Fourier Neural Operators with rank-1 lattice points and hyperbolic cross
Pith reviewed 2026-06-27 17:39 UTC · model grok-4.3
The pith
Replacing tensor grids with rank-1 lattices improves FNO generalization error bounds for spatial and parametric variables.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
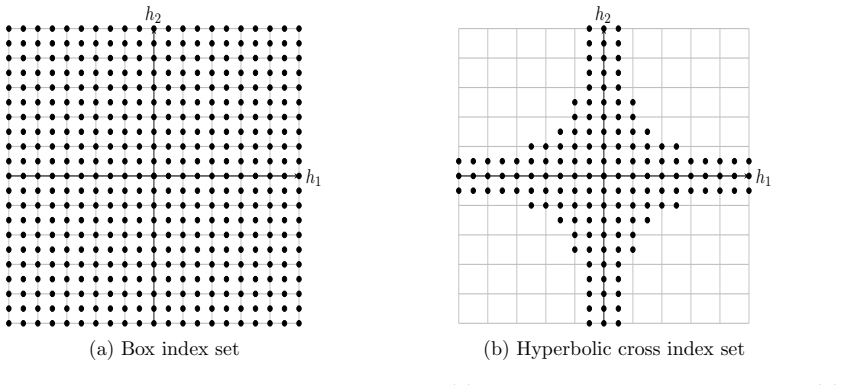
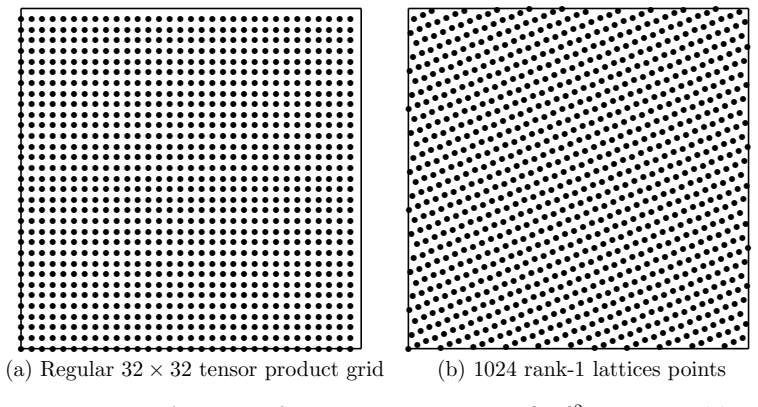
By deriving general regularity bounds for the FNO with respect to both the spatial and parametric variables, the generalization error of the FNO can be improved by replacing spatial tensor product grids with purpose-built rank-1 lattice points, and by using a second lattice carefully constructed as training points in the parametric space. This yields more accurate and efficient approximations from fewer network parameters, fewer spatial points, and fewer training samples. The architecture simplifies because the high-dimensional Fourier transform on rank-1 lattices requires only a one-dimensional fast Fourier transform, and a hyperbolic cross frequency index set can be used with lattice point
What carries the argument
Rank-1 lattice points in spatial discretization together with a second lattice for parametric training points, which support a hyperbolic cross frequency index set and reduce the Fourier transform to one dimension.
If this is right
- Fewer network parameters suffice for a given accuracy level.
- Fewer spatial discretization points are needed while maintaining the error bound.
- Fewer training samples in the parametric domain achieve the target generalization error.
- The implementation reduces to a one-dimensional FFT instead of a multi-dimensional transform.
Where Pith is reading between the lines
- The same lattice construction may extend the error improvement to other PDE types beyond the elliptic case on the torus.
- Hyperbolic cross truncation could be tested for further reduction in the number of retained Fourier modes.
- The approach may scale to higher-dimensional parameter spaces where tensor grids become prohibitive.
Load-bearing premise
The derived regularity bounds for the FNO continue to hold after the spatial discretization is switched from tensor grids to rank-1 lattices and after the parametric training points are chosen according to the second lattice construction.
What would settle it
A numerical experiment on the elliptic PDE on the torus in which the measured generalization error with rank-1 lattices and the second lattice exceeds the error obtained with standard tensor grids and uniform parametric sampling.
