Structure-Conditioned Actor-Critic Branches for Quality-Diversity Reinforcement Learning
Pith reviewed 2026-06-27 18:36 UTC · model grok-4.3
The pith
Coupling actor structure with branch-specific value learning generates diverse QD-RL policy repertoires.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that representing candidates as structure-conditioned actor-critic branches, with a structural mask defining the actor subspace and a branch-specific critic shaping the value-learning trajectory, allows a branch-aware QD archive to construct policy repertoires that achieve both high performance and behavioral diversity through the complementary contributions of structural conditioning, critic differentiation, and memory-consistent refinement.
What carries the argument
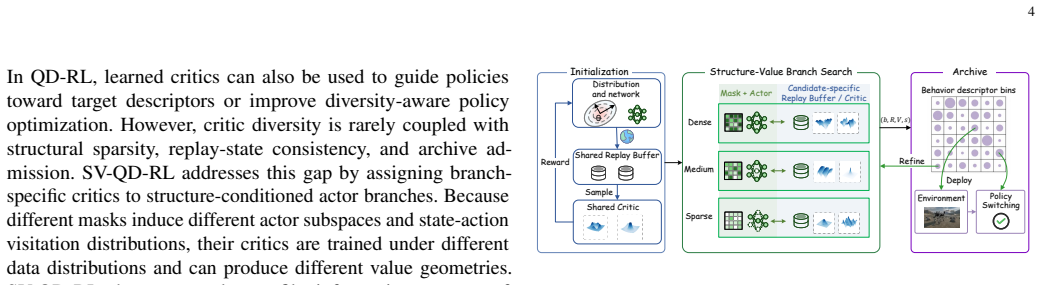
The structure-conditioned actor-critic branch, where a structural mask defines the actor subspace and a branch-specific critic shapes the value-learning trajectory inside a branch-aware QD archive that retains items by behavioral quality, structural footprint, and value-profile information.
Load-bearing premise
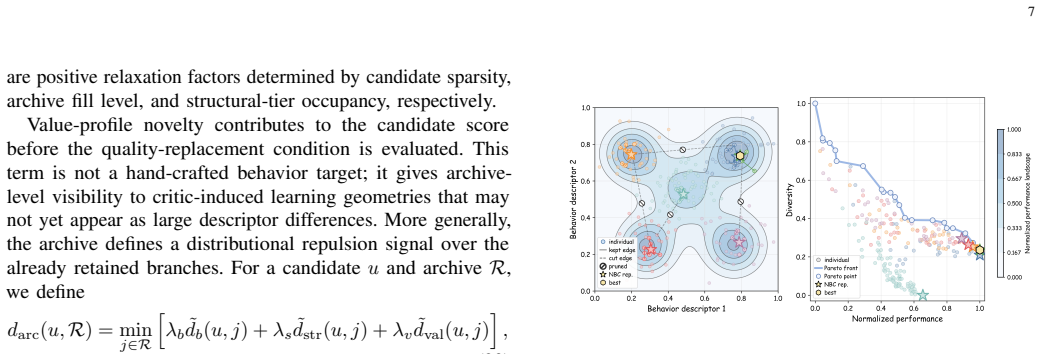
The branch-aware QD archive can effectively evaluate and retain branches according to behavioral quality, structural footprint, and value-profile information.
What would settle it
An ablation on the same MuJoCo tasks in which the structural masks or branch-specific critics are removed and the resulting repertoire diversity and quality are compared against the full method and against prior QD-RL baselines.
