Building Customer Support AI Agents at 100M-User Scale: An Evaluation-Driven Framework
Pith reviewed 2026-06-27 18:20 UTC · model grok-4.3
The pith
An evaluation-driven framework for customer support AI agents produces 37-point gains in satisfaction metrics and predicts online results from offline tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
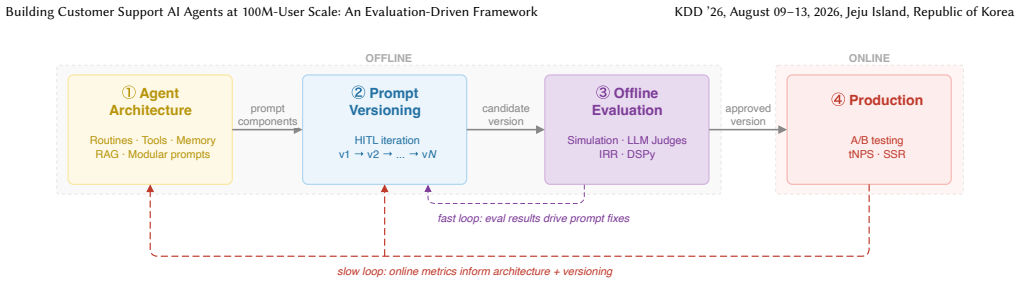
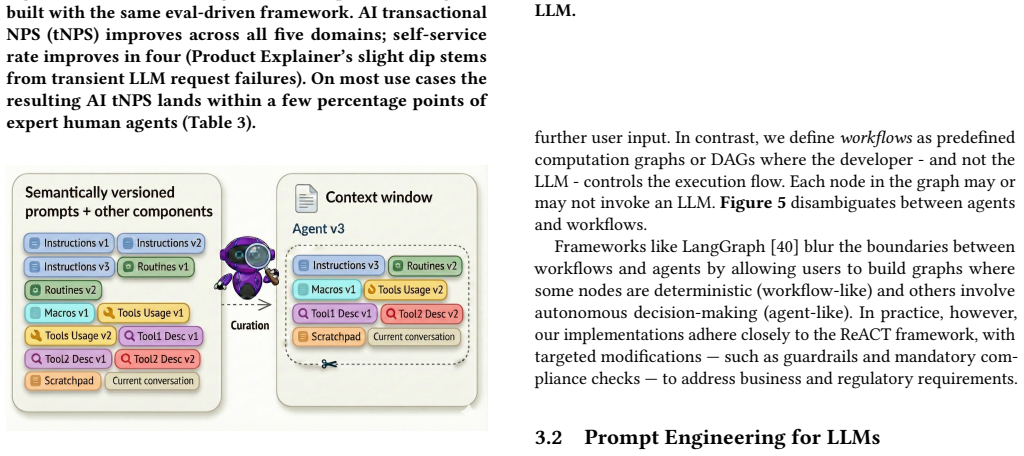
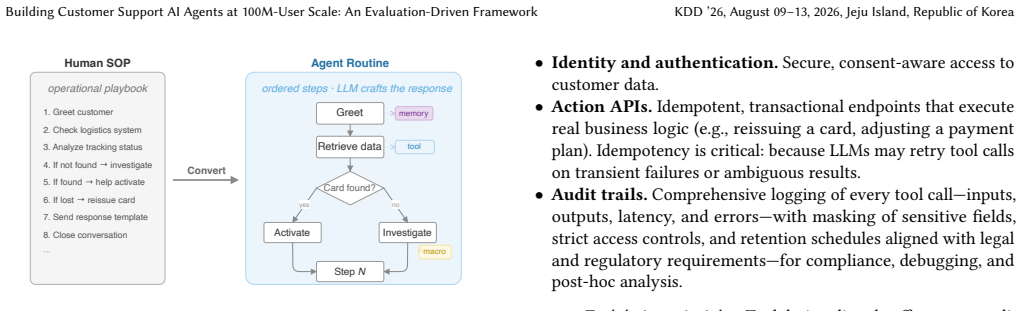
The central claim is that a unified framework integrating structured context engineering, systematic human-in-the-loop prompt iteration, rigorous LLM judge evaluation with measured inter-rater agreement and GEPA optimization, and ideation-to-production validation bridges offline development with online impact for customer support AI agents, producing consistent satisfaction gains and strong correlation between simulation metrics and real-world results across five deployments.
