RGB-S: Image-Aligned Tactile Saliency for Robust Dexterous Manipulation
Pith reviewed 2026-06-27 18:08 UTC · model grok-4.3
The pith
Projecting tactile contacts onto RGB images as saliency maps improves occluded dexterous manipulation success by 26.7 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
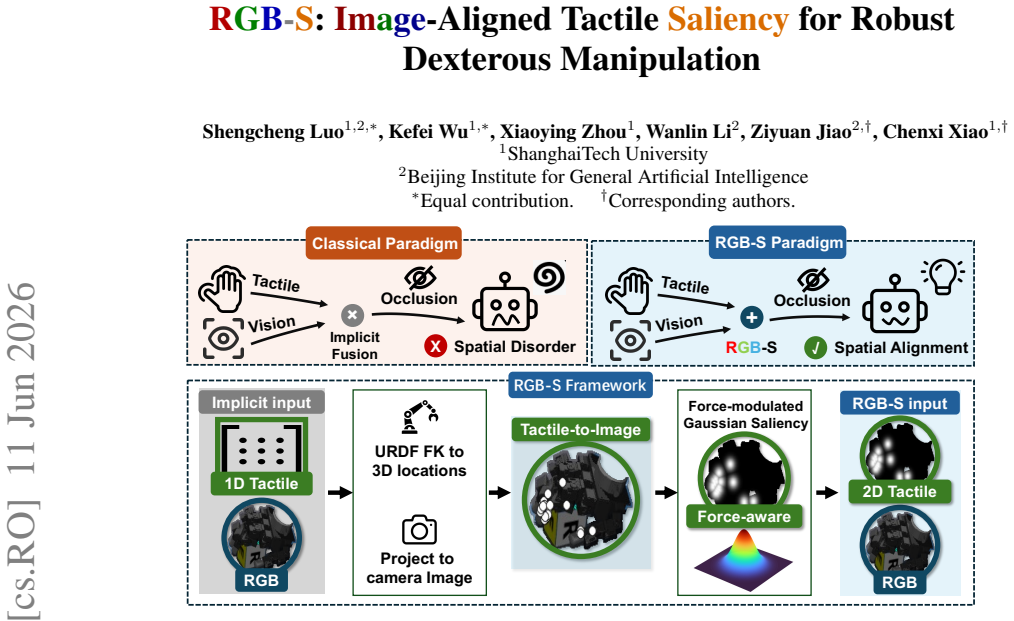
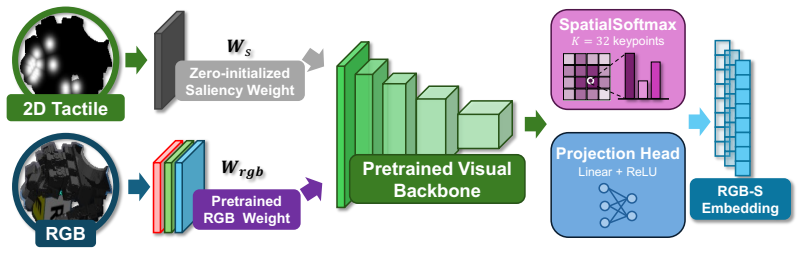
By projecting tactile sensor positions onto the image plane via forward kinematics and camera calibration, then rendering force-modulated Gaussian saliency maps, the RGB-S method injects physical contact information directly into visual backbones through a zero-initialized conditioning architecture, preserving pre-trained features while adding explicit spatial anchors.
What carries the argument
Image-aligned tactile saliency maps: force-modulated Gaussians projected from tactile sensors onto the RGB plane to model contact locations and uncertainty.
If this is right
- Explicit RGB-S grounding enables better spatial reasoning in policies under visual degradation.
- Zero-initialized conditioning allows integration without disrupting pre-trained visual representations.
- Improved performance holds across simulation and real-world occluded scenarios on six dexterous tasks.
