The Consistency Illusion: How Multi-Agent Debate Hides Reasoning Misalignment
Pith reviewed 2026-06-27 17:54 UTC · model grok-4.3
The pith
Multi-agent debate in medical QA makes agents agree on answers while making their reasoning less similar.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
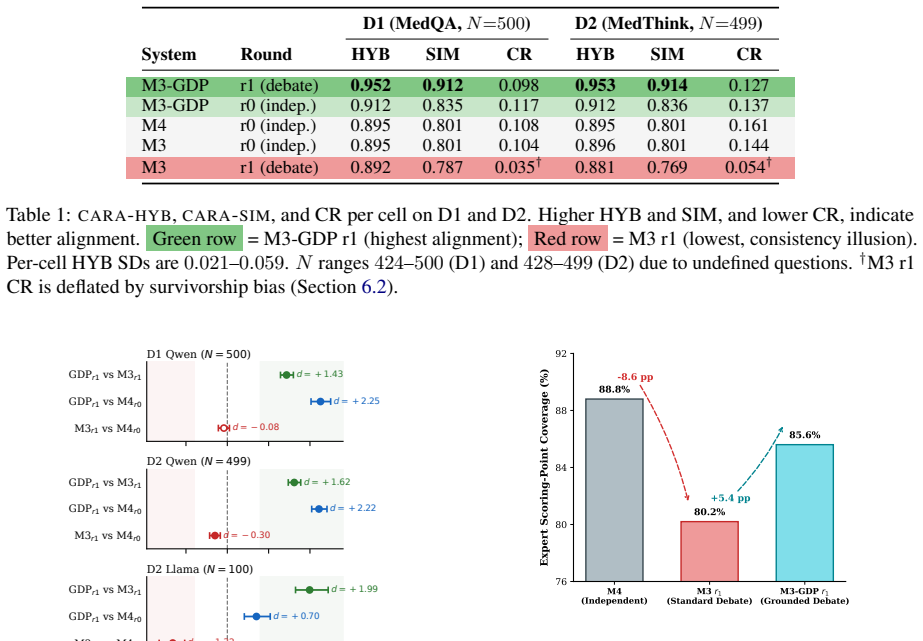
The paper establishes that answer-level consensus in multi-agent debate does not imply reasoning-level alignment. On MedQA-USMLE and MedThink-Bench, standard debate lowers detectable answer contradictions yet decreases semantic similarity of reasoning chains according to the CARA metrics; the resulting consistency illusion is presented as a distinct failure mode. The Grounded Debate Protocol corrects the misalignment by requiring agents to commit to named medical facts and take explicit stances on other agents' claims, producing Cohen's d improvements of +1.43 to +1.99 across two datasets and two backbone models while leaving system architecture unchanged.
What carries the argument
CARA (Cross-Agent Reasoning Alignment) metrics that quantify semantic similarity of reasoning chains among agents who reach the same answer.
If this is right
- Answer consensus alone cannot be treated as a reliability signal in safety-critical multi-agent systems.
- Standard debate protocols can actively reduce reasoning consistency even as they increase answer agreement.
- The Grounded Debate Protocol improves reasoning alignment without increasing the number of LLM calls or changing system architecture.
- Cross-agent reasoning alignment should be audited alongside accuracy when deploying multi-agent systems in medical domains.
Where Pith is reading between the lines
- The same divergence between answer agreement and reasoning alignment could appear in non-medical domains where multi-agent debate is used for factual or technical questions.
- Systems might benefit from hybrid protocols that combine debate with automated checks for reasoning similarity before accepting consensus.
- The illusion suggests that evaluation benchmarks for multi-agent systems should include reasoning-chain comparison in addition to final-answer accuracy.
Load-bearing premise
The CARA metrics capture genuine differences in reasoning rather than merely differences in surface wording or phrasing.
What would settle it
If human experts rate pairs of reasoning chains as aligned or misaligned and the CARA scores fail to match those ratings on a held-out set of medical QA debates, the claim that debate produces a measurable consistency illusion would be undermined.
