LUNA-AD: Lightweight Uncertainty-Aware Language Model with Lifelong Learning for Autonomous Driving
Pith reviewed 2026-06-27 18:38 UTC · model grok-4.3
The pith
LUNA-AD distills multi-agent reasoning into a lightweight dual-head model that learns continuously for better autonomous driving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
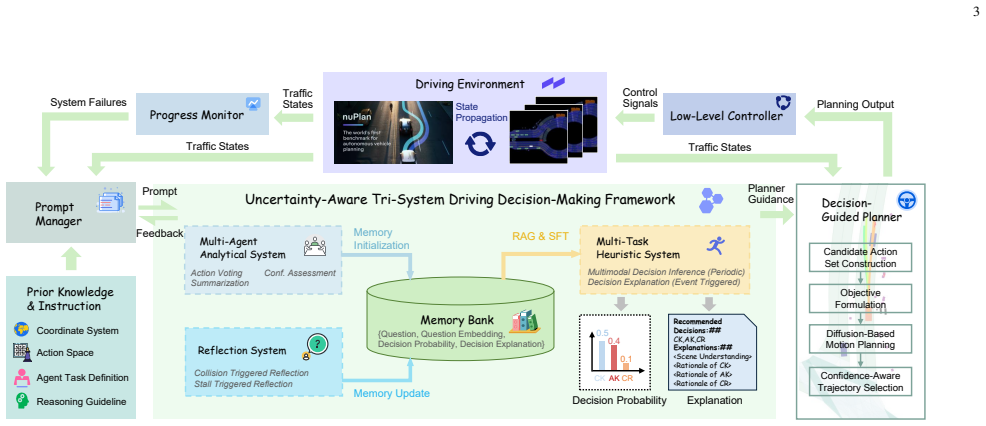
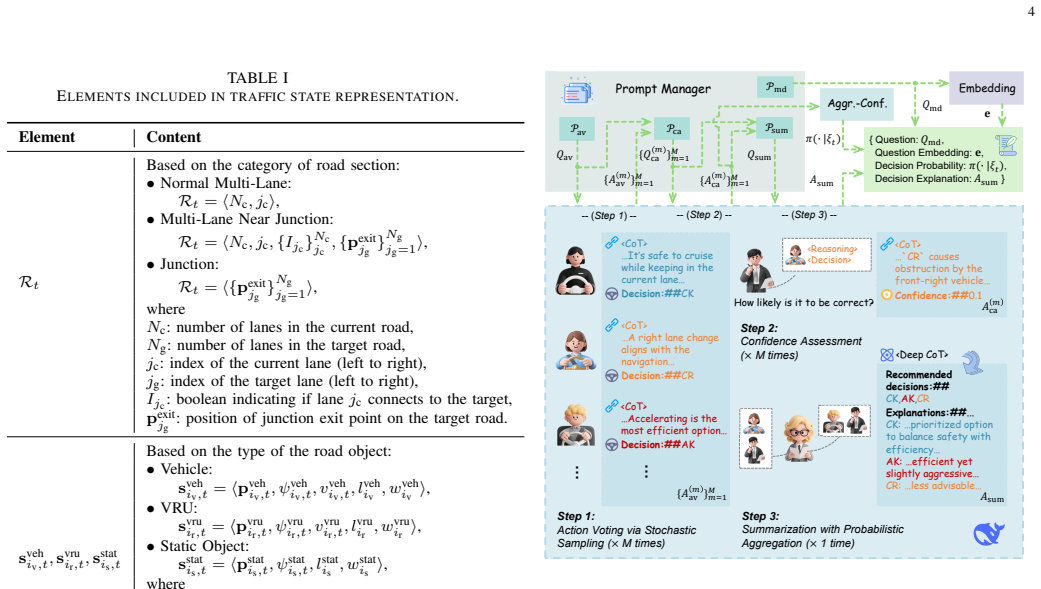
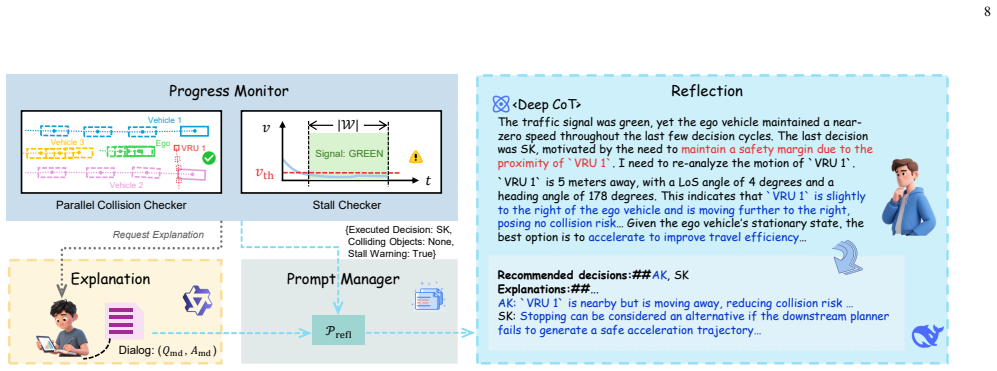
LUNA-AD features a tri-system architecture that reconciles complex multimodal behavioral reasoning, efficient deployment, and continual refinement: a multi-agent analytical system generates uncertainty-aware decision-making demonstrations through diverse hypothesis exploration, a dual-head lightweight heuristic model is distilled to unify the inference of decision distributions and textual explanations, and a reflection-driven lifelong learning mechanism operates on multimodal decision outputs to preserve strategic diversity and refine candidate decisions and rationales via closed-loop feedback.