What carries the argument
The evaluation pipeline, which uses LLM judges with quantified inter-rater agreement and GEPA optimization to create reliable proxies for customer satisfaction, serves as the mechanism that sets iteration speed and production predictability.
If this is right
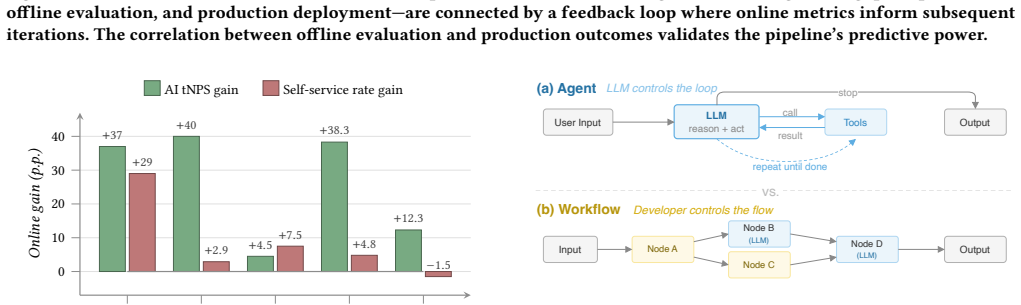
- Large-scale A/B testing in card delivery confirms 37-point tNPS and 29-point self-service gains over prior agent versions.
- Offline simulation metrics correlate strongly with online customer outcomes.
- AI agent satisfaction reaches within a few percentage points of expert human agents on most tested use cases.
- The same framework components apply successfully across five distinct domains including debt management and credit-limit support.
- Higher-quality evaluation pipelines directly increase the speed of reaching production-ready agents.
Where Pith is reading between the lines
- The same offline-to-online correlation could be tested in non-support agent domains such as sales or internal tooling.
- Further improvements in judge consistency might narrow the remaining gap to human performance.
- At 100M-user scale, even modest percentage-point lifts in self-service translate to large absolute reductions in agent workload.
- The framework's success in five domains suggests it may generalize to additional support categories without major redesign.
Load-bearing premise
LLM judge scores with measured agreement serve as accurate, generalizable proxies for actual customer satisfaction across support domains.
What would settle it
A new deployment in which the framework's offline simulation metrics show no correlation with subsequent large-scale A/B test results on transactional Net Promoter Score or self-service rate.
Figures

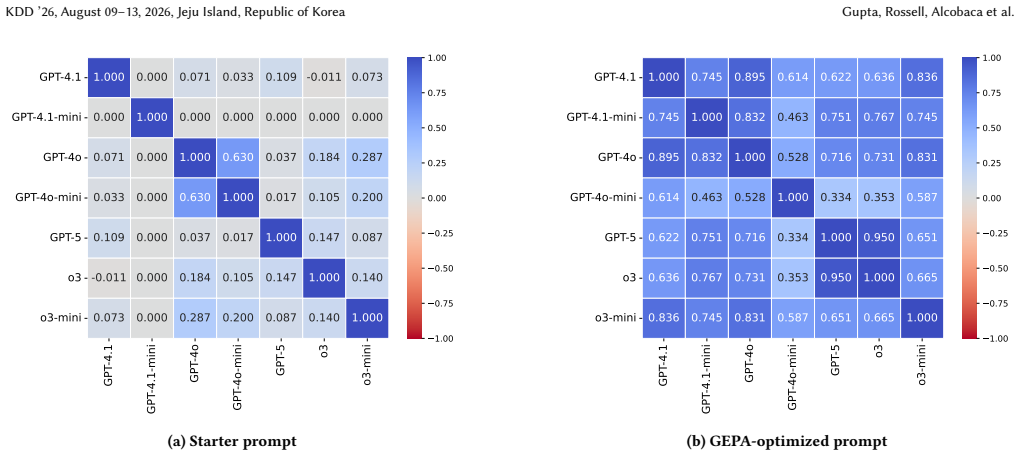

read the original abstract
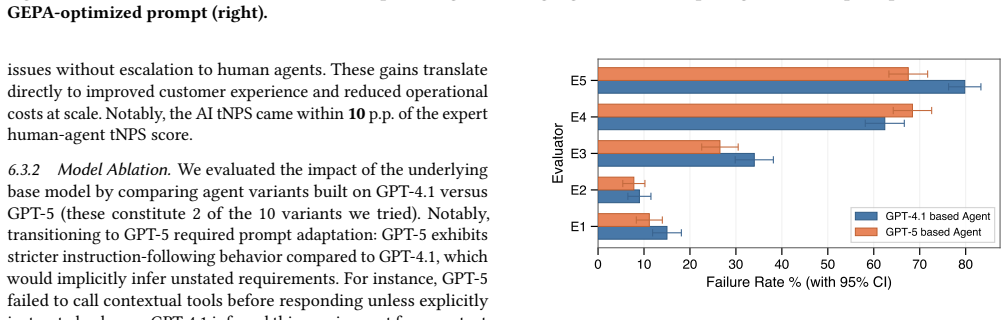
The rapid rise in LLM capabilities has made AI agents increasingly viable across a broad range of tasks. Among the most promising applications is building production-ready customer-facing agents, a challenge that demands coordinated excellence in evaluation methodology, context engineering, training, and online measurement. Yet these critical pillars are typically developed in isolation, creating blind spots that only surface after deployment. In this paper, we present a unified framework that bridges offline development with online impact for customer support AI agents at Nubank, a company with 100M+ users. Our approach integrates several key components: (1) structured context engineering tailored to customer support agents, (2) systematic human-in-the-loop prompt iteration, (3) rigorous LLM judge evaluation with measured inter-rater