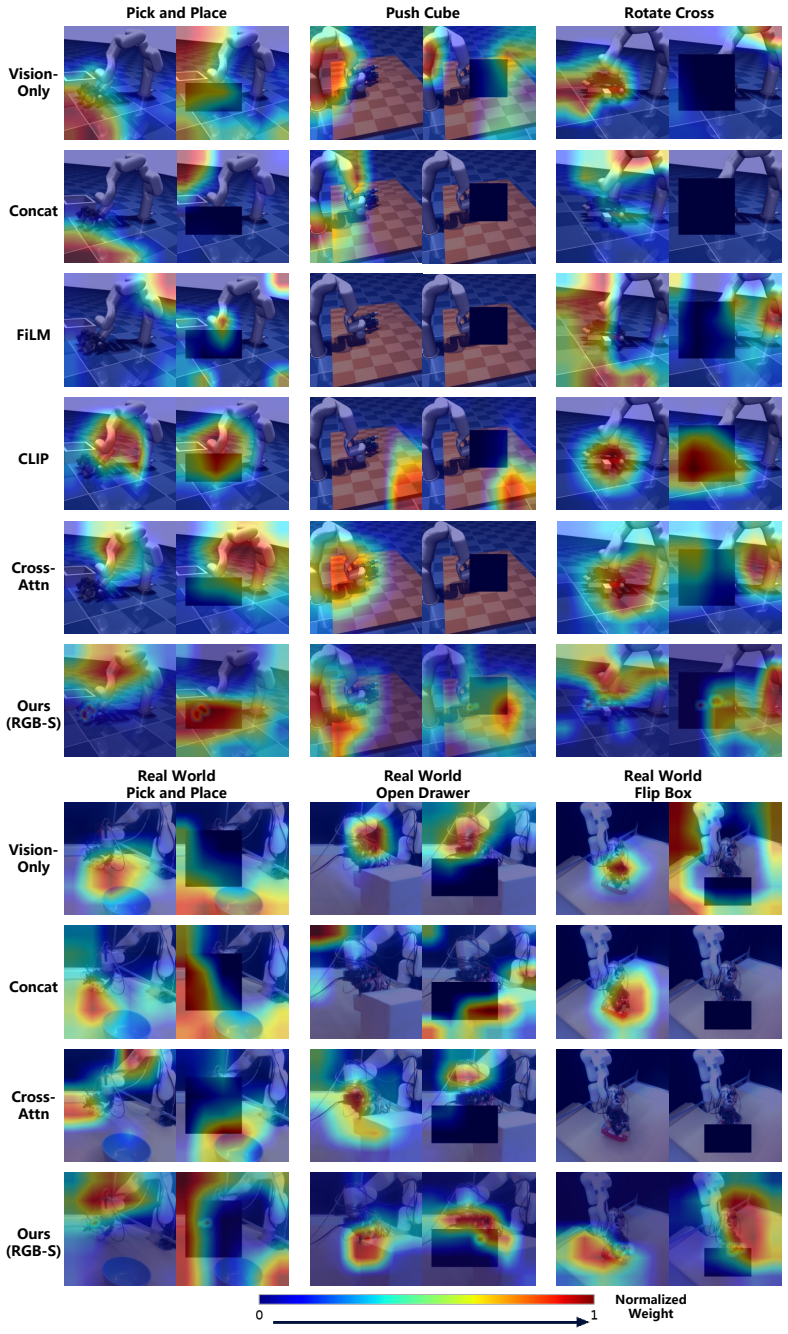
- Success rates increase by 26.7 percentage points over implicit baselines in real-world tests.
Where Pith is reading between the lines
- Similar projection techniques could extend to other sensor modalities like audio or thermal if geometric mappings exist.
- The Gaussian uncertainty modeling might be tuned per task to further improve robustness if calibration varies.
- Testing on tasks with moving cameras or deformable objects would reveal limits of the fixed calibration assumption.
Load-bearing premise
Robot forward kinematics and camera calibration are accurate enough to project tactile sensor locations onto the RGB image plane with only the modeled Gaussian uncertainty.
What would settle it
Running the method with deliberately miscalibrated camera parameters and observing if the performance gain over implicit baselines disappears or reverses.