What carries the argument
The tri-system architecture of multi-agent demonstration generation, dual-head model distillation, and reflection-driven lifelong learning.
If this is right
- LUNA-AD delivers state-of-the-art success rates on nuPlan in both non-reactive and reactive modes.
- Inference latency drops substantially compared to other knowledge-driven autonomous driving frameworks.
- The lifelong learning component supports ongoing refinement of decisions and rationales without static limitations.
- Uncertainty awareness in the distilled model helps maintain strategic diversity in driving choices.
Where Pith is reading between the lines
- The distillation step could extend the same lightweight reasoning pattern to other real-time control tasks that need both speed and explanatory output.
- Closed-loop reflection might allow faster adaptation to novel environments than retraining on fixed datasets alone.
- If the uncertainty modeling transfers well, similar pipelines could address overconfidence problems in other deployed decision systems.
Load-bearing premise
The multi-agent analytical system generates high-quality uncertainty-aware decision-making demonstrations that can be distilled into a lightweight dual-head model while preserving performance and enabling effective lifelong refinement via closed-loop feedback.
What would settle it
Running the model on nuPlan benchmarks and measuring success rates below those of existing knowledge-driven frameworks or finding inference latency not drastically reduced would show the architecture does not deliver the claimed benefits.
Figures



read the original abstract
While large language models (LLMs) offer promising reasoning capabilities, their integration into safety-critical driving systems is hindered by limited reasoning diversity, high computational overhead, and static learning paradigms. To address these challenges, we propose LUNA-AD, a lightweight uncertainty-aware language model with lifelong learning for autonomous driving (AD). LUNA-AD features a tri-system architecture that reconciles complex multimodal behavioral reasoning, efficient deployment, and continual refinement. We design a multi-agent analytical system to generate uncertainty-aware decision-making demonstrations through diverse hypothesis exploration. A dual-head lightweight heuristic model is distilled to unify the inference of decision distributions and textual explanations while enabling efficient deployment. Furthermore, a reflection-driven lifelong learning mechanism operates on multimodal decision outputs and preserves strategic diversity, allowing for the refinement of candidate decisions and rationales via closed-loop feedback to enhance driving robustness. Extensive experiments on nuPlan benchmarks demonstrate that LUNA-AD achieves state-of-the-art success rates under both non-reactive and reactive modes, with drastically reduced inference latency compared to existing knowledge-driven AD frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LUNA-AD, a lightweight uncertainty-aware language model with lifelong learning for autonomous driving. It features a tri-system architecture: a multi-agent analytical system to generate uncertainty-aware decision-making demonstrations through diverse hypothesis exploration, a dual-head lightweight heuristic model distilled from it to unify inference of decision distributions and textual explanations, and a reflection-driven lifelong learning mechanism that refines decisions and rationales via closed-loop feedback on multimodal outputs. The paper claims that extensive experiments on nuPlan benchmarks demonstrate state-of-the-art success rates under both non-reactive and reactive modes, along with drastically reduced inference latency compared to existing knowledge-driven AD frameworks.
