From Hazard Functions to Language Space: Cox-Supervised Distillation of Survival Risk into a Large Language Model
Pith reviewed 2026-06-27 17:06 UTC · model grok-4.3
The pith
Survival risk from Cox models can be distilled into large language models via text prompt fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
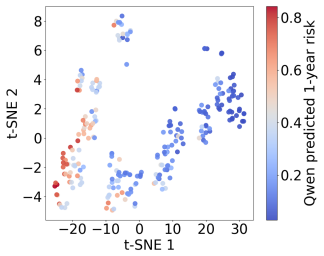
By converting clinical covariates to text and fine-tuning an LLM to generate survival risk scores that match those from a fitted Cox model, the model achieves competitive discrimination and calibration on held-out portions of the GBSG2, ACTG320, and WHAS500 datasets. Visualizations of the model's hidden states show smooth risk gradients under t-SNE, indicating that the LLM represents survival risk as a continuous structure in latent space rather than isolated categories. These observations together indicate that large language models can internalize survival-risk structure from Cox targets while still producing calibrated predictions.
What carries the argument
The text-based survival modelling pipeline that uses Cox model predictions as direct training targets for fine-tuning an LLM on text prompts derived from clinical covariates.
If this is right
- LLMs can reach competitive discrimination and calibration in survival tasks when trained only as text generation.
- Survival risk is represented internally as smooth continuous gradients in the model's latent space.
- This approach supplies a direct route to time-to-event reasoning inside generative language models.
Where Pith is reading between the lines
- The same distillation process could be tested on other parametric or machine-learning survival models beyond Cox.
- LLMs trained this way might combine survival risk with unstructured clinical notes or free-text patient descriptions.
- Natural-language interfaces could allow clinicians to query individualized survival predictions conversationally.
Load-bearing premise
Converting structured clinical covariates into text prompts preserves enough information for the LLM to accurately recover the survival risk structure encoded in the Cox model targets.
What would settle it
If the fine-tuned LLM produces substantially lower concordance or markedly poorer calibration than the original Cox model on held-out data from GBSG2, ACTG320, or WHAS500, or if t-SNE plots of its hidden states fail to display smooth risk gradients.
Figures

read the original abstract
We investigate whether information about time-to-event risk estimated by a Cox proportional hazards model can be transferred into a generative large language model. We propose a text-based survival modelling pipeline in which structured clinical covariates are converted into text prompts and a Qwen-based large language model is fine-tuned to generate patient-specific survival risk using Cox model predictions as a training target. Across GBSG2, ACTG320, and WHAS500, the model achieves competitive held-out discrimination and calibration despite being trained as a text-generation task rather than with a conventional survival-analysis loss. We further analyse the geometry of the model's hidden states, where t-SNE visualisations reveal smooth risk gradients in latent space, suggesting that the model represents survival risk as a continuous structure rather than isolated risk categories. Together, these findings suggest that large language models can internalise survival-risk structure while supporting calibrated prediction, providing a route towards time-to-event reasoning in language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes distilling Cox proportional-hazards risk scores into a generative LLM (Qwen-based) by converting structured clinical covariates into text prompts and fine-tuning the model to output patient-specific survival risk as a text-generation task. It reports competitive held-out discrimination and calibration on GBSG2, ACTG320, and WHAS500, and presents t-SNE visualizations of hidden states showing smooth risk gradients, arguing that LLMs can internalize continuous survival-risk structure without a conventional survival loss.
Significance. If the quantitative results hold, the work is significant for demonstrating that text-generation objectives can approximate survival-analysis metrics and that LLM latent spaces can encode proportional-hazards structure. The explicit use of held-out Cox targets for evaluation avoids circularity and provides a falsifiable test of distillation. This opens a route to natural-language interfaces for time-to-event prediction.
major comments (2)
- [Abstract] Abstract: the central claim of 'competitive held-out discrimination and calibration' is stated without any reported C-index, Brier score, calibration slope, baselines, or error bars. This absence is load-bearing because the claim that text-generation training successfully distills Cox risk cannot be evaluated without these metrics.