Figures


read the original abstract
Multi-agent LLM systems for medical question answering often treat consensus as a reliability signal: if multiple agents agree on an answer, it is presumed trustworthy. However, answer-level consensus does not entail reasoning-level alignment. We introduce CARA (Cross-Agent Reasoning Alignment), a family of automated metrics that measure whether agents who agree on an answer also agree on the reasoning. Applying CARA to a standard debate system on two medical QA benchmarks, MedQA-USMLE and MedThink-Bench, we identify the consistency illusion: a failure mode where debate reduces detectable contradictions between agents while simultaneously decreasing the semantic similarity of their reasoning chains; agents appear to agree more but reason less consistently. To improve this misalignment, we propose the Grounded Debate Protocol (GDP), a prompt-level intervention that requires agents to commit to named medical facts and take explicit stances on other agents' claims. GDP produces large, consistent alignment improvements, with Cohen's d ranging from +1.43 to +1.99, across two datasets and two backbone models, without adding LLM calls or modifying system architecture. Our results motivate cross-agent reasoning alignment as a quantity to audit alongside accuracy in safety-critical domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that answer-level consensus in multi-agent LLM debate for medical QA does not imply reasoning-level alignment. It introduces the CARA family of metrics to quantify whether agreeing agents share similar reasoning chains, reports that standard debate produces a 'consistency illusion' (increased answer agreement but decreased reasoning similarity) on MedQA-USMLE and MedThink-Bench, and proposes the Grounded Debate Protocol (GDP) prompt intervention that yields large alignment gains (Cohen's d +1.43 to +1.99) across two datasets and two models without extra LLM calls.
Significance. If the CARA metrics are shown to be valid and independent measures of reasoning alignment, the work identifies a practically relevant failure mode for using consensus as a reliability signal in safety-critical domains and supplies a lightweight, architecture-preserving intervention; the reported effect sizes and cross-dataset consistency are strengths.
major comments (2)
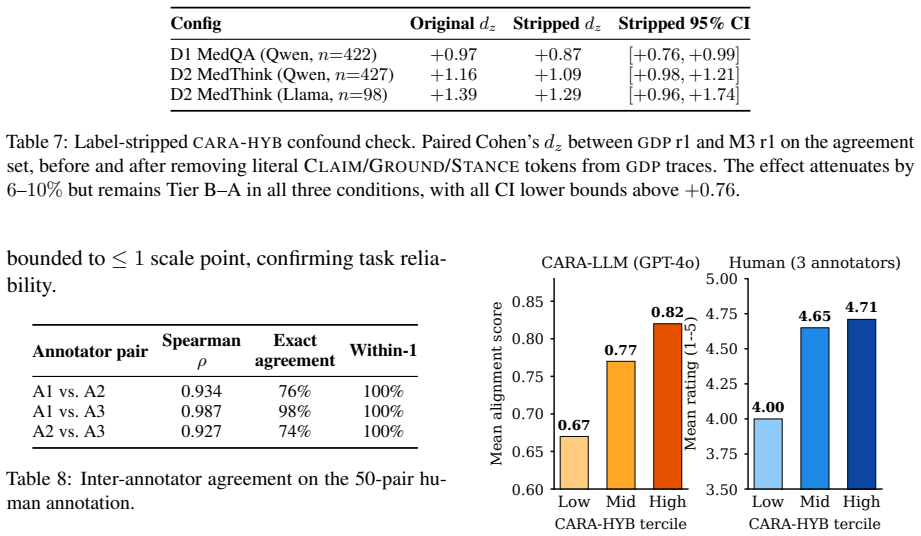
- [Abstract / §3] Abstract and §3 (CARA construction): the claim that CARA measures reasoning-level alignment (rather than surface textual similarity) is load-bearing for the consistency-illusion result, yet the abstract provides no details on metric construction, validation against human judgments, controls for length or lexical overlap, or statistical tests separating semantic from surface effects; without these the central interpretation cannot be assessed.
- [§4] §4 (experimental results): the reported Cohen's d values for GDP are large, but the manuscript does not specify how reasoning chains were extracted, how contradictions were detected, or whether data exclusion rules or multiple-comparison corrections were applied; these details are required to evaluate whether the illusion and its mitigation are robust.
minor comments (2)
- [§3] Notation for the CARA family should be defined once with explicit formulas rather than described narratively.
- [§4] The two benchmarks are named but their construction, size, and any filtering steps are not summarized; a short table would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight areas where additional clarity on CARA construction and experimental details will strengthen the manuscript. We address each point below and will incorporate the requested information in the revision.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (CARA construction): the claim that CARA measures reasoning-level alignment (rather than surface textual similarity) is load-bearing for the consistency-illusion result, yet the abstract provides no details on metric construction, validation against human judgments, controls for length or lexical overlap, or statistical tests separating semantic from surface effects; without these the central interpretation cannot be assessed.
