BLUE: Toward Better Language Use in Efficient Vision-Language-Action Models for Autonomous Driving
Pith reviewed 2026-06-27 18:28 UTC · model grok-4.3
The pith
A 0.11M-parameter gate on pretrained VLA hidden states decides per frame whether language generation will help autonomous driving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
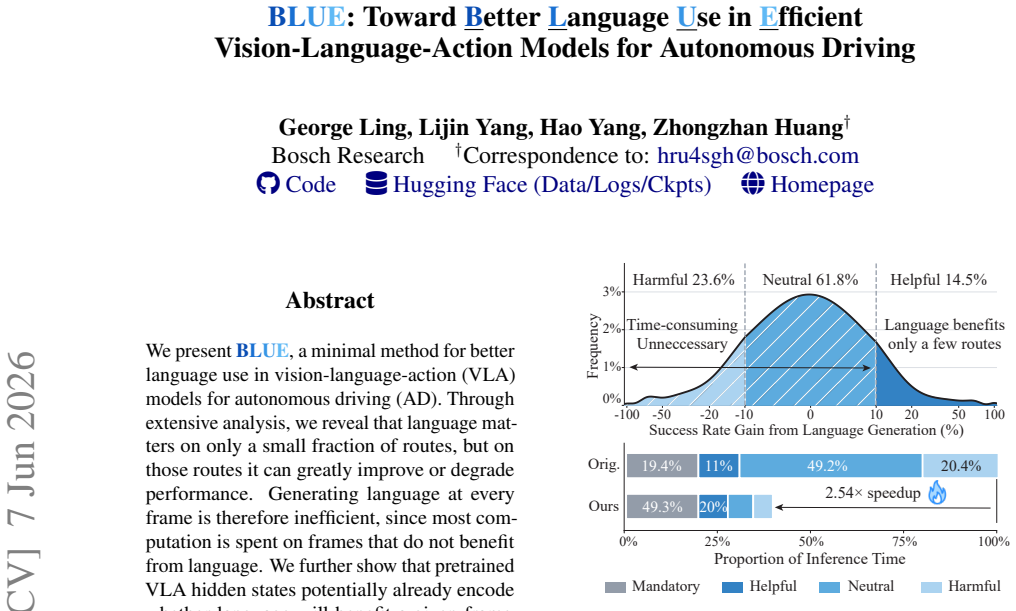
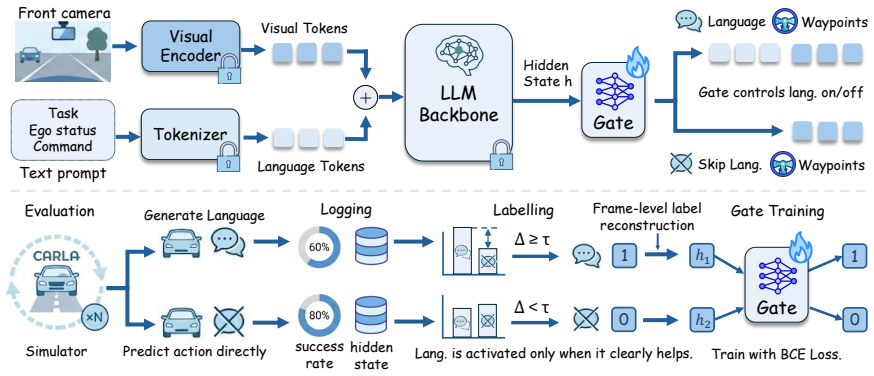
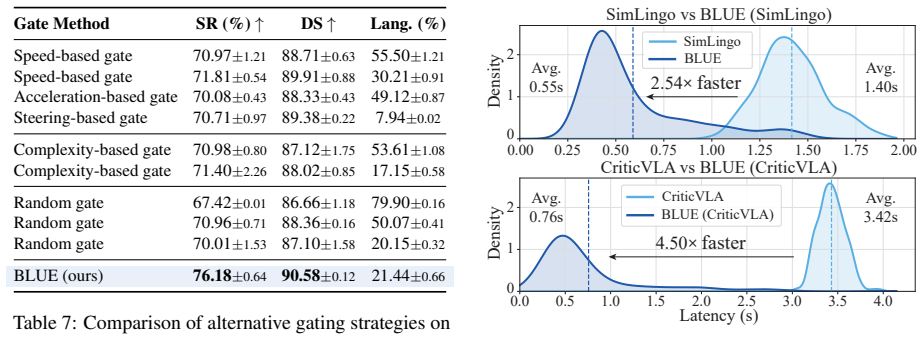
BLUE trains a lightweight gate on frozen VLA hidden states to decide per frame whether to activate language generation or predict actions directly. With just 0.11M parameters, it achieves 76.2% success rate on Bench2Drive and 36 driving score on Longest6 v2, delivering 2.54x inference speedup and 8.9% success rate improvement over the backbone.
