An Effective Router for Vision-Language Model Selection
Pith reviewed 2026-06-27 17:04 UTC · model grok-4.3
The pith
ARMS is a compact router that selects the best vision-language model for a query and adapts via two training strategies to outperform models hundreds of times larger.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
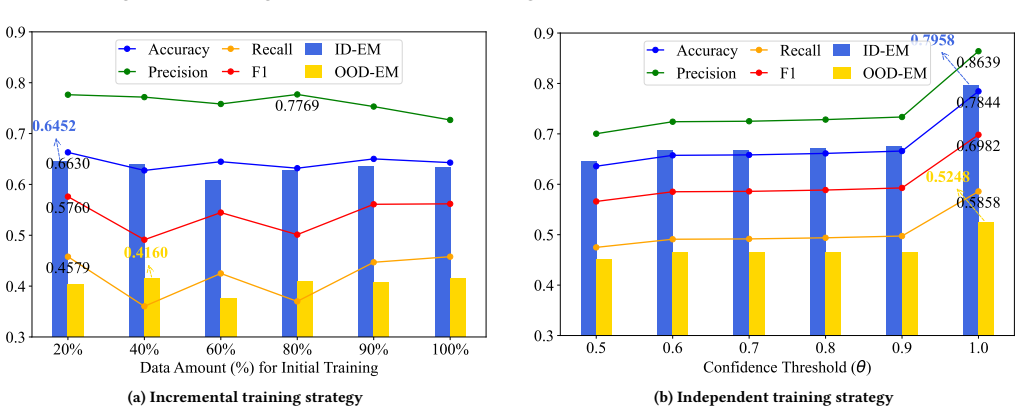
ARMS enhances input signals with VLM profiles and employs a simple architecture for better query and capability representations; combined with incremental or independent training it adapts to new VLMs, allowing an 800M model to defeat much larger commercial ones on VLM selection tasks.
What carries the argument
ARMS router that augments inputs with VLM profiles and applies incremental or independent training to expand the model space.
If this is right
- ARMS achieves strong performance on both in-distribution and out-of-distribution test sets for VLM selection.
- Incremental and independent training let the router extend to new VLMs at lower cost than full retraining.
- An 800M router can match or exceed selection quality of commercial models hundreds of times larger after adaptation.
- The constructed multimodal dataset supplies the specialized data needed to train future VLM routers.
Where Pith is reading between the lines
- The same profile-augmented routing approach could be tested on selecting among other multimodal or unimodal model families.
- Dynamic selection with ARMS could lower average inference cost for users who currently default to the largest available model.
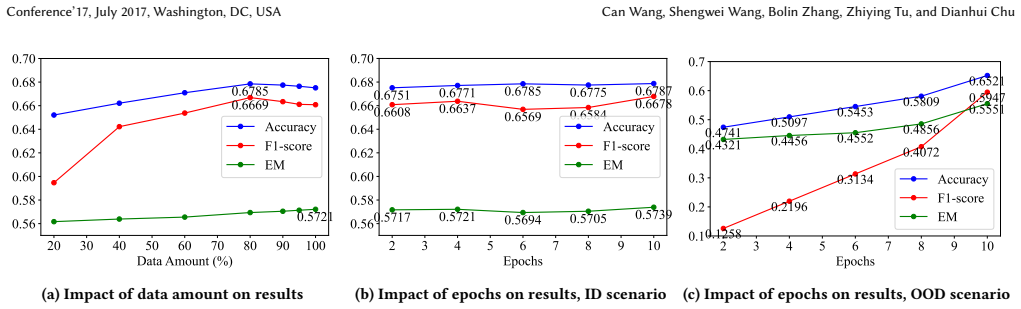
- Collecting outputs from additional VLMs on the same queries would allow direct measurement of how dataset scale affects router accuracy.