Figures
read the original abstract
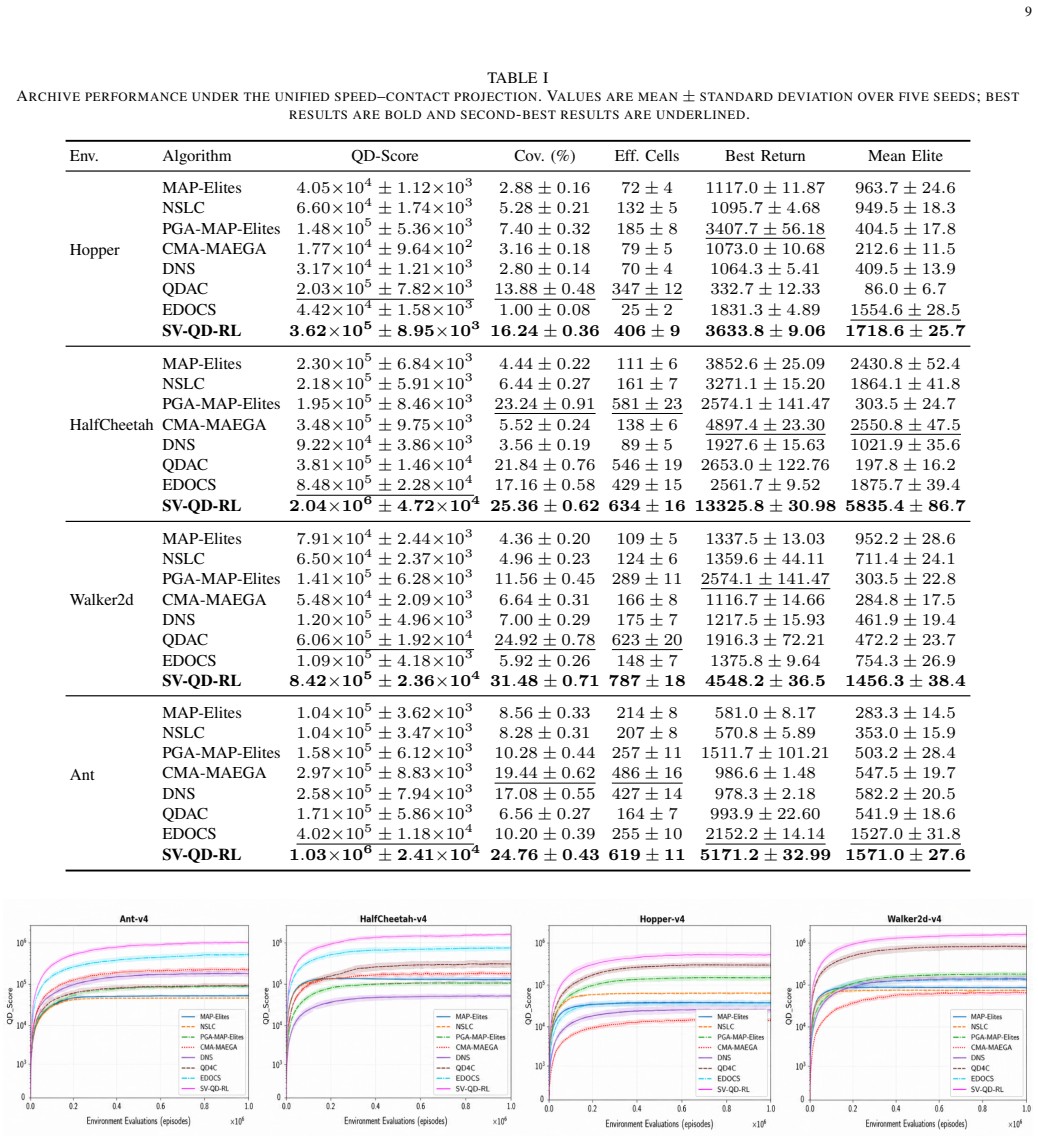
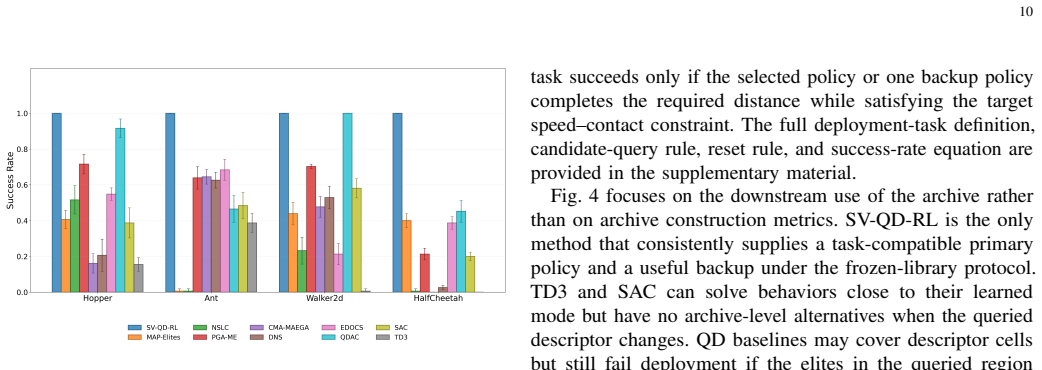
Quality-diversity reinforcement learning (QD-RL) aims to construct policy repertoires that contain both high-performing and behaviorally diverse policies. Existing QD-RL methods mainly diversify policy instances after rollout evaluation or use learned value information to improve policy quality and behavior targeting, while the learning branches that generate candidate policies remain less explored. This paper proposes SV-QD-RL, a structure-value coupled framework that represents each candidate as a structure-conditioned actor-critic branch. Each branch contains an actor, a structural mask, a branch-specific critic, a replay state, and evaluation attributes including behavior, return, sparsity, and value profile. The structural mask defines the actor subspace in which the branch learns, while the branch-specific critic and replay state shape its value-learning trajectory. A branch-aware QD archive then evaluates and retains branches according to behavioral quality, structural footprint, and value-profile information. Experiments on MuJoCo continuous-control tasks show that SV-QD-RL constructs policy repertoires with strong archive quality and behaviorally useful diversity. Ablation and diagnostic analyses further indicate that structural conditioning, critic differentiation, and memory-consistent refinement make complementary contributions to behavioral specialization. Schedule-aware repertoire evaluation shows that the learned archive provides selectable policy alternatives under changing behavior-level requirements. These results suggest that coupling actor structure with branch-specific value learning is an effective mechanism for generating diverse QD-RL policy repertoires.