What carries the argument
The 0.11M-parameter gate trained on frozen VLA hidden states to predict per-frame language utility.
If this is right
- Language generation can be skipped on most frames without hurting driving performance.
- Pretrained VLA hidden states contain frame-specific information about language utility.
- Selective language activation produces both higher success rates and faster inference.
- No backbone modification or extra human annotation is required to gain these benefits.
- State-of-the-art results appear on Bench2Drive and Longest6 v2 benchmarks.
Where Pith is reading between the lines
- The same hidden-state signal could be used to gate other expensive modules in multimodal driving models.
- Gating during pretraining might reduce overall training cost for future VLA systems.
- The approach may transfer to non-driving VLA tasks where language is useful only sporadically.
- Making the gate output a continuous score instead of a binary decision could allow partial language use.
Load-bearing premise
The hidden states of a pretrained VLA model already encode whether language generation will benefit performance on a given frame.
What would settle it
A gate trained on random noise or only kinematic features achieving similar success-rate gains and speedup on the same benchmarks would show the VLA hidden states are not the key signal.
Figures

read the original abstract
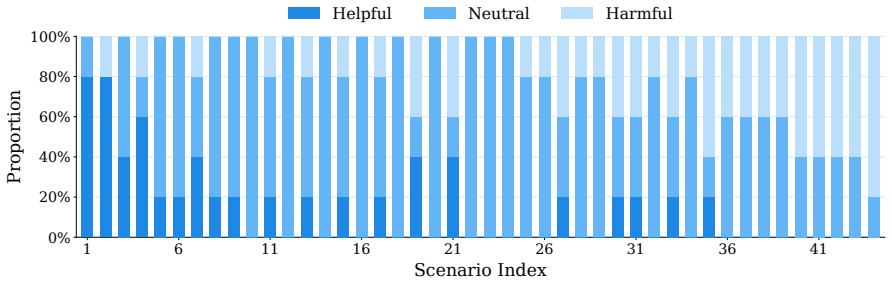
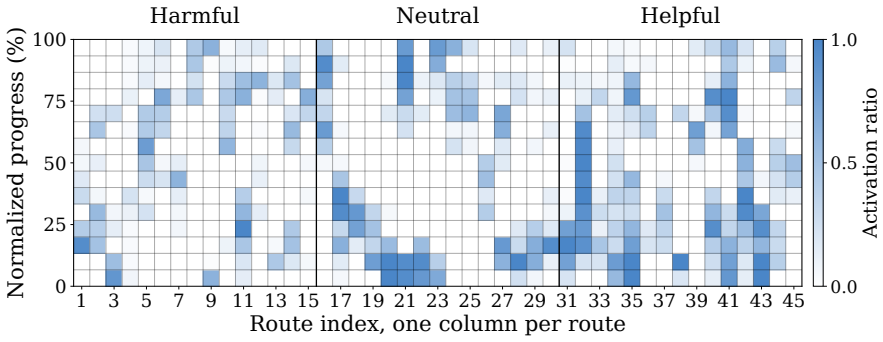
We present BLUE, a minimal method for better language use in vision-language-action (VLA) models for autonomous driving (AD). Through extensive analysis, we reveal that language matters on only a small fraction of routes, but on those routes it can greatly improve or degrade performance. Generating language at every frame is therefore inefficient, since most computation is spent on frames that do not benefit from language. We further show that pretrained VLA hidden states potentially already encode whether language will benefit a given frame, even though scene complexity and kinematic features alone struggle to predict this. Based on this finding, BLUE trains a lightweight gate on frozen VLA hidden states to decide per frame whether to activate language generation or predict actions directly, without modifying the backbone or requiring additional human annotation. With just a 0.11M-parameter gate, BLUE sets a new state of the art on both benchmarks, achieving 76.2% success rate on Bench2Drive and 36 driving score on Longest6 v2, while delivering 2.54x inference speedup and 8.9% success rate improvement over the backbone. BLUE provides a practical path toward efficient language-augmented AD, showing that VLA models can retain the benefits of language at a fraction of the cost. Our code, data, logs and checkpoints are fully available on https://github.com/George-Ling3/BLUE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BLUE, a minimal method for efficient language use in vision-language-action (VLA) models for autonomous driving. Through analysis, the authors find that language benefits performance on only a small fraction of routes but can greatly improve or degrade results there; pretrained VLA hidden states encode whether language will help on a given frame better than scene or kinematic features. BLUE trains a 0.11M-parameter gate on frozen hidden states to decide per-frame whether to invoke language generation or predict actions directly, without backbone changes or extra labels. This yields SOTA results of 76.2% success rate on Bench2Drive and 36 driving score on Longest6 v2, plus 2.54x speedup and 8.9% success improvement over the backbone.