Figures
read the original abstract
The \emph{Fourier neural operator} (FNO) is a neural network architecture that learns mappings between function spaces. Its efficient implementation is based on the multi-dimensional Fourier transform. By deriving general regularity bounds for the FNO with respect to both the spatial and parametric variables, we prove that the generalization error of the FNO can be improved by replacing spatial tensor product grids with purpose-built rank-1 lattice points, and by using a second lattice carefully constructed as training points in the parametric space. We achieve more accurate and efficient approximations from fewer network parameters, fewer spatial points, and fewer training samples. In addition, the architecture is simplified, because the high-dimensional Fourier transform on rank-1 lattices requires only a \emph{one-dimensional fast Fourier transform}, and we can use a \emph{hyperbolic cross} frequency index set with lattice points. We demonstrate the benefits of our \emph{lattice-based hyperbolic-cross FNOs} for an elliptic PDE on the torus.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that deriving general regularity bounds for the Fourier neural operator (FNO) with respect to both spatial and parametric variables proves that generalization error improves when spatial tensor-product grids are replaced by purpose-built rank-1 lattice points and a second carefully constructed lattice is used for parametric training points. This yields more accurate and efficient approximations from fewer network parameters, fewer spatial points, and fewer training samples. The architecture is simplified because the high-dimensional Fourier transform on rank-1 lattices requires only a one-dimensional FFT together with a hyperbolic-cross frequency index set. The benefits are demonstrated for an elliptic PDE on the torus.
Significance. If the regularity bounds are shown to hold after the change in discretization, the approach could reduce the computational cost of FNO training and inference for high-dimensional parametric PDE problems while preserving approximation quality, by exploiting the efficiency of 1D FFTs and hyperbolic crosses.
major comments (2)
- [Derivation of regularity bounds (abstract and main proof sections)] The load-bearing step is whether the derived regularity bounds (w.r.t. spatial and parametric variables) remain valid after the spatial discretization is changed from tensor grids to rank-1 lattices. The proof must explicitly adapt the Fourier analysis (aliasing, quadrature accuracy, Sobolev constants) to the properties of rank-1 lattices and the hyperbolic-cross index set rather than relying on tensor-grid separability or uniform-grid orthogonality; if any step invokes product-structure assumptions that no longer hold, the claimed generalization-error improvement does not follow.
- [Parametric training points construction] The parametric-space lattice construction and its interaction with the spatial lattice must be shown to preserve the stated bounds; the abstract asserts a second lattice is 'carefully constructed,' but the explicit dependence of the error constants on this choice needs to be derived rather than asserted.
minor comments (2)
- [Numerical experiments] The elliptic PDE demonstration should report quantitative error metrics with standard deviations over multiple random seeds or initializations to support the efficiency and accuracy claims.
- [Preliminaries] Notation for the rank-1 lattice generating vector and the hyperbolic-cross index set should be introduced with explicit definitions before their use in the bounds.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. The points raised concern the explicit adaptation of the regularity bounds and error analysis to rank-1 lattices; we respond to each below and will revise the manuscript to address them.
read point-by-point responses
-
Referee: [Derivation of regularity bounds (abstract and main proof sections)] The load-bearing step is whether the derived regularity bounds (w.r.t. spatial and parametric variables) remain valid after the spatial discretization is changed from tensor grids to rank-1 lattices. The proof must explicitly adapt the Fourier analysis (aliasing, quadrature accuracy, Sobolev constants) to the properties of rank-1 lattices and the hyperbolic-cross index set rather than relying on tensor-grid separability or uniform-grid orthogonality; if any step invokes product-structure assumptions that no longer hold, the claimed generalization-error improvement does not follow.
Authors: We agree that the adaptation of the Fourier analysis to rank-1 lattices must be made fully explicit. In the revised manuscript we will expand the relevant proof sections to derive the aliasing error bounds, quadrature accuracy estimates, and adjusted Sobolev embedding constants directly from the discrepancy and generating-vector properties of rank-1 lattices. The hyperbolic-cross frequency index set will be shown to preserve the necessary orthogonality relations without invoking tensor-product separability. These additions will confirm that the regularity bounds remain valid and that the stated generalization-error improvement follows. revision: yes
-
Referee: [Parametric training points construction] The parametric-space lattice construction and its interaction with the spatial lattice must be shown to preserve the stated bounds; the abstract asserts a second lattice is 'carefully constructed,' but the explicit dependence of the error constants on this choice needs to be derived rather than asserted.
