Multilingual Fact-Checking at Scale: Fine-Tuned Compact Models vs LLMs
Pith reviewed 2026-06-27 18:57 UTC · model grok-4.3
The pith
Fine-tuned compact models deliver stable multilingual fact-checking across 114 languages while matching LLM accuracy with far lower latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Experiments on production data spanning 114 languages for claim detection and 28 languages for veracity prediction show that task-specific fine-tuning provides strong and stable multilingual performance, while the fine-tuned retrieval model remains competitive with modern proprietary embeddings. Same-hardware latency measurements further show large efficiency gains for encoder-based components, supporting their use in production deployments with tight cost and privacy constraints.
What carries the argument
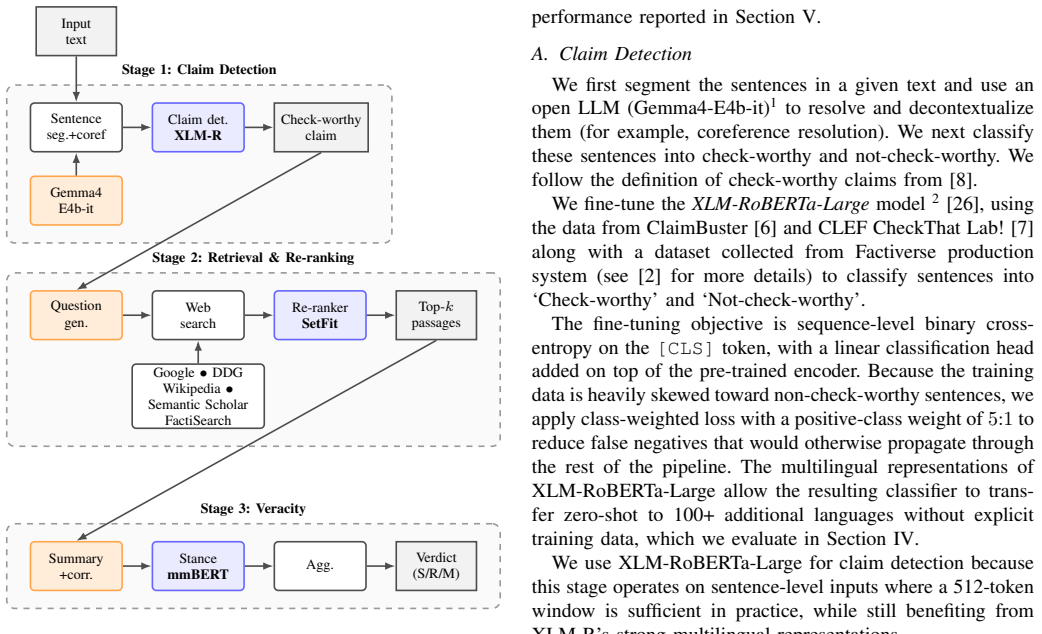
The modular three-stage pipeline of claim detection, evidence retrieval and re-ranking, and veracity prediction, implemented with task-specific fine-tuned encoder models.
If this is right
- Task-specific fine-tuning yields more stable results than general-purpose LLMs when languages vary widely.
- Encoder models can handle high-throughput claim detection without the cost of calling large generative models.
- Self-hosted fine-tuned components preserve data privacy while remaining competitive on retrieval quality.
- The same modular design can support ongoing updates to individual stages without retraining the entire system.
Where Pith is reading between the lines
- Similar fine-tuning patterns may transfer to other high-volume multilingual text classification problems such as sentiment or topic detection.
- The efficiency advantage could allow fact-checking services to operate in regions with limited compute resources.
- If the production data distribution shifts over time, periodic re-tuning of the compact models would be needed to maintain the reported stability.
Load-bearing premise
The production data used for evaluation is representative of real-world multilingual fact-checking challenges.
What would settle it
A new test set of claims or languages outside the current production data where the fine-tuned models fall below the LLM baselines in either accuracy or measured latency.