agreement and GEPA optimization for consistency, and (4) ideation-to-production validation. A central insight is that evaluation-pipeline quality directly determines iteration velocity. We present results from five production deployments spanning distinct domains: card delivery, debt management, credit-limit support, card management, and product explanation. These deployments deliver consistent customer-satisfaction gains while substantially accelerating iteration. In our card-delivery deployment, large-scale A/B testing yields a 37 percentage-point improvement in AI transactional Net Promoter Score and a 29 percentage-point gain in self-service rate over prior agent variants, alongside a strong correlation between offline simulation metrics and online outcomes, demonstrating that eval-driven development reliably predicts production impact. On most use cases, AI satisfaction reaches within a few percentage points of expert human agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present a unified evaluation-driven framework for building customer support AI agents at scale, incorporating structured context engineering, human-in-the-loop prompt iteration, LLM judge evaluation with inter-rater agreement and GEPA optimization, and ideation-to-production validation. It reports empirical results from five production deployments at Nubank, with the card-delivery deployment showing a 37 percentage-point improvement in AI transactional Net Promoter Score and a 29 percentage-point gain in self-service rate over prior variants via large-scale A/B testing, a strong correlation between offline and online metrics, and AI satisfaction approaching that of expert human agents on most use cases.
Significance. If the reported results hold, the work provides valuable evidence from a 100M-user scale deployment that an integrated evaluation framework can accelerate development and deliver substantial improvements in customer satisfaction metrics for LLM-based agents. The explicit reporting of production A/B test outcomes across five domains and offline-online correlation offers a rare industry-scale benchmark for the field, highlighting the potential for LLM agents to reach near-human performance in customer support tasks. This could inform best practices for bridging offline evaluation to online impact in AI agent development.
major comments (2)
- [Abstract] Abstract: The description of the A/B testing results does not include sample sizes, confidence intervals, p-values, or details on the experimental design (e.g., randomization, duration, exclusion criteria), which are essential to substantiate the claimed 37pp NPS and 29pp self-service gains as load-bearing evidence for the framework's effectiveness.
