoning offers a practical route to handling semantic complexity and extreme length mismatch. The explicit use of GRPO for policy optimization and the rejection-reward mechanism constitute concrete, falsifiable contributions that could be adopted by follow-up work.
major comments (2)
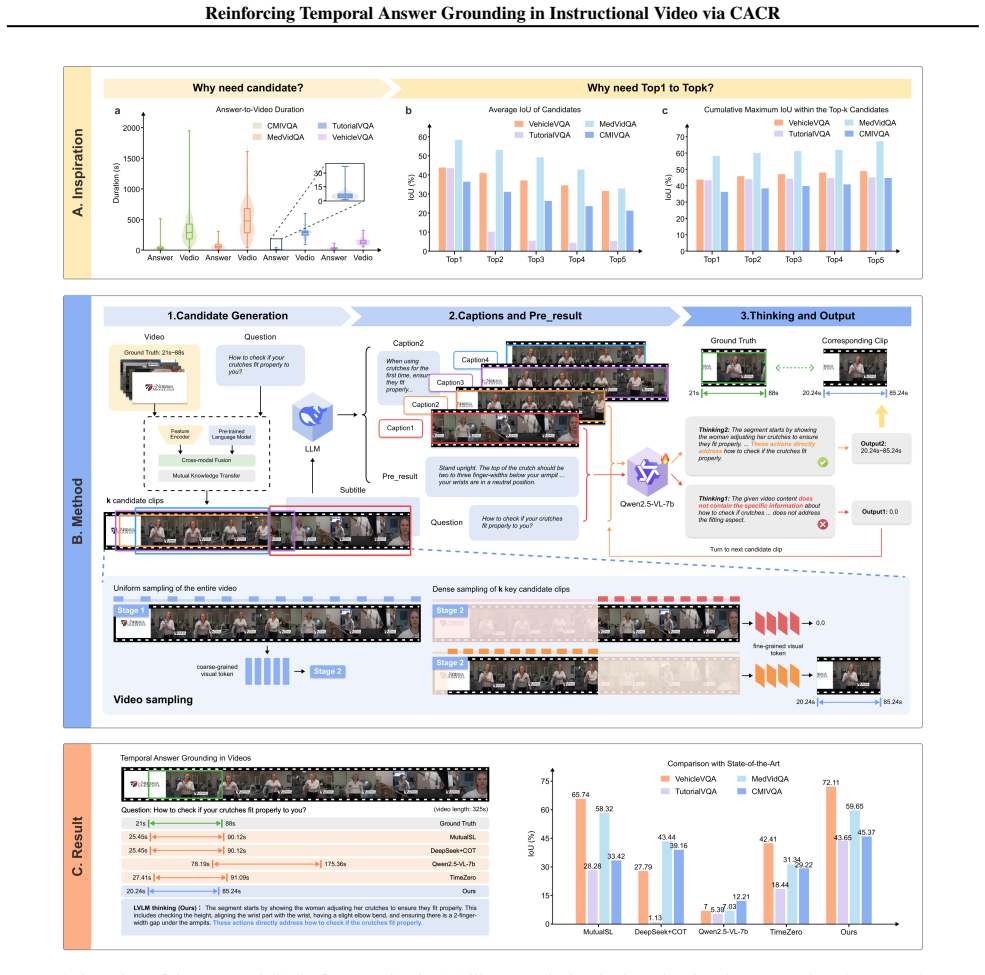
- [§3.2] §3.2 (VBCS description): the central claim that SOTA mIoU is attributable to the temporal logic reasoning module presupposes that VBCS recall@K is near-perfect and that the ground-truth segment is reliably present among the K candidates. No recall@K figures, no ablation removing the true segment from the candidate pool, and no failure-case analysis are supplied; without these the performance attribution cannot be verified.