Significance. If the performance claims hold with proper substantiation, the work could meaningfully advance LLM integration into safety-critical autonomous driving by addressing computational overhead, limited reasoning diversity, and static learning through efficient distillation and continual refinement. The tri-system design offers a practical path toward deployable, uncertainty-aware systems that maintain strategic diversity.
major comments (2)
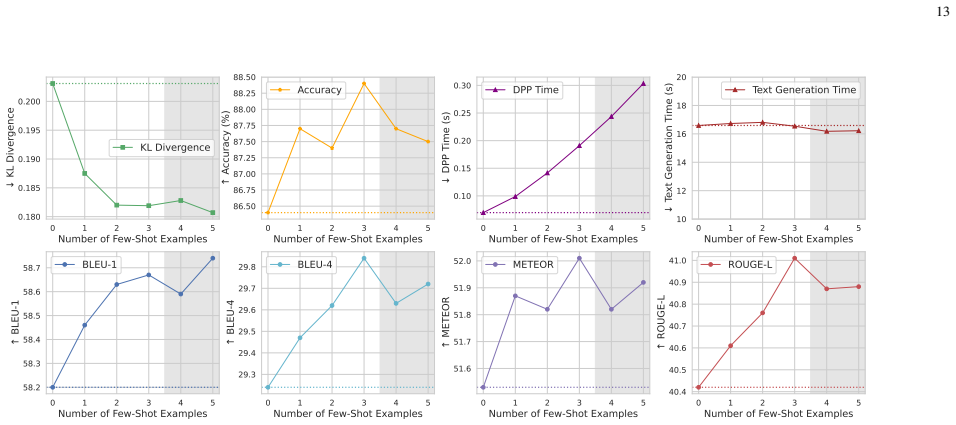
- [Abstract] Abstract: The central claim of state-of-the-art success rates on nuPlan (non-reactive and reactive modes) with reduced latency is presented without any quantitative metrics, baseline comparisons, error bars, dataset details, or ablation studies, preventing verification of the performance improvements against the paper's own evidence.
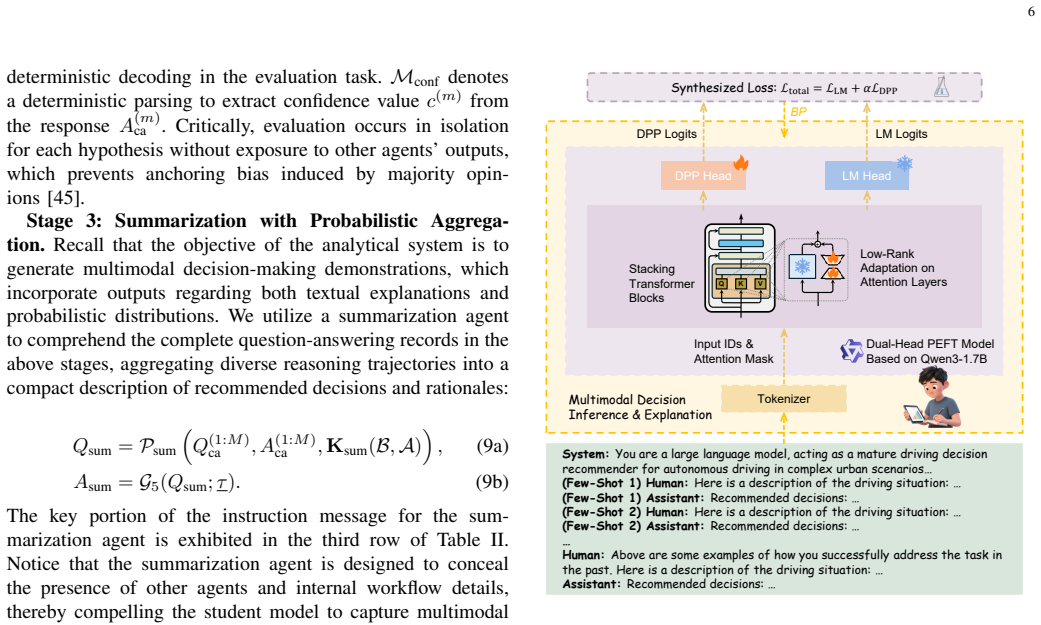
- [Distillation process (dual-head heuristic model)] Distillation process (dual-head heuristic model): The load-bearing assumption that high-quality uncertainty-aware demonstrations from the multi-agent analytical system survive distillation into the lightweight dual-head model (preserving both performance and uncertainty awareness) lacks any quantitative verification, such as success-rate deltas, calibration error, or explanation fidelity comparisons between teacher outputs and student model on identical scenarios.
minor comments (1)
- [Abstract] Abstract: The phrase 'extensive experiments' is used without any numerical results or key statistics, which would allow immediate assessment of the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the distillation process. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of state-of-the-art success rates on nuPlan (non-reactive and reactive modes) with reduced latency is presented without any quantitative metrics, baseline comparisons, error bars, dataset details, or ablation studies, preventing verification of the performance improvements against the paper's own evidence.