Figures



read the original abstract
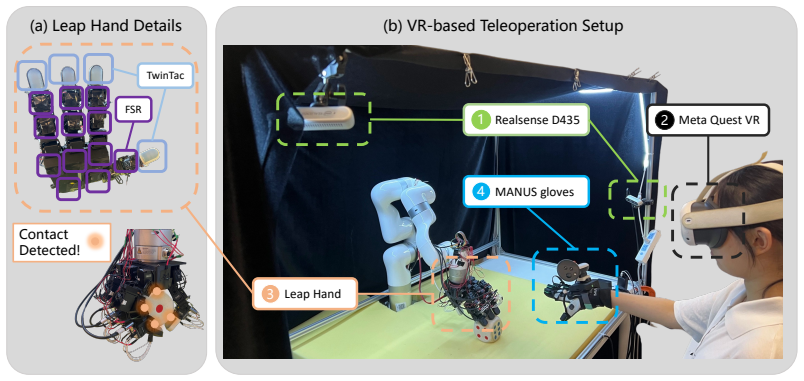
Effective visuo-tactile integration is critical for robotic dexterous manipulation, especially when visual observations are unreliable or occluded. However, robustly aligning sparse, heterogeneous tactile measurements with dense visual representations remains a fundamental challenge. Most existing approaches require policies to learn cross-modal correspondences implicitly from limited demonstrations, without leveraging geometric priors. As a result, they are often data-inefficient and generalize poorly when visual observations are degraded. To address this limitation, we propose a framework that explicitly grounds physical contacts in the image domain. Using robot forward kinematics and camera calibration, we project tactile sensor locations directly onto the RGB image plane. We then render force-modulated Gaussian saliency maps to model spatial uncertainty arising from kinematic and calibration errors. By integrating these 2D spatial anchors through a zero-initialized conditioning architecture, our method injects physical contact priors into standard visual backbones while preserving pre-trained visual representations. We evaluate our method on six dexterous manipulation tasks in both simulation and the real world under severe visual occlusions. Real-world experiments show that explicit RGB-S grounding in the image domain improves real-world occluded manipulation success rates by $26.7$ percentage points over the strongest implicit visuo-tactile baseline, suggesting its improved spatial reasoning and robustness to occlusion. Project page: touch-as-saliency.github.io
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RGB-S, a framework for explicit visuo-tactile integration in dexterous manipulation. It projects tactile sensor locations onto RGB images via robot forward kinematics and camera calibration, renders force-modulated Gaussian saliency maps to capture spatial uncertainty, and injects these into visual backbones through zero-initialized conditioning. Evaluated on six tasks in simulation and real-world settings with severe occlusions, it reports a 26.7 percentage point improvement in real-world occluded manipulation success rates over the strongest implicit visuo-tactile baseline.
Significance. If the central result holds after addressing calibration concerns, the work provides a geometrically grounded alternative to implicit cross-modal learning, potentially improving data efficiency and occlusion robustness while preserving pre-trained visual features. The explicit use of kinematic priors and real-world evaluation under occlusion are notable strengths.
major comments (2)
- [Abstract] Abstract: The reported 26.7 pp real-world improvement is presented without any details on experimental protocol, baseline implementations, number of trials, statistical tests, or data handling; this information is load-bearing for verifying whether the gain is attributable to explicit RGB-S grounding rather than implementation specifics.
- [Method] Method (projection and saliency rendering): The approach depends on forward kinematics and camera calibration being accurate enough that the modeled isotropic Gaussian captures all spatial uncertainty; if hardware errors contain systematic biases or exceed the modeled variance, the saliency maps become misaligned and the measured improvement could be an artifact of calibration quality rather than the explicit-grounding principle. The manuscript should include quantitative validation of projection accuracy on the experimental hardware.
minor comments (1)
- [Abstract] Abstract: The project page URL is referenced but not provided in the manuscript text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the geometric grounding and real-world evaluation under occlusion as strengths. We address the two major comments point by point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported 26.7 pp real-world improvement is presented without any details on experimental protocol, baseline implementations, number of trials, statistical tests, or data handling; this information is load-bearing for verifying whether the gain is attributable to explicit RGB-S grounding rather than implementation specifics.
Authors: We agree that the abstract would benefit from additional context on the experimental protocol to support the reported improvement. The full details (30 trials per task across six tasks, baseline re-implementations following original papers, paired t-tests with p < 0.01, and data handling procedures) are already provided in Sections 4.2–4.3 and the supplementary material. In the revision we will add one concise sentence to the abstract summarizing trial count and statistical significance while respecting length constraints. revision: yes
-
Referee: [Method] Method (projection and saliency rendering): The approach depends on forward kinematics and camera calibration being accurate enough that the modeled isotropic Gaussian captures all spatial uncertainty; if hardware errors contain systematic biases or exceed the modeled variance, the saliency maps become misaligned and the measured improvement could be an artifact of calibration quality rather than the explicit-grounding principle. The manuscript should include quantitative validation of projection accuracy on the experimental hardware.