Load-bearing premise
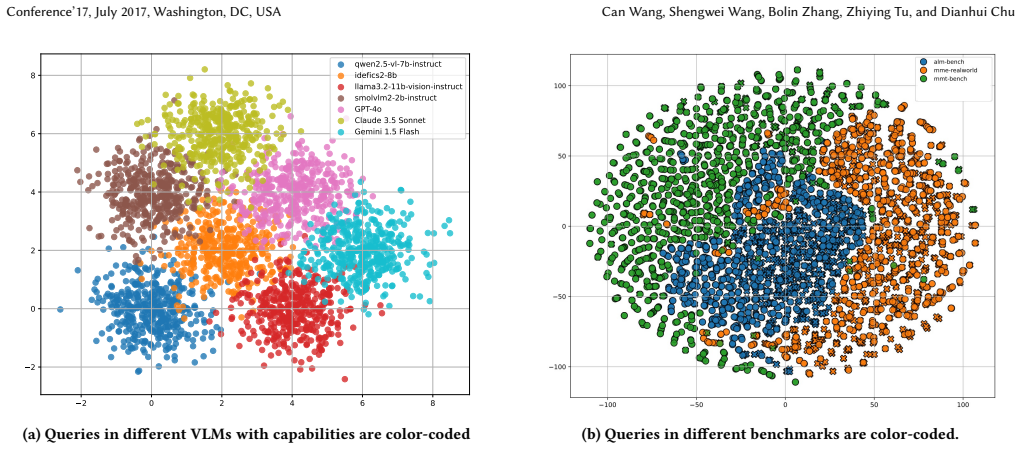
The 32,626-query dataset from seven VLMs is representative enough that a router trained on it will keep selecting the best model for new queries and newly added VLMs.
What would settle it
Evaluating the trained ARMS on a fresh collection of queries or on VLMs released after the dataset was built and finding that its selections are no longer better than those of GPT-4o or other large models.
Figures


read the original abstract
Vision-language models (VLMs) with varying performance and resource requirements are widely deployed, making it difficult for users to select the most appropriate one among numerous VLM candidates. Existing work reveals the performance paradox phenomenon in language models and focuses on routing methods to solve it. However, developing a router for VLM selection is still a critical yet challenging problem, which primarily faces: 1) lack of specialized data, 2) ineffective feature representation, and 3) rigid model space and costly adaptation. In this paper, we construct a multimodal dataset for VLM selection, containing the outputs of seven mainstream VLMs on 32,626 unique image-text queries. We then propose ARMS, a router for VLM selection. ARMS enhances input signals with VLM profiles, employs a simple but effective architecture to improve representations of queries and VLM capabilities. To improve ARMS' adaptation to new VLMs, we propose two extension training strategies: incremental training and independent training. Experimental results on both in-distribution and out-of-distribution test sets demonstrate the effectiveness of ARMS. In particular, using our training strategy, ARMs (only 800M in size) can adapt to a broader VLM space and defeat commercial models like GPT-4o that are hundreds of times larger in scale. Our code, models, and datasets are available in the anonymous repository.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript constructs a multimodal dataset consisting of 32,626 image-text queries evaluated by seven mainstream VLMs. It proposes ARMS, an 800M-parameter router that augments query features with VLM profiles, employs a simple architecture for improved representations, and introduces incremental and independent training strategies to adapt the router to new VLMs. Experiments are reported to show effectiveness on both in-distribution and out-of-distribution test sets, with the headline claim that the adapted ARMS outperforms much larger commercial models such as GPT-4o.
