JAX-AMG: A GPU-Accelerated Differentiable Sparse Linear Solver Library for JAX
Pith reviewed 2026-06-27 14:23 UTC · model grok-4.3
The pith
JAX-AMG wraps Nvidia AmgX as a native JAX primitive to deliver GPU-accelerated AMG, automatic differentiation, and multi-GPU execution for sparse linear systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
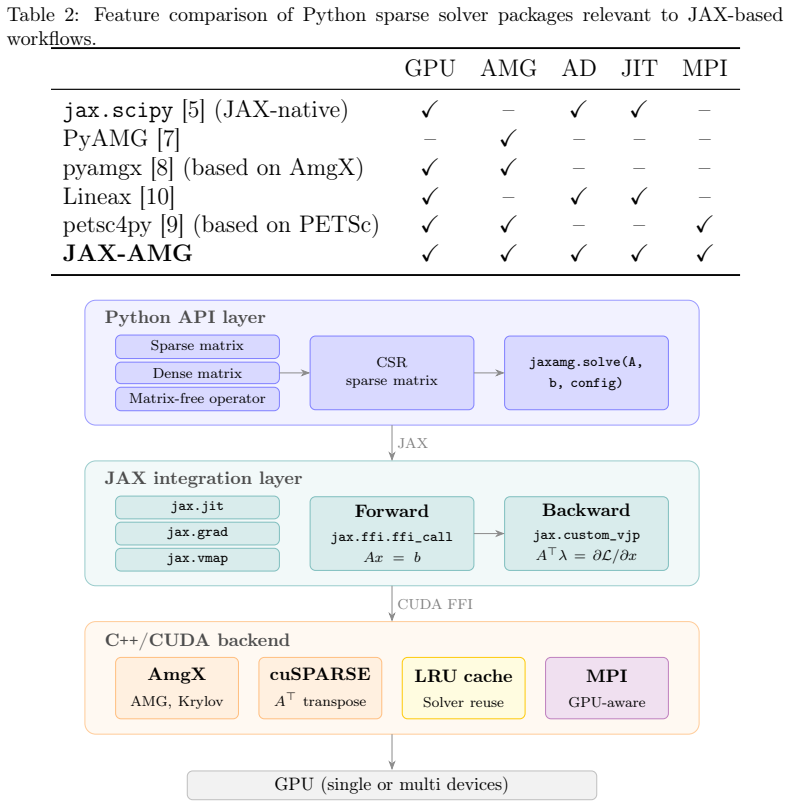
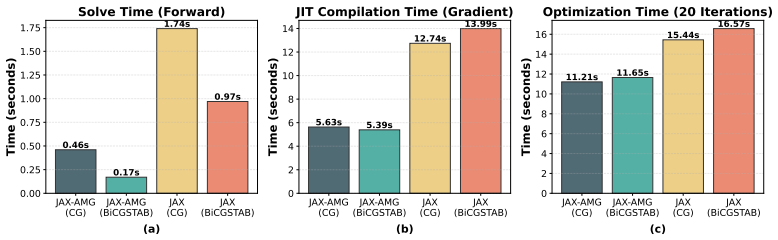
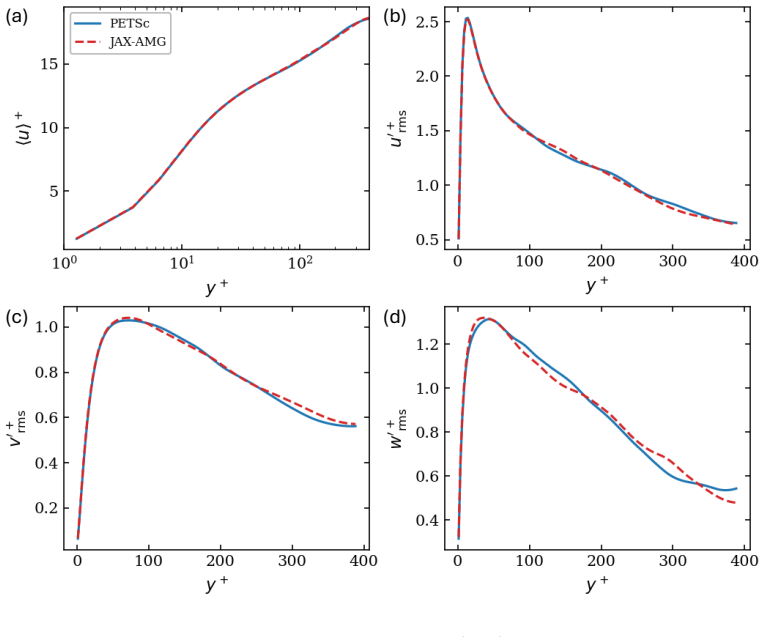
By wrapping the Nvidia AmgX solver suite as a native JAX primitive, JAX-AMG exposes AMG and Krylov methods with configurable preconditioners through a unified interface. This interface supports JIT compilation, reverse-mode AD via adjoint methods, batched solves, and MPI-based distributed execution. Solver caching amortizes setup costs across repeated solves, making JAX-AMG practical for PDE-constrained optimization and inverse problems.
What carries the argument
The AmgX wrapper exposed as a native JAX primitive that carries AMG and Krylov solves while preserving compatibility with JIT, adjoint differentiation, batching, and MPI distribution.
If this is right
- PDE-constrained optimization becomes feasible inside JAX using GPU-accelerated AMG preconditioners.
- Inverse problems that require repeated sparse solves can now use automatic differentiation through the linear algebra step.
- Large-scale simulations gain access to distributed multi-GPU execution without exiting the JAX environment.
- Repeated solves inside iterative algorithms benefit from cached setup costs that are amortized across calls.
Where Pith is reading between the lines
- The same wrapping technique could be reused for other external solver packages to enlarge the set of differentiable linear algebra primitives available in JAX.
- Differentiable AMG opens the door to gradient-based adaptation of preconditioner parameters inside larger optimization loops.
- Integration with JAX's vectorized map and parallel primitives could enable hybrid CPU-GPU workflows for mixed-precision or multi-physics models.
