PaperMentor: A Human-Centered Multi-Agent Writing Tutor for AI Research Papers on Overleaf
Pith reviewed 2026-06-27 18:22 UTC · model grok-4.3
The pith
PaperMentor combines a curated expert skill library with twelve specialized agents to produce actionable inline comments on Overleaf research paper drafts while leaving all writing to the human author.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
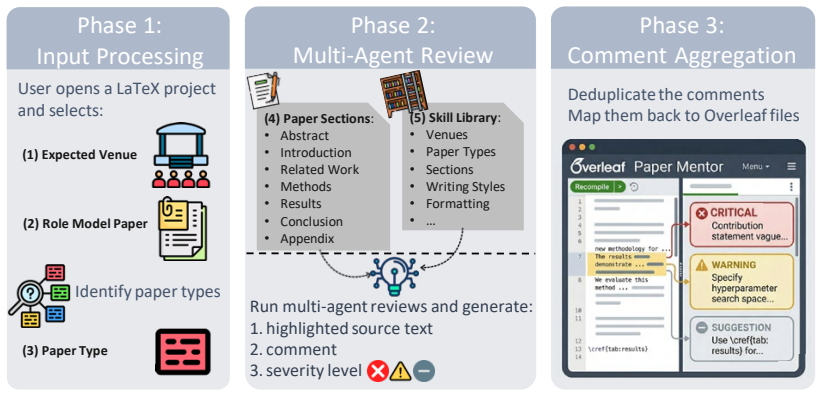
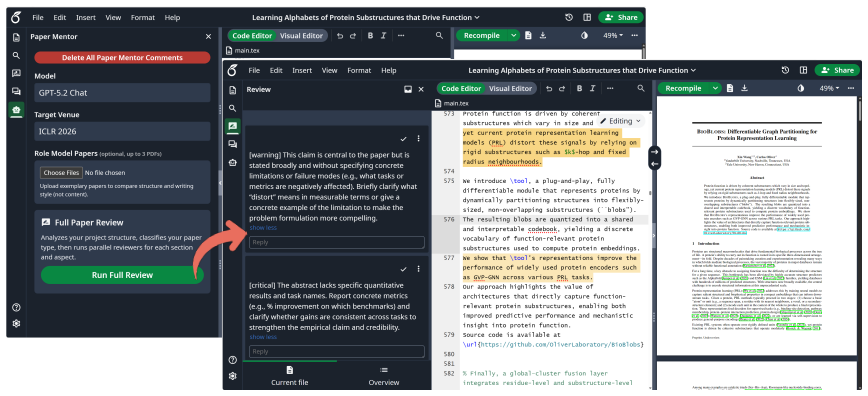
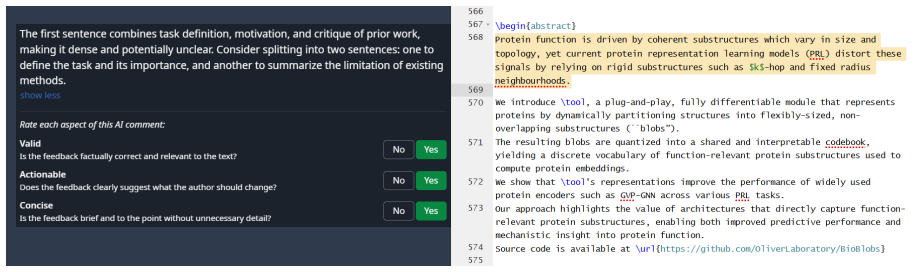
PaperMentor integrates an expert skill library carefully curated from established researchers' writing advice with 12 specialized agents covering different aspects of paper writing, such as formatting compliance, phrasing accuracy, and terminology consistency. In a user study (n=14), 90.6% of the generated comments were rated actionable and 67.5% were rated valid, significantly outperforming a GPT-5.2 baseline without the skill library. The system delivers these suggestions as Overleaf-native inline comments while leaving the actual writing entirely to human authors.
What carries the argument
A multi-agent architecture in which twelve specialized agents apply a fixed expert skill library to scan Overleaf drafts and emit native inline comments.
Load-bearing premise
The expert skill library curated from established researchers' writing advice remains effective and generalizable when applied by the twelve agents across varied paper drafts and user populations.
What would settle it
A follow-up study with more participants in which the share of comments rated actionable falls below 70 percent would show that the reported performance does not hold.