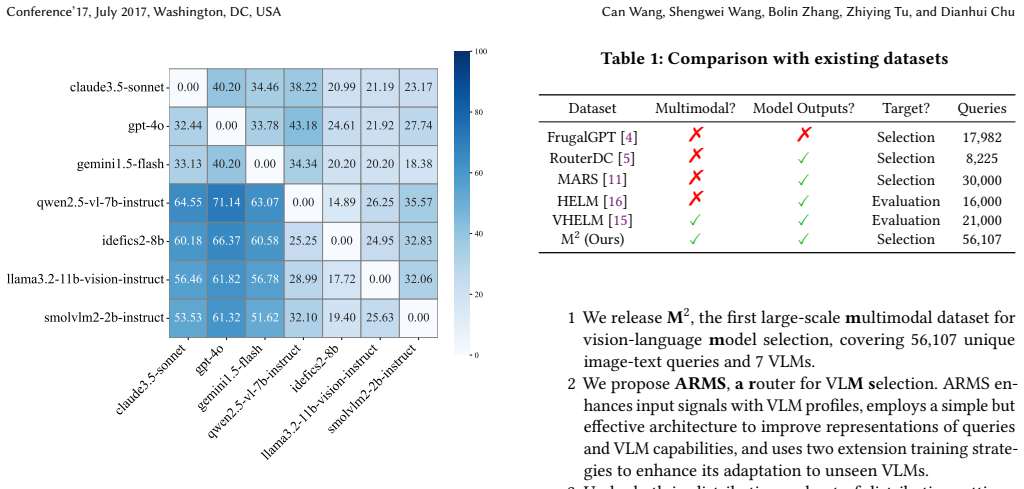
Significance. If the empirical claims are substantiated with full quantitative detail, the work would address a practical deployment challenge in heterogeneous VLM ecosystems by providing a lightweight, adaptable router. The public release of the dataset, code, and models is a clear strength that enables reproducibility and follow-on research.
major comments (2)
- [Abstract and §4] Abstract and §4 (experimental results): the claim that the 800M ARMS defeats GPT-4o is presented without any numerical performance values, baseline comparisons, error bars, or ablation tables. This absence is load-bearing for the central empirical contribution.
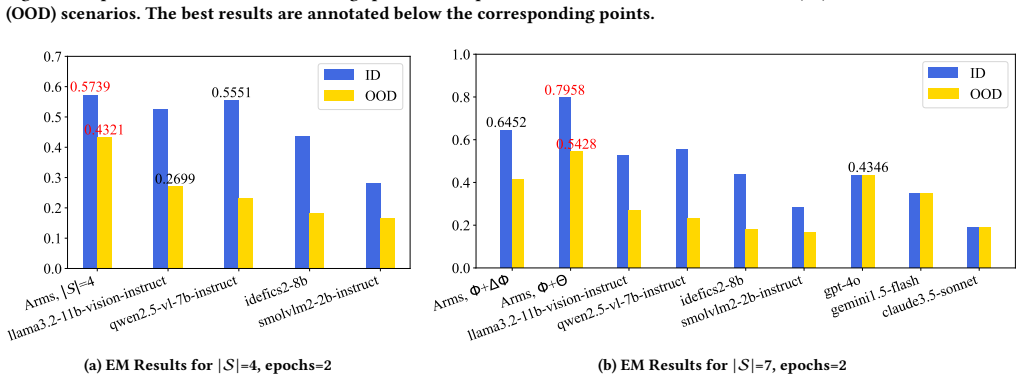
- [§3.2 and §4.2] §3.2 and §4.2 (OOD evaluation): the out-of-distribution test sets are constructed exclusively from the same seven source VLMs used to build the 32,626-query training collection. This does not probe extrapolation to new VLMs whose capability profiles may lie outside the convex hull of the training set, which is required to support the adaptation-to-broader-space claim.
minor comments (1)
- [§3.1] Clarify the precise encoding and dimensionality of the VLM profiles and how they are concatenated with query embeddings in the router architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (experimental results): the claim that the 800M ARMS defeats GPT-4o is presented without any numerical performance values, baseline comparisons, error bars, or ablation tables. This absence is load-bearing for the central empirical contribution.