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SV-QD-RL, a structure-value coupled framework for quality-diversity reinforcement learning (QD-RL). It represents each candidate policy as a structure-conditioned actor-critic branch consisting of an actor, structural mask, branch-specific critic, replay state, and evaluation attributes (behavior, return, sparsity, value profile). A branch-aware QD archive evaluates and retains branches based on behavioral quality, structural footprint, and value-profile information. Experiments on MuJoCo continuous-control tasks demonstrate that the method constructs policy repertoires with strong archive quality and behaviorally useful diversity. Ablation studies suggest complementary contributions from structural conditioning, critic differentiation, and memory-consistent refinement, and schedule-aware evaluation indicates the archive provides selectable policies under changing requirements.
Significance. If the empirical results hold, this work could contribute to QD-RL by introducing a mechanism that couples actor structure with branch-specific value learning to generate diverse policy repertoires. The identification of complementary contributions from the three components via ablations is a positive aspect, as is the schedule-aware evaluation for practical utility. The framework appears novel in its branch design.
minor comments (2)
- [Abstract] The abstract claims positive results on MuJoCo tasks but does not provide specific quantitative metrics, error bars, or details on the tasks used, making it difficult to assess the magnitude of improvement over baselines.
- [Abstract] The description of the branch-aware QD archive is high-level; more detail on how branches are evaluated and retained would strengthen the presentation.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of SV-QD-RL, the recognition of its novelty in branch design, and the recommendation for minor revision. No major comments were listed in the report.
