ATTAIN: Automated Exploit Failure Analysis through Trace-Driven Diff Analysis
Pith reviewed 2026-06-27 15:56 UTC · model grok-4.3
The pith
ATTAIN determines which library versions contain a vulnerability by tracing exploit executions and guiding LLM searches over code diffs even when the exploit fails to run.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ATTAIN is a three-module framework that first constructs cross-version execution traces to surface behavioral divergences, then uses those divergences to drive an LLM through a finite-state tool loop that autonomously collects vulnerability-relevant diff hunks, and finally reasons over the evidence to output the range of affected library versions.
What carries the argument
Trace-driven diff analysis that converts execution divergences into guidance for an LLM tool loop to retrieve relevant code changes across library versions.
If this is right
- ATTAIN produces more accurate affected-version ranges than commit-based methods such as V-SZZ and LLM4SZZ on the evaluated dataset.
- The framework maintains performance on frequent CWE categories even when exploit runs fail for non-vulnerability reasons.
- Token consumption stays low because the method uses short prompts and a fixed iteration count.
- The same approach can be applied to any library with available historical versions and an exploit script.
Where Pith is reading between the lines
- The divergence-guided search pattern could be reused for tasks such as identifying API-breaking changes without an exploit.
- Extending the trace construction module to record additional runtime signals might improve precision when multiple unrelated changes occur between versions.
- The judgment module could be adapted to produce confidence scores rather than binary affected/unaffected decisions for downstream triage tools.
Load-bearing premise
Execution divergences observed when an exploit runs on different versions will reliably indicate the vulnerability cause rather than unrelated API or environment shifts.
What would settle it
A set of CVEs where the exploit fails on some versions solely because of non-vulnerability API changes, with ground-truth labels showing whether ATTAIN still marks the correct versions as affected or unaffected.
Figures
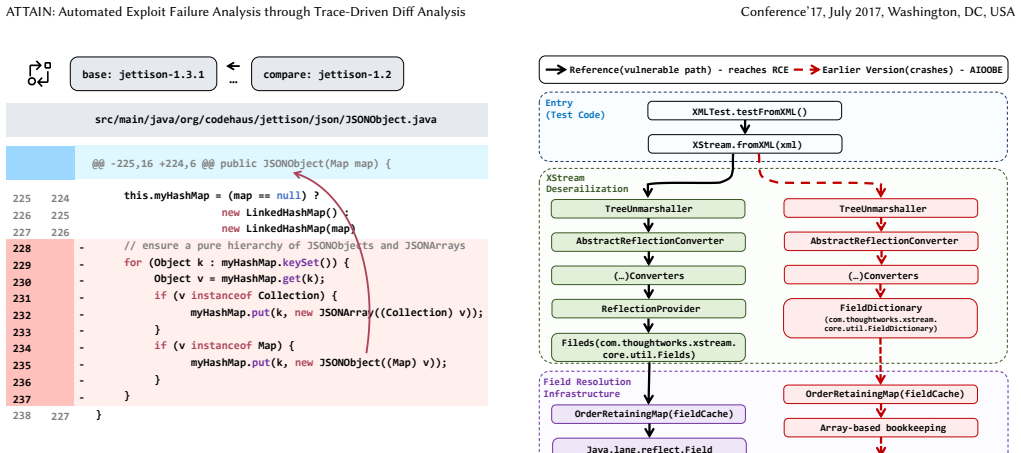

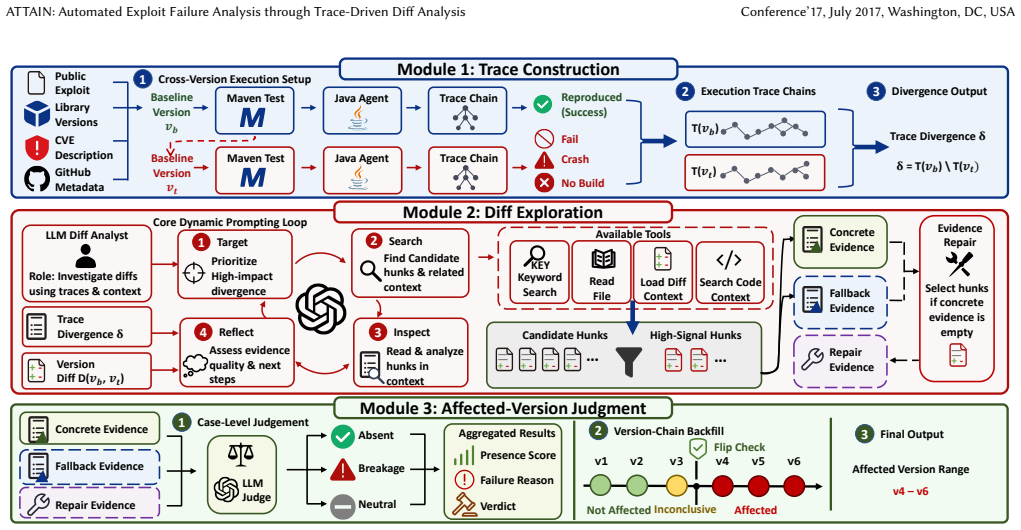



read the original abstract
Exploits are widely used to check whether library vulnerabilities appear in different versions and to mark affected version ranges. Exploit-based checks sometimes fail because exploits stop running on many versions after API or environment changes. Commit-based methods, such as SZZ-style analysis, sometimes miss the right introduce commits and spread labels incorrectly along long version chains. These problems leave many affected versions unlabeled or wrongly labeled and make manual exploit failure analysis very expensive and impractical at scale. We present ATTAIN, a trace-driven diff analysis framework with three modules to assess vulnerability