Load-bearing premise
The AmgX wrapper can be exposed as a JAX primitive while preserving full compatibility with JIT compilation, reverse-mode adjoint differentiation, batched execution, and MPI distribution without introducing correctness or performance issues.
What would settle it
A benchmark in which gradients obtained through JAX-AMG on a small linear PDE optimization task deviate from finite-difference reference values, or in which the same solve fails to scale correctly across multiple GPUs under MPI.
Figures
read the original abstract
Sparse linear systems from PDE discretizations are central to scientific computing, yet no existing JAX-ecosystem solver simultaneously provides GPU-accelerated algebraic multigrid (AMG), automatic differentiation (AD), and distributed multi-GPU execution. JAX-AMG fills this gap by wrapping the Nvidia AmgX solver suite as a native JAX primitive, exposing AMG and Krylov methods with configurable preconditioners through a unified interface compatible with JIT compilation, reverse-mode AD via adjoint methods, batched solves, and MPI-based distributed execution. Solver caching amortizes setup costs across repeated solves, making JAX-AMG practical for PDE-constrained optimization and inverse problems. The result is a robust, scalable sparse linear algebra layer that integrates seamlessly into differentiable simulation and scientific machine learning pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents JAX-AMG, a library that wraps Nvidia AmgX as a native JAX primitive to deliver GPU-accelerated algebraic multigrid and Krylov solvers with configurable preconditioners. It claims a unified interface supporting JIT compilation, reverse-mode automatic differentiation via adjoints, batched execution, and MPI-based distributed multi-GPU runs, plus solver caching to amortize setup costs for repeated solves in PDE-constrained optimization and inverse problems.