Figures




read the original abstract
We present a multilingual fact-checking system deployed at Factiverse, designed for high-throughput and low-latency operation across diverse languages. The system follows a modular pipeline with three stages: claim detection, evidence retrieval and re-ranking, and veracity prediction. We fine-tune XLM-RoBERTa-Large for claim detection, mmBERT-base for three-label stance classification (Supports/Refutes/Mixed), and a SetFit-based multilingual re-ranker for claim--evidence matching. We compare these components against strong LLM baselines, including GPT-5.2, Claude Opus~4.6, and Qwen3-8b. Experiments on production data spanning 114 languages for claim detection and 28 languages for veracity prediction show that task-specific fine-tuning provides strong and stable multilingual performance, while the fine-tuned retrieval model remains competitive with modern proprietary embeddings. Same-hardware latency measurements further show large efficiency gains for encoder-based components, supporting their use in production deployments with tight cost and privacy constraints. Overall, compact fine-tuned, self-hosted models remain a practical and effective foundation for multilingual fact-checking at scale. Code and data used for this study are available at https://github.com/factiverse/factcheck-editor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a modular multilingual fact-checking pipeline deployed at Factiverse, with three stages: claim detection via fine-tuned XLM-RoBERTa-Large, evidence retrieval and re-ranking via a SetFit-based model, and veracity prediction via mmBERT-base for three-label stance classification. It evaluates these compact models against LLM baselines (GPT-5.2, Claude Opus 4.6, Qwen3-8b) on Factiverse production data spanning 114 languages for claim detection and 28 languages for veracity prediction, claiming that task-specific fine-tuning yields strong and stable multilingual performance while remaining competitive with proprietary embeddings and delivering large same-hardware latency gains for encoder components. Code and data are released on GitHub.
Significance. If the results hold, the work provides concrete evidence that fine-tuned compact encoder models can serve as a practical, efficient, and privacy-preserving foundation for high-throughput multilingual fact-checking at production scale, outperforming or matching larger LLMs in targeted tasks while reducing latency and cost. The emphasis on real-world deployment metrics and open release of resources strengthens its relevance for applied NLP systems.
major comments (3)
- [Abstract] Abstract: The central claim that 'task-specific fine-tuning provides strong and stable multilingual performance' across 114 languages rests exclusively on internal production data; no per-language performance breakdowns, language-balance statistics, or head-to-head results on public benchmarks (e.g., X-Fact, Multi-FEVER) are referenced, leaving the stability and generalizability assertions without an external anchor.
- [Abstract] Abstract (and experiments section): Production data are described only at aggregate level (114/28 languages); without details on data collection filters, labeling quality controls, or potential over-representation of high-resource languages or easily detectable claims, it is impossible to assess whether the data distribution matches real-world multilingual fact-checking challenges.
- [Abstract] Abstract: The efficiency claim of 'large efficiency gains for encoder-based components' is stated without quantitative latency numbers, hardware specifications, or direct comparison tables against the LLM baselines under identical conditions, weakening the support for the production-deployment recommendation.
minor comments (2)
- The abstract references 'Code and data used for this study are available at https://github.com/factiverse/factcheck-editor' but does not specify whether the repository includes exact data splits, evaluation scripts, and model checkpoints needed for full reproducibility.
- [Abstract] Model names (XLM-RoBERTa-Large, mmBERT-base, SetFit) and LLM versions (GPT-5.2, Claude Opus 4.6) are given without citation to their original papers or release notes.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'task-specific fine-tuning provides strong and stable multilingual performance' across 114 languages rests exclusively on internal production data; no per-language performance breakdowns, language-balance statistics, or head-to-head results on public benchmarks (e.g., X-Fact, Multi-FEVER) are referenced, leaving the stability and generalizability assertions without an external anchor.
Authors: We agree that external validation would strengthen generalizability claims. While the core contribution centers on production-scale deployment, we will add a subsection with results on public benchmarks (X-Fact, Multi-FEVER) and include language-balance statistics plus per-language breakdowns for high-resource languages in the production data. These will be referenced in the abstract. revision: yes
-
Referee: [Abstract] Abstract (and experiments section): Production data are described only at aggregate level (114/28 languages); without details on data collection filters, labeling quality controls, or potential over-representation of high-resource languages or easily detectable claims, it is impossible to assess whether the data distribution matches real-world multilingual fact-checking challenges.
Authors: We will expand the data section with details on labeling quality controls (including agreement metrics) and language distribution analysis to address potential over-representation. Some collection filters are proprietary and cannot be disclosed in full, but we will provide maximum feasible transparency and discuss limitations. revision: partial
-
Referee: [Abstract] Abstract: The efficiency claim of 'large efficiency gains for encoder-based components' is stated without quantitative latency numbers, hardware specifications, or direct comparison tables against the LLM baselines under identical conditions, weakening the support for the production-deployment recommendation.