- [Abstract / Pipeline description] Pipeline description (abstract and methods): the conversion of structured covariates to text prompts is described only as 'converted into text prompts' with no template, rounding/binning rules, or fidelity verification. This is load-bearing for the weakest assumption that numerical precision is preserved sufficiently for the LLM to recover the Cox linear predictor on held-out data.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where the abstract and methods could be strengthened for clarity and evaluability. We address each point below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'competitive held-out discrimination and calibration' is stated without any reported C-index, Brier score, calibration slope, baselines, or error bars. This absence is load-bearing because the claim that text-generation training successfully distills Cox risk cannot be evaluated without these metrics.
Authors: We agree that the abstract would be stronger and more self-contained if it included the quantitative results. The manuscript reports C-index, Brier scores, calibration slopes, and baseline comparisons in the results section with held-out evaluations on the three datasets. In revision we will add the key metrics, baselines, and any error bars or intervals directly to the abstract to support the claim. revision: yes
-
Referee: [Abstract / Pipeline description] Pipeline description (abstract and methods): the conversion of structured covariates to text prompts is described only as 'converted into text prompts' with no template, rounding/binning rules, or fidelity verification. This is load-bearing for the weakest assumption that numerical precision is preserved sufficiently for the LLM to recover the Cox linear predictor on held-out data.
Authors: We accept that the current description of the covariate-to-text conversion is insufficiently detailed. The methods section will be expanded in revision to include the exact prompt template, rules for handling numerical values (rounding, binning, or direct inclusion), and any verification performed to confirm that the text encoding retains the information needed for the model to approximate the Cox linear predictor. revision: yes
Circularity Check
No significant circularity; Cox targets are external and evaluation is held-out
full rationale
The paper fits a separate Cox model on training data to generate targets, then fine-tunes the LLM on text prompts to match those targets via text-generation loss. Held-out discrimination and calibration are measured against true event times, not the Cox predictions themselves. No equations reduce the reported performance to a fitted quantity by construction, no self-citation chain supports a uniqueness claim, and the text-conversion step is a preprocessing choice rather than a definitional loop. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- LLM fine-tuning hyperparameters
axioms (1)
- domain assumption Cox proportional hazards model supplies reliable risk targets for the LLM to learn from
Reference graph
Works this paper leans on
-
[1]
John Wiley & Sons, 2002
John D Kalbfleisch and Ross L Prentice.The statistical analysis of failure time data. John Wiley & Sons, 2002
2002
-
[2]
Regression models and life-tables.Journal of the Royal Statistical Society: Series B (Methodological), 34(2):187–202, 1972
David R Cox. Regression models and life-tables.Journal of the Royal Statistical Society: Series B (Methodological), 34(2):187–202, 1972
1972
-
[3]
Deephit: A deep learning approach to survival analysis with competing risks
Changhee Lee, William Zame, Jinsung Yoon, and Mihaela Van Der Schaar. Deephit: A deep learning approach to survival analysis with competing risks. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[4]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfeng ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024. URL https:// qwenlm.github.io/blog/qwen2.5/
2024
-
[7]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[8]
Randomized 2 x 2 trial evaluating hormonal treatment and the duration of chemotherapy in node-positive breast cancer patients
M Schumacher, G Bastert, H Bojar, K Hübner, M Olschewski, W Sauerbrei, C Schmoor, C Beyerle, RL Neumann, and HF Rauschecker. Randomized 2 x 2 trial evaluating hormonal treatment and the duration of chemotherapy in node-positive breast cancer patients. german breast cancer study group.Journal of Clinical Oncology, 12(10):2086–2093, 1994
2086
-
[9]
Scott M Hammer, Kathleen E Squires, Michael D Hughes, Janet M Grimes, Lisa M Demeter, Judith S Currier, Joseph J Eron Jr, Judith E Feinberg, Henry H Balfour Jr, Lawrence R Deyton, et al. A controlled trial of two nucleoside analogues plus indinavir in persons with human immunodeficiency virus infection and cd4 cell counts of 200 per cubic millimeter or le...
