What Makes a Desired Graph for Relational Deep Learning?
Pith reviewed 2026-06-27 18:36 UTC · model grok-4.3
The pith
Schema-derived graphs for relational deep learning suffer from information overload and semantic fragmentation, but controlled filtering and injection produce graphs that raise accuracy and often lower inference cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
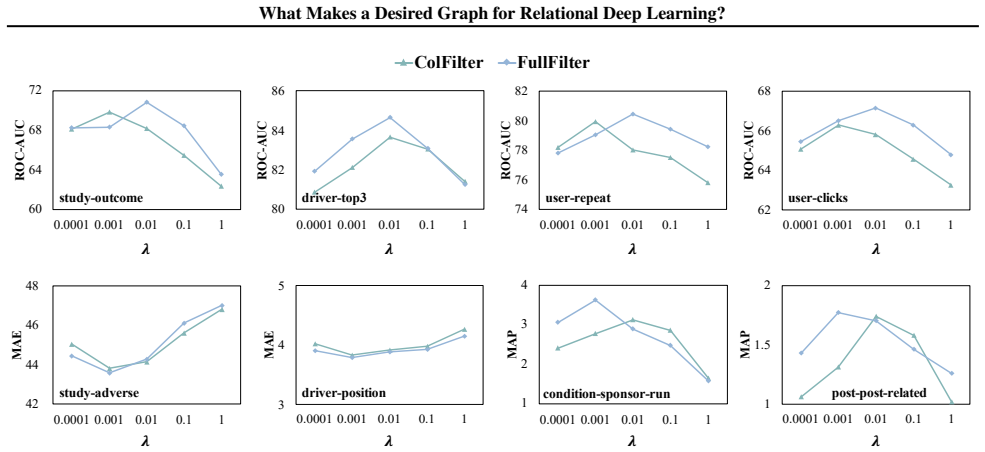
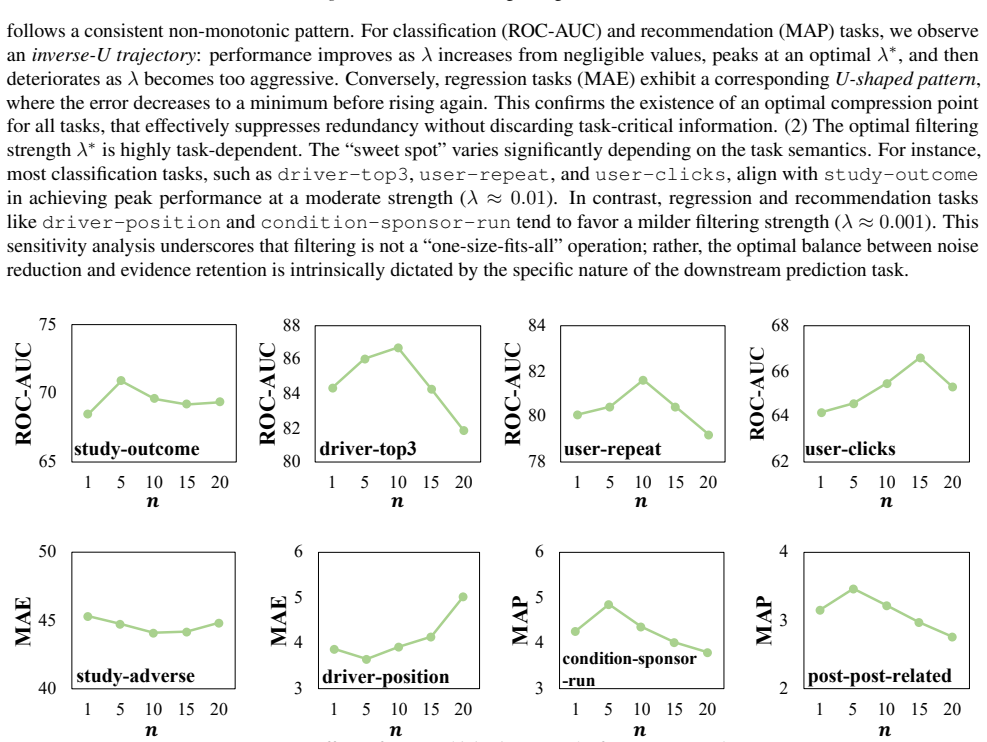
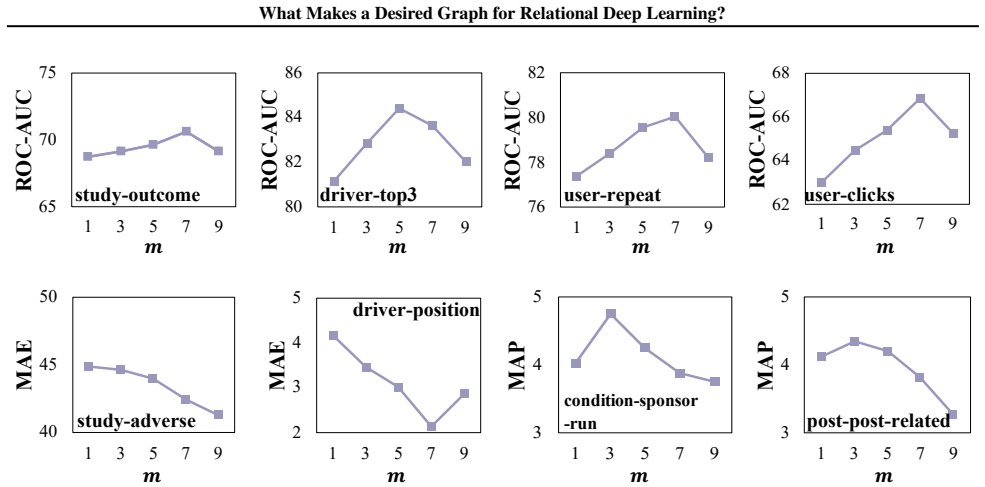
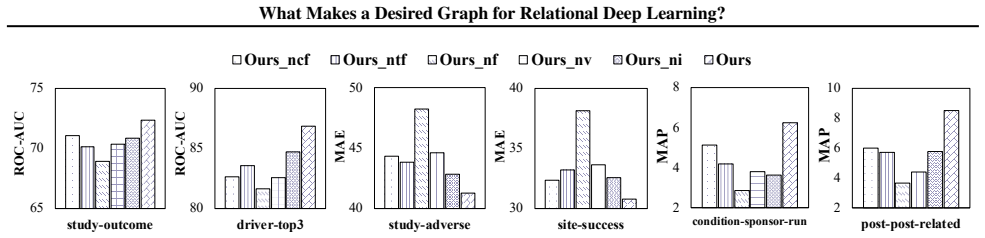
Schema-derived graphs are not the desired input for relational deep learning; the suitable graph arises from controlled structural adaptation that balances mitigation of information overload through filtering with repair of semantic fragmentation through injection, where filtering functions as a non-monotonic bias-variance control and injection succeeds only when it restores explicit relational dependencies absent from the original schema.
What carries the argument
An end-to-end structural optimizer that automatically applies filtering to reduce overload and injection to restore missing relations.
If this is right
- Optimized graphs raise accuracy on classification, regression, and recommendation tasks drawn from relational databases.
- The same optimized graphs frequently reduce inference cost compared with raw schema graphs.
- Filtering acts as a bias-variance knob whose performance effect is non-monotonic.
- Injection improves results only when it explicitly restores relational dependencies missing from the schema.
- An automatic optimizer that combines both operations can replace manual graph design for relational deep learning.
Where Pith is reading between the lines
- Similar overload and fragmentation issues may appear in other graph-construction pipelines that start from structured data sources.
- The non-monotonic effect of filtering suggests that future work could search for optimal filter thresholds rather than fixed rules.
- If injection only helps when it restores explicit dependencies, then automatic dependency detection could become a separate sub-problem.
- The cost-accuracy trade-off observed here could be tested on larger-scale relational databases where inference time matters more.
Load-bearing premise
That information overload and semantic fragmentation are the primary problems with schema-derived graphs and that filtering and injection can be balanced without creating new unmeasured distortions.
What would settle it
Running the structural optimizer on a fresh collection of relational tasks and finding no consistent accuracy gain or a consistent rise in inference cost would falsify the claim that the adapted graphs are reliably better.