Authors: We agree that the abstract would benefit from including key quantitative results to make the performance claims more immediately verifiable. The experimental section of the manuscript reports the specific success rates, baseline comparisons, and latency figures on nuPlan under both modes. We will revise the abstract to incorporate representative metrics (e.g., success-rate improvements and latency reductions) along with a brief reference to the evaluation protocol. revision: yes
-
Referee: [Distillation process (dual-head heuristic model)] Distillation process (dual-head heuristic model): The load-bearing assumption that high-quality uncertainty-aware demonstrations from the multi-agent analytical system survive distillation into the lightweight dual-head model (preserving both performance and uncertainty awareness) lacks any quantitative verification, such as success-rate deltas, calibration error, or explanation fidelity comparisons between teacher outputs and student model on identical scenarios.
Authors: This observation is correct. The manuscript describes the distillation procedure and its design goals but does not provide direct quantitative comparisons (such as success-rate deltas, calibration metrics, or explanation fidelity) between the teacher multi-agent outputs and the distilled dual-head student model on matched scenarios. We will add an ablation study with these comparisons in the revised manuscript to substantiate the preservation of performance and uncertainty awareness. revision: yes
Circularity Check
No circularity: claims rest on external benchmark experiments
full rationale
The paper presents an architecture (multi-agent demonstration generator, distilled dual-head model, reflection-driven lifelong learning) whose performance is asserted via nuPlan success-rate and latency measurements. No equations, fitted parameters, or self-citations are shown to reduce any claimed result to its own inputs by construction; the distillation step is described as a design choice whose fidelity is left to empirical verification rather than enforced by definition. The derivation chain therefore remains self-contained against the stated external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Planning and decision- making for autonomous vehicles,
W. Schwarting, J. Alonso-Mora, and D. Rus, “Planning and decision- making for autonomous vehicles,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 1, no. 1, pp. 187–210, 2018
2018
-
[2]
An integrated framework of decision making and motion planning for autonomous vehicles considering social behaviors,
P. Hang, C. Lv, C. Huang, J. Cai, Z. Hu, and Y . Xing, “An integrated framework of decision making and motion planning for autonomous vehicles considering social behaviors,”IEEE Transactions on Vehicular Technology, vol. 69, no. 12, pp. 14458–14469, 2020
2020
-
[3]
Senna: Bridging large vision-language models and end-to-end autonomous driving,
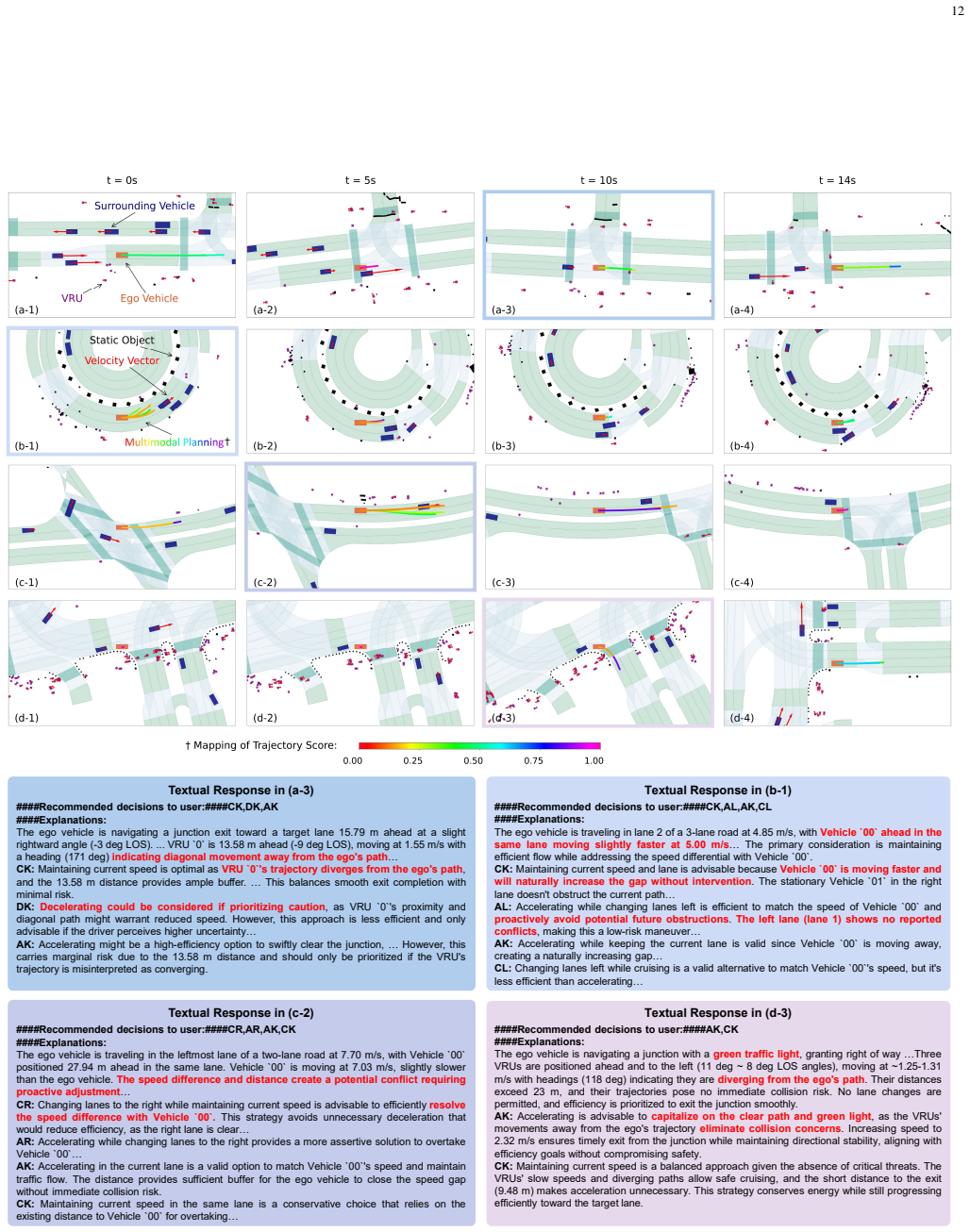
B. Jiang, S. Chen, B. Liao, X. Zhang, W. Yin, Q. Zhang, C. Huang, W. Liu, and X. Wang, “Senna: Bridging large vision-language models and end-to-end autonomous driving,”arXiv preprint arXiv:2410.22313, 2024. 15 t = t0 − 2.0s t = t0 − 1.5s t = t0 − 1.0s t = t0 − 0.5s t = t0 (present) ####Recommended decisions to user:####DK,DR ####Explanations: The ego vehi...
Pith/arXiv arXiv 2024
-
[4]
Bilevel multi-armed bandit- based hierarchical reinforcement learning for interaction-aware self- driving at unsignalized intersections,
Z. Peng, Y . Wang, L. Zheng, and J. Ma, “Bilevel multi-armed bandit- based hierarchical reinforcement learning for interaction-aware self- driving at unsignalized intersections,”IEEE Transactions on Vehicular Technology, vol. 74, no. 6, pp. 8824–8838, 2025