Circularity Check
No significant circularity; proposal validated by experiments
full rationale
The paper proposes SV-QD-RL as a novel algorithmic framework coupling structure-conditioned actor-critic branches with a branch-aware QD archive. Claims of complementary contributions from structural conditioning, critic differentiation, and memory-consistent refinement are presented as empirical outcomes from MuJoCo experiments, ablations, and schedule-aware evaluations rather than derived from equations or definitions that reduce to the inputs by construction. No self-definitional steps, fitted parameters renamed as predictions, or load-bearing self-citations appear in the described mechanism; the derivation chain is self-contained as an engineering proposal tested externally.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard reinforcement learning assumptions including Markov decision processes and approximable value functions hold for the MuJoCo tasks.
invented entities (1)
-
structure-conditioned actor-critic branch
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Robots that can adapt like animals,
A. Cully, J. Clune, D. Tarapore, and J.-B. Mouret, “Robots that can adapt like animals,”Nature, vol. 521, no. 7553, pp. 503–507, 2015
2015
-
[2]
Quality and diversity optimization: A unifying modular framework,
A. Cully and Y . Demiris, “Quality and diversity optimization: A unifying modular framework,”IEEE Transactions on Evolutionary Computation, vol. 22, no. 2, pp. 245–259, 2018
2018
-
[3]
Illuminating search spaces by mapping elites
J.-B. Mouret and J. Clune, “Illuminating search spaces by mapping elites,” arXiv preprint arXiv:1504.04909, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[4]
Evolving a diversity of virtual creatures through novelty search and local competition,
J. Lehman and K. O. Stanley, “Evolving a diversity of virtual creatures through novelty search and local competition,” inProceedings of the 13th Annual Conference on Genetic and Evolutionary Computation, 2011, pp. 211–218
2011
-
[5]
Policy gradient assisted MAP-Elites,
O. Nilsson and A. Cully, “Policy gradient assisted MAP-Elites,” in Proceedings of the Genetic and Evolutionary Computation Conference, 2021, pp. 866–875
2021
-
[6]
Understanding the synergies between quality-diversity and deep reinforcement learning,
B. Lim, M. Flageat, and A. Cully, “Understanding the synergies between quality-diversity and deep reinforcement learning,” inProceedings of the Genetic and Evolutionary Computation Conference. ACM, 2023, pp. 1212–1220
2023
-
[7]
Diversity policy gradient for sample efficient quality-diversity optimization,
T. Pierrot, V . Mac´e, F. Chalumeau, A. Flajolet, G. Cideron, K. Beguir, A. Cully, O. Sigaud, and N. Perrin-Gilbert, “Diversity policy gradient for sample efficient quality-diversity optimization,” inProceedings of the Genetic and Evolutionary Computation Conference. ACM, 2022, pp. 1075–1083
2022
-
[8]
Map-elites with descriptor-conditioned gradients and archive distillation into a single policy,
M. Faldor, F. Chalumeau, M. Flageat, and A. Cully, “Map-elites with descriptor-conditioned gradients and archive distillation into a single policy,” inProceedings of the Genetic and Evolutionary Computation Conference, 2023, pp. 138–146
2023
-
[9]
Synergizing quality-diversity with descriptor-conditioned reinforcement learning,