Authors: The referee correctly notes that projection accuracy is central to the method. The isotropic Gaussian variance was selected empirically to encompass observed kinematic and calibration residuals on our hardware, and the zero-initialized conditioning allows the policy to down-weight misaligned cues. To strengthen the claim we will add a new appendix subsection with quantitative projection validation: repeated measurements of pixel error between forward-kinematics projections and ground-truth contact locations obtained via an external motion-capture system on the real robot, reporting mean and standard deviation across multiple arm configurations. revision: yes
Circularity Check
No significant circularity; method uses independent geometric priors and reports experimental results
full rationale
The paper describes a method that projects tactile sensor locations onto RGB images using robot forward kinematics and camera calibration, then renders force-modulated Gaussians. The 26.7 pp improvement is an empirical result from real-world experiments against baselines. No equations, derivations, or self-citations reduce the central claim to fitted inputs or self-referential quantities by construction. The geometric projection is an external prior independent of the performance metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Robot forward kinematics and camera calibration provide sufficiently accurate projections of tactile sensor locations onto the image plane
invented entities (1)
-
RGB-S saliency maps
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Radosavovic, T
I. Radosavovic, T. Xiao, S. James, P. Abbeel, J. Malik, and T. Darrell. Real-world robot learn- ing with masked visual pre-training. In K. Liu, D. Kulic, and J. Ichnowski, editors,Proceedings of The 6th Conference on Robot Learning, volume 205 ofProceedings of Machine Learning Research, pages 416–426. PMLR, 14–18 Dec 2023
2023
-
[2]
Majumdar, K
A. Majumdar, K. Yadav, S. Arnaud, J. Ma, C. Chen, S. Silwal, A. Jain, V .-P. Berges, T. Wu, J. Vakil, P. Abbeel, J. Malik, D. Batra, Y . Lin, O. Maksymets, A. Rajeswaran, and F. Meier. Where are we in the search for an artificial visual cortex for embodied intelligence? In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advanc...
2023
-
[3]
Perez, F
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[4]
Calandra, A
R. Calandra, A. Owens, M. Upadhyaya, W. Yuan, J. Lin, E. H. Adelson, and S. Levine. The feeling of success: Does touch sensing help predict grasp outcomes? In S. Levine, V . Van- houcke, and K. Goldberg, editors,Proceedings of the 1st Annual Conference on Robot Learn- ing, volume 78 ofProceedings of Machine Learning Research, pages 314–323. PMLR, 13–15 Nov 2017
2017
-
[5]
R. Calandra, A. Owens, D. Jayaraman, J. Lin, W. Yuan, J. Malik, E. H. Adelson, and S. Levine. More than a feeling: Learning to grasp and regrasp using vision and touch.IEEE Robotics and Automation Letters, 3(4):3300–3307, Oct. 2018. ISSN 2377-3774. doi:10.1109/lra.2018. 2852779. URLhttp://dx.doi.org/10.1109/LRA.2018.2852779
-
[6]
Guzey, Y
I. Guzey, Y . Dai, B. Evans, S. Chintala, and L. Pinto. See to touch: Learning tactile dexterity through visual incentives. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 13825–13832. IEEE, 2024
2024
-
[7]
H. Chen, J. Xu, H. Chen, K. Hong, B. Huang, C. Liu, J. Mao, Y . Li, Y . Du, and K. Driggs- Campbell. Multi-modal manipulation via multi-modal policy consensus. In2026 IEEE Inter- national Conference on Robotics and Automation (ICRA), 2026
2026
-
[8]
R. Feng, D. Hu, W. Ma, and X. Li. Play to the score: Stage-guided dynamic multi-sensory fusion for robotic manipulation. In P. Agrawal, O. Kroemer, and W. Burgard, editors,Pro- ceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learning Research, pages 340–363. PMLR, 06–09 Nov 2025
2025
-
[9]
E. Su, C. Jia, Y . Qin, W. Zhou, A. Macaluso, B. Huang, and X. Wang. Sim2real manipulation on unknown objects with tactile-based reinforcement learning. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 9234–9241. IEEE, 2024