- [Abstract] Abstract: The claim of a "strong correlation between offline simulation metrics and online outcomes" is not supported by any quantitative statistic (e.g., correlation coefficient, p-value) or description of the simulation metrics and their construction, undermining the assertion that eval-driven development reliably predicts production impact.
minor comments (1)
- [Abstract] Abstract: The term 'GEPA optimization' is introduced without explanation, reference, or expansion of the acronym, which may reduce accessibility for readers.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our work's significance and for the specific feedback on the abstract. We address each major comment below and will incorporate revisions to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The description of the A/B testing results does not include sample sizes, confidence intervals, p-values, or details on the experimental design (e.g., randomization, duration, exclusion criteria), which are essential to substantiate the claimed 37pp NPS and 29pp self-service gains as load-bearing evidence for the framework's effectiveness.
Authors: We agree that the abstract would benefit from additional statistical detail to support the reported gains. In the revised version, we will expand the relevant sentence to include sample sizes, confidence intervals, p-values, and a brief outline of the experimental design (randomization procedure, test duration, and exclusion criteria). These elements are available from our production A/B testing infrastructure and can be reported at a level that preserves necessary confidentiality. revision: yes
-
Referee: [Abstract] Abstract: The claim of a "strong correlation between offline simulation metrics and online outcomes" is not supported by any quantitative statistic (e.g., correlation coefficient, p-value) or description of the simulation metrics and their construction, undermining the assertion that eval-driven development reliably predicts production impact.
Authors: We accept this point. The abstract currently states the correlation qualitatively. We will revise it to report the specific correlation coefficient, its p-value, and a short description of the offline simulation metrics (including how they were constructed from the evaluation pipeline). This change will make the offline-to-online linkage more transparent and directly address the concern. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper is an empirical engineering report on a production framework for customer support agents. Its central claims rest on direct large-scale A/B test outcomes (37 pp NPS gain, 29 pp self-service gain, offline-online correlation) measured in five real deployments at Nubank. These are external production measurements, not quantities derived from fitted parameters, self-defined metrics, or self-citation chains. No equations, uniqueness theorems, or ansatzes appear; the framework components are presented as the process that produced the measured results rather than being justified by internal reduction to the same results. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM judges optimized via GEPA with measured inter-rater agreement serve as reliable proxies for human customer satisfaction
Reference graph
Works this paper leans on
-
[1]
Gepa: Reflective prompt evolution can outperform reinforcement learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning. arXiv preprint arXiv:2507.19457, 2025
Pith/arXiv arXiv 2025
-
[2]
Building effective agents, 2024
Anthropic. Building effective agents, 2024. URL https://www.anthropic.com/ engineering/building-effective-agents. Published Dec 19, 2024. Accessed: 2026- 02-02
2024
-
[3]
Cursor: The ai code editor, 2024
Anysphere, Inc. Cursor: The ai code editor, 2024. URL https://cursor.com. Ac- cessed: 2025-02-05
2024
-
[4]
Negar Arabzadeh and Charles L. A. Clarke. A human-ai comparative analysis of prompt sensitivity in LLM-based relevance judgment, 2025. URL https://arxiv. org/abs/2504.12408. Related DOI: 10.1145/3726302.3730159
-
[5]
Language models are few-shot learners.Advances in neural infor- mation processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural infor- mation processing systems, 33:1877–1901, 2020
1901
-
[6]
Reinforcement learning for long-horizon interactive LLM agents.arXiv preprint arXiv:2502.01600, 2025