Figures

read the original abstract
Relational deep learning (RDL) converts relational databases (RDBs) into heterogeneous graphs, but graphs derived directly from database schemas are often not well suited for how graph neural networks (GNNs) perform relational reasoning. We study what makes a relational graph suitable for deep learning and show that schema-derived graphs suffer from two systematic failures: information overload and semantic fragmentation. Our empirical analysis reveals that the desired graph is not the raw schema, but a result of controlled structural adaptation. Performance depends on balancing two operations: mitigating information overload via filtering, and repairing semantic fragmentation via injection. Specifically, filtering serves as a bias-variance knob with non-monotonic effects, while injection improves performance only when it explicitly restores the relational dependencies missing from the original schema. Based on these findings, we develop an end-to-end structural optimizer that applies both operations to adapt relational graphs automatically. Across 26 tasks spanning classification, regression, and recommendation, the optimized graphs consistently improve accuracy while often reducing inference cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that schema-derived heterogeneous graphs for relational deep learning suffer from two systematic failures—information overload and semantic fragmentation—and that these can be addressed by balancing filtering (to control bias-variance) and injection (to restore missing relational dependencies). An end-to-end structural optimizer is developed to apply these operations automatically, yielding consistent accuracy gains and frequent inference-cost reductions across 26 tasks in classification, regression, and recommendation.
Significance. If the empirical results hold under proper controls, the work would be moderately significant: it supplies a concrete, reproducible procedure for adapting relational graphs rather than treating schema-derived graphs as fixed inputs, and it isolates two failure modes with testable operational remedies. The absence of free parameters or axiomatic derivations is consistent with the empirical framing.
major comments (2)
- [Abstract] Abstract: the central claim of consistent accuracy improvements (and cost reductions) on 26 tasks is presented without any enumeration of the datasets, choice of baselines, statistical significance tests, or selection procedure for filtering/injection hyperparameters; this information is load-bearing for evaluating whether the reported gains are robust or artifactual.
- The manuscript does not report whether the optimizer was compared against strong, task-specific graph-construction heuristics or against end-to-end differentiable graph-learning methods; without such controls the claim that the proposed balancing of filtering and injection is the operative mechanism remains under-supported.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of consistent accuracy improvements (and cost reductions) on 26 tasks is presented without any enumeration of the datasets, choice of baselines, statistical significance tests, or selection procedure for filtering/injection hyperparameters; this information is load-bearing for evaluating whether the reported gains are robust or artifactual.
Authors: We agree that the abstract would benefit from additional context to help readers assess robustness. In the revision we will expand the abstract to note that the 26 tasks come from 8 standard relational benchmarks spanning the three domains, that baselines include schema-derived graphs paired with common GNN architectures, and that reported gains are accompanied by statistical significance testing. The hyperparameter selection procedure (validation-based grid search) is already detailed in the experimental protocol section; we will add a one-sentence pointer in the abstract. Full enumeration remains in the main text due to length limits. revision: partial
-
Referee: [—] The manuscript does not report whether the optimizer was compared against strong, task-specific graph-construction heuristics or against end-to-end differentiable graph-learning methods; without such controls the claim that the proposed balancing of filtering and injection is the operative mechanism remains under-supported.
Authors: The manuscript's central empirical contribution is the controlled analysis showing that filtering acts as a bias-variance knob with non-monotonic effects and that injection improves performance only when it restores schema-missing dependencies. These findings are supported by targeted ablations that isolate each operation. Our evaluation therefore centers on the improvement obtained by applying the optimizer to schema-derived graphs rather than on replacing schema graphs with graphs learned entirely from scratch. We maintain that the existing controls are sufficient to substantiate the stated mechanism; adding external baselines would constitute a different experimental framing outside the paper's scope. revision: no
Circularity Check
No significant circularity
full rationale