2024
-
[10]
T. Wu, J. Li, J. Zhang, M. Wu, and H. Dong. Canonical representation and force-based pre- training of 3d tactile for dexterous visuo-tactile policy learning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 6786–6792. IEEE, 2025. 9
2025
-
[11]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. InPro- ceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[12]
Zhang, A
L. Zhang, A. Rao, and M. Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
2023
-
[13]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware, 2023. URLhttps://arxiv.org/abs/2304.13705
Pith/arXiv arXiv 2023
-
[14]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[15]
Guzey, B
I. Guzey, B. Evans, S. Chintala, and L. Pinto. Dexterity from touch: Self-supervised pre- training of tactile representations with robotic play. In J. Tan, M. Toussaint, and K. Darvish, editors,Proceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 3142–3166. PMLR, 06–09 Nov 2023
2023
-
[16]
P. Lin, Y . Huang, W. Li, J. Ma, C. Xiao, and Z. Jiao. Pp-tac: Paper picking using tactile feedback in dexterous robotic hands.arXiv preprint arXiv:2504.16649, 2025
arXiv 2025
-
[17]
S. Dong, D. Ma, E. Donlon, and A. Rodriguez. Maintaining grasps within slipping bounds by monitoring incipient slip. In2019 International Conference on Robotics and Automation (ICRA), pages 3818–3824. IEEE, 2019
2019
-
[18]
Y . She, S. Wang, S. Dong, N. Sunil, A. Rodriguez, and E. Adelson. Cable manipulation with a tactile-reactive gripper.The International Journal of Robotics Research, 40(12-14):1385– 1401, 2021
2021
-
[19]
H. Li, S. Dikhale, S. Iba, and N. Jamali. Vihope: Visuotactile in-hand object 6d pose estimation with shape completion.IEEE Robotics and Automation Letters, 8(11):6963–6970, 2023. doi: 10.1109/LRA.2023.3313941
-
[20]
C. Sferrazza, Y . Seo, H. Liu, Y . Lee, and P. Abbeel. The power of the senses: Generalizable manipulation from vision and touch through masked multimodal learning. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 9698–9705, 2024. doi:10.1109/IROS58592.2024.10802719
-
[21]
X. Chen, Y . Pan, M. Li, and X. Ding. Dexvitac: Collecting human visuo-tactile-kinematic demonstrations for contact-rich dexterous manipulation, 2026. URLhttps://arxiv.org/ abs/2603.17851
arXiv 2026
-
[22]
X. Zhu, B. Huang, and Y . Li. Touch in the wild: Learning fine-grained manipulation with a portable visuo-tactile gripper.ArXiv, abs/2507.15062, 2025. URLhttps://api. semanticscholar.org/CorpusID:280270301
arXiv 2025
-
[23]
Y . Chen, M. V . d. Merwe, A. Sipos, and N. Fazeli. Visuo-tactile transformers for manipu- lation. In K. Liu, D. Kulic, and J. Ichnowski, editors,Proceedings of The 6th Conference on Robot Learning, volume 205 ofProceedings of Machine Learning Research, pages 2026–2040. PMLR, 14–18 Dec 2023
2026
-
[24]
V . Pattabiraman, Y . Cao, S. Haldar, L. Pinto, and R. Bhirangi. Learning precise, contact- rich manipulation through uncalibrated tactile skins, 2024. URLhttps://arxiv.org/abs/ 2410.17246
arXiv 2024
- [25]
- [26]
-
[27]
W. Yuan, S. Dong, and E. H. Adelson. Gelsight: High-resolution robot tactile sensors for estimating geometry and force.Sensors (Basel, Switzerland), 17, 2017. URLhttps://api. semanticscholar.org/CorpusID:3474913
2017
-
[28]
R. Bhirangi, V . Pattabiraman, E. Erciyes, Y . Cao, T. Hellebrekers, and L. Pinto. Anyskin: Plug- and-play skin sensing for robotic touch, 2024. URLhttps://arxiv.org/abs/2409.08276
arXiv 2024
- [29]
-
[30]
Smug planner: A safe multi-goal planner for mobile robots in challenging environments
M. Lambeta, P.-W. Chou, S. Tian, B. Yang, B. Maloon, V . R. Most, D. Stroud, R. Santos, A. Byagowi, G. Kammerer, D. Jayaraman, and R. Calandra. Digit: A novel design for a low- cost compact high-resolution tactile sensor with application to in-hand manipulation.IEEE Robotics and Automation Letters, 5(3):3838–3845, 2020. ISSN 2377-3774. doi:10.1109/lra. 20...