1997
-
[10]
Incidence and case fatality rates of acute myocardial infarction (1975–1984): the worcester heart attack study
Robert J Goldberg, Joel M Gore, Joseph S Alpert, and James E Dalen. Incidence and case fatality rates of acute myocardial infarction (1975–1984): the worcester heart attack study. American Heart Journal, 115(4):761–767, 1988
1975
-
[11]
Evaluating the yield of medical tests.Jama, 247(18):2543–2546, 1982
Frank E Harrell, Robert M Califf, David B Pryor, Kerry L Lee, and Robert A Rosati. Evaluating the yield of medical tests.Jama, 247(18):2543–2546, 1982
1982
-
[12]
Calibration: the achilles heel of predictive analytics.BMC medicine, 17(1):230, 2019
Ben Van Calster, David J McLernon, Maarten Van Smeden, Laure Wynants, and Ewout W Steyerberg. Calibration: the achilles heel of predictive analytics.BMC medicine, 17(1):230, 2019
2019
-
[13]
Deepsurv: personalized treatment recommender system using a cox proportional hazards deep neural network.BMC medical research methodology, 18(1):24, 2018
Jared L Katzman, Uri Shaham, Alexander Cloninger, Jonathan Bates, Tingting Jiang, and Yuval Kluger. Deepsurv: personalized treatment recommender system using a cox proportional hazards deep neural network.BMC medical research methodology, 18(1):24, 2018
2018
-
[14]
A transformer-based survival model for prediction of all-cause mortality in patients with heart failure: a multi-cohort study.npj Digital Medicine, 2026
Shishir Rao, Nouman Ahmed, Gholamreza Salimi-Khorshidi, Christopher Yau, Huimin Su, Nathalie Conrad, Folkert W Asselbergs, Mark Woodward, Rod Jackson, John GF Cleland, et al. A transformer-based survival model for prediction of all-cause mortality in patients with heart failure: a multi-cohort study.npj Digital Medicine, 2026. 5
2026
-
[15]
Tabllm: Few-shot classification of tabular data with large language models
Stefan Hegselmann, Alejandro Buendia, Hunter Lang, Monica Agrawal, Xiaoyi Jiang, and David Sontag. Tabllm: Few-shot classification of tabular data with large language models. InInternational conference on artificial intelligence and statistics, pages 5549–5581. PMLR, 2023
2023
-
[16]
scikit-survival: A library for time-to-event analysis built on top of scikit-learn
Sebastian Pölsterl. scikit-survival: A library for time-to-event analysis built on top of scikit-learn. Journal of Machine Learning Research, 21(212):1–6, 2020
2020
-
[17]
lifelines: Survival Analysis in Python.Journal of Open Source Software, 2019
Cameron Davidson-Pilon. lifelines: Survival Analysis in Python.Journal of Open Source Software, 2019. URL https://github.com/CamDavidsonPilon/lifelines/ tree/master
2019
-
[18]
Python Tutorial
Guido Van Rossum. Python Tutorial. Technical report, Centrum voor Wiskunde en Informatica (CWI), 1995
1995
-
[19]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[20]
Nicholas I-Hsien Kuo, Blanca Gallego, Louisa Jorm, et al. Ck4gen: A knowledge distillation framework for generating high-utility synthetic survival datasets in healthcare.arXiv preprint arXiv:2410.16872, 2024
-
[21]
Performance of the net reclassification improvement for nonnested models and a novel percentile-based alternative.American journal of epidemiology, 187(6):1327–1335, 2018
Shannon B McKearnan, Julian Wolfson, David M V ock, Gabriela Vazquez-Benitez, and Patrick J O’Connor. Performance of the net reclassification improvement for nonnested models and a novel percentile-based alternative.American journal of epidemiology, 187(6):1327–1335, 2018
2018
-
[22]
Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
2008
-
[23]
Tristan Bouckley, Rimma Myton-Katieva, David Peiris, Devaki Nambiar, Samuel Prince, Simon Bishop, Damien Cordery, Flynn Robert Hill, Patricia Correll, Anne-Marie Feyer, et al. An assessment of data quality and sociodemographic variation in health service utilisation of general practice, emergency department and admitted services in a new south wales linke...