Authors: We agree that the abstract and Section 4 require explicit numerical performance values, baseline comparisons, error bars, and ablation tables to substantiate the claim. In the revised manuscript, we will add these quantitative details from our experiments, including the specific metrics demonstrating ARMS outperforming GPT-4o after adaptation. revision: yes
-
Referee: [§3.2 and §4.2] §3.2 and §4.2 (OOD evaluation): the out-of-distribution test sets are constructed exclusively from the same seven source VLMs used to build the 32,626-query training collection. This does not probe extrapolation to new VLMs whose capability profiles may lie outside the convex hull of the training set, which is required to support the adaptation-to-broader-space claim.
Authors: The OOD test sets evaluate generalization to unseen queries drawn from the same seven VLMs, while the incremental and independent training strategies are intended to enable adaptation to new VLMs. The broader-space claim is supported by results on incorporating additional models via these strategies. We will revise the manuscript to explicitly distinguish query-level OOD from model adaptation and discuss the limitation regarding profiles outside the original set. revision: partial
Circularity Check
No circularity: empirical training and evaluation on external dataset
full rationale
The paper collects a 32,626-query dataset from seven VLMs, trains the ARMS router (with incremental/independent strategies), and reports empirical accuracy on in-distribution and out-of-distribution splits plus comparisons to GPT-4o. No equations, fitted parameters renamed as predictions, or self-citation chains are shown that reduce the reported performance to an input by construction. The result remains an open empirical claim whose validity depends on dataset representativeness, not on definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2024. Claude 3.5 sonnet model card addendum.anthropic blog. https://www-cdn.anthropic.com/fed9cc193a14b84131812372d8d5857f8f304c 52/Model_Card_Claude_3_Addendum.pdf
2024
-
[2]
Shuai Bai et al. 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923
Pith/arXiv arXiv 2025
-
[3]
Zongsheng Cao, Yangfan He, Anran Liu, Jun Xie, Feng Chen, and Zhepeng Wang. 2025. Tv-rag: a temporal-aware and semantic entropy-weighted frame- work for long video retrieval and understanding. InProceedings of the 33rd ACM International Conference on Multimedia(MM ’25). Association for Computing Machinery, Dublin, Ireland, 9071–9079.isbn: 9798400720352. d...
-
[4]
Lingjiao Chen, Matei Zaharia, and James Zou. 2024. Frugalgpt: how to use large language models while reducing cost and improving performance.Transactions on Machine Learning Research
2024
-
[5]
Shuhao Chen, Weisen Jiang, Baijiong Lin, James Kwok, and Yu Zhang. 2024. Routerdc: query-based router by dual contrastive learning for assembling large language models.Advances in Neural Information Processing Systems, 37, 66305– 66328
2024
-
[6]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 4171–4186
2019
-
[7]
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Rühle, Laks VS Lakshmanan, and Ahmed Hassan Awadallah. 2023. Hybrid llm: cost-efficient and quality-aware query routing. InThe Twelfth International Conference on Learning Representations
2023
-
[8]
Tao Feng, Yanzhen Shen, and Jiaxuan You. 2024. Graphrouter: a graph-based router for llm selections. InThe Thirteenth International Conference on Learning Representations
2024
-
[9]
Aaron Grattafiori et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783
Pith/arXiv arXiv 2024
-
[10]
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2021. Deberta: decoding-enhanced bert with disentangled attention. InInternational Confer- ence on Learning Representations
2021
-
[11]
Qitian Jason Hu, Jacob Bieker, Xiuyu Li, Nan Jiang, Benjamin Keigwin, Gaurav Ranganath, Kurt Keutzer, and Shriyash Kaustubh Upadhyay. 2024. Mars: a benchmark for multi-llm algorithmic routing system. InICLR 2024 Workshop: How Far Are We From AGI
2024
-
[12]
Aaron Hurst et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276