- [§4] §4 (Experiments): the abstract and method sections assert SOTA mIoU on six benchmarks, yet the provided text supplies neither the full set of baseline numbers, statistical significance tests, nor variance across runs. This omission prevents assessment of whether the reported gains exceed the variability of prior methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important aspects of experimental validation that strengthen the manuscript. We address each point below and will revise the paper to incorporate the suggested analyses.
read point-by-point responses
-
Referee: [§3.2] §3.2 (VBCS description): the central claim that SOTA mIoU is attributable to the temporal logic reasoning module presupposes that VBCS recall@K is near-perfect and that the ground-truth segment is reliably present among the K candidates. No recall@K figures, no ablation removing the true segment from the candidate pool, and no failure-case analysis are supplied; without these the performance attribution cannot be verified.
Authors: We agree that explicit verification of VBCS recall is necessary to attribute gains to the reasoning module. In the revised manuscript we will add recall@K (K=1,5,10) results for VBCS on all six benchmarks. We will also include a controlled ablation that removes the ground-truth segment from the candidate pool and report the resulting mIoU drop, plus a dedicated failure-case analysis subsection. These additions will directly address the attribution concern. revision: yes
-
Referee: [§4] §4 (Experiments): the abstract and method sections assert SOTA mIoU on six benchmarks, yet the provided text supplies neither the full set of baseline numbers, statistical significance tests, nor variance across runs. This omission prevents assessment of whether the reported gains exceed the variability of prior methods.
Authors: We acknowledge that the initial submission omitted full baseline tables, significance tests, and run-to-run variance. The revised version will present the complete per-benchmark baseline mIoU numbers, paired t-test p-values against the strongest baselines, and mean ± standard deviation computed over five independent runs with different random seeds. This will allow direct evaluation of whether the reported improvements are statistically reliable. revision: yes
Circularity Check
No circularity; empirical benchmark claims with no derivations or self-referential reductions
full rationale
The provided abstract and description contain no equations, derivations, or mathematical claims that could reduce to self-definition, fitted inputs renamed as predictions, or self-citation chains. The method is described as a pipeline (VBCS candidate selection followed by reasoning with GRPO), with success measured by external SOTA mIoU on six benchmarks. This is standard empirical validation against held-out data rather than any internal construction or load-bearing self-reference. No uniqueness theorems, ansatzes, or renamings of known results appear. The central claim remains falsifiable via benchmark performance and does not collapse to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
How to check if your crutches fit properly to you
URL https://openai.com/index/ gpt-3-5-turbo-fine-tuning-and-api-updates/ . Official product announcement for GPT-3.5 Turbo. Qu, X., Tang, P., Zou, Z., Cheng, Y ., Dong, J., Zhou, P., and Xu, Z. Fine-grained iterative attention network for temporal language localization in videos. InProceedings of the 28th ACM International Conference on Multimedia, pp. 42...
-
[2]
For Candidate 1 ([173.37, 317.59]), the model receives the corresponding subtitle and pre-answer. The reasoning output is: "ans": "<think> The given video content does not contain the 13 Reinforcing Temporal Answer Grounding in Instructional Video via CACR specific information about how to check if crutches fit properly to someone. The video provides inst...
-
[3]
The output is: "ans": "<think> The segment starts by showing the woman adjusting her crutches to ensure they fit properly
For Candidate 2 ([20.24, 179.29]), the model performs cross-modal reasoning based on its subti- tle and the shared pre-answer. The output is: "ans": "<think> The segment starts by showing the woman adjusting her crutches to ensure they fit properly. This includes checking the height, aligning the wrist part with the wrist, having a slight elbow bend, and ...
2023
-
[4]
causal decision-making within a finite candidate set
A lightweight VBCS module filters a small set of candidate segments C={c k = (t k s , tk e)} from the full video, transforming the long-video search into “causal decision-making within a finite candidate set.” 16 Reinforcing Temporal Answer Grounding in Instructional Video via CACR
-
[5]
For each candidate ck, a denser frame sequence F k candidate is extracted using a higher sampling rate fcandidate. After assembling multi-source information, it is iteratively fed to the LVLM for verification: Inputk LVLM =Assemble F k candidate, Ck vis Subtitle,Pre-answer, Q ok =LVLM Inputk LVLM
-
[6]
hypothesis-verification
Decision Rule (first-valid with explicit fallback):Given the candidate set C={c 1, c2, . . . , cK} ordered by VBCS confidence, the LVLM is invoked sequentially onc1, c2, . . . , cK. For each outputo k: – if ok = [t∗ s, t∗ e] with t∗ s, t∗ e ∈R + (i.e., a valid temporal interval), ok isimmediatelyreturned as the final prediction and the iteration terminate...