——, “Synergizing quality-diversity with descriptor-conditioned reinforcement learning,”ACM Transactions on Evolutionary Learning and Optimization, vol. 5, no. 1, 2025
2025
-
[10]
Quality-diversity actor-critic: Learning high-performing and diverse behaviors via value and successor features critics,
L. Grillotti, M. Faldor, B. Gonz´alez Le´on, and A. Cully, “Quality-diversity actor-critic: Learning high-performing and diverse behaviors via value and successor features critics,” inProceedings of the 41st International Conference on Machine Learning. PMLR, 2024
2024
-
[11]
Tackling neural architecture search with quality diversity optimization,
L. Schneider, F. Pfisterer, P. Kent, J. Branke, B. Bischl, and J. Thomas, “Tackling neural architecture search with quality diversity optimization,” inProceedings of the First Conference on Automated Machine Learning, 2022
2022
-
[12]
Sample-efficient quality-diversity by cooperative coevolution,
K. Xue, R.-J. Wang, P. Li, D. Li, J. Hao, and C. Qian, “Sample-efficient quality-diversity by cooperative coevolution,” inProceedings of the 12th International Conference on Learning Representations, 2024
2024
-
[13]
The lottery ticket hypothesis: Finding sparse, trainable neural networks,
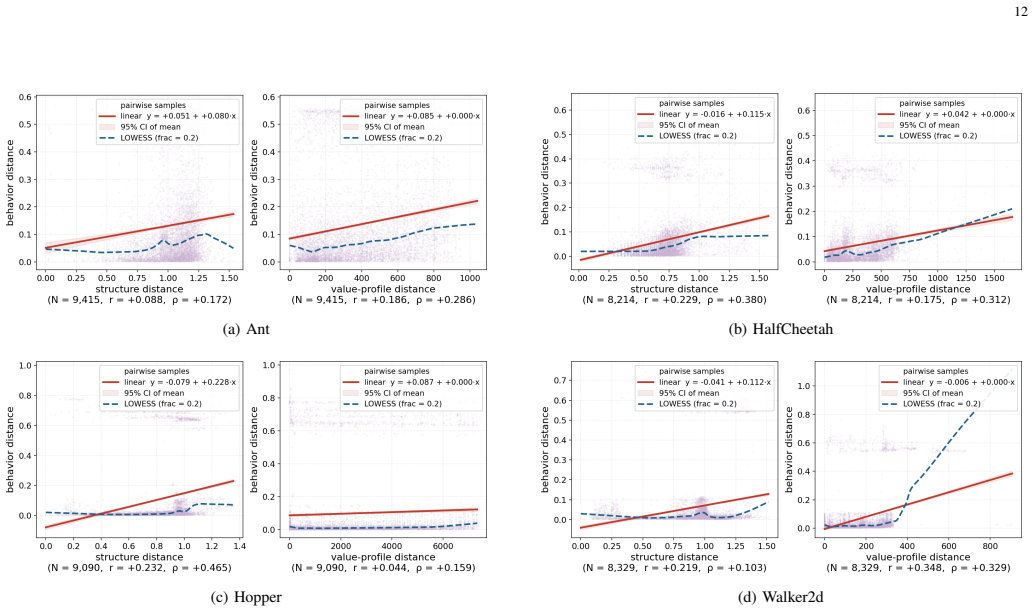
J. Frankle and M. Carbin, “The lottery ticket hypothesis: Finding sparse, trainable neural networks,” inProceedings of the 7th International Conference on Learning Representations (ICLR), 2019. 12 (a) Ant (b) HalfCheetah (c) Hopper (d) Walker2d Fig. 5. Same-sparsity controlled structure–value coupling. Each panel keeps only branch pairs satisfying |si −s ...
2019
-
[14]
The state of sparse training in deep reinforcement learning,
L. Graesser, U. Evci, E. Elsen, and P. S. Castro, “The state of sparse training in deep reinforcement learning,” inProceedings of the 39th International Conference on Machine Learning (ICML), 2022, pp. 7766– 7792
2022
-
[15]
Rlx2: Training a sparse deep reinforcement learning model from scratch,
Y . Tan, P. Hu, L. Pan, J. Huang, and L. Huang, “Rlx2: Training a sparse deep reinforcement learning model from scratch,” inInternational Conference on Learning Representations, 2023
2023
-
[16]
Deterministic policy gradient algorithms,
D. Silver, G. Lever, N. Heess, T. Degris, D. Wierstra, and M. Riedmiller, “Deterministic policy gradient algorithms,” inProceedings of the 31st International Conference on Machine Learning. PMLR, 2014, pp. 387–395
2014
-
[17]
Continuous control with deep reinforcement learning,
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,” inProceedings of the 4th International Conference on Learning Representations (ICLR), 2016
2016
-
[18]
Addressing function approximation error in actor-critic methods,
S. Fujimoto, H. Hoof, and D. Meger, “Addressing function approximation error in actor-critic methods,” inProceedings of the 35th International Conference on Machine Learning (ICML), 2018, pp. 1582–1591
2018
-
[19]
Diversity-driven exploration in reinforcement learning,
R. Zhao and V . Tresp, “Diversity-driven exploration in reinforcement learning,”Journal of Artificial Intelligence Research, vol. 76, pp. 1025– 1068, 2023
2023
-
[20]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silveret al., “Human-level control through deep reinforcement learning,”Nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[21]
Quality diversity: A new frontier for evolutionary computation,