2025
-
[24]
Estimating 5-year absolute risk of cardiovascular disease using routinely collected electronic medical records from australian general practices.Heart, 2025
Nicholas I-Hsien Kuo, Sebastiano Barbieri, Clare Arnott, Blanca Gallego, Ziba Gandomkar, Shahana Ferdousi, Kirsty Douglas, Mark Woodward, and Louisa Jorm. Estimating 5-year absolute risk of cardiovascular disease using routinely collected electronic medical records from australian general practices.Heart, 2025
2025
-
[25]
Cardiovascular disease risk prediction equations in 400 000 primary care patients in new zealand: a derivation and validation study.The Lancet, 391(10133):1897–1907, 2018
Romana Pylypchuk, Sue Wells, Andrew Kerr, Katrina Poppe, Tania Riddell, Matire Harwood, Dan Exeter, Suneela Mehta, Corina Grey, Billy P Wu, et al. Cardiovascular disease risk prediction equations in 400 000 primary care patients in new zealand: a derivation and validation study.The Lancet, 391(10133):1897–1907, 2018
1907
-
[26]
Development and validation of qrisk3 risk prediction algorithms to estimate future risk of cardiovascular disease: prospective cohort study.bmj, 357, 2017
Julia Hippisley-Cox, Carol Coupland, and Peter Brindle. Development and validation of qrisk3 risk prediction algorithms to estimate future risk of cardiovascular disease: prospective cohort study.bmj, 357, 2017
2017
-
[27]
Development and validation of the american heart association’s prevent equations
Sadiya S Khan, Kunihiro Matsushita, Yingying Sang, Shoshana H Ballew, Morgan E Grams, Aditya Surapaneni, Michael J Blaha, April P Carson, Alexander R Chang, Elizabeth Ciemins, et al. Development and validation of the american heart association’s prevent equations. Circulation, 149(6):430–449, 2024
2024
-
[28]
Informative missingness in electronic health record systems: the curse of knowing.Diagnostic and prognostic research, 4(1):8, 2020
Rolf HH Groenwold. Informative missingness in electronic health record systems: the curse of knowing.Diagnostic and prognostic research, 4(1):8, 2020
2020
-
[29]
Evaluat- ing deep learning sepsis prediction models in icus under distribution shift: a multi-centre retrospective cohort study.npj Digital Medicine, 2026
Fanny Tranchellini, Youssef Farag, Catherine Jutzeler, and Lakmal Meegahapola. Evaluat- ing deep learning sepsis prediction models in icus under distribution shift: a multi-centre retrospective cohort study.npj Digital Medicine, 2026. 6
2026
-
[30]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[31]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Huggingface’s transform- ers: State-of-the-art natural language processing.arXiv preprint arXiv:1910.03771, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[32]
Unsloth team
Michael Han Daniel Han and Michael Han. Unsloth team. 2023
2023
-
[33]
TRL: Transformers Rein- forcement Learning, 2020
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. TRL: Transformers Rein- forcement Learning, 2020. URLhttps://github.com/huggingface/trl
2020
-
[34]
Peft: State-of-the-art parameter-efficient fine-tuning methods, 2022
Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, Sayak Paul, and Ben- jamin Bossan. Peft: State-of-the-art parameter-efficient fine-tuning methods, 2022. URL https://github.com/huggingface/peft
2022
-
[35]
Accelerate: Training and inference at scale made simple, efficient and adaptable.https://github.com/huggingface/accelerate, 2022
Sylvain Gugger, Lysandre Debut, Thomas Wolf, Philipp Schmid, Zachary Mueller, Sourab Mangrulkar, Marc Sun, and Benjamin Bossan. Accelerate: Training and inference at scale made simple, efficient and adaptable.https://github.com/huggingface/accelerate, 2022
2022
-
[36]
Qlora: Efficient finetuning of quantized llms.Advances in neural information processing systems, 36:10088– 10115, 2023
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms.Advances in neural information processing systems, 36:10088– 10115, 2023
2023
-
[37]
Datasets: A community library for natural language processing
Quentin Lhoest, Albert Villanova Del Moral, Yacine Jernite, Abhishek Thakur, Patrick V on Platen, Suraj Patil, Julien Chaumond, Mariama Drame, Julien Plu, Lewis Tunstall, et al. Datasets: A community library for natural language processing. InProceedings of the 2021 conference on empirical methods in natural language processing: system demonstrations, pag...