2023
-
[7]
which segments might be relevant to the question
Hierarchical Causal Reasoning Pipeline Aligns with Task NatureTraditional end-to-end methods directly map the query to the entire video, making them susceptible to irrelevant segments and prone to learning spurious statistical correlations. GRPO, instead, simulates human reasoning cognition through a structured pipeline. It first employs a Visual- Languag...
-
[8]
which candidate is better,
Relative Advantage Evaluation Mechanism Addresses Abstraction and AmbiguityFaced with abstract queries, multiple candidate segments might be partially relevant based solely on surface-level visual features (e.g., the presence of the same object), yet only a few fully encompass the causal chain required to complete the task. The core of GRPO – the relative...
-
[9]
admitting uncertainty
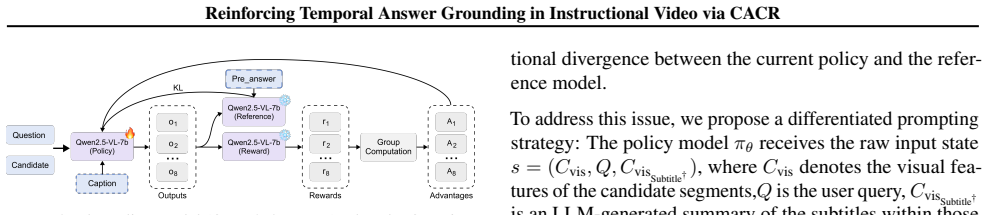
IoU Reward and Rejection Mechanism Enable Precise and Robust OptimizationThe composite reward function of GRPO is key to its efficient training: Rtotal(oi) =R fmt(oi) + (1−α)·R IoU(oi) +α·R rej(oi) whereR fmt is a formatting bonus, and RIoU(oi) = |[tpred s , tpred e ]∩[t GT s , tGT e ]| |[tpred s , tpred e ]∪[t GTs , tGTe ]| directly uses the core evaluat...
-
[10]
how” or “why
Semantic Enhancement and Regularization Constraints Ensure Reasoning PlausibilityTo bridge the semantic gap between abstract queries and visual content, GRPO integrates additional semantic information S (e.g., text descriptions generated based on candidate segments) during the reasoning process. This provides the model with a high-level contextual underst...
-
[11]
Temporal Sampling:The base frame count Nbase =L clip ×FPS target (e.g., 2 fps) is determined, rounded to a power of 2, and constrained within the interval[4,768]to obtain the final sampled frame countN frames
-
[12]
Pixel Budget Calculation:This is the core constraint step. Based on the sequence length limit, the model allocates a total pixel budget for all frames in the current segment, thereby calculating themaximum usable pixels per frame: MaxPixelsPerFrame≈min VIDEO FRAME MAX PIXELS, 0.9×MODEL SEQ LEN×(image factor)2 Nframes ×FRAME FACTOR where image factor= 28 ....
-
[13]
Spatial Resolution Adjustment:While maintaining the aspect ratio, an intelligent scaling function adjusts the resolution per frame to satisfy: (a) height and width are divisible by 28; (b) the total pixel count lies between a set lower bound (min pixels= 16×28×28) and the MaxPixelsPerFrame calculated in the previous step
-
[14]
Recall@5
Visual Token Generation:Based on the final resolution (H, W) and the visual Transformer patch size (14), the tokens per frame are calculated as TokensPerFrame= (H/14)×(W/14) . The total visual tokens for the segment are Tlvlm =N frames ×TokensPerFrame, which must satisfyT lvlm ≤0.9×MODEL SEQ LEN. The adaptive strategy of the LVLM module achieves an optima...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.