2025
-
[5]
End-to-end autonomous driving: Challenges and frontiers,
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li, “End-to-end autonomous driving: Challenges and frontiers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 10164– 10183, 2024
2024
-
[6]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell,et al., “Language models are few-shot learners,” inthe Proceedings of Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901, 2020
1901
-
[7]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv,et al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[8]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou,et al., “Chain-of-thought prompting elicits reasoning in large language models,”the Proceedings of Advances in Neural Information Processing Systems, vol. 35, pp. 24824–24837, 2022
2022
-
[9]
GPT-Driver: Learning to drive with GPT,
J. Mao, Y . Qian, J. Ye, H. Zhao, and Y . Wang, “GPT-Driver: Learning to drive with GPT,”arXiv preprint arXiv:2310.01415, 2023
Pith/arXiv arXiv 2023
-
[10]
LMDrive: Closed-loop end-to-end driving with large language models,
H. Shao, Y . Hu, L. Wang, G. Song, S. L. Waslander, Y . Liu, and H. Li, “LMDrive: Closed-loop end-to-end driving with large language models,” inthe Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15120–15130, 2024
2024
-
[11]
DrivegGPT4: Interpretable end-to-end autonomous driving via large language model,
Z. Xu, Y . Zhang, E. Xie, Z. Zhao, Y . Guo, K.-Y . K. Wong, Z. Li, and H. Zhao, “DrivegGPT4: Interpretable end-to-end autonomous driving via large language model,”IEEE Robotics and Automation Letters, vol. 9, no. 10, pp. 8186 – 8193, 2024
2024
-
[12]
DriveLM: Driving with graph visual question answering,
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, J. Beißwenger, P. Luo, A. Geiger, and H. Li, “DriveLM: Driving with graph visual question answering,” inthe Proceedings of European Conference on Computer Vision, pp. 256–274, 2024
2024
-
[13]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. V . Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” inthe Proceedings of Inter- national Conference on Learning Representations, 2023
2023
-
[14]
Tree of thoughts: Deliberate problem solving with large language models,
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,” inthe Proceedings of Advances in Neural Information 16 Processing Systems, vol. 36, pp. 11809–11822, 2023
2023
-
[15]
Forking paths in neural text generation,
E. J. Bigelow, A. Holtzman, H. Tanaka, and T. Ullman, “Forking paths in neural text generation,” inthe Proceedings of International Conference on Learning Representations, 2025
2025
-
[16]
A unified framework integrating decision making and trajectory planning based on spatio-temporal voxels for highway autonomous driving,
T. Zhang, W. Song, M. Fu, Y . Yang, X. Tian, and M. Wang, “A unified framework integrating decision making and trajectory planning based on spatio-temporal voxels for highway autonomous driving,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 8, pp. 10365–10379, 2021
2021
-
[17]
CALMM-Drive: Confidence-aware autonomous driving with large mul- timodal model,
R. Yao, Y . Wang, H. Liu, R. Yang, Z. Peng, L. Zhu, and J. Ma, “CALMM-Drive: Confidence-aware autonomous driving with large mul- timodal model,”arXiv preprint arXiv:2412.04209, 2024
arXiv 2024
-
[18]
GameFormer: Game-theoretic modeling and learning of transformer-based interactive prediction and planning for autonomous driving,
Z. Huang, H. Liu, and C. Lv, “GameFormer: Game-theoretic modeling and learning of transformer-based interactive prediction and planning for autonomous driving,” inthe Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3903–3913, 2023