presence across evolving library versions. The modules are trace construction, diff exploration, and affected-version judgment. The trace construction module executes an exploit across historical library versions and compares their behaviors to capture cross-version execution divergences. Using these divergences, the diff exploration module guides an LLM through a finite-state tool loop to autonomously search over version changes and collect vulnerability-relevant diff hunks. The affected-version judgment module reasons over the collected evidence to determine whether the vulnerability exists in each version and outputs the affected version range. We evaluate ATTAIN on an extensive dataset comprising 224 CVEs and 25,943 library versions across 128 libraries. ATTAIN achieves an F1-score of 93.24%, outperforming the commit-based methods V-SZZ and LLM4SZZ by 116.28% and 33.30%, respectively. ATTAIN uses short tool-guided prompts and a fixed number of iterations, keeping token usage low. It matches or surpasses existing methods on frequent CWE types, including cases where exploit runs fail for non-vulnerability reasons or commit messages do not clearly delimit affected versions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ATTAIN, a three-module framework (trace construction via cross-version exploit execution, LLM-guided diff exploration over execution divergences, and affected-version judgment) for determining vulnerability presence in library versions when exploits fail due to non-vulnerability causes such as API or environment changes. On a dataset of 224 CVEs and 25,943 library versions across 128 libraries, it reports an F1-score of 93.24%, outperforming V-SZZ by 116.28% and LLM4SZZ by 33.30%.
Significance. If the end-to-end pipeline is shown to isolate vulnerability-relevant changes without being misled by orthogonal divergences, the approach could automate scalable analysis of exploit failures and improve labeling accuracy over both exploit-based checks and commit-based SZZ variants, particularly for frequent CWE types.
major comments (2)
- [Evaluation (abstract and §5)] Evaluation (abstract and §5): the reported F1-score of 93.24% and relative improvements are presented without any description of dataset construction, filtering of non-vulnerability exploit failures, evaluation protocol, ground-truth labeling process, or statistical significance tests, so the central performance claim cannot be verified from the supplied information.
- [Diff exploration module (§4.2)] Diff exploration module (§4.2): the claim that LLM-guided search over trace divergences reliably surfaces vulnerability-relevant hunks even when failures stem from unrelated API or dependency changes is load-bearing for the F1 result, yet no ablation, error analysis, or robustness test is described to show that the tool loop is not misled by orthogonal divergences.
minor comments (2)
- [Abstract] Abstract: the relative improvement figures (116.28% and 33.30%) should be accompanied by absolute baseline F1 values for clarity.