Significance. If the integration works as described, the library would address a documented gap in the JAX ecosystem by combining high-performance AMG with differentiability and distribution, enabling new workflows in scientific machine learning. The pragmatic reuse of AmgX is a strength, but the significance hinges on whether the claimed JAX-primitive properties are actually achieved without hidden limitations.
major comments (1)
- [Abstract] Abstract (paragraph describing the unified interface): the central claim that wrapping AmgX yields a true JAX primitive supporting JIT, reverse-mode AD via adjoints, batched solves, and MPI distribution without correctness or performance regressions lacks any description of custom_op registration, VJP definition (e.g., whether adjoints reuse AmgX transpose solves), caching interaction with tracing/differentiation, or MPI rank mapping to device_put/pmap. This information is load-bearing for assessing the stated compatibility.
Simulated Author's Rebuttal
We thank the referee for the careful review and the identification of areas where the abstract could better support its central claims. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph describing the unified interface): the central claim that wrapping AmgX yields a true JAX primitive supporting JIT, reverse-mode AD via adjoints, batched solves, and MPI distribution without correctness or performance regressions lacks any description of custom_op registration, VJP definition (e.g., whether adjoints reuse AmgX transpose solves), caching interaction with tracing/differentiation, or MPI rank mapping to device_put/pmap. This information is load-bearing for assessing the stated compatibility.
Authors: We agree that the abstract, as written, is high-level and does not enumerate the low-level JAX mechanisms. The manuscript body (Sections 3.1–3.3) details the registration of AmgX solvers via jax.custom_vjp, the VJP rule that invokes AmgX transpose solves for the adjoint, the cache design that remains transparent to tracing, and the use of device_put/pmap for MPI rank-to-device mapping. These sections also report verification that the resulting primitives preserve correctness and do not introduce performance regressions relative to direct AmgX calls. To make the abstract self-contained, we will add one sentence referencing the custom-operation and adjoint construction. We believe this addresses the referee’s concern without altering the abstract’s length or tone. revision: yes
Circularity Check
No circularity: software wrapper library with no derivation chain
full rationale
This is a software engineering paper describing a JAX wrapper around the external AmgX library. It makes no mathematical claims, derives no equations, fits no parameters, and presents no predictions that could reduce to inputs by construction. The contribution is the integration itself (unified interface, JIT/AD/MPI compatibility via custom primitives and caching). No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing steps. The reader's assessment of score 0.0 is correct; this is the expected outcome for a non-derivational library paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Nvidia AmgX correctly implements AMG and Krylov methods and exposes a usable C++ API
Reference graph
Works this paper leans on
-
[1]
J. H. Ferziger, M. Perić, R. L. Street, Computational Methods for Fluid Dynamics, Springer Nature Switzerland AG, Cham, Switzerland, 2020
2020
-
[2]
M.N.Özişik, H.R.Orlande, M.J.Colaço, R.M.Cotta, FiniteDifference Methods in Heat Transfer, CRC Press, Boca Raton, FL, USA, 2017
2017
-
[3]