Authors: We acknowledge that the dependence of the error constants on the parametric lattice choice requires explicit derivation. In the revision we will add a dedicated subsection deriving the interaction between the spatial rank-1 lattice and the parametric lattice, including the precise criteria used for the parametric construction and the resulting bounds on the combined error constants. This will replace the current assertion with a complete derivation showing preservation of the regularity bounds. revision: yes
Circularity Check
Derivation of general regularity bounds is self-contained with no reduction to fitted inputs or self-citations
full rationale
The paper states it derives general regularity bounds for the FNO w.r.t. spatial and parametric variables, then uses those bounds to prove generalization error improvement from rank-1 lattices and hyperbolic crosses. The abstract presents the bounds as independently derived rather than fitted or defined in terms of the target result. No equations, self-citations, or ansatzes are shown that reduce the central claim to its inputs by construction. The load-bearing step (bounds holding after discretization change) is asserted as a derivation, not a renaming or self-referential fit. This is the normal case of a self-contained theoretical claim.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Adcock, S
B. Adcock, S. Brugiapaglia, and C. G. Webster. Sparse Polynomial Approximation of High-Dimensional Functions . Society for Industrial and Applied Mathematics, Philadelphia, PA, 2022
2022
-
[2]
Adcock, S
B. Adcock, S. Brugiapaglia, N. Dexter, and S. Moraga. Chapter 1 - learning smooth functions in high dimensions: From sparse polynomials to deep neural networks. In S. Mishra and A. Townsend, editors, Numerical Analysis Meets Machine Learning, volume 25 of Handbook of Numerical Analysis, pages 1--52. Elsevier, 2024
2024
-
[3]
Bhattacharya, B
K. Bhattacharya, B. Hosseini, N. B. Kovachki, and A. M. Stuart. Model reduction and neural networks for parametric PDEs . The SIAM Journal of computational mathematics, 7: 0 121--157, 2021
2021
-
[4]
Bonev, T
B. Bonev, T. Kurth, C. Hundt, J. Pathak, M. Baust, K. Kashinath, and A. Anandkumar. Spherical F ourier neural operators: Learning stable dynamics on the sphere. Proceedings of the 40th International Conference on Machine Learning, 202: 0 2806--2823, 2023
2023
-
[5]
B. Bonev, T. Kurth, A. Mahesh, M. Bisson, J. Kossaifi, K. Kashinath, A. Anandkumar, W. D. Collins, M. S. Pritchard, and A. Keller. Four C ast N et 3: A geometric approach to probabilistic machine-learning weather forecasting at scale, 2025. URL https://arxiv.org/abs/2507.12144
-
[6]
Q. Cao, S. Goswami, and G. E. Karniadakis. Laplace neural operator for solving differential equations. Nature Machine Intelligence, 6 0 (6): 0 631--640, 2024
2024
-
[7]
Cohen, R
A. Cohen, R. DeVore, and C. Schwab. Convergence rates of best N -term Galerkin approximations for a class of elliptic SPDE s. Foundations of Computational Mathematics, 10: 0 615--646, 2010
2010
-
[8]
Cools, F
R. Cools, F. Y. Kuo, and D. Nuyens. Constructing embedded lattice rules for multivariate integration. SIAM Journal on Scientific Computing, 28 0 (6): 0 2162--2188, 2006
2006
-
[9]
Cools, F
R. Cools, F. Y. Kuo, and D. Nuyens. Constructing lattice rules based on weighted degree of exactness and worst case error. Computing, 87 0 (1): 0 63--89, 2010
2010
-
[10]
Cools, F
R. Cools, F. Y. Kuo, D. Nuyens, and I. H. Sloan. Lattice algorithms for multivariate approximation in periodic spaces with general weight parameters. In S. C. Brenner, I. Shparlinski, C.-W. Shu, and D. Szyld, editors, 75 Years of Mathematics of Computation, volume 754 of Contemporary Mathematics, pages 93--113. American Mathematical Society, 2020