Significance. If the hidden-state analysis and reported gains hold, the work demonstrates a practical, low-overhead way to retain language benefits in VLA models while cutting unnecessary computation, which is relevant for real-time autonomous driving. The explicit release of code, data, logs, and checkpoints supports reproducibility and is a positive aspect of the contribution.
major comments (2)
- [Analysis section (referenced in abstract as 'extensive analysis')] The central claim that hidden states encode language-benefit information better than scene/kinematic features (and therefore justify training the gate on them) is load-bearing; the analysis section must supply concrete quantitative comparisons (e.g., classification accuracy, AUC, or F1 for benefit prediction using each feature type) and statistical tests to establish this superiority.
- [Results / Experiments section] The reported SOTA numbers and 8.9% improvement are load-bearing for the efficiency claim; the results section should include ablations isolating the gate's contribution, full baseline tables with recent VLA methods, and error bars or multiple runs to confirm the gains are not due to training variance.
minor comments (2)
- Provide the exact architecture, input dimension, and training hyperparameters (loss, optimizer, epochs) of the 0.11M gate so that the 'lightweight' claim can be verified.
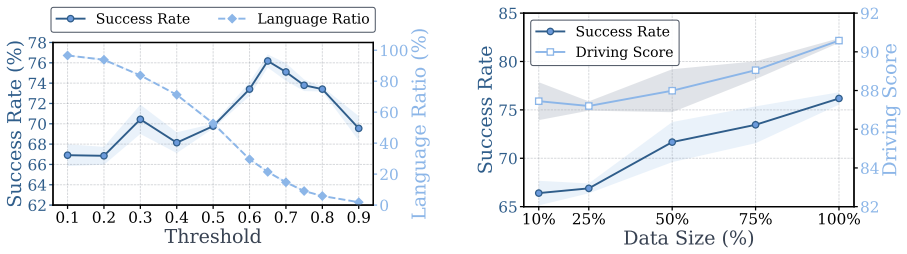
- Clarify the precise definition of 'language matters' used in the route-level analysis (e.g., success-rate delta threshold) and how frames were labeled without additional human annotation.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and the constructive comments on the analysis and results sections. We appreciate the recognition of the work's significance for efficient VLA models in autonomous driving and the value placed on reproducibility. We address each major comment below.
read point-by-point responses
-
Referee: [Analysis section (referenced in abstract as 'extensive analysis')] The central claim that hidden states encode language-benefit information better than scene/kinematic features (and therefore justify training the gate on them) is load-bearing; the analysis section must supply concrete quantitative comparisons (e.g., classification accuracy, AUC, or F1 for benefit prediction using each feature type) and statistical tests to establish this superiority.
Authors: We agree that explicit quantitative metrics and statistical validation would make the superiority claim more rigorous. The current analysis demonstrates the advantage of hidden states over scene and kinematic features through comparative experiments on benefit prediction, but we will revise the analysis section to include the requested classification accuracy, AUC, and F1 scores for each feature type, along with statistical tests such as paired t-tests or Wilcoxon tests to establish significance. revision: yes
-
Referee: [Results / Experiments section] The reported SOTA numbers and 8.9% improvement are load-bearing for the efficiency claim; the results section should include ablations isolating the gate's contribution, full baseline tables with recent VLA methods, and error bars or multiple runs to confirm the gains are not due to training variance.
Authors: We thank the referee for highlighting opportunities to strengthen the empirical validation. The manuscript already reports the 8.9% improvement over the backbone along with some ablations on gate design choices, but we will expand the results section with additional ablations that more precisely isolate the gate's contribution, include a fuller baseline table incorporating recent VLA methods, and report performance across multiple independent runs with error bars and standard deviations to address variance concerns. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core derivation trains a lightweight gate on frozen VLA hidden states to decide language activation per frame, after an analysis showing those states encode benefit information better than scene/kinematic features. This gate is evaluated on separate external benchmarks (Bench2Drive, Longest6 v2) with reported gains in success rate and speedup. No equations or steps reduce the reported outcomes to quantities defined by the gate parameters themselves, no self-citation chains justify the central premise, and no fitted inputs are relabeled as predictions. The method remains self-contained against external benchmarks with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained VLA hidden states encode whether language will benefit a given frame
Reference graph
Works this paper leans on
-
[1]
InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 24823– 24834
Orion: A holistic end-to-end autonomous driv- ing framework by vision-language instructed action generation. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 24823– 24834. Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. 2024. Vista: A generalizable driving world ...