- [Evaluation] The paper states that ATTAIN uses short prompts and a fixed iteration count to keep token usage low, but no quantitative token or cost numbers are supplied to support this claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will revise the manuscript to incorporate the requested details and analyses.
read point-by-point responses
-
Referee: [Evaluation (abstract and §5)] Evaluation (abstract and §5): the reported F1-score of 93.24% and relative improvements are presented without any description of dataset construction, filtering of non-vulnerability exploit failures, evaluation protocol, ground-truth labeling process, or statistical significance tests, so the central performance claim cannot be verified from the supplied information.
Authors: We agree that the abstract and Section 5 currently present results at a high level without sufficient supporting detail on dataset construction, filtering criteria, evaluation protocol, ground-truth labeling, and statistical tests. In the revised manuscript we will expand Section 5 with a dedicated subsection describing: (1) how the 224 CVEs and 25,943 versions across 128 libraries were assembled, (2) the filtering rules applied to exclude non-vulnerability exploit failures, (3) the precise evaluation protocol and metrics, (4) the ground-truth labeling process, and (5) any statistical significance tests performed on the reported improvements. These additions will make the central claims verifiable. revision: yes
-
Referee: [Diff exploration module (§4.2)] Diff exploration module (§4.2): the claim that LLM-guided search over trace divergences reliably surfaces vulnerability-relevant hunks even when failures stem from unrelated API or dependency changes is load-bearing for the F1 result, yet no ablation, error analysis, or robustness test is described to show that the tool loop is not misled by orthogonal divergences.
Authors: We concur that demonstrating the diff exploration module is not misled by orthogonal divergences is essential. The current manuscript describes the LLM-guided tool loop but does not include ablations or targeted analyses. In revision we will add: (a) an ablation comparing the full guided loop against a non-guided baseline and against reduced iteration counts, (b) an error analysis of cases involving API or dependency changes that produce orthogonal divergences, and (c) robustness tests measuring how often vulnerability-relevant hunks are still surfaced under controlled orthogonal noise. These will be reported in a new subsection of §4 or §5. revision: yes
Circularity Check
No circularity: independent empirical pipeline on external CVE dataset
full rationale
The paper describes a three-module analysis framework (trace construction, LLM-guided diff exploration, judgment) evaluated empirically on 224 CVEs and 25,943 versions. No equations, fitted parameters, self-definitional relations, or load-bearing self-citations appear in the derivation or claims. The F1 result is a direct measurement against ground-truth labels, not a re-expression of inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nadia Alshahwan, Jubin Chheda, Anastasia Finogenova, Beliz Gokkaya, Mark Harman, Inna Harper, Alexandru Marginean, Shubho Sengupta, and Eddy Wang
-
[2]
Automated Unit Test Improvement using Large Language Models at Meta. InCompanion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering(Porto de Galinhas, Brazil)(FSE 2024). Association for Computing Machinery, New York, NY, USA, 185–196. doi:10.1145/3663529.3663839
-
[3]
Lingfeng Bao, Xin Xia, Ahmed E. Hassan, and Xiaohu Yang. 2022. V-SZZ: au- tomatic identification of version ranges affected by CVE vulnerabilities. InPro- ceedings of the 44th International Conference on Software Engineering(Pittsburgh, Pennsylvania)(ICSE ’22). Association for Computing Machinery, New York, NY, USA, 2352–2364. doi:10.1145/3510003.3510113
-
[4]
Gabriele Bavota, Gerardo Canfora, Massimiliano Di Penta, Rocco Oliveto, and Sebastiano Panichella. 2015. How the apache community upgrades dependencies: an evolutionary study.Empirical Software Engineering20 (2015), 1275–1317
2015
-
[5]