Pith/arXiv arXiv 2024
-
[13]
Dongfu Jiang, Xiang Ren, and Bill Yuchen Lin. 2023. Llm-blender: ensembling large language models with pairwise ranking and generative fusion. InProceed- ings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL: Long Papers), 14165–14178
2023
-
[14]
Hugo Laurençon, Léo Tronchon, Matthieu Cord, and Victor Sanh. 2024. What matters when building vision-language models?Advances in Neural Information Processing Systems, 37, 87874–87907
2024
-
[15]
Tony Lee et al. 2024. Vhelm: a holistic evaluation of vision language models. Advances in Neural Information Processing Systems, 37, 140632–140666
2024
-
[16]
Percy Liang et al. 2023. Holistic evaluation of language models.Transactions on Machine Learning Research. Featured Certification, Expert Certification. https://openreview.net/forum?id=iO4LZibEqW
2023
-
[17]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. InInternational Conference on Learning Representations
2017
-
[18]
Keming Lu, Hongyi Yuan, Runji Lin, Junyang Lin, Zheng Yuan, Chang Zhou, and Jingren Zhou. 2024. Routing to the expert: efficient reward-guided ensemble of large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 1964–1974
2024
-
[19]
Andrés Marafioti et al. 2025. Smolvlm: redefining small and efficient multimodal models.arXiv preprint arXiv:2504.05299
Pith/arXiv arXiv 2025
-
[20]
Alec Radford et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[21]
Marija Šakota, Maxime Peyrard, and Robert West. 2024. Fly-swat or cannon? cost-effective language model choice via meta-modeling. InProceedings of the 17th ACM International Conference on Web Search and Data Mining, 606–615
2024
-
[22]
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. Dis- tilbert, a distilled version of bert: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108
Pith/arXiv arXiv 2019
-
[23]
Tal Shnitzer, Anthony Ou, Mírian Silva, Kate Soule, Yuekai Sun, Justin Solomon, Neil Thompson, and Mikhail Yurochkin. 2024. Large language model routing with benchmark datasets. InFirst Conference on Language Modeling
2024
-
[24]
Dimitris Stripelis et al. 2024. Tensoropera router: a multi-model router for effi- cient llm inference. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, 452–462
2024
-
[25]
Gemini Team et al. 2024. Gemini 1.5: unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530
Pith/arXiv arXiv 2024
-
[26]
Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-sne.Journal of machine learning research, 9, 11
2008
-
[27]
Ashmal Vayani et al. 2024. All languages matter: evaluating lmms on culturally diverse 100 languages.arXiv preprint arXiv:2411.16508
arXiv 2024
-
[28]
Can Wang, Dianbo Sui, Bolin Zhang, Xiaoyu Liu, Jiabao Kang, Zhidong Qiao, and Zhiying Tu. 2025. A framework for effective invocation methods of various LLM services. InProceedings of the 31st International Conference on Computa- tional Linguistics. Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert, (E...
2025
-
[29]
Qinchen Wu, Difei Gao, Qinghong Lin, Zhuoyu Wu, and Mike Zheng Shou. 2025. Gui-narrator: detecting and captioning computer gui actions. InProceedings of the 33rd ACM International Conference on Multimedia(MM ’25). Association for Computing Machinery, Dublin, Ireland, 3683–3692.isbn: 9798400720352. doi:10.1145/3746027.3755150
-
[30]
Kaining Ying et al. 2024. Mmt-bench: a comprehensive multimodal bench- mark for evaluating large vision-language models towards multitask agi. In Proceedings of the 41st International Conference on Machine Learning, 57116– 57198
2024
-
[31]
Runtian Yuan, Mohan Chen, Jilan Xu, Ling Zhou, Qingqiu Li, Yuejie Zhang, Rui Feng, Tao Zhang, and Shang Gao. 2025. Text-promptable propagation for referring medical image sequence segmentation. InProceedings of the 33rd ACM International Conference on Multimedia(MM ’25). Association for Computing Machinery, Dublin, Ireland, 362–371.isbn: 9798400720352. do...
-
[32]
Yi-Fan Zhang et al. 2024. Mme-realworld: could your multimodal llm chal- lenge high-resolution real-world scenarios that are difficult for humans?arXiv preprint arXiv:2408.13257
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.