-
[2]
EMMA: End-to-End Multimodal Model for Autonomous Driving
Emma: End-to-end multimodal model for au- tonomous driving.arXiv preprint arXiv:2410.23262. Xiaosong Jia, Yulu Gao, Li Chen, Junchi Yan, Patrick Langechuan Liu, and Hongyang Li. 2023a. Driveadapter: Breaking the coupling barrier of per- ception and planning in end-to-end autonomous driv- ing. InProceedings of the IEEE/CVF International Conference on Compu...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 24312–24320
C3ot: Generating shorter chain-of-thought without compromising effectiveness. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 24312–24320. B Ravi Kiran, Ibrahim Sobh, Victor Talpaert, Patrick Mannion, Ahmad A Al Sallab, Senthil Yogamani, and Patrick Pérez. 2021. Deep reinforcement learn- ing for autonomous driving: A surv...
-
[4]
Neural chain-of-thought search: Searching the optimal reasoning path to enhance large language models.arXiv preprint arXiv:2601.11340. Haochen Liu, Tianyu Li, Haohan Yang, Li Chen, Cao- jun Wang, Ke Guo, Haochen Tian, Hongchen Li, Hongyang Li, and Chen Lv. 2026a. Reinforced re- finement with self-aware expansion for end-to-end autonomous driving.IEEE Tran...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Can language models learn to skip steps?Ad- vances in Neural Information Processing Systems, 37:45359–45385. Haotian Luo, Haiying He, Yibo Wang, Jinluan Yang, Rui Liu, Naiqiang Tan, Xiaochun Cao, Dacheng Tao, and Li Shen. 2026. Ada-r1: Hybrid-cot via bi-level adaptive reasoning optimization.Advances in Neural Information Processing Systems, 38:59353–59377...
-
[6]
Multi-modal fusion transformer for end-to- end autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pat- tern recognition, pages 7077–7087. 11 Kangan Qian, Zhikun Ma, Yangfan He, Ziang Luo, Tianyu Shi, Tianze Zhu, Jiayin Li, Jianhui Wang, Ziyu Chen, Xiao He, and 1 others. 2024. Fasionad: Fast and slow fusion thinking systems...
-
[7]
Yingqi Tang, Zhuoran Xu, Zhaotie Meng, and Erkang Cheng
Hermes: A holistic end-to-end risk-aware mul- timodal embodied system with vision-language mod- els for long-tail autonomous driving.arXiv preprint arXiv:2602.00993. Yingqi Tang, Zhuoran Xu, Zhaotie Meng, and Erkang Cheng. 2025. Hip-ad: Hierarchical and multi- granularity planning with deformable attention for autonomous driving in a single decoder. InPro...
-
[8]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599. Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xian- peng Lang, and Hang Zhao. 2024. Drivevlm: The convergence of autonomous driving and large vision- language models.arXiv preprint arXiv:2402.12289. Sen Wang, Daoyuan Jia, and...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Wenzhao Zheng, Ruiqi Song, Xianda Guo, Chenming Zhang, and Long Chen
Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence, 46(8):5625–5644. Wenzhao Zheng, Ruiqi Song, Xianda Guo, Chenming Zhang, and Long Chen. 2024. Genad: Generative end-to-end autonomous driving. InEuropean Con- ference on Computer Vision, pages 87–104. Springer. Shanshan Zhong, Zhongzhan Huang, ...
-
[10]
We provide a detailed comparison between BLUE and these methods in §B.5.1
applies parallel decoding to structured chain- of-thought templates, and Reasoning-VLA (Zhang et al., 2025a) replaces autoregressive action decod- ing with learnable action queries for parallel trajec- tory generation. We provide a detailed comparison between BLUE and these methods in §B.5.1. B.3 Efficient Reasoning in LLMs BLUE detects when language gene...
2025
-
[11]
CoT-Valve (Ma et al., 2025) progressively mixes parameters of long-reasoning and non-reasoning models to gen- erate variable-length training data
samples multiple reasoning paths and selects the shortest correct one as training data. CoT-Valve (Ma et al., 2025) progressively mixes parameters of long-reasoning and non-reasoning models to gen- erate variable-length training data. Other related works include ReCUT (Jin et al., 2025), ConCISE (Qiao et al., 2025), NCoTS (Ling et al., 2026) and Ada-R1 (L...
2025
-
[12]
We will fully open-source our code, trained gate checkpoints, training data, and evaluation logs to support reproducibility and future research
are publicly available for academic research. We will fully open-source our code, trained gate checkpoints, training data, and evaluation logs to support reproducibility and future research. Users who build upon our released materials should com- ply with the licenses of the underlying components and cite the relevant works accordingly. Potential RisksBLU...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.