Figures
read the original abstract
Expert writing feedback from experienced researchers is critical for early-career scholars to improve their manuscripts, yet high-quality feedback often remains scarce because reviewing research papers is labor-intensive. Emerging AI-powered writing assistants largely focus on grammar fixes or simulating peer review with final scores, yet they fall short of providing concrete, actionable suggestions that help students improve their papers during drafting. We present PaperMentor, a human-centered writing assistant system that delivers actionable suggestions as Overleaf-native inline comments while leaving the actual writing entirely to human authors. PaperMentor integrates an expert skill library carefully curated from established researchers' writing advice with 12 specialized agents covering different aspects of paper writing, such as formatting compliance, phrasing accuracy, and terminology consistency. In a user study (n=14), 90.6% of the generated comments were rated actionable and 67.5% were rated valid, significantly outperforming a GPT-5.2 baseline uswithout the skill library. We release PaperMentor as open source for public use. Our code is publicly available under the AGPL-3.0 license at https://github.com/jiarui-liu/overleaf
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PaperMentor, a multi-agent system integrated with Overleaf that uses a curated expert skill library and 12 specialized agents to generate actionable inline comments on research paper drafts. The system leaves writing to the human author. A user study (n=14) reports that 90.6% of generated comments were rated actionable and 67.5% valid, significantly outperforming a GPT-5.2 baseline without the skill library. The code is released as open source under AGPL-3.0.
Significance. If the performance claims are substantiated by larger-scale evaluation, the work could advance human-centered AI writing tools by showing how curated expert advice can be operationalized via multi-agent systems to deliver inline, actionable feedback during drafting rather than post-hoc review. The open-source release is a clear strength that supports reproducibility and adoption.
major comments (3)
- [Abstract] Abstract (user study paragraph): the central performance claim rests on n=14 with reported percentages of 90.6% actionable and 67.5% valid but provides no statistical details, confidence intervals, p-values, or error bars, nor any description of participant selection, task instructions, or inter-rater reliability; this leaves the 'significantly outperforming' assertion weakly supported.
- [Abstract] Abstract (expert skill library description): the claim that the library drives the improvement over the no-library baseline requires evidence on curation process, number and diversity of source researchers, and how advice is encoded for the 12 agents; none is supplied, so the results cannot be confidently attributed to the library rather than prompt engineering or study-specific factors.
- [Abstract] Abstract (evaluation): no information is given on paper topics, lengths, author experience levels, or out-of-distribution testing, so the generalizability of the 12-agent + library approach across varied drafts remains untested and load-bearing for the human-centered contribution.
minor comments (2)
- [Abstract] Abstract contains the apparent typo 'uswithout' in the baseline description; correct to 'without'.
- [Abstract] Clarify the exact model used for the 'GPT-5.2 baseline' (version, prompting details) so readers can replicate the comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below, proposing targeted revisions to the abstract where details can be added without exceeding length limits, while referring to the full manuscript for supporting information.
read point-by-point responses
-
Referee: [Abstract] Abstract (user study paragraph): the central performance claim rests on n=14 with reported percentages of 90.6% actionable and 67.5% valid but provides no statistical details, confidence intervals, p-values, or error bars, nor any description of participant selection, task instructions, or inter-rater reliability; this leaves the 'significantly outperforming' assertion weakly supported.
Authors: The abstract summarizes key outcomes under space constraints. The Evaluation section of the full manuscript details participant selection (14 early-career AI researchers recruited via academic networks), task instructions, inter-rater reliability (Cohen's kappa reported), and statistical tests confirming significance over the baseline. We will revise the abstract to include a concise reference to statistical significance and participant background to better support the claim. revision: yes
-
Referee: [Abstract] Abstract (expert skill library description): the claim that the library drives the improvement over the no-library baseline requires evidence on curation process, number and diversity of source researchers, and how advice is encoded for the 12 agents; none is supplied, so the results cannot be confidently attributed to the library rather than prompt engineering or study-specific factors.
Authors: The abstract notes the library is 'carefully curated from established researchers' writing advice.' The full manuscript (Section 3.2) describes curation from 20+ published sources by researchers at diverse institutions, with advice encoded as structured, modular prompts for the 12 agents. We will add a brief clause to the abstract on the curation process and source diversity to clarify attribution of gains to the library. revision: yes
-
Referee: [Abstract] Abstract (evaluation): no information is given on paper topics, lengths, author experience levels, or out-of-distribution testing, so the generalizability of the 12-agent + library approach across varied drafts remains untested and load-bearing for the human-centered contribution.