2020
-
[11]
Cools, F
R. Cools, F. Y. Kuo, D. Nuyens, and I. H. Sloan. Fast component-by-component construction of lattice algorithms for multivariate approximation with POD and SPOD weights. Mathematics of Computation, 90: 0 787--812, 2021
2021
-
[12]
G. Cybenko. Approximation by superpositions of a sigmoidal function. Mathematics of Control, Signals and Systems, 2: 0 303--314, 1989
1989
-
[13]
J. Dick, F. Y. Kuo, and I. H. Sloan. High-dimensional integration: The quasi- Monte Carlo way. Acta Numerica, 22: 0 133--288, 2013
2013
-
[14]
J. Dick, P. Kritzer, and F. Pillichshammer. Lattice Rules: Numerical Integration, Approximation, and Discrepancy, volume 58 of Springer Series in Computational Mathematics. Springer Cham, 2022
2022
-
[15]
Dilen, F
J. Dilen, F. Y. Kuo, and D. Nuyens. On universal approximation for lattice-based hyperbolic-cross F ourier neural operators, in preparation, 2026
2026
-
[16]
A. D. Gilbert, F. Y. Kuo, and A. Srikumar. Density estimation for elliptic PDE with random input by preintegration and quasi- M onte C arlo methods. SIAM Journal on Numerical Analysis, 63 0 (2): 0 1025--1054, 2025
2025
- [17]
-
[18]
I. G. Graham, F. Y. Kuo, D. Nuyens, I. H. Sloan, and E. A. Spence. Quasi- M onte C arlo methods for uncertainty quantification of wave propagation and scattering problems modelled by the H elmholtz equation. IMA Journal of Numerical Analysis, 2026. doi:10.1093/imanum/draf101. Advance article available online
-
[19]
R. L. Graham, D. E. Knuth, and P. Oren. Concrete Mathematics. Addison-Wesley, 1994
1994
-
[20]
Guibas, M
J. Guibas, M. Mardani, Z. Li, A. Tao, A. Anandkumar, and B. Catanzaro. Efficient token mixing for transformers via adaptive F ourier neural operators. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=EXHG-A3jlM
2022
-
[21]
P. A. Guth, V. Kaarnioja, F. Y. Kuo, C. Schillings, and I. H. Sloan. Parabolic PDE -constrained optimal control under uncertainty with entropic risk measure using quasi- Monte Carlo integration. Numerische Mathematik, 156: 0 565--608, 2024
2024
-
[22]
Hakula, H
H. Hakula, H. Harbrecht, V. Kaarnioja, F. Y. Kuo, and I. H. Sloan. Uncertainty quantification for random domains using periodic random variables. Numerische Mathematik, 156: 0 273--317, 2024
2024
-
[23]
Hardt and B
M. Hardt and B. Recht. Patterns, predictions, and actions: Foundations of machine learning. Princeton University Press, 2022
2022
-
[24]
Herrmann, C
L. Herrmann, C. Schwab, and J. Zech. Neural network expression rates for solvers of parametric O rdinary D ifferential E quations. Advances in Computational Mathematics, 50 0 (5): 0 91, 2024
2024
-
[25]
K. Hornik. Approximation capabilities of multilayer feedforward networks. Neural Networks, 4 0 (2): 0 251--257, 1991
1991
-
[26]
Hornik, M
K. Hornik, M. Stinchcombe, and H. White. Multilayer feedworward networks are universal approximators. Neural Networks, 2, 1989
1989
-
[27]
P. Jin, S. Meng, and L. Lu. Mionet: Learning multiple-input operators via tensor product. SIAM Journal on Scientific Computing, 44 0 (6): 0 A3490--A3514, 2022
2022
-
[28]
Kaarnioja, F
V. Kaarnioja, F. Y. Kuo, and I. H. Sloan. Uncertainty quantification using periodic random variables. SIAM Journal on Numerical Analysis, 58 0 (2): 0 1068--1091, 2020
2020
-
[29]
Kaarnioja, Y
V. Kaarnioja, Y. Kazashi, F. Y. Kuo, F. Nobile, and I. H. Sloan. Fast approximation by periodic kernel-based lattice-point interpolation with application in uncertainty quantification. Numerische Mathematik, 150: 0 33--77, 2022
2022
-
[30]
Kaarnioja, F