Zirui Chen, Xing Hu, Puhua Sun, Xin Xia, and Xiaohu Yang. 2025. Generating Mit- igations for Downstream Projects to Neutralize Upstream Library Vulnerability. arXiv:2503.24273 [cs.SE] https://arxiv.org/abs/2503.24273
arXiv 2025
-
[6]
Zirui Chen, Xing Hu, Xin Xia, Yi Gao, Tongtong Xu, David Lo, and Xiaohu Yang
-
[8]
Zirui Chen, Zhipeng Xue, Jiayuan Zhou, Xing Hu, Xin Xia, and Xiaohu Yang. 2025. Diffploit: Facilitating Cross-Version Exploit Migration for Open Source Library Vulnerabilities. arXiv:2511.12950 [cs.SE] https://arxiv.org/abs/2511.12950
arXiv 2025
-
[9]
Zirui Chen, Qi Zhan, Jiayuan Zhou, Xing Hu, Xin Xia, and Xiaohu Yang. 2026. A Large-scale Empirical Study on the Generalizability of Disclosed Java Library Vulnerability Exploits. arXiv:2603.25997 [cs.SE] https://arxiv.org/abs/2603.25997
arXiv 2026
-
[10]
Yiran Cheng, Ting Zhang, Lwin Khin Shar, Shouguo Yang, Chaopeng Dong, David Lo, Shichao Lv, Zhiqiang Shi, and Limin Sun. 2025. VERCATION: Precise Vulnerable Open-source Software Version Identification based on Static Analysis and LLM.IEEE Transactions on Software Engineering(2025)
2025
-
[11]
Representthemall: A universal learning representation of bug reports
Roland Croft, M. Ali Babar, and M. Mehdi Kholoosi. 2023. Data Quality for Soft- ware Vulnerability Datasets. InProceedings of the 45th International Conference on Software Engineering(Melbourne, Victoria, Australia)(ICSE ’23). IEEE Press, 121–133. doi:10.1109/ICSE48619.2023.00022
-
[12]
Barthélémy Dagenais and Martin P Robillard. 2011. Recommending adaptive changes for framework evolution.ACM Transactions on Software Engineering and Methodology (TOSEM)20, 4 (2011), 1–35
2011
-
[13]
Jiarun Dai, Yuan Zhang, Hailong Xu, Haiming Lyu, Zicheng Wu, Xinyu Xing, and Min Yang. 2021. Facilitating Vulnerability Assessment through PoC Migration. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security(Virtual Event, Republic of Korea)(CCS ’21). Association for Computing Machinery, New York, NY, USA, 3300–3317. doi...
-
[14]
Danny Dig and Ralph Johnson. 2006. How do APIs evolve? A story of refactoring. Journal of software maintenance and evolution: Research and Practice18, 2 (2006), 83–107
2006
-
[15]
Ying Dong, Wenbo Guo, Yueqi Chen, Xinyu Xing, Yuqing Zhang, and Gang Wang
-
[16]
InProceedings of the 28th USENIX Conference on Security Symposium (Santa Clara, CA, USA)(SEC’19)
Towards the detection of inconsistencies in public security vulnerability reports. InProceedings of the 28th USENIX Conference on Security Symposium (Santa Clara, CA, USA)(SEC’19). USENIX Association, USA, 869–885
-
[17]
Yi Gao, Xing Hu, Tongtong Xu, Jiali Zhao, Xiaohu Yang, and Xin Xia. 2026. DepRadar: Agentic Coordination for Context Aware Defect Impact Analysis in Deep Learning Libraries. arXiv:2601.09440 [cs.SE] https://arxiv.org/abs/2601. 09440
arXiv 2026
-
[18]
Yi Gao, Xing Hu, Xiaohu Yang, and Xin Xia. 2025. Automated unit test refactoring. Proceedings of the ACM on Software Engineering2, FSE (2025), 713–733
2025
-
[19]
Luca Gazzola, Daniela Micucci, and Leonardo Mariani. 2018. Automatic software repair: A survey. InProceedings of the 40th International Conference on Software Engineering. 1219–1219
2018
-
[20]
Konstantin Grotov, Sergey Titov, Yaroslav Zharov, and Timofey Bryksin. 2024. Untangling Knots: Leveraging LLM for Error Resolution in Computational Note- books. arXiv:2405.01559 [cs.SE] https://arxiv.org/abs/2405.01559
arXiv 2024
-
[21]
Runzhi He, Hao He, Yuxia Zhang, and Minghui Zhou. 2023. Automating Depen- dency Updates in Practice: An Exploratory Study on GitHub Dependabot.IEEE Trans. Softw. Eng.49, 8 (Aug. 2023), 4004–4022. doi:10.1109/TSE.2023.3278129
-
[22]
Yongzhong He, Yiming Wang, Sencun Zhu, Wei Wang, Yunjia Zhang, Qiang Li, and Aimin Yu. 2024. Automatically Identifying CVE Affected Versions With Patches and Developer Logs.IEEE Transactions on Dependable and Secure Com- puting21, 2 (2024), 905–919. doi:10.1109/TDSC.2023.3264567
-
[23]
Zhiyuan Jiang, Shuitao Gan, Adrian Herrera, Flavio Toffalini, Lucio Romerio, Chaojing Tang, Manuel Egele, Chao Zhang, and Mathias Payer. 2022. Evocatio: Conjuring Bug Capabilities from a Single PoC. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security(Los Angeles, CA, USA)(CCS ’22). Association for Computing Machinery, N...