2023
-
[19]
PLUTO: Pushing the limit of imi- tation learning-based planning for autonomous driving,
J. Cheng, Y . Chen, and Q. Chen, “PLUTO: Pushing the limit of imi- tation learning-based planning for autonomous driving,”arXiv preprint arXiv:2404.14327, 2024
arXiv 2024
-
[20]
Hierarchical prediction uncertainty-aware motion planning for autonomous driving in lane-changing scenarios,
R. Yao and X. Sun, “Hierarchical prediction uncertainty-aware motion planning for autonomous driving in lane-changing scenarios,”Trans- portation Research Part C: Emerging Technologies, vol. 171, p. 104962, 2025
2025
-
[21]
GenAD: Gener- ative end-to-end autonomous driving,
W. Zheng, R. Song, X. Guo, C. Zhang, and L. Chen, “GenAD: Gener- ative end-to-end autonomous driving,” inthe Proceedings of European Conference on Computer Vision, pp. 87–104, 2024
2024
-
[22]
Diffusion-based planning for autonomous driving with flexible guidance,
Y . Zheng, R. Liang, K. Zheng, J. Zheng, L. Mao, J. Li, W. Gu, R. Ai, S. E. Li, X. Zhan,et al., “Diffusion-based planning for autonomous driving with flexible guidance,” inthe Proceedings of International Conference on Learning Representations, 2025
2025
-
[23]
HE-Drive: Human-like end-to-end driving with vision language models,
J. Wang, X. Zhang, Z. Xing, S. Gu, X. Guo, Y . Hu, Z. Song, Q. Zhang, X. Long, and W. Yin, “HE-Drive: Human-like end-to-end driving with vision language models,”arXiv preprint arXiv:2410.05051, 2024
arXiv 2024
-
[24]
H. Fu, D. Zhang, Z. Zhao, J. Cui, D. Liang, C. Zhang, D. Zhang, H. Xie, B. Wang, and X. Bai, “Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation,” arXiv preprint arXiv:2503.19755, 2025
Pith/arXiv arXiv 2025
-
[25]
Recogdrive: A reinforced cognitive framework for end- to-end autonomous driving,
Y . Li, K. Xiong, X. Guo, F. Li, S. Yan, G. Xu, L. Zhou, L. Chen, H. Sun, B. Wang,et al., “Recogdrive: A reinforced cognitive framework for end- to-end autonomous driving,”arXiv preprint arXiv:2506.08052, 2025
Pith/arXiv arXiv 2025
-
[26]
DriveVLA-W0: World models amplify data scaling law in autonomous driving,
Y . Li, S. Shang, W. Liu, B. Zhan, H. Wang, Y . Wang, Y . Chen, X. Wang, Y . An, C. Tang,et al., “DriveVLA-W0: World models amplify data scaling law in autonomous driving,”arXiv preprint arXiv:2510.12796, 2025
Pith/arXiv arXiv 2025
-
[27]
Scaling laws for neural language models,
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,”arXiv preprint arXiv:2001.08361, 2020
Pith/arXiv arXiv 2001
-
[28]
Distilling the knowledge in a neural network,
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[29]
A survey on knowledge distillation of large language models,
X. Xu, M. Li, C. Tao, T. Shen, R. Cheng, J. Li, C. Xu, D. Tao, and T. Zhou, “A survey on knowledge distillation of large language models,” arXiv preprint arXiv:2402.13116, 2024
Pith/arXiv arXiv 2024
-
[30]
Hydra-MDP: End-to-end multimodal planning with multi-target hydra-distillation,
Z. Li, K. Li, S. Wang, S. Lan, Z. Yu, Y . Ji, Z. Li, Z. Zhu, J. Kautz, Z. Wu, et al., “Hydra-MDP: End-to-end multimodal planning with multi-target hydra-distillation,”arXiv preprint arXiv:2406.06978, 2024
Pith/arXiv arXiv 2024
-
[31]
DistillDrive: End-to-end multi-mode autonomous driving distillation by isomorphic hetero-source planning model,
R. Yu, X. Zhang, R. Zhao, H. Yan, and M. Wang, “DistillDrive: End-to-end multi-mode autonomous driving distillation by isomorphic hetero-source planning model,” inthe Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 26188–26197, 2025
2025
-
[32]
Continuously learning, adapting, and improving: A dual-process approach to autonomous driving,