J. K. Pugh, L. B. Soros, and K. O. Stanley, “Quality diversity: A new frontier for evolutionary computation,”Frontiers in Robotics and AI, vol. 3, p. 40, 2016
2016
-
[22]
Illumination algorithms: A survey,
J.-B. Mouret and J. Clune, “Illumination algorithms: A survey,”Artificial Life, vol. 26, no. 1, pp. 1–28, 2020
2020
-
[23]
Abandoning objectives: Evolution through the search for novelty alone,
J. Lehman and K. O. Stanley, “Abandoning objectives: Evolution through the search for novelty alone,”Evolutionary Computation, vol. 19, no. 2, pp. 189–223, 2011
2011
-
[24]
Covariance matrix adaptation for the rapid illumination of behavior space,
M. C. Fontaine, J. Togelius, S. Nikolaidis, and A. K. Hoover, “Covariance matrix adaptation for the rapid illumination of behavior space,” inPro- ceedings of the 2020 Genetic and Evolutionary Computation Conference (GECCO), 2020, pp. 94–102
2020
-
[25]
Dynamics-aware quality- diversity for efficient learning of skill repertoires,
B. Lim, M. Allard, L. Grillotti, and A. Cully, “Dynamics-aware quality- diversity for efficient learning of skill repertoires,” inProceedings of the 2022 IEEE International Conference on Robotics and Automation (ICRA), 2022, pp. 5360–5366
2022
-
[26]
Scaling map- elites to deep neuroevolution,
C. Colas, V . Madhavan, J. Huizinga, and J. Clune, “Scaling map- elites to deep neuroevolution,” inProceedings of the 2020 Genetic and Evolutionary Computation Conference (GECCO), 2020
2020
-
[27]
Using centroidal voronoi tessellations to scale up the multi-dimensional archive of phenotypic elites algorithm,
V . Vassiliades, K. Chatzilygeroudis, and J.-B. Mouret, “Using centroidal voronoi tessellations to scale up the multi-dimensional archive of phenotypic elites algorithm,” inIEEE Transactions on Evolutionary Computation, vol. 22, no. 4, 2018, pp. 623–630
2018
-
[28]
The benefits of structured elites in quality-diversity optimization,
V . Vassiliades and C. Christodoulou, “The benefits of structured elites in quality-diversity optimization,”Evolutionary Computation, vol. 26, no. 1, pp. 23–45, 2018
2018
-
[29]
Model-based reinforcement learning: A survey,
T. M. Moerland, J. Broekens, A. Plaat, and C. M. Jonker, “Model-based reinforcement learning: A survey,”arXiv preprint arXiv:2006.16795, 2023
-
[30]
Diversity is all you need: Learning skills without a reward function,
B. Eysenbach, A. Gupta, J. Ibarz, and S. Levine, “Diversity is all you need: Learning skills without a reward function,” inProceedings of the 7th International Conference on Learning Representations (ICLR), 2019
2019
-
[31]
CEM-RL: Combining evolutionary and gradient-based methods for policy search
A. Pourchot and O. Sigaud, “Cem-rl: Combining evolutionary and gradient-based methods for deep reinforcement learning,”arXiv preprint arXiv:1810.01222, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Evolution-guided policy gradient in reinforcement learning,
S. Khadka and K. Tumer, “Evolution-guided policy gradient in reinforcement learning,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 31, 2018
2018
-
[33]
Improving exploration in evolution strategies for deep reinforcement learning via a population of novelty-seeking agents,
E. Conti, V . Madhavan, F. P. Such, J. Lehman, K. O. Stanley, and J. Clune, “Improving exploration in evolution strategies for deep reinforcement learning via a population of novelty-seeking agents,” inAdvances in Neural Information Processing Systems, vol. 31, 2018, pp. 5027–5038