-
[24]
Zheyue Jiang, Yuan Zhang, Jun Xu, Xinqian Sun, Zhuang Liu, and Min Yang
-
[25]
AEM: Facilitating Cross-Version Exploitability Assessment of Linux Kernel Vulnerabilities. In2023 IEEE Symposium on Security and Privacy (SP). 2122–2137. doi:10.1109/SP46215.2023.10179286
-
[26]
Hyeonseong Jo, Jinwoo Kim, Phillip Porras, Vinod Yegneswaran, and Seungwon Shin. 2021. GapFinder: Finding Inconsistency of Security Information From Unstructured Text.IEEE Transactions on Information Forensics and Security16 (2021), 86–99. doi:10.1109/TIFS.2020.3003570
-
[27]
Seulbae Kim, Seunghoon Woo, Heejo Lee, and Hakjoo Oh. 2017. Vuddy: A scalable approach for vulnerable code clone discovery. In2017 IEEE symposium on security and privacy (SP). IEEE, 595–614
2017
-
[29]
Raula Gaikovina Kula, Daniel M German, Ali Ouni, Takashi Ishio, and Katsuro Inoue. 2018. Do developers update their library dependencies? An empirical study on the impact of security advisories on library migration.Empirical Software Engineering23 (2018), 384–417
2018
-
[30]
Jia Li, Zhuo Li, Huangzhao Zhang, Ge Li, Zhi Jin, Xing Hu, and Xin Xia
-
[31]
arXiv:2210.17029 [cs.SE] https://arxiv.org/abs/2210.17029
Poison Attack and Defense on Deep Source Code Processing Models. arXiv:2210.17029 [cs.SE] https://arxiv.org/abs/2210.17029
-
[32]
Siyuan Li, Yongpan Wang, Chaopeng Dong, Shouguo Yang, Hong Li, Hao Sun, Zhe Lang, Zuxin Chen, Weijie Wang, Hongsong Zhu, and Limin Sun. 2023. LibAM: An Area Matching Framework for Detecting Third-Party Libraries in Binaries.ACM Trans. Softw. Eng. Methodol.33, 2, Article 52 (Dec. 2023), 35 pages. doi:10.1145/3625294
-
[33]
Xiangyu Li, Marcelo d’Amorim, and Alessandro Orso. 2019. Intent-Preserving Test Repair . In2019 12th IEEE Conference on Software Testing, Validation and Verification (ICST). IEEE Computer Society, Los Alamitos, CA, USA, 217–227. doi:10.1109/ICST.2019.00030
-
[34]
Zhen Li, Deqing Zou, Shouhuai Xu, Hai Jin, Hanchao Qi, and Jie Hu. 2016. Vulpecker: an automated vulnerability detection system based on code similar- ity analysis. InProceedings of the 32nd annual conference on computer security applications. 201–213
2016
-
[35]
Zhen Li, Deqing Zou, Shouhuai Xu, Hai Jin, Yawei Zhu, and Zhaoxuan Chen. 2021. Sysevr: A framework for using deep learning to detect software vulnerabilities. IEEE Transactions on Dependable and Secure Computing19, 4 (2021), 2244–2258
2021
-
[36]
Zhen Li, Deqing Zou, Shouhuai Xu, Xinyu Ou, Hai Jin, Sujuan Wang, Zhijun Deng, and Yuyi Zhong. 2018. Vuldeepecker: A deep learning-based system for vulnerability detection.arXiv preprint arXiv:1801.01681(2018)
Pith/arXiv arXiv 2018
-
[37]
Shuhan Liu, Jiayuan Zhou, Xing Hu, Filipe Roseiro Cogo, Xin Xia, and Xiaohu Yang. 2025. An Empirical Study on Vulnerability Disclosure Management of Open Source Software Systems.ACM Trans. Softw. Eng. Methodol.34, 7, Article 214 (Aug. 2025), 31 pages. doi:10.1145/3716822
-
[38]
Looly. [n. d.].Introducing Commit of CVE-2023-51080. https://github.com/ chinabugotech/hutool/commit/c45b3f
2023
-
[39]
Xinwei Mao. 2026. ATTAIN: Automated Exploit Failure Analysis through Trace-Driven Diff Analysis. GitHub repository. https://github.com/Cirno-9- lab/ATTAIN_REPLICATION