J. Mei, Y . Ma, X. Yang, L. Wen, X. Cai, X. Li, D. Fu, B. Zhang, P. Cai, M. Dou,et al., “Continuously learning, adapting, and improving: A dual-process approach to autonomous driving,”Advances in Neural Information Processing Systems, vol. 37, pp. 123261–123290, 2024
2024
-
[33]
W. Liu, P. Liu, and J. Ma, “DSDrive: Distilling large language model for lightweight end-to-end autonomous driving with unified reasoning and planning,”arXiv preprint arXiv:2505.05360, 2025
arXiv 2025
-
[34]
DiLu: A knowledge-driven approach to autonomous driving with large language models,
L. Wen, D. Fu, X. Li, X. Cai, M. Tao, P. Cai, M. Dou, B. Shi, L. He, and Y . Qiao, “DiLu: A knowledge-driven approach to autonomous driving with large language models,” inthe Proceedings of International Conference on Learning Representations, 2024
2024
-
[35]
LeapV AD: A leap in autonomous driving via cognitive perception and dual-process thinking,
Y . Ma, T. Wei, N. Zhong, J. Mei, T. Hu, L. Wen, X. Yang, B. Shi, and Y . Liu, “LeapV AD: A leap in autonomous driving via cognitive perception and dual-process thinking,”arXiv preprint arXiv:2501.08168, 2025
arXiv 2025
-
[36]
Decision- making with lightweight confidence-aware language model for au- tonomous driving,
R. Yao, R. Zhong, P. Liu, M. Peng, R. Yang, and J. Ma, “Decision- making with lightweight confidence-aware language model for au- tonomous driving,”arXiv preprint arXiv:2605.25393, 2026
Pith/arXiv arXiv 2026
-
[37]
nuPlan: A closed-loop ML- based planning benchmark for autonomous vehicles,
H. Caesar, J. Kabzan, K. S. Tan, W. K. Fong, E. Wolff, A. Lang, L. Fletcher, O. Beijbom, and S. Omari, “nuPlan: A closed-loop ML- based planning benchmark for autonomous vehicles,”arXiv preprint arXiv:2106.11810, 2021
Pith/arXiv arXiv 2021
-
[38]
A behavioral planning framework for autonomous driving,
J. Wei, J. M. Snider, T. Gu, J. M. Dolan, and B. Litkouhi, “A behavioral planning framework for autonomous driving,” inthe Proceedings of IEEE Intelligent Vehicles Symposium, pp. 458–464, 2014
2014
-
[39]
A universal cooperative decision- making framework for connected autonomous vehicles with generic road topologies,
Z. Huang, W. Liu, S. Shen, and J. Ma, “A universal cooperative decision- making framework for connected autonomous vehicles with generic road topologies,”IEEE Transactions on Vehicular Technology, vol. 74, no. 4, pp. 5414–5429, 2024
2024
-
[40]
A safe hierarchical planning framework for complex driving scenarios based on reinforce- ment learning,
J. Li, L. Sun, J. Chen, M. Tomizuka, and W. Zhan, “A safe hierarchical planning framework for complex driving scenarios based on reinforce- ment learning,” inthe Proceedings of IEEE International Conference on Robotics and Automation, pp. 2660–2666, 2021
2021
-
[41]
Conditional predictive behavior planning with inverse reinforcement learning for human-like autonomous driving,
Z. Huang, H. Liu, J. Wu, and C. Lv, “Conditional predictive behavior planning with inverse reinforcement learning for human-like autonomous driving,”IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 7, pp. 7244–7258, 2023
2023
-
[42]
Is ego status all you need for open-loop end-to-end autonomous driving?,
Z. Li, Z. Yu, S. Lan, J. Li, J. Kautz, T. Lu, and J. M. Alvarez, “Is ego status all you need for open-loop end-to-end autonomous driving?,” in the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14864–14873, 2024
2024
-
[43]
Open- DriveVLA: Towards end-to-end autonomous driving with large vision language action model,
X. Zhou, X. Han, F. Yang, Y . Ma, V . Tresp, and A. Knoll, “Open- DriveVLA: Towards end-to-end autonomous driving with large vision language action model,”arXiv preprint arXiv:2503.23463, 2025
arXiv 2025
-
[44]