Authors: The user study used AI/ML paper drafts of 4-8 pages by authors with 1-5 years of experience. The full manuscript characterizes the drafts and notes the study scope. Out-of-distribution testing was not performed in this initial evaluation. We will add a short description of draft characteristics to the abstract and expand the limitations discussion on generalizability. revision: partial
Circularity Check
No circularity; evaluation is external user study with no derivations or self-referential reductions
full rationale
The paper describes a multi-agent writing assistant system and reports performance via a user study (n=14) comparing against a GPT-5.2 baseline without the skill library. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text. The central claims rest on empirical ratings (90.6% actionable, 67.5% valid) from an external study rather than any derivation that reduces to the paper's own inputs by construction. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
invented entities (2)
-
12 specialized agents
no independent evidence
-
expert skill library
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Challenges, Experiments, and Computational Solutions in Peer Review , author =. Communications of the. doi:10.1145/3528086 , url =
-
[2]
Writing is thinking , journal =. 2025 , volume =. doi:10.1038/s44222-025-00323-4 , url =
-
[3]
CSP aper Review: Fast, Rubric-Faithful Conference Feedback
Cao, Lele and You, Lei and Team, R & d. CSP aper Review: Fast, Rubric-Faithful Conference Feedback. Proceedings of the 18th International Natural Language Generation Conference: System Demonstrations. 2025
2025
-
[4]
What Can We Do to Improve Peer Review in
Rogers, Anna and Augenstein, Isabelle , year = 2020, booktitle =. What Can We Do to Improve Peer Review in. doi:10.18653/v1/2020.findings-emnlp.112 , url =
-
[5]
How to Write a Great Research Paper , author =
-
[6]
NLP PhD Global Equality: Writing Suggestions from Various Professors , author =
-
[7]
Journal of Artificial Intelligence Research , volume = 75, pages =
Can We Automate Scientific Reviewing? , author =. Journal of Artificial Intelligence Research , volume = 75, pages =
-
[8]
Data Statements for Natural Language Processing: Toward Mitigating System Bias and Enabling Better Science , author =. Transactions of the Association for Computational Linguistics , volume = 6, pages =. doi:10.1162/tacl_a_00041 , url =
-
[9]
Datasheets for Datasets , author =. Communications of the ACM , volume = 64, number = 12, pages =. doi:10.1145/3458723 , url =
-
[10]
Embers of Autoregression: Understanding Large Language Models Through the Problem They are Trained to Solve , author =
-
[11]
The Twelfth International Conference on Learning Representations,
Can Large Language Models Infer Causation from Correlation? , author =. The Twelfth International Conference on Learning Representations,
-
[12]
, year = 2019, booktitle =
Reddy, Siva and Chen, Danqi and Manning, Christopher D. , year = 2019, booktitle =
2019
-
[13]
Know What You Don't Know: Unanswerable Questions for
Rajpurkar, Pranav and Jia, Robin and Liang, Percy , year = 2018, booktitle =. Know What You Don't Know: Unanswerable Questions for
2018
-
[14]
Can large language models provide useful feedback on research papers? A large-scale empirical analysis , author=. NEJM AI , volume=. 2024 , publisher=. doi:10.1056/AIoa2400196 , url=
-
[15]
arXiv preprint arXiv:2306.00622 , year=
Reviewergpt? an exploratory study on using large language models for paper reviewing , author=. arXiv preprint arXiv:2306.00622 , year=
-
[16]
Proceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (LREC-COLING 2024) , pages=
Is LLM a reliable reviewer? A comprehensive evaluation of LLM on automatic paper reviewing tasks , author=. Proceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (LREC-COLING 2024) , pages=. 2024 , url=
2024
-
[17]
Journal of Artificial Intelligence Research , volume=
Can we automate scientific reviewing? , author=. Journal of Artificial Intelligence Research , volume=. 2022 , doi=
2022
-
[18]
arXiv preprint arXiv:2504.09737 , year=
Can LLM feedback enhance review quality? A randomized study of 20k reviews at ICLR 2025 , author=. arXiv preprint arXiv:2504.09737 , year=
arXiv 2025
-
[19]