2026
-
[40]
Dongliang Mu, Alejandro Cuevas, Limin Yang, Hang Hu, Xinyu Xing, Bing Mao, and Gang Wang. 2018. Understanding the reproducibility of crowd-reported security vulnerabilities. InProceedings of the 27th USENIX Conference on Security Symposium(Baltimore, MD, USA)(SEC’18). USENIX Association, USA, 919–936
2018
-
[41]
Viet Hung Nguyen, Stanislav Dashevskyi, and Fabio Massacci. 2016. An automatic method for assessing the versions affected by a vulnerability.Empirical Software Engineering21, 6 (2016), 2268–2297
2016
-
[42]
Viet Hung Nguyen and Fabio Massacci. 2013. The (un) reliability of nvd vulnerable versions data: An empirical experiment on google chrome vulnerabilities. In Proceedings of the 8th ACM SIGSAC symposium on Information, computer and communications security. 493–498
2013
-
[43]
Shengyi Pan, Lingfeng Bao, Xin Xia, David Lo, and Shanping Li. 2023. Fine- grained Commit-level Vulnerability Type Prediction by CWE Tree Structure. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). 957–969. doi:10.1109/ICSE48619.2023.00088
-
[44]
Shengyi Pan, Lingfeng Bao, Jiayuan Zhou, Xing Hu, Xin Xia, and Shanping Li. 2024. Towards More Practical Automation of Vulnerability Assessment. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering (Lisbon, Portugal)(ICSE ’24). Association for Computing Machinery, New York, NY, USA, Article 148, 13 pages. doi:10.1145/359750...
-
[45]
Shengyi Pan, Jiayuan Zhou, Filipe Roseiro Cogo, Xin Xia, Lingfeng Bao, Xing Hu, Shanping Li, and Ahmed E. Hassan. 2022. Automated unearthing of dangerous issue reports. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering(Singapore, Singapore)(ESEC/FSE 2022). Association for ...
-
[46]
Henning Perl, Sergej Dechand, Matthew Smith, Daniel Arp, Fabian Yamaguchi, Konrad Rieck, Sascha Fahl, and Yasemin Acar. 2015. Vccfinder: Finding potential vulnerabilities in open-source projects to assist code audits. InProceedings of the 22nd ACM SIGSAC conference on computer and communications security. 426–437
2015
-
[47]
Shanto Rahman, Sachit Kuhar, Berk Cirisci, Pranav Garg, Shiqi Wang, Xiaofei Ma, Anoop Deoras, and Baishakhi Ray. 2025. UTFix: Change Aware Unit Test Repairing using LLM.Proc. ACM Program. Lang.9, OOPSLA1, Article 85 (April 2025), 26 pages. doi:10.1145/3720419
-
[48]
Shanto Rahman and August Shi. 2024. FlakeSync: Automatically Repairing Async Flaky Tests. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering(Lisbon, Portugal)(ICSE ’24). Association for Computing Machinery, New York, NY, USA, Article 136, 12 pages. doi:10.1145/3597503. 3639115
-
[49]
Ahmadreza Saboor Yaraghi, Darren Holden, Nafiseh Kahani, and Lionel Briand
-
[50]
Automated Test Case Repair Using Language Models.IEEE Trans. Softw. Eng.51, 4 (Feb. 2025), 1104–1133. doi:10.1109/TSE.2025.3541166
-
[51]
Youkun Shi, Yuan Zhang, Tianhan Luo, Xiangyu Mao, and Min Yang. 2022. Precise (un) affected version analysis for web vulnerabilities. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 1–13
2022
-
[52]
Jacek Śliwerski, Thomas Zimmermann, and Andreas