Kevin Chen, Marco Cusumano-Towner, Brody Huval, Aleksei Petrenko, Jackson Hamburger, Vladlen Koltun, and Philipp Krähenbühl. Reinforcement learning for long-horizon interactive LLM agents.arXiv preprint arXiv:2502.01600, 2025
arXiv 2025
-
[7]
A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 20(1):37–46, 1960
Jacob Cohen. A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 20(1):37–46, 1960
1960
-
[8]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
Pith/arXiv arXiv 2025
-
[9]
The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[10]
Lutfi Eren Erdogan, Nicholas Lee, Sehoon Kim, Suhong Moon, Hiroki Furuta, Gopala Anumanchipalli, Kurt Keutzer, and Amir Gholami. Plan-and-act: Improv- ing planning of agents for long-horizon tasks.arXiv preprint arXiv:2503.09572, 2025
Pith/arXiv arXiv 2025
-
[11]
Retool: Reinforcement learning for strategic tool use in llms.arXiv preprint arXiv:2504.11536, 2025
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, et al. Retool: Reinforcement learning for strategic tool use in llms.arXiv preprint arXiv:2504.11536, 2025
Pith/arXiv arXiv 2025
-
[12]
Schema-guided user satisfaction modeling for task-oriented dialogues
Yue Feng, Yunlong Jiao, Animesh Prasad, Nikolaos Aletras, Emine Yilmaz, and Gabriella Kazai. Schema-guided user satisfaction modeling for task-oriented dialogues. InProceedings of the 61st Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 2079–2091, Toronto, Canada,
2079
-
[13]
Association for Computational Linguistics
-
[14]
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rocktäschel. Promptbreeder: Self-referential self-improvement via prompt evolution.arXiv preprint arXiv:2309.16797, 2023
Pith/arXiv arXiv 2023
-
[15]
Joseph L. Fleiss. Measuring nominal scale agreement among many raters.Psy- chological Bulletin, 76(5):378–382, 1971
1971
-
[16]
Asbjørn Følstad, Effie L.-C. Law, and Nena van As. Conversational breakdown in a customer service chatbot: Impact of task order and criticality on user trust and emotion.ACM Transactions on Computer-Human Interaction, 31(5), 2024. doi: 10.1145/3690383
-
[17]
Google antigravity: Experience liftoff with the next-generation ide, 2025
Google. Google antigravity: Experience liftoff with the next-generation ide, 2025. URL https://antigravity.google/
2025
-
[18]
NatCS: Eliciting natural customer support dialogues
James Gung, Emily Moeng, Wesley Rose, Arshit Gupta, Yi Zhang, and Saab Mansour. NatCS: Eliciting natural customer support dialogues. InFindings of the Association for Computational Linguistics: ACL 2023, pages 9652–9677, Toronto, Canada, 2023. Association for Computational Linguistics
2023
-
[19]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[20]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b.arXiv e-prints, 2023....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06825 2023
-
[21]
Arik, Dong Wang, Hamed Zamani, and Jiawei Han
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O. Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
Pith/arXiv arXiv 2025
-
[22]
Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan A, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. DSPy: Compiling declarative language model calls into state-of- the-art pipelines. InInternational Conference on Learning Representations (ICL...
2024
-
[23]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. InAdvances in Neural Information Processing Systems 35 (NeurIPS 2022), pages 22199–22213, 2022
2022
-
[24]
Reliability in content analysis: Some common misconceptions and recommendations.Human Communication Research, 30(3):411–433, 2004
Klaus Krippendorff. Reliability in content analysis: Some common misconceptions and recommendations.Human Communication Research, 30(3):411–433, 2004
2004
-
[25]
Measuring ai ability to complete long tasks.arXiv preprint arXiv:2503.14499, 2025
Thomas Kwa, Ben West, Joel Becker, Amy Deng, Katharyn Garcia, Max Hasin, Sami Jawhar, Megan Kinniment, Nate Rush, Sydney Von Arx, et al. Measuring ai ability to complete long tasks.arXiv preprint arXiv:2503.14499, 2025
arXiv 2025
-
[26]
From generation to judgment: Opportunities and challenges of LLM-as-a-judge
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, Kai Shu, Lu Cheng, and Huan Liu. From generation to judgment: Opportunities and challenges of LLM-as-a-judge. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2757–2...