2018
-
[34]
Neural architecture search: A survey,
T. Elsken, J. H. Metzen, and F. Hutter, “Neural architecture search: A survey,”Journal of Machine Learning Research, vol. 20, no. 55, pp. 1–21, 2019
2019
-
[35]
Darts: Differentiable architecture search,
H. Liu, K. Simonyan, and Y . Yang, “Darts: Differentiable architecture search,” inProceedings of the 7th International Conference on Learning Representations (ICLR), 2019
2019
-
[36]
Once-for-all: Train one network and specialize it for efficient deployment,
H. Cai, C. Gan, T. Wang, Z. Zhang, and S. Han, “Once-for-all: Train one network and specialize it for efficient deployment,”arXiv preprint arXiv:1908.09791, 2019
-
[37]
Optimal brain damage,
Y . LeCun, J. S. Denker, and S. A. Solla, “Optimal brain damage,” Advances in Neural Information Processing Systems (NeurIPS), vol. 2, 1989
1989
-
[38]
Second order derivatives for network pruning: Optimal brain surgeon,
B. Hassibi and D. G. Stork, “Second order derivatives for network pruning: Optimal brain surgeon,” inAdvances in Neural Information Processing Systems (NeurIPS), 1993, pp. 164–171
1993
-
[39]
Learning both weights and 13 connections for efficient neural network,
S. Han, J. Pool, J. Tran, and W. Dally, “Learning both weights and 13 connections for efficient neural network,”Advances in Neural Information Processing Systems (NeurIPS), vol. 28, 2015
2015
-
[40]
Rigging the lottery: Making all tickets winners,
U. Evci, T. Gale, J. Menick, P. S. Castro, and E. Elsen, “Rigging the lottery: Making all tickets winners,” inProceedings of the 37th International Conference on Machine Learning (ICML), 2020, pp. 2943– 2952
2020
-
[41]
Supermasks in superposition,
M. Wortsman, V . Ramanujan, R. Liu, A. Kembhavi, M. Rastegari, J. Yosinski, and A. Farhadi, “Supermasks in superposition,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 15 173– 15 184
2020
-
[42]
Rlx2: Training a sparse deep reinforcement learning model from scratch,
Y . Tan, P. Hu, L. Pan, J. Huang, and L. Huang, “Rlx2: Training a sparse deep reinforcement learning model from scratch,” inProceedings of the 11th International Conference on Learning Representations, 2023
2023
- [43]
-
[44]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
Neuroscience-inspired artificial intelligence,
D. Hassabis, D. Kumaran, C. Summerfield, and M. Botvinick, “Neuroscience-inspired artificial intelligence,”Neuron, vol. 95, no. 2, pp. 245–258, 2017
2017
-
[46]
Adaptive representation learning for continual reinforcement learning,
S. Liu, F. Wanget al., “Adaptive representation learning for continual reinforcement learning,”Nature Machine Intelligence, vol. 6, no. 4, pp. 400–415, 2024
2024
-
[47]
Effective diversity in population based reinforcement learning,
J. Parker-Holder, A. Nguyen, and S. J. Roberts, “Effective diversity in population based reinforcement learning,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020
2020
-
[48]
Deep exploration via bootstrapped dqn,
I. Osband, C. Blundell, A. Pritzel, and B. V . Roy, “Deep exploration via bootstrapped dqn,” inAdvances in Neural Information Processing Systems, vol. 29, 2016. S1 Supplementary Document of “Structure-Conditioned Actor–Critic Branches for Quality-Diversity Reinforcement Learning” S-I. FIXED-ARCHIVEDEPLOYMENTEVALUATION This supplementary section provides t...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.