work page doi:10.1109/lra 2020
-
[31]
V . Dave, F. Lygerakis, and E. Rueckert. Multimodal visual-tactile representation learning through self-supervised contrastive pre-training. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 8013–8020. IEEE, 2024
2024
-
[32]
Z. Xue, H. Zhang, J. Cheng, Z. He, Y . Ju, C. Lin, G. Zhang, and H. Xu. Arraybot: Rein- forcement learning for generalizable distributed manipulation through touch. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 16744–16751. IEEE, 2024
2024
-
[33]
M. A. Lee, Y . Zhu, K. Srinivasan, P. Shah, S. Savarese, L. Fei-Fei, A. Garg, and J. Bohg. Making sense of vision and touch: Self-supervised learning of multimodal representations for contact-rich tasks. In2019 International conference on robotics and automation (ICRA), pages 8943–8950. IEEE, 2019
2019
-
[34]
R. Feng, J. Hu, W. Xia, T. Gao, A. Shen, Y . Sun, B. Fang, and D. Hu. Anytouch: Learning unified static-dynamic representation across multiple visuo-tactile sensors, 2025. URLhttps: //arxiv.org/abs/2502.12191
arXiv 2025
-
[35]
Rodriguez, Y
S. Rodriguez, Y . Dou, W. van den Bogert, M. Oller, K. So, A. Owens, and N. Fazeli. Con- trastive touch-to-touch pretraining. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 5857–5863. IEEE, 2025
2025
-
[36]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. De- hghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021. URLhttps: //arxiv.org/abs/2010.11929
Pith/arXiv arXiv 2021
-
[37]
K. Shaw, A. Agarwal, and D. Pathak. Leap hand: Low-cost, efficient, and anthropomorphic hand for robot learning.arXiv preprint arXiv:2309.06440, 2023
arXiv 2023
-
[38]
Zhang, Z
T. Zhang, Z. McCarthy, O. Jow, D. Lee, X. Chen, K. Goldberg, and P. Abbeel. Deep imita- tion learning for complex manipulation tasks from virtual reality teleoperation. In2018 IEEE international conference on robotics and automation (ICRA), pages 5628–5635. Ieee, 2018
2018
-
[39]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[40]
Jaegle, F
A. Jaegle, F. Gimeno, A. Brock, O. Vinyals, A. Zisserman, and J. Carreira. Perceiver: General perception with iterative attention. InInternational conference on machine learning, pages 4651–4664. PMLR, 2021. 11
2021
-
[41]
N. M. Shafiullah, Z. Cui, A. A. Altanzaya, and L. Pinto. Behavior transformers: Cloningk modes with one stone.Advances in neural information processing systems, 35:22955–22968, 2022
2022
-
[42]
S. Chen, C. Wang, K. Nguyen, L. Fei-Fei, and C. K. Liu. Arcap: Collecting high-quality human demonstrations for robot learning with augmented reality feedback. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8291–8298. IEEE, 2025
2025
-
[43]
Z. Xu, F. Zhao, X. Huang, and C. Xiao. Etac: A lightweight and efficient tactile simulation framework for learning dexterous manipulation.arXiv preprint arXiv:2604.20295, 2026
Pith/arXiv arXiv 2026
-
[44]
L. Chen, Y . Qin, X. Zhou, and H. Su. Easyhec: Accurate and automatic hand-eye calibration via differentiable rendering and space exploration.IEEE Robotics and Automation Letters, 8 (11):7234–7241, Nov. 2023. ISSN 2377-3774. doi:10.1109/lra.2023.3315551. URLhttp: //dx.doi.org/10.1109/LRA.2023.3315551
-
[45]
Y .-H. Wu, J. Wang, and X. Wang. Learning generalizable dexterous manipulation from human grasp affordance. InConference on robot learning, pages 618–629. PMLR, 2023
2023
-
[46]
C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660, 2017
2017
-
[47]
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE international conference on computer vision, pages 618–626, 2017
2017
-
[48]
R. Cadene, S. Aliberts, F. Capuano, M. Aractingi, A. Zouitine, P. Kooijmans, J. Choghari, M. Russi, C. Pascal, S. Palma, et al. Lerobot: An open-source library for end-to-end robot learning.arXiv preprint arXiv:2602.22818, 2026. 12 Appendix Overview This appendix provides additional details on the experimental setup, simulation and real-world task configu...
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.