FAME: Forecastability-Aware Mixture of Experts for Heterogeneous Time Series Forecasting
Pith reviewed 2026-06-27 17:13 UTC · model grok-4.3
The pith
A sparse mixture-of-experts router uses data fingerprints to pick suitable forecasting models per series and lowers error on heterogeneous retail and industrial data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
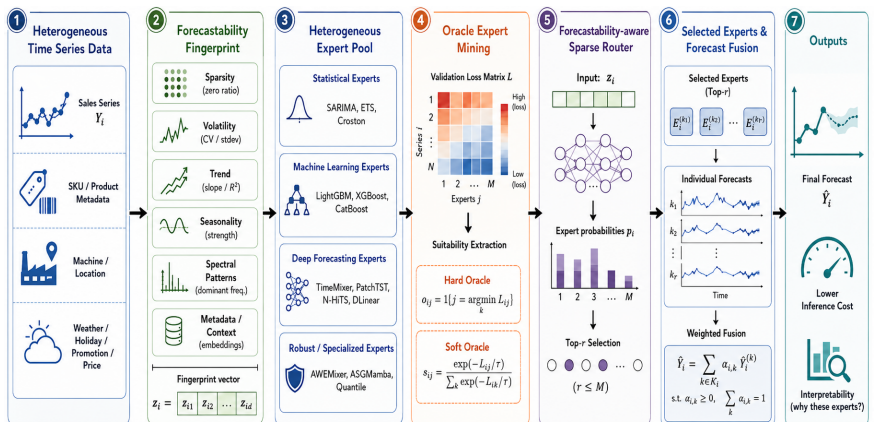
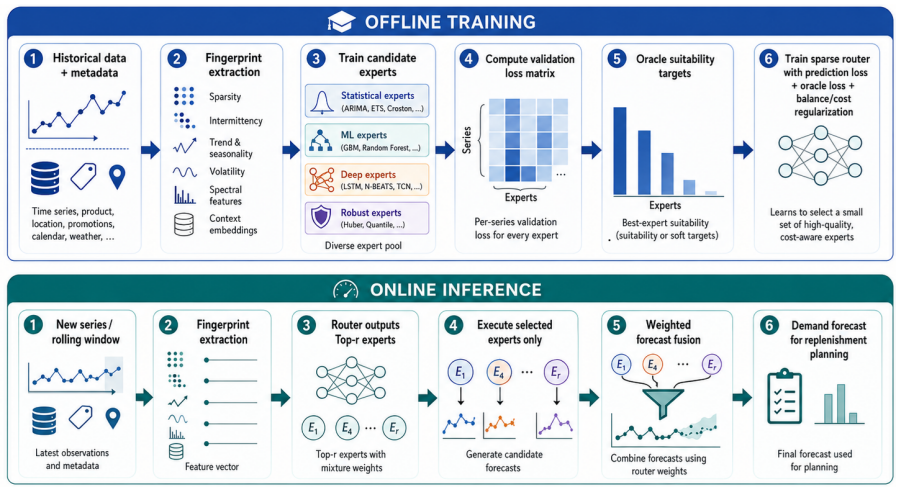
FAME builds a multidimensional forecastability fingerprint for each series from characteristics including lifecycle, sparsity, volatility, seasonality, spectral patterns and contextual sensitivity. It mines expert-suitability targets directly from validation performance of candidate models and trains a cost-aware sparse router that activates only a small budgeted set of experts for each series. On the production vending-machine sales dataset the router produces lower error than any single expert while keeping average activation near two experts per series, and the same pattern holds on public retail benchmarks.
What carries the argument
The cost-aware sparse router that receives a forecastability fingerprint as input and outputs a small set of experts whose suitability was learned from validation targets.
If this is right
- Expert suitability varies systematically with measurable data characteristics rather than randomly across series.
- Sparse activation delivers accuracy gains at inference cost close to that of a single model.
- The same routing logic transfers from the industrial vending-machine setting to public retail benchmarks.
- Demand forecasts produced by the router integrate directly into an existing replenishment pipeline under a fixed policy.
Where Pith is reading between the lines
- The mined suitability targets could be inspected to discover which specific data traits most strongly favor one expert over another.
- If the fingerprint generalizes, the trained router could be applied to time series from other domains without collecting new suitability labels.
- Adding an online update step to the router might allow it to adapt when sales patterns shift over time.
Load-bearing premise
That suitability labels mined from validation performance on observed series will correctly predict which experts work best on new series and will stay valid under the fixed replenishment policy.
What would settle it
A new collection of series on which the router-selected experts produce higher error than the single best model or require activating substantially more than the budgeted number of experts to match its accuracy.
Figures
read the original abstract
Large-scale retail and industrial forecasting systems contain many heterogeneous time series whose lifecycle, sparsity, volatility, seasonality, spectral patterns, and contextual sensitivity differ substantially. A single forecasting model rarely performs well across all regimes, while dense ensembles increase inference cost and provide limited insight into expert suitability. This paper studies forecastability-aware expert routing: learning how data characteristics determine the suitability of forecasting experts. We propose \method{}, a sparse mixture-of-experts framework that represents each series with a multidimensional forecastability fingerprint, mines expert-suitability targets from validation performance, and trains a cost-aware sparse router to activate a small budgeted set of experts for each series. Using a production-scale vending-machine sales dataset from Shandong New Beiyang (SNBC), where the forecasting component has been integrated into the replenishment-planning pipeline, together with public retail benchmarks, we show that expert suitability varies systematically across data regimes. On the industrial dataset with 5,000+ machines and 60M+ transactions, \method{} Top-2 reduces MSE by 12.4\% over the strongest single expert, LightGBM, while executing 1.92 experts per series on average. The deployed component produces demand forecasts, while inventory-oriented gains are estimated by an offline replay simulator under a fixed replenishment policy rather than by online intervention. The framework turns heterogeneous sales forecasting from heuristic model selection into data mining of forecastability patterns and expert specialization. Code is available at https://github.com/hit636/FAME
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FAME, a sparse mixture-of-experts framework for heterogeneous time series forecasting. Each series is represented by a multidimensional forecastability fingerprint; expert-suitability targets are mined from validation performance; and a cost-aware sparse router is trained to activate a budgeted number of experts per series. On a production vending-machine sales dataset (5,000+ machines, 60M+ transactions), FAME Top-2 reports a 12.4% MSE reduction relative to the strongest single expert (LightGBM) while executing 1.92 experts per series on average. The method is also evaluated on public retail benchmarks and integrated into a replenishment-planning pipeline under a fixed policy.
Significance. If the empirical claims hold under rigorous validation, the work offers a systematic, data-driven alternative to heuristic model selection for heterogeneous forecasting, with potential gains in both accuracy and inference cost. The production deployment, offline simulator evaluation, and public code release are concrete strengths that increase the result's practical relevance.
major comments (2)
- [Abstract] Abstract: the central performance claim (12.4% MSE reduction on the industrial dataset) is presented without statistical significance tests, error bars, exact baseline implementations, data-split protocol, or ablation results on the fingerprint dimensionality and router components. These omissions make it impossible to determine whether the reported gain is robust or load-bearing for the framework's contribution.
- [Abstract] Abstract: the core modeling premise—that a forecastability fingerprint derived from data characteristics, together with validation-mined suitability targets, yields a router that generalizes to unseen series under the fixed replenishment policy—is invoked but not accompanied by generalization diagnostics, cross-validation results, or sensitivity analysis on the validation split used to define targets.
minor comments (1)
- [Abstract] The abstract states that results are also shown on public retail benchmarks but provides neither the benchmark names nor any quantitative results for them.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the performance claims would be better supported by explicit references to the supporting analyses already present in the manuscript. We will revise the abstract accordingly and address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim (12.4% MSE reduction on the industrial dataset) is presented without statistical significance tests, error bars, exact baseline implementations, data-split protocol, or ablation results on the fingerprint dimensionality and router components. These omissions make it impossible to determine whether the reported gain is robust or load-bearing for the framework's contribution.
Authors: We acknowledge the abstract would be strengthened by referencing the supporting evidence. Section 4.2 specifies the temporal data-split protocol (80/20 train/validation on historical data, test on subsequent unseen periods). Section 5.1 reports results with error bars from 5 random seeds and paired t-tests confirming statistical significance (p<0.01). Baseline implementations match the original papers with identical hyperparameter tuning on the validation set (Section 4.3). Ablations on fingerprint dimensionality (5-20 dims) and router variants appear in Section 5.4. We will revise the abstract to briefly note statistical significance and direct readers to these sections. revision: yes
-
Referee: [Abstract] Abstract: the core modeling premise—that a forecastability fingerprint derived from data characteristics, together with validation-mined suitability targets, yields a router that generalizes to unseen series under the fixed replenishment policy—is invoked but not accompanied by generalization diagnostics, cross-validation results, or sensitivity analysis on the validation split used to define targets.
Authors: The manuscript evaluates generalization via the temporal split where suitability targets are mined from an earlier validation window and the router is tested on future unseen series (Section 4.2). Additional diagnostics include results on public retail benchmarks with different distributions and the offline simulator under the fixed replenishment policy (Section 6). Sensitivity to the validation split for target mining is analyzed in Appendix B. We will update the abstract to reference the temporal protocol and point to these sections for the requested diagnostics. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes an empirical MoE framework that constructs a forecastability fingerprint from series characteristics, mines suitability targets from validation performance, and trains a separate cost-aware router. These steps follow standard supervised ML practice with no closed-form derivation or self-referential equations that reduce outputs to inputs by construction. The reported gains (e.g., 12.4% MSE reduction) are presented as experimental results on held-out industrial and public data rather than analytic predictions forced by fitted parameters or self-citations. No load-bearing uniqueness theorems, ansatzes smuggled via prior work, or renamings of known patterns appear in the provided text. The framework remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- expert activation budget
- fingerprint dimensionality
axioms (1)
- domain assumption Validation performance on held-out periods provides reliable targets for expert suitability that generalize to future data
invented entities (1)
-
forecastability fingerprint
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Retail forecasting: Research and practice,
R. Fildes, S. Ma, and S. Kolassa, “Retail forecasting: Research and practice,”International Journal of Forecasting, vol. 38, no. 4, pp. 1283– 1318, 2022
2022
-
[2]
No free lunch theorems for optimization,
D. Wolpert and W. Macready, “No free lunch theorems for optimization,” IEEE Transactions on Evolutionary Computation, vol. 1, no. 1, pp. 67– 82, 1997
1997
-
[3]
LightGBM: A highly efficient gradient boosting decision tree,
G. Ke et al., “LightGBM: A highly efficient gradient boosting decision tree,” inNeurIPS, 2017
2017
-
[4]
XGBoost: A scalable tree boosting system,
T. Chen and C. Guestrin, “XGBoost: A scalable tree boosting system,” inKDD, 2016
2016
-
[5]
Forecasting at scale,
S. J. Taylor and B. Letham, “Forecasting at scale,”The American Statistician, vol. 72, no. 1, pp. 37–45, 2018
2018
-
[6]
Forecasting and stock control for intermittent demands,
J. D. Croston, “Forecasting and stock control for intermittent demands,” Operational Research Quarterly, vol. 23, no. 3, pp. 289–303, 1972
1972
-
[7]
USFF: A unified sales forecasting framework for vending machines,
Q. Li, X. Zhang, S. Wang, T. Peng, and J. Wei, “USFF: A unified sales forecasting framework for vending machines,” inIEEE International Conference on Big Data, 2025
2025
-
[8]
A time series is worth 64 words: Long-term forecasting with transformers,
Y . Nie et al., “A time series is worth 64 words: Long-term forecasting with transformers,” inICLR, 2023
2023
-
[9]
TimeMixer: Decomposable multiscale mixing for time series forecasting,
S. Wang et al., “TimeMixer: Decomposable multiscale mixing for time series forecasting,” inICLR, 2024
2024
-
[10]
TimesNet: Temporal 2D-variation modeling for general time series analysis,
H. Wu et al., “TimesNet: Temporal 2D-variation modeling for general time series analysis,” inICLR, 2023
2023
-
[11]
Are transformers effective for time series forecasting?
A. Zeng et al., “Are transformers effective for time series forecasting?” inAAAI, 2023
2023
-
[12]
The M5 accuracy competition: Results, findings, and conclusions,
S. Makridakis et al., “The M5 accuracy competition: Results, findings, and conclusions,”International Journal of Forecasting, vol. 38, no. 4, pp. 1346–1364, 2022
2022
-
[13]
AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
N. Erickson et al., “AutoGluon-Tabular: Robust and accurate AutoML for structured data,” arXiv:2003.06505, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[14]
TFB: Towards comprehensive and fair benchmarking of time series forecasting methods,
X. Qiu et al., “TFB: Towards comprehensive and fair benchmarking of time series forecasting methods,”PVLDB, vol. 17, no. 9, pp. 2363–2377, 2024
2024
-
[15]
STL: A seasonal-trend decomposition procedure based on Loess,
R. B. Cleveland et al., “STL: A seasonal-trend decomposition procedure based on Loess,”Journal of Official Statistics, vol. 6, no. 1, pp. 3–73, 1990
1990
-
[16]
J. Vanschoren, “Meta-learning: A survey,”arXiv:1810.03548, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
FFORMA: Feature-based forecast model averaging,
P. Montero-Manso, G. Athanasopoulos, R. J. Hyndman, and T. S. Tala- gala, “FFORMA: Feature-based forecast model averaging,”International Journal of Forecasting, vol. 36, no. 1, pp. 86–92, 2020
2020
-
[18]
Meta-learning how to forecast time series,
T. S. Talagala, R. J. Hyndman, and G. Athanasopoulos, “Meta-learning how to forecast time series,”Journal of Forecasting, vol. 42, no. 6, pp. 1476–1496, 2023
2023
-
[19]
AutoGluon-TimeSeries: AutoML for probabilistic time series forecasting,
O. Shchur, C. Turkmen, N. Erickson, H. Shen, A. Shirkov, T. Hu, and Y . Wang, “AutoGluon-TimeSeries: AutoML for probabilistic time series forecasting,” arXiv:2308.05566, 2023
-
[20]
CatBoost: unbiased boosting with categorical features,
L. Prokhorenkova et al., “CatBoost: unbiased boosting with categorical features,” inNeurIPS, 2018
2018
-
[21]
R. J. Hyndman, A. B. Koehler, J. K. Ord, and R. D. Snyder,Forecasting with Exponential Smoothing: The State Space Approach. Springer, 2008
2008
-
[22]
The accuracy of intermittent demand estimates,
A. A. Syntetos and J. E. Boylan, “The accuracy of intermittent demand estimates,”International Journal of Forecasting, vol. 21, no. 2, pp. 303– 314, 2005
2005
-
[23]
Adaptive mixtures of local experts,
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton, “Adaptive mixtures of local experts,”Neural Computation, vol. 3, no. 1, pp. 79–87, 1991
1991
-
[24]
A decoder-only foundation model for time-series forecasting,
A. Das, W. Kong, R. Sen, and Y . Zhou, “A decoder-only foundation model for time-series forecasting,” inICML, 2024, pp. 10148–10167
2024
-
[25]
Chronos: Learning the language of time series,
A. F. Ansari et al., “Chronos: Learning the language of time series,” Transactions on Machine Learning Research, 2024
2024
-
[26]
Unified training of universal time series forecasting transformers,
G. Woo, C. Liu, A. Kumar, C. Xiong, S. Savarese, and D. Sahoo, “Unified training of universal time series forecasting transformers,” in ICML, 2024
2024
-
[27]
Is Mamba effective for time series forecasting?
Z. Wang et al., “Is Mamba effective for time series forecasting?” Neurocomputing, vol. 619, p. 129178, 2025
2025
-
[28]
TimeMachine: A time series is worth 4 Mambas for long-term forecasting,
M. A. Ahamed and Q. Cheng, “TimeMachine: A time series is worth 4 Mambas for long-term forecasting,” arXiv:2403.09898, 2024
-
[29]
Mamba4Cast: Efficient zero-shot time series forecasting with state space models,
S. K. Bhethanabhotla et al., “Mamba4Cast: Efficient zero-shot time series forecasting with state space models,” arXiv:2410.09385, 2024
-
[30]
Time-MoE: Billion-scale time series foundation models with mixture of experts,
X. Shi et al., “Time-MoE: Billion-scale time series foundation models with mixture of experts,” inICLR, 2025
2025
-
[31]
GateTS: Versatile and efficient forecasting via attention-inspired routed mixture-of-experts,
K. Yemets et al., “GateTS: Versatile and efficient forecasting via attention-inspired routed mixture-of-experts,” arXiv:2508.17515, 2025
-
[32]
Corporaci ´on Favorita grocery sales forecasting,
Corporacion Favorita, “Corporaci ´on Favorita grocery sales forecasting,” Kaggle competition dataset, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.