The paper's central claims rest on an empirical analysis of schema-derived graphs across 26 tasks, identifying two failure modes and demonstrating performance gains from a structural optimizer that applies filtering and injection. No equations, derivations, or first-principles predictions are described that reduce to fitted quantities or self-citations by construction. The results are presented as experimental outcomes rather than self-referential definitions, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Relgnn: Com- posite message passing for relational deep learning.arXiv preprint arXiv:2502.06784,
Chen, T., Kanatsoulis, C., and Leskovec, J. Relgnn: Com- posite message passing for relational deep learning.arXiv preprint arXiv:2502.06784,
-
[3]
arXiv preprint arXiv:2002.02046 (2020)
Cvitkovic, M. Supervised learning on relational databases with graph neural networks.arXiv preprint arXiv:2002.02046,
-
[4]
P., Jaladi, S., Shen, Y ., L´opez, F., Kanatsoulis, C
Dwivedi, V . P., Jaladi, S., Shen, Y ., L´opez, F., Kanatsoulis, C. I., Puri, R., Fey, M., and Leskovec, J. Relational graph transformer.arXiv preprint arXiv:2505.10960,
-
[5]
Normal forms and relational database operators
Fagin, R. Normal forms and relational database operators. InProceedings of the 1979 ACM SIGMOD international conference on Management of data, pp. 153–160,
1979
-
[6]
Pytorch frame: A modular framework for multi-modal tabular learning
Hu, W., Yuan, Y ., Zhang, Z., Nitta, A., Cao, K., Kocijan, V ., Sunil, J., Leskovec, J., and Fey, M. Pytorch frame: A modular framework for multi-modal tabular learning. arXiv preprint arXiv:2404.00776,
-
[7]
I., Choi, E., Jegelka, S., Leskovec, J., and Ribeiro, A
Kanatsoulis, C. I., Choi, E., Jegelka, S., Leskovec, J., and Ribeiro, A. Learning efficient positional encodings with graph neural networks.arXiv preprint arXiv:2502.01122,
-
[8]
Kingma, D. P. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Learning Sparse Neural Networks through $L_0$ Regularization
Liu, C., Sun, H., Zehmakan, A. N., and Zhang, Z. Efficient edge rewiring strategies for enhancing pagerank fairness. Theoretical Computer Science, 1067:115765, 2026a. Liu, C., Xie, Z., Zehmakan, A. N., and Zhang, Z. Efficient algorithms for computing random walk centrality.IEEE Transactions on Knowledge and Data Engineering, 38 (1):235–247, 2026b. Liu, C....
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Wang, X., Ji, H., Shi, C., Wang, B., Ye, Y ., Cui, P., and Yu, P. S. Heterogeneous graph attention network. InThe world wide web conference, pp. 2022–2032,
2022
-
[11]
A deep learning blueprint for relational databases
Zahradn´ık, L., Neumann, J., and ˇS´ır, G. A deep learning blueprint for relational databases. InNeurIPS 2023 Sec- ond Table Representation Learning Workshop,
2023
-
[12]
11 What Makes a Desired Graph for Relational Deep Learning? Table 7.Datasets statistics. Dataset Task Abbr Task type #Rows of training table Train Validation Test rel-amazon item-churn i-ch classification 2,559,264 177,689 166,842 item-ltv i-ltv regression 2,707,679 166,978 178,334 user-item-review u-i-v recommendation 2,324,177 116,970 127,021 rel-avito ...
2024
-
[13]
model used in Section 3.3, trained on the original heteroge- neous graph obtained from the RDB schema without filtering or structural injection. (2) Traditional non-graph methods.To measure the benefit of explicit relational modeling, we include a strong tabular baseline: • LightGBM (Ke et al., 2017).A gradient boosting decision tree model trained on flat...
2017
-
[14]
We evaluate whether our structural optimizer provides orthogonal gains when applied to ID-GNN
incorporates learnable node identity embeddings, particularly effective for recommendation tasks. We evaluate whether our structural optimizer provides orthogonal gains when applied to ID-GNN. (4) Relational deep learning (RDL) methods.These models are specifically designed for relational databases but do not explicitly optimize the graph structure: • REL...
2025
-
[15]
All GNN-based methods, including our optimizer and RDL baselines, are trained with the Adam optimizer (Kingma, 2014)
and conducted experiments on RELBench tasks using a single NVIDIA A30 GPU. All GNN-based methods, including our optimizer and RDL baselines, are trained with the Adam optimizer (Kingma, 2014). To ensure fair comparison, every baseline is trained under the same temporal train/validation/test split and uses the same heterogeneous encoder described in Section
2014
-
[16]
For methods requiring schema-derived structures (e.g., HAN), we generate meta-paths directly from the RDB schema without task-specific tuning. For the LLM-Struct baseline, we conduct experiments with GPT-4 (Achiam et al., 2023), and the LLM is queried once per task to produce a filtered and augmented graph, which is then used to train the same Base backbo...
-
[17]
First, the full model consistently achieves the best performance across all six tasks, indicating that filtering, VIB, and structural injection are all useful and complementary. Removing all filtering (Ours nf) leads to the largest degradation, especially on the regression-style tasks, showing that column/type sparsification is crucial for preventing nois...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.