2025
-
[27]
A technique for the measurement of attitudes.Archives of Psychol- ogy, 22(140):1–55, 1932
Rensis Likert. A technique for the measurement of attitudes.Archives of Psychol- ogy, 22(140):1–55, 1932
1932
-
[28]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics. URL https://aclanthology.org/W04- 1013/
2004
-
[29]
How NOT to evaluate your dialogue system: An empirical study of unsupervised evaluation metrics for dialogue response generation
Chia-Wei Liu, Ryan Lowe, Iulian Serban, Mike Noseworthy, Laurent Charlin, and Joelle Pineau. How NOT to evaluate your dialogue system: An empirical study of unsupervised evaluation metrics for dialogue response generation. In Jian Su, Kevin Duh, and Xavier Carreras, editors,Proceedings of the 2016 Conference on Empirical Methods in Natural Language Proces...
2016
-
[30]
Farinha, Helena Moniz, Alon Lavie, and Isabel Trancoso
John Mendonça, Patrícia Pereira, Miguel Menezes, Vera Cabarrão, Ana C. Farinha, Helena Moniz, Alon Lavie, and Isabel Trancoso. Dialogue quality and emotion annotations for customer support conversations. InProceedings of the 3rd Work- shop on Natural Language Generation, Evaluation, and Metrics (GEM), pages 9–21, Singapore, 2023. Association for Computati...
2023
-
[31]
Evaluation and benchmarking of llm agents: A survey
Mahmoud Mohammadi, Yipeng Li, Jane Lo, and Wendy Yip. Evaluation and benchmarking of llm agents: A survey. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Toronto, Canada, 2025. ACM
2025
-
[32]
Bhaskar, Bencheng Wei, Iris Ren, Waqar Muhammad, Erin Li, Bukola Ishola, Michael Wang, Griffin Tanner, Yu-Jia Shiah, Sean X
Stephen Obadinma, Faiza Khan Khattak, Shirley Wang, Tania Sidhom, Elaine Lau, Sean Robertson, Jingcheng Niu, Winnie Au, Alif Munim, Karthik Raja K. Bhaskar, Bencheng Wei, Iris Ren, Waqar Muhammad, Erin Li, Bukola Ishola, Michael Wang, Griffin Tanner, Yu-Jia Shiah, Sean X. Zhang, Kwesi P. Apponsah, Kanishk Patel, Jaswinder Narain, Deval Pandya, Xiaodan Zhu...
2022
-
[33]
Introducing deep research, February 2025
OpenAI. Introducing deep research, February 2025. URL https://openai.com/ index/introducing-deep-research/. Accessed: 2025-02-05
2025
-
[34]
Arjun Panickssery, Samuel R. Bowman, and Shi Feng. LLM evaluators recognize and favor their own generations. InAdvances in Neural Information Processing Systems, volume 37, 2024. doi: 10.52202/079017-2197. URL https://papers.nips. cc/paper_files/paper/2024/hash/7f1f0218e45f5414c79c0679633e47bc-Abstract- Conference.html
-
[35]
BLEU : a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Pierre Isabelle, Eugene Charniak, and Dekang Lin, editors,Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA, July 2002. Association for Computa...
-
[36]
Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng. Automatic prompt optimization with" gradient descent" and beam search.arXiv preprint arXiv:2305.03495, 2023
arXiv 2023
-
[37]
Dis- tinguish sense from nonsense: Out-of-scope detection for virtual assistants
Cheng Qian, Haode Qi, Gengyu Wang, Ladislav Kunc, and Saloni Potdar. Dis- tinguish sense from nonsense: Out-of-scope detection for virtual assistants. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 502–511, Abu Dhabi, UAE, 2022. Association for Computational Linguistics
2022
-
[38]
Reichheld
Frederick F. Reichheld. The one number you need to grow.Harvard Business Review, 81(12):46–54, 2003
2003
-
[39]
Generative ai in customer support services: A framework for augmenting the routines of frontline service employees
Philipp Reinhard, Mahei Manhai Li, Christoph Peters, and Jan Marco Leimeister. Generative ai in customer support services: A framework for augmenting the routines of frontline service employees. InProceedings of the 57th Hawaii In- ternational Conference on System Sciences (HICSS), pages 468–477. ScholarSpace, 2024
2024
-
[40]
Hanchen Su, Wei Luo, Yashar Mehdad, Wei Han, Elaine Liu, Wayne Zhang, Mia Zhao, and Joy Zhang. LLM-friendly knowledge representation for customer Building Customer Support AI Agents at 100M-User Scale: An Evaluation-Driven Framework KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea support. InProceedings of the 31st International Conference on C...