Authors: We agree that the abstract should include more detail on CARA to support the central claims. In the revised manuscript we will expand the abstract to summarize CARA construction (embedding-based semantic similarity on extracted reasoning chains) and note the inclusion of controls and validation. In §3 we will add explicit subsections describing validation against human judgments, length and lexical-overlap controls, and statistical tests that separate semantic from surface effects. These additions will make the reasoning-alignment interpretation directly assessable. revision: yes
-
Referee: [§4] §4 (experimental results): the reported Cohen's d values for GDP are large, but the manuscript does not specify how reasoning chains were extracted, how contradictions were detected, or whether data exclusion rules or multiple-comparison corrections were applied; these details are required to evaluate whether the illusion and its mitigation are robust.
Authors: We agree these methodological details are necessary for evaluating robustness. In the revised §4 we will specify the reasoning-chain extraction procedure, the exact method used to detect contradictions, the data-exclusion rules applied, and any multiple-comparison corrections. These clarifications will allow readers to assess the reliability of the reported effect sizes and the consistency illusion. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The abstract introduces CARA metrics and the consistency illusion as new quantities measured on debate outputs, with GDP as an independent prompt intervention. No equations, definitions, or self-citations are shown that would make the reported misalignment or alignment gains reduce by construction to fitted parameters, renamed inputs, or prior author results. The central claim (debate can increase answer consensus while decreasing reasoning similarity) is presented as an empirical observation on external benchmarks, not a tautology. Absent any load-bearing step that quotes to a self-referential reduction, the paper's chain is treated as independent.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Answer-level consensus serves as a reliability signal in multi-agent LLM systems for medical QA
invented entities (2)
-
CARA (Cross-Agent Reasoning Alignment) metrics
no independent evidence
-
Grounded Debate Protocol (GDP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
Improving Factuality and Reasoning in Language Models through Multiagent Debate , author =. Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
-
[2]
2024 , address =
Tang, Xiangru and Zou, Anni and Zhang, Zhuosheng and Zhao, Yilun and Zhang, Xingyao and Cohan, Arman and Gerstein, Mark , booktitle =. 2024 , address =
2024
-
[3]
2024 , url =
Kim, Yubin and Park, Chanwoo and Jeong, Hyewon and Chan, Yik Siu and Xu, Xuhai and McDuff, Daniel and Breazeal, Cynthia and Park, Hae Won , booktitle =. 2024 , url =
2024
-
[4]
Model confrontation and collaboration:
Sun, Xinti and Hong, Qiyang and Zhang, Mengyan and Li, Yuyan and Chen, Tingwei and Huang, Zigeng and Liang, Guihan and Tang, Wenjun and Xu, Sulin and Ni, Xiaolin and Pang, Junling and Wan, Peixing and Long, Erping , journal=. Model confrontation and collaboration:. 2026 , doi =
2026
-
[5]
2025 , url =
Mishra, Pranav Pushkar and Arvan, Mohammad and Zalake, Mohan , journal =. 2025 , url =
2025
-
[6]
2025 , eprint=
Agent Hospital: A Simulacrum of Hospital with Evolvable Medical Agents , author=. 2025 , eprint=
2025
-
[7]
2026 , publisher=
Schmidgall, Samuel and Ziaei, Rojin and Harris, Carl and Kim, Ji Woong and Reis, Eduardo and Jopling, Jeffrey and Moor, Michael , journal=. 2026 , publisher=
2026
-
[8]
2025 , url =
Zhu, Yinghao and He, Ziyi and Hu, Haoran and Zheng, Xiaochen and Zhang, Xichen and Wang, Zixiang and Gao, Junyi and Ma, Liantao and Yu, Lequan , journal =. 2025 , url =
2025
-
[9]
Measuring Faithfulness in Chain-of-Thought Reasoning
Measuring Faithfulness in Chain-of-Thought Reasoning , author =. arXiv preprint arXiv:2307.13702 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
The Thirteenth International Conference on Learning Representations (ICLR) , year =
Walk the Talk? Measuring the Faithfulness of Large Language Model Explanations , author =. The Thirteenth International Conference on Learning Representations (ICLR) , year =
-
[11]
Faithful or Just Plausible? Evaluating Faithfulness for Medical Reasoning in Closed-Source
Afolabi, Halimat and Afolabi, Zainab and Friel, Elizabeth and Roberts, Jude and Ji-Xu, Antonio and Chen, Lloyd and Ogbomo, Egheosa and Imevbore, Emiliomo and Eneje, Phil and El Ouahidi, Wissal and Sohal, Aaron and Kennan, Alisa and Srivastava, Shreya and Vairavan, Anirudh and Napitu, Laura and McClure, Katie , booktitle =. Faithful or Just Plausible? Eval...