T. J. R. Hughes, The Finite Element Method: Linear Static and Dy- namic Finite Element Analysis, Dover Publications, Mineola, NY, USA, 2000. 14
2000
-
[4]
Jin, The Finite Element Method in Electromagnetics, John Wiley & Sons, Hoboken, NJ, USA, 2014
J.-M. Jin, The Finite Element Method in Electromagnetics, John Wiley & Sons, Hoboken, NJ, USA, 2014
2014
-
[5]
Bradbury, R
J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman- Milne, Q. Zhang, JAX: composable transformations of Python+NumPy programs (2018). URLhttps://github.com/jax-ml/jax
2018
-
[6]
Stüben, A review of algebraic multigrid, Journal of Computational and Applied Mathematics 128 (1) (2001) 281–309.doi:10.1016/ S0377-0427(00)00516-1
K. Stüben, A review of algebraic multigrid, Journal of Computational and Applied Mathematics 128 (1) (2001) 281–309.doi:10.1016/ S0377-0427(00)00516-1
2001
-
[7]
N. Bell, L. N. Olson, J. Schroder, B. Southworth, PyAMG: Algebraic multigrid solvers in Python, Journal of Open Source Software 8 (87) (2023) 5495.doi:10.21105/joss.05495
-
[8]
Srinath, Pyamgx: Python interface to NVIDIA’s AMGX library
A. Srinath, Pyamgx: Python interface to NVIDIA’s AMGX library. URLhttps://github.com/shwina/pyamgx
-
[9]
L. Dalcin, P. Kler, R. Paz, A. Cosimo, Parallel distributed computing using Python, Advances in Water Resources 34 (9) (2011) 1124–1139. doi:10.1016/j.advwatres.2011.04.013
-
[10]
J. Rader, T. Lyons, P. Kidger, Lineax: unified linear solves and lin- ear least-squares in JAX and Equinox, arXiv preprint arXiv:2311.17283 (2023).doi:10.48550/arXiv.2311.17283
-
[11]
M. Naumov, M. Arsaev, P. Castonguay, J. Cohen, J. Demouth, J. Eaton, S. Layton, N. Markovskiy, I. Reguly, N. Sakharnykh, V. Sellappan, R. Strzodka, AmgX: A library for GPU accelerated algebraic multi- grid and preconditioned iterative methods, SIAM Journal on Scientific Computing 37 (5) (2015) S602–S626.doi:10.1137/140980260
-
[12]
A. R. Curtis, M. J. D. Powell, J. K. Reid, On the estimation of sparse Jacobian matrices, IMA Journal of Applied Mathematics 13 (1) (1974) 117–119.doi:10.1093/imamat/13.1.117
-
[13]
A. H. Gebremedhin, F. Manne, A. Pothen, What color is your Jacobian? Graph coloring for computing derivatives, SIAM Review 47 (4) (2005) 629–705.doi:10.1137/S0036144504444711
-
[14]
D. Häfner, F. Vicentini, mpi4jax: Zero-copy MPI communication of JAX arrays, Journal of Open Source Software 6 (65) (2021) 3419.doi: 10.21105/joss.03419. 15
-
[15]
X. Fan, X.-Y. Liu, M. Wang, J.-X. Wang, Diff-FlowFSI: A GPU- optimized differentiable CFD platform for high-fidelity turbulence and FSI simulations, Computer Methods in Applied Mechanics and Engi- neering 448 (2026) 118455.doi:10.1016/j.cma.2025.118455
-
[16]
R. Newbury, J. Collins, K. He, J. Pan, I. Posner, D. Howard, A. Cosgun, A review of differentiable simulators, IEEE Access 12 (2024) 97581– 97604.doi:10.1109/ACCESS.2024.3425448
-
[17]
T. Xue, S. Liao, Z. Gan, C. Park, X. Xie, W. K. Liu, J. Cao, JAX-FEM: A differentiable GPU-accelerated 3D finite element solver for automatic inverse design and mechanistic data science, Computer Physics Com- munications 291 (2023) 108802.doi:10.1016/j.cpc.2023.108802
-
[18]
Machine learning ⚶accelerated computational fluid dynamics
D. Kochkov, J. A. Smith, A. Alieva, Q. Wang, M. P. Brenner, S. Hoyer, Machine learning–accelerated computational fluid dynamics, Proceed- ings of the National Academy of Sciences 118 (21) (2021).doi: 10.1073/pnas.2101784118
-
[19]
W. Shang, J. Zhou, J. Panda, Z. Xu, Y. Liu, P. Du, J.-X. Wang, T. Luo, JAX-BTE: a GPU-accelerated differentiable solver for phonon Boltz- mann transport equations, npj Computational Materials 11 (1) (2025) 129.doi:10.1038/s41524-025-01635-0. 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.