2026
-
[41]
Langgraph: A library for orchestrating multi-agent systems,
LangChain Team. Langgraph: A library for orchestrating multi-agent systems,
-
[42]
Accessed: 2026-02-06
URL https://github.com/langchain-ai/langgraph. Accessed: 2026-02-06
2026
-
[43]
Replacing judges with juries: Evaluating LLM generations with a panel of diverse models, April 2024
Pat Verga, Sebastian Hofstätter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. Replacing judges with juries: Evaluating LLM generations with a panel of diverse models, April 2024. URL https://arxiv.org/abs/2404.18796
Pith/arXiv arXiv 2024
-
[44]
Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems 35 (NeurIPS 2022), pages 24824–24837, 2022
2022
-
[45]
An empirical study of LLM-as-a-judge: How design choices impact evaluation reliability, 2025
Yusuke Yamauchi, Taro Yano, and Masafumi Oyamada. An empirical study of LLM-as-a-judge: How design choices impact evaluation reliability, 2025. URL https://arxiv.org/abs/2506.13639
arXiv 2025
-
[46]
Large language models as optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. InThe Twelfth Interna- tional Conference on Learning Representations, 2023
2023
-
[47]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR), 2023
2023
-
[48]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-Judge with MT-bench and Chatbot Arena. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[49]
Large language models are human-level prompt engineers
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers. InThe eleventh international conference on learning representations, 2022
2022
-
[50]
Starter Prompt
Jie Zhu, Huaixia Dou, Junhui Li, Lifan Guo, Feng Chen, Chi Zhang, and Fang Kong. Evaluating, synthesizing, and enhancing for customer support conversation. In Proceedings of the AAAI Conference on Artificial Intelligence, 2026. To appear. A Evaluator Prompt Evolution This appendix presents a before-and-after comparison of an evalu- ator prompt from the ca...
2026
-
[51]
the address itself (street, city, zip, etc.) AND
-
[52]
score": 0,
at least one extra detail (e.g., apartment number, suite, floor, building name, landmark, delivery instructions), then return: {"score": 0, "analysis": "<why it passed>"}. - Otherwise return: {"score": 1, "analysis": "<why it failed>"}. RULES ----- - Base your decision on the *entire* conversation. - Respond with valid JSON only, no additional text. Outpu...
2026
-
[53]
score": 0,
Does the user need to reissue their card? Triggers: lost/ stolen/damaged/expired/ not-received with a request for a new card; explicit reissue/ second-copy request; or assistant proposes reissue and the flow proceeds on that basis. - If NO -> {"score": 0, "analysis": "Input gathering not required because card reissuance was not needed."}
-
[54]
score": 0,
If reissue is needed: is a physical card actually being sent ( delivery involved)? - If NO -> {"score": 0, "analysis": "No card delivery involved ..."}
-
[55]
score": 0,
If reissue with delivery: will the card go to the same address on file? - If user explicitly confirms same address -> {"score": 0, " analysis": "Address confirmation is sufficient..."}
-
[56]
full/complete address
Otherwise (new/changed address needed): evaluate whether the ASSISTANT handled address gathering correctly. - PASS (0): assistant explicitly requested all core fields ( incl. ZIP and number) AND >=1 extra detail; OR user provided all core fields AND >=1 extra detail. - FAIL (1): vague "full/complete address" without enumerating core fields; OR no extra de...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.