2025
-
[12]
2023 , url =
Golovneva, Olga and Chen, Moya and Poff, Spencer and Corredor, Martin and Zettlemoyer, Luke and Galley, Michel and Celikyilmaz, Asli , booktitle =. 2023 , url =
2023
-
[13]
Ranking Generated Summaries by Correctness: An Interesting but Challenging Application for Natural Language Inference , author =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , month = jul, year =. doi:10.18653/v1/P19-1213 , pages =
-
[14]
On measuring faithfulness or self-consistency of natural language explanations
On Measuring Faithfulness or Self-consistency of Natural Language Explanations , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = aug, year =. doi:10.18653/v1/2024.acl-long.329 , pages =
-
[15]
Advances in Neural Information Processing Systems 38 (NeurIPS) , year =
Debate or Vote: Which Yields Better Decisions in Multi-Agent Large Language Models? , author =. Advances in Neural Information Processing Systems 38 (NeurIPS) , year =
-
[16]
Transactions on Machine Learning Research , year =
More Agents Is All You Need , author =. Transactions on Machine Learning Research , year =
-
[17]
Wang, Qineng and Wang, Zihao and Su, Ying and Tong, Hanghang and Song, Yangqiu , editor =. Rethinking the Bounds of. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = aug, year =. doi:10.18653/v1/2024.acl-long.331 , pages =
-
[18]
Single-Agent
Tran, Dat and Kiela, Douwe , journal =. Single-Agent. 2026 , url =
2026
-
[19]
2025 , eprint=
Stop Overvaluing Multi-Agent Debate -- We Must Rethink Evaluation and Embrace Model Heterogeneity , author=. 2025 , eprint=
2025
-
[20]
Findings of the Association for Computational Linguistics: ACL 2025 , month = jul, year =
Pitre, Priya and Ramakrishnan, Naren and Wang, Xuan , editor =. Findings of the Association for Computational Linguistics: ACL 2025 , month = jul, year =. doi:10.18653/v1/2025.findings-acl.1141 , pages =
-
[21]
2025 , eprint=
Peacemaker or Troublemaker: How Sycophancy Shapes Multi-Agent Debate , author=. 2025 , eprint=
2025
-
[22]
Findings of the Association for Computational Linguistics: EACL 2026 , month = mar, year =
Stay Focused: Problem Drift in Multi-Agent Debate , author =. Findings of the Association for Computational Linguistics: EACL 2026 , month = mar, year =. doi:10.18653/v1/2026.findings-eacl.268 , pages =
-
[23]
2026 , url =
Laban, Philippe and Hayashi, Hiroaki and Zhou, Yingbo and Neville, Jennifer , booktitle =. 2026 , url =
2026
-
[24]
arXiv preprint arXiv:2312.17543 , year=
Building Efficient Universal Classifiers with Natural Language Inference , author =. arXiv preprint arXiv:2312.17543 , year =
-
[25]
Marelli, Marco and Bentivogli, Luisa and Baroni, Marco and Bernardi, Raffaella and Menini, Stefano and Zamparelli, Roberto , booktitle =. 2014 , address =. doi:10.3115/v1/S14-2001 , pages =
-
[26]
2025 , eprint=
Jasper and Stella: distillation of SOTA embedding models , author=. 2025 , eprint=
2025
-
[27]
Young-Min Cho, Sharath Chandra Guntuku, and Lyle Ungar
Chen, Justin and Saha, Swarnadeep and Bansal, Mohit , editor =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = aug, year =. doi:10.18653/v1/2024.acl-long.381 , pages =
-
[28]
What Disease Does This Patient Have?
Jin, Di and Pan, Eileen and Oufattole, Nassim and Weng, Wei-Hung and Fang, Hanyi and Szolovits, Peter , journal =. What Disease Does This Patient Have?. 2021 , doi =
2021
-
[29]
npj Digital Medicine , year=
Automating expert-level medical reasoning evaluation of large language models , author=. npj Digital Medicine , year=
-
[30]
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
and Zhang, Hao and Stoica, Ion , booktitle =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , booktitle =. Efficient Memory Management for Large Language Model Serving with. 2023 , doi =
2023
-
[32]
Aaron Grattafiori and Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al-Dahle and Aiesha Letman and Akhil Mathur and Alan Schelten and Alex Vaughan and Amy Yang and Angela Fan and Anirudh Goyal and Anthony Hartshorn and Aobo Yang and Archi Mitra and Archie Sravankumar and Artem Korenev and Arthur Hinsvark and Arun Rao ...
2024
-
[33]
2024 , url =
OpenAI , journal =. 2024 , url =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.