V. Kaarnioja, F. Y. Kuo, and I. H. Sloan. Lattice-based kernel approximation and serendipitous weights for parametric PDE s in very high dimensions. In A. Hinrichs, P. Kritzer, and F. Pillichshammer, editors, M onte C arlo and Q uasi- M onte C arlo Methods 2022 , pages 81--103. Springer-Verlag, 2024
2022
-
[31]
K \"a mmerer, D
L. K \"a mmerer, D. Potts, and T. Volkmer. Approximation of multivariate periodic functions by trigonometric polynomials based on rank-1 lattice sampling. Journal of Complexity, 31 0 (4): 0 543--576, 2015
2015
-
[32]
K \"a mmerer, D
L. K \"a mmerer, D. Potts, and T. Volkmer. High-dimensional sparse FFT based on sampling along multiple rank- 1 lattices. Applied and Computational Harmonic Analysis, 51: 0 225--257, 2021
2021
-
[33]
Keiner, S
J. Keiner, S. Kunis, and D. Potts. Using NFFT 3: A software library for various nonequispaced fast fourier transforms. ACM transactions on mathematical software, 36 0 (4): 0 46--75, 2010
2010
- [34]
-
[35]
Keller, F
A. Keller, F. Y. Kuo, D. Nuyens, and I. H. Sloan. Lattice-based deep neural networks: regularity and tailored regularization. In Lemieux and B. Feng, editors, M onte C arlo and Q uasi- M onte C arlo Methods 2024, to appear . Springer-Verlag, 2026 b
2024
-
[36]
Y. Khoo, J. Lu, and L. Ying. Solving parametric PDE problems with artificial neural networks. European Journal of Applied Mathematics, 32 0 (3): 0 421--435, 2021
2021
-
[37]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. In proceedings of the 3rd international conference on learning representations. ICLR, 2015
2015
-
[38]
arXiv preprint arXiv:2412.10354 , year =
J. Kossaifi, N. Kovachki, Z. Li, D. Pitt, M. Liu-Schiaffini, R. J. George, B. Bonev, K. Azizzadenesheli, J. Berner, V. Duruisseaux, and A. Anandkumar. A library for learning neural operators, 2026. URL https://arxiv.org/abs/2412.10354
-
[39]
Kovachki, S
N. Kovachki, S. Lanthaler, and S. Mishra. On universal approximation and error bounds for fourier neural operators. Machine Learning Research, 22: 0 1--76, 2021
2021
-
[40]
Kovachki, Z
N. Kovachki, Z. Li, B. Liu, K. Azizzadenesheli, K. Bhattacharya, A. Stuart, and A. Anandkumar. Neural operator: learning maps between function spaces with applications to PDE s. Journal of Machine Learning Research, 24: 0 4061--4157, 2023
2023
-
[41]
F. Y. Kuo and D. Nuyens. Application of quasi- Monte Carlo methods to elliptic PDE s with random diffusion coefficients: A survey of analysis and implementation. Foundations of Computational Mathematics, 16: 0 1631--1696, 2016
2016
-
[42]
F. Y. Kuo, G. Migliorati, F. Nobile, and D. Nuyens. Function integration, reconstruction and approximation using rank-1 lattices. Mathematics of Computation, 90 0 (330): 0 1861--1897, 2021
2021
-
[43]
F. Y. Kuo, W. Mo, and D. Nuyens. Constructing embedded lattice-based algorithms for multivariate function approximation with a composite number of points. Constructive Approximation, 61 0 (1): 0 81--113, 2025
2025
-
[44]
Lanthaler
S. Lanthaler. Operator learning with PCA-Net : upper and lower complexity bounds. Journal of Machine Learning Research, 24 0 (318): 0 1--67, 2023
2023
-
[45]
Lanthaler, Z
S. Lanthaler, Z. Li, and A. M. Stuart. Nonlocality and nonlinearity implies universality in operator learning. Constructive Approximation, 62: 0 261--303, 2025 a
2025
-
[46]
S. Lanthaler, A. M. Stuart, and M. Trautner. Discretization error of F ourier neural operators, 2025 b . URL https://arxiv.org/abs/2405.02221
-
[47]
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, and A. Anandkumar. Neural operator: Graph kernel network for partial differential equations, 2020 a . URL https://arxiv.org/abs/2003.03485
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[48]
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, and A. Anandkumar. Multipole graph neural operator for parametric partial differential equations. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NeurIPS '20, Red Hook, NY, USA, 2020 b . Curran Associates Inc
2020
-
[49]
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, and A. Anandkumar. Fourier neural operator for parametric partial differential equations. ICLR, 2021
2021
-
[50]
Y. Liu, T. Mao, and D.-X. Zhou. Approximation of functions from korobov spaces by shallow neural networks. Information Sciences, 2024
2024
-
[51]
Longo, S
M. Longo, S. Mishra, T. K. Rusch, and C. Schwab. Higher-order quasi- Monte Carlo training of deep neural networks. SIAM Journal on Scientific Computing, 43: 0 A3938--A3966, 2021
2021
-
[52]
L. Lu, P. Jin, G. Pang, Z. Zhang, and G. E. Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nature Machine Intelligence, 3: 0 218 -- 229, 2021
2021
-
[53]
K. O. Lye, S. Mishra, and D. Ray. Deep learning observables in computational fluid dynamics. Journal of Computational Physics, 410: 0 109339, 2020
2020
-
[54]
Mishra and T
S. Mishra and T. K. Rusch. Enhancing accuracy of deep learning algorithms by training with low-discrepancy sequences. SIAM Journal on Numerical Analysis, 59: 0 1811--1834, 2021
2021
-
[55]
Niederreiter
H. Niederreiter. Random Number Generation and Quasi-Monte Carlo Methods. CBMS-NSF Regional Conference Series in Applied Mathematics. Society for Industrial and Applied Mathematics, Philadelphia, PA, 1992
1992
-
[56]
Novak, H
L. Novak, H. Sharma, and M. D. Shields. Physics-informed polynomial chaos expansions. Journal of Computational Physics, 506: 0 112926, 2024
2024
-
[57]
Nuyens and R
D. Nuyens and R. Cools. Fast algorithms for component-by-component construction of rank-1 lattice rules in shift-invariant reprodicing kernel Hilbert spaces. Mathematics of Computation, 75 0 (254), 2006
2006
-
[58]
O'Leary-Roseberry, P
T. O'Leary-Roseberry, P. Chen, U. Villa, and O. Ghattas. Derivative-informed neural operator: An efficient framework for high-dimensional parametric derivative learning. Journal of Computational Physics, 496: 0 112555, 2024
2024
-
[59]
Pestourie, Y
R. Pestourie, Y. Mroueh, C. Rackauckas, P. Das, and S. G. Johnson. Physics-enhanced deep surrogates for partial differential equations. Nature Machine Intelligence, 5 0 (12), 2023
2023
-
[60]
Raissi, P
M. Raissi, P. Perdikaris, and G. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378: 0 686--707, 2019
2019
-
[61]
T. H. Savits. Some statistical applications of Faa di Bruno . Journal of Multivariate Analysis, 97 0 (10): 0 2131--2140, 2006
2006
-
[62]
Schwab and J
C. Schwab and J. Zech. Deep learning in high dimension: Neural network expression rates for generalized polynomial chaos expansions in UQ . Analysis and Applications, 17 0 (01): 0 19--55, 2019
2019
-
[63]
Schwab and J
C. Schwab and J. Zech. Deep learning in high dimension: Neural network expression rates for analytic functions in L^2( R ^d, _d) . SIAM/ASA Journal on Uncertainty Quantification, 11 0 (1): 0 199--234, 2023
2023
-
[64]
Shahane, N
S. Shahane, N. R. Aluru, and S. Pratap Vanka. Uncertainty quantification in three dimensional natural convection using polynomial chaos expansion and deep neural networks. International Journal of Heat and Mass Transfer, 139: 0 613--631, 2019
2019
-
[65]
I. H. Sloan and S. Joe. Lattice rules for multiple integration. Oxford University Press, 1994
1994
-
[66]
Voigtlaender
F. Voigtlaender. The universal approximation theorem for complex-valued neural networks. Applied and Computational Harmonic Analysis, 64: 0 33--61, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.