Can LLMs express their uncertainty? An empirical evaluation of confidence elicitation in LLMs,
M. Xiong, Z. Hu, X. Lu, Y . LI, J. Fu, J. He, and B. Hooi, “Can LLMs express their uncertainty? An empirical evaluation of confidence elicitation in LLMs,” inthe Proceedings of International Conference on Learning Representations, 2024
2024
-
[45]
Conformity in large language models,
X. Zhu, C. Zhang, T. Stafford, N. Collier, and A. Vlachos, “Conformity in large language models,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3854–3872, 2025
2025
-
[46]
What language model architecture and pretraining objective works best for zero-shot generalization?,
T. Wang, A. Roberts, D. Hesslow, T. Le Scao, H. W. Chung, I. Belt- agy, J. Launay, and C. Raffel, “What language model architecture and pretraining objective works best for zero-shot generalization?,” in the Proceedings of International Conference on Machine Learning, pp. 22964–22984, 2022
2022
-
[47]
Parting with misconceptions about learning-based vehicle motion planning,
D. Dauner, M. Hallgarten, A. Geiger, and K. Chitta, “Parting with misconceptions about learning-based vehicle motion planning,” inthe Proceedings of Conference on Robot Learning, pp. 1268–1281, 2023
2023
-
[48]
Diffusion-ES: Gradient-free planning with diffusion for autonomous and instruction-guided driving,
B. Yang, H. Su, N. Gkanatsios, T.-W. Ke, A. Jain, J. Schneider, and K. Fragkiadaki, “Diffusion-ES: Gradient-free planning with diffusion for autonomous and instruction-guided driving,” inthe Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15342–15353, 2024
2024
-
[49]
Rethinking imitation-based planners for autonomous driving,
J. Cheng, Y . Chen, X. Mei, B. Yang, B. Li, and M. Liu, “Rethinking imitation-based planners for autonomous driving,” inthe Proceedings of IEEE International Conference on Robotics and Automation, pp. 14123– 14130, 2024
2024
-
[50]
Generalized force model of traffic dynamics,
D. Helbing and B. Tilch, “Generalized force model of traffic dynamics,” Physical review E, vol. 58, no. 1, p. 133, 1998
1998
-
[51]
Are vlms ready for autonomous driving? an empirical study from the reliability, data and metric perspectives,
S. Xie, L. Kong, Y . Dong, C. Sima, W. Zhang, Q. A. Chen, Z. Liu, and L. Pan, “Are vlms ready for autonomous driving? an empirical study from the reliability, data and metric perspectives,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 6585– 6597, 2025
2025
-
[52]
From prediction to planning with goal conditioned lane graph traversals,
M. Hallgarten, M. Stoll, and A. Zell, “From prediction to planning with goal conditioned lane graph traversals,” inthe Proceedings of Interna- tional Conference on Intelligent Transportation Systems, pp. 951–958, 2023
2023
-
[53]
Urban Driver: Learning to drive from real-world demonstrations using policy gradients,
O. Scheel, L. Bergamini, M. Wolczyk, B. Osi ´nski, and P. Ondruska, “Urban Driver: Learning to drive from real-world demonstrations using policy gradients,” inthe Proceedings of Conference on Robot Learning, pp. 718–728, 2022
2022
-
[54]
PlanAgent: A multi-modal large language agent for closed-loop vehicle motion planning,
Y . Zheng, Z. Xing, Q. Zhang, B. Jin, P. Li, Y . Zheng, Z. Xia, K. Zhan, X. Lang, Y . Chen,et al., “PlanAgent: A multi-modal large language agent for closed-loop vehicle motion planning,”arXiv preprint arXiv:2406.01587, 2024
arXiv 2024
-
[55]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan,et al., “DeepSeek-V3 technical report,”arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[56]
DeepSeek-R1: Incentivizing reasoning capability in llms via reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi,et al., “DeepSeek-R1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.