Large language models for automated scholarly paper review: A survey , author=. Information Fusion , volume=. 2025 , publisher=. doi:10.1016/j.inffus.2025.103332 , url=
-
[20]
arXiv preprint arXiv:2401.04259 , year=
Marg: Multi-agent review generation for scientific papers , author=. arXiv preprint arXiv:2401.04259 , year=
-
[21]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Automated focused feedback generation for scientific writing assistance , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=. 2024 , doi=
2024
-
[22]
Neurips 2024 Workshop Foundation Models for Science: Progress, Opportunities, and Challenges , year=
MAMORX: Multi-agent multi-modal scientific review generation with external knowledge , author=. Neurips 2024 Workshop Foundation Models for Science: Progress, Opportunities, and Challenges , year=
2024
-
[23]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Agentreview: Exploring peer review dynamics with llm agents , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=. 2024 , doi=
2024
-
[24]
G en GO Ultra: an LLM -powered ACL Paper Explorer
Takeshita, Sotaro and Tsereteli, Tornike and Ponzetto, Simone Paolo. G en GO Ultra: an LLM -powered ACL Paper Explorer. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). 2025. doi:10.18653/v1/2025.acl-demo.24
-
[25]
2025 , eprint=
ReviewAgents: Bridging the Gap Between Human and AI-Generated Paper Reviews , author=. 2025 , eprint=
2025
-
[26]
Generative Reviewer Agents: Scalable Simulacra of Peer Review
Bougie, Nicolas and Watanabe, Narimawa. Generative Reviewer Agents: Scalable Simulacra of Peer Review. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track. 2025. doi:10.18653/v1/2025.emnlp-industry.8
-
[27]
DeepReview: Improving LLM- based paper review with human-like deep thinking process
Zhu, Minjun and Weng, Yixuan and Yang, Linyi and Zhang, Yue. D eep R eview: Improving LLM -based Paper Review with Human-like Deep Thinking Process. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1420
-
[28]
Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems , pages=
A design space for intelligent and interactive writing assistants , author=. Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems , pages=. 2024 , doi=
2024
-
[29]
Proceedings of the 2024 CHI conference on human factors in computing systems , pages=
Shaping human-AI collaboration: Varied scaffolding levels in co-writing with language models , author=. Proceedings of the 2024 CHI conference on human factors in computing systems , pages=. 2024 , doi=
2024
-
[30]
2024 , url =
Han, Jieun and Yoo, Haneul and Myung, Junho and Kim, Minsun and Lim, Hyunseung and Kim, Yoonsu and Lee, Tak Yeon and Hong, Hwajung and Kim, Juho and Ahn, So-Yeon and others , booktitle =. 2024 , url =
2024
-
[31]
2026 , note =
Writefull , author =. 2026 , note =
2026
-
[32]
2026 , note =
Grammarly , author =. 2026 , note =
2026
-
[33]
2026 , note =
Prism , author =. 2026 , note =
2026
-
[34]
2026 , note =
PaperReview.ai , author =. 2026 , note =
2026
-
[35]
2021 , howpublished =
Zhijing Jin , title =. 2021 , howpublished =
2021
-
[36]
2010 , howpublished =
Jason Eisner , title =. 2010 , howpublished =
2010
-
[37]
How to Write a Great Research Paper: Seven Simple Suggestions , year =
Simon. How to Write a Great Research Paper: Seven Simple Suggestions , year =
-
[38]
2006 , howpublished =
Jennifer Widom , title =. 2006 , howpublished =
2006
-
[39]
Shomir Wilson , title =
-
[40]
Tim Rockt. How to. 2022 , howpublished =
2022
-
[41]
Chris Maddison , title =
-
[42]
Michael Black , title =
-
[43]
2023 , howpublished =
Jia-Bin Huang , title =. 2023 , howpublished =
2023
-
[44]
2021 , howpublished =
ACL , title =. 2021 , howpublished =
2021
-
[45]
Jordan Boyd-Graber , title =
-
[46]
Devi Parikh , title =
-
[47]
2021 , howpublished =
Maxwell Forbes , title =. 2021 , howpublished =
2021
-
[48]
Introducing GPT-5.2 , year =
-
[49]
BioBlobs: Unsupervised Discovery of Functional Substructures for Protein Function Prediction
BioBlobs: Unsupervised Discovery of Functional Substructures for Protein Function Prediction , author=. arXiv preprint arXiv:2510.01632 , year=. doi:10.48550/arXiv.2510.01632 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.01632
-
[50]
2025 , howpublished =
Introducing Claude Opus 4.5 , author =. 2025 , howpublished =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.