Authors: The experiments section already contains the quantitative latency results, hardware details (e.g., A100 GPUs), and comparison tables. We will revise the abstract to incorporate key numbers (e.g., specific ms-per-example figures) and explicitly reference the tables. revision: yes
Circularity Check
No circularity; empirical evaluation on external production data and LLM baselines
full rationale
The paper describes an empirical pipeline for multilingual fact-checking using fine-tuned encoder models (XLM-RoBERTa, mmBERT, SetFit) evaluated on Factiverse production data across 114/28 languages, with direct comparisons to external LLM baselines (GPT-5.2, Claude Opus, Qwen3). No equations, derivations, or 'predictions' appear. No self-citations are invoked to justify uniqueness or load-bearing premises. Results are presented as measured performance and latency on held-out production logs, not as quantities forced by fitting or self-definition. This matches the default expectation of a non-circular experimental report.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brenda: Browser extension for fake news detection,
B. Botnevik, E. Sakariassen, and V . Setty, “Brenda: Browser extension for fake news detection,” inProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, ser. SIGIR ’20, 2020, p. 2117–2120
2020
-
[2]
Surprising efficacy of fine-tuned transformers for fact-checking over larger language models,
V . Setty, “Surprising efficacy of fine-tuned transformers for fact-checking over larger language models,” inProceedings of the 47th international ACM SIGIR conference on research and development in information retrieval, 2024, pp. 2842–2846
2024
-
[3]
Generative Large Language Models in Automated Fact-Checking: A Survey
I. Vykopal, M. Pikuliak, S. Ostermann, and M. ˇSimko, “Generative large language models in automated fact-checking: A survey,”arXiv preprint arXiv:2407.02351, 2024
work page internal anchor Pith review arXiv 2024
-
[4]
Rarr: Researching and revising what language models say, using language models,
L. Gao, Z. Dai, P. Pasupat, A. Chen, A. T. Chaganty, Y . Fan, V . Zhao, N. Lao, H. Lee, D.-C. Juanet al., “Rarr: Researching and revising what language models say, using language models,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 16 477–16 508
2023
-
[5]
A survey on automated fact-checking,
Z. Guo, M. Schlichtkrull, and A. Vlachos, “A survey on automated fact-checking,”Transactions of the Association for Computational Lin- guistics, vol. 10, pp. 178–206, 2022
2022
-
[6]
Claimbuster: the first-ever end-to-end fact-checking system,
N. Hassan, G. Zhang, F. Arslan, J. Caraballo, D. Jimenez, S. Gawsane, S. Hasan, M. Joseph, A. Kulkarni, A. K. Nayak, V . Sable, C. Li, and M. Tremayne, “Claimbuster: the first-ever end-to-end fact-checking system,”Proc. VLDB Endow., vol. 10, no. 12, pp. 1945–1948, 2017
1945
-
[7]
Fighting the COVID-19 infodemic: Modeling the perspective of journalists, fact-checkers, social media platforms, policy makers, and the society,
F. Alam, S. Shaar, F. Dalvi, H. Sajjad, A. Nikolov, H. Mubarak, G. Da San Martino, A. Abdelali, N. Durrani, K. Darwish, A. Al- Homaid, W. Zaghouani, T. Caselli, G. Danoe, F. Stolk, B. Bruntink, and P. Nakov, “Fighting the COVID-19 infodemic: Modeling the perspective of journalists, fact-checkers, social media platforms, policy makers, and the society,” in...
2021
-
[8]
Claim detection for automated fact-checking: A survey on monolingual, multilingual and cross-lingual research,
R. Panchendrarajan and A. Zubiaga, “Claim detection for automated fact-checking: A survey on monolingual, multilingual and cross-lingual research,”Natural Language Processing Journal, vol. 7, p. 100066, 2024
2024
-
[9]
Factir: A real-world zero-shot open-domain retrieval benchmark for fact-checking,
V . V and V . Setty, “Factir: A real-world zero-shot open-domain retrieval benchmark for fact-checking,” inCompanion Proceedings of the ACM on Web Conference 2025, ser. WWW ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 809–812. [Online]. Available: https://doi.org/10.1145/3701716.3715300
-
[10]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, ser. EMNLP ’19’, K. Inui, J. Jiang, V . Ng, and X. Wan, Eds. Association for Computational Linguistics, 2019, pp. 3982–3992
2019
-
[11]
L. Tunstall, N. Reimers, U. E. S. Jo, L. Bates, D. Korat, M. Wasserblat, and O. Pereg, “Efficient few-shot learning without prompts,”arXiv preprint arXiv:2209.11055, 2022. [Online]. Available: https://arxiv.org/abs/2209.11055
-
[12]
Declare: Debunking fake news and false claims using evidence-aware deep learning,
K. Popat, S. Mukherjee, A. Yates, and G. Weikum, “Declare: Debunking fake news and false claims using evidence-aware deep learning,” in Proceedings of the 2018 conference on empirical methods in natural language processing, 2018, pp. 22–32
2018
-
[13]
Averitec: A dataset for real-world claim verification with evidence from the web,
M. Schlichtkrull, Z. Guo, and A. Vlachos, “Averitec: A dataset for real-world claim verification with evidence from the web,”Advances in Neural Information Processing Systems, vol. 36, pp. 65 128–65 167, 2023
2023
-
[14]
Finding streams in knowledge graphs to support fact checking,
P. Shiralkar, A. Flammini, F. Menczer, and G. L. Ciampaglia, “Finding streams in knowledge graphs to support fact checking,” in2017 IEEE International Conference on Data Mining (ICDM), 2017, pp. 859–864
2017
-
[15]
Higil: Hierarchical graph inference learning for fact checking,
Q. Mao, Y . Wang, C. Yang, L. Du, H. Peng, J. Wu, J. Li, and Z. Wang, “Higil: Hierarchical graph inference learning for fact checking,” in2022 IEEE International Conference on Data Mining (ICDM), 2022, pp. 337– 346
2022
-
[16]
Jointly embedding the local and global relations of heterogeneous graph for rumor detection,
C. Yuan, Q. Ma, W. Zhou, J. Han, and S. Hu, “Jointly embedding the local and global relations of heterogeneous graph for rumor detection,” in2019 IEEE International Conference on Data Mining (ICDM), 2019, pp. 796–805
2019
-
[17]
SelfCheckGPT: Zero-resource black-box hallucination detection for generative large language models,
P. Manakul, A. Liusie, and M. Gales, “SelfCheckGPT: Zero-resource black-box hallucination detection for generative large language models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, ser. EMNLP ’23, H. Bouamor, J. Pino, and K. Bali, Eds. Association for Computational Linguistics, 2023, pp. 9004–9017
2023
-
[18]
I.-C. Chern, S. Chern, S. Chen, W. Yuan, K. Feng, C. Zhou, J. He, G. Neubig, and P. Liu, “Factool: Factuality detection in generative ai – a tool augmented framework for multi-task and multi-domain scenarios,” arXiv preprint arXiv:2307.13528, 2023
- [19]
-
[20]
Factcheck-bench: Fine-grained evaluation benchmark for automatic fact-checkers,
Y . Wang, R. G. Reddy, Z. M. Mujahid, A. Arora, A. Rubashevskii, J. Geng, O. M. Afzal, L. Pan, N. Borenstein, A. Pillai, I. Au- genstein, I. Gurevych, and P. Nakov, “Factcheck-bench: Fine-grained evaluation benchmark for automatic fact-checkers,”arXiv preprint arXiv:2311.09000, 2024
-
[21]
A survey on natural language processing for fake news detection,
R. Oshikawa, J. Qian, and W. Y . Wang, “A survey on natural language processing for fake news detection,” inProceedings of the Twelfth Language Resources and Evaluation Conference, 2020, pp. 6086–6093
2020
-
[22]
The perils and promises of fact-checking with large language models,
D. Quelle and A. Bovet, “The perils and promises of fact-checking with large language models,”Frontiers in Artificial Intelligence, vol. 7, p. 1341697, 2024
2024
-
[23]
Livefc: A system for live fact-checking of audio streams,
V . Venktesh and V . Setty, “Livefc: A system for live fact-checking of audio streams,” in18th ACM International Conference on Web Search and Data Mining, WSDM 2025. Association for Computing Machinery (ACM), 2025, pp. 1060–1063
2025
-
[24]
Shortcheck: Checkworthiness detection of mul- tilingual short-form videos,
H. Vatndal and V . Setty, “Shortcheck: Checkworthiness detection of mul- tilingual short-form videos,” inThe 14th International Joint Conference on Natural Language Processing and The 4th Conference of the Asia- Pacific Chapter of the Association for Computational Linguistics: System Demonstrations, 2025, p. 77
2025
-
[25]
Factcheck editor: Multilingual text editor with end-to-end fact-checking,
V . Setty, “Factcheck editor: Multilingual text editor with end-to-end fact-checking,” inProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024, pp. 2744–2748
2024
-
[26]
Unsu- pervised cross-lingual representation learning at scale,
A. Conneau, K. Khandelwal, N. Goyal, V . Chaudhary, G. Wenzek, F. Guzm´an, E. Grave, M. Ott, L. Zettlemoyer, and V . Stoyanov, “Unsu- pervised cross-lingual representation learning at scale,” inProceedings of the 58th Annual Meeting of the Association for Computational Lin- guistics, ser. ACL ’20, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. ...
2020
-
[27]
Where the truth lies: Explaining the credibility of emerging claims on the web and social media,
K. Popat, S. Mukherjee, J. Str ¨otgen, and G. Weikum, “Where the truth lies: Explaining the credibility of emerging claims on the web and social media,” inProceedings of the 26th International Conference on World Wide Web Companion, ser. WWW ’17 Companion, 2017, p. 1003–1012
2017
-
[28]
SADHAN: Hierarchical attention networks to learn latent aspect embeddings for fake news detection,
R. Mishra and V . Setty, “SADHAN: Hierarchical attention networks to learn latent aspect embeddings for fake news detection,” inProceedings of the 2019 ACM SIGIR International Conference on Theory of Informa- tion Retrieval, ser. ICTIR ’19. Association for Computing Machinery, 2019, p. 197–204
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.