2021
-
[38]
Scikit- learn: Machine learning in python.the Journal of machine Learning research, 12:2825–2830, 2011
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, et al. Scikit- learn: Machine learning in python.the Journal of machine Learning research, 12:2825–2830, 2011
2011
-
[39]
Array programming with numpy.nature, 585(7825):357–362, 2020
Charles R Harris, K Jarrod Millman, Stéfan J Van Der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J Smith, et al. Array programming with numpy.nature, 585(7825):357–362, 2020
2020
-
[40]
Data structures for statistical computing in python.scipy, 445(1):51–56, 2010
Wes McKinney et al. Data structures for statistical computing in python.scipy, 445(1):51–56, 2010
2010
-
[41]
Matplotlib: A 2d graphics environment.Computing in science & engineering, 9(3):90–95, 2007
John D Hunter. Matplotlib: A 2d graphics environment.Computing in science & engineering, 9(3):90–95, 2007
2007
-
[42]
John Wiley & Sons, 2008
David W Hosmer Jr, Stanley Lemeshow, and Susanne May.Applied survival analysis: regression modeling of time-to-event data, volume 618. John Wiley & Sons, 2008
2008
-
[43]
Modelling the effects of standard prognostic factors in node-positive breast cancer.British Journal of Cancer, 79(11): 1752–1760, 1999
W Sauerbrei, P Royston, H Bojar, C Schmoor, and M Schumacher. Modelling the effects of standard prognostic factors in node-positive breast cancer.British Journal of Cancer, 79(11): 1752–1760, 1999
1999
-
[44]
Table 6.7 on page 198
David A Karnofsky, Walter H Abelmann, Lloyd F Craver, and Joseph H Burchenal. The use of the nitrogen mustards in the palliative treatment of carcinoma: with particular reference to bronchogenic carcinoma.Cancer, 1948. 7 Appendix: Additional Details to the Main Text Purpose of this Appendix.This appendix formalises the Cox-to-Qwen survival distillation fr...
1948
-
[45]
Harrell’s C-index for survival discrimination [11],
-
[46]
calibration error (D21) based on calibration slope estimation [20, 12],
-
[47]
Du ra ti on
percentile-based NRI [21]. The evaluation pipeline first merges the generated predictions with the held-out survival outcomes, removes invalid predictions, and clips all predicted risks to the interval [0,1] before downstream analysis. Calibration analysis is then performed using quantile-based risk bins and Kaplan–Meier survival estimation at the 1-year ...
-
[48]
the mean predicted risk is computed,
-
[49]
ri sk_ bi n
the observed 1-year event probability is estimated using Kaplan–Meier survival estimation. Let: ˆrb denote the mean predicted risk in bin b, and ob denote the observed Kaplan–Meier risk in the same bin. Calibration is assessed using a regression without intercept: ˆrb =βo b. (note that in this formulation, we are essentially putting the predicted risk on ...
-
[50]
p r e d i c t e d _ r i s k
values . reshape ( -1 , 1) , 6ca li b_d f [ " p r e d i c t e d _ r i s k " ]. values 7) 8 9slope = float ( reg . coef_ [0]) 10c a l i b _ e r r o r = abs ( slope - 1.0) This calibration framework therefore measures whether the generated survival-risk predictions remain numerically consistent with empirically observed event frequencies. 30 C.5.3 Details 5...
-
[51]
a t t e n t i o n _ m a s k
to ( " cuda " ) 9 10with torch . no_grad () : 11outputs = model ( 12** inputs , 13o u t p u t _ h i d d e n _ s t a t e s = True , 14r e t u r n _ d i c t = True , 15) 16 32 17hidden = outputs . h i d d e n _ s t a t e s [ -1] 18 19attn = inputs [ " a t t e n t i o n _ m a s k " ] 20la st _i dx = attn . sum ( dim =1) - 1 21 22vec = hidden [0 , l ast _i dx...
-
[52]
a t t e n t i o n _ m a s k
numpy () 27 28return vec Lines 11–15: The key operation enabling hidden-state extraction is: 1outputs = model ( 2** inputs , 3o u t p u t _ h i d d e n _ s t a t e s = True , 4r e t u r n _ d i c t = True , 5) which instructs the transformer to return the full sequence of hidden-state activations from all transformer layers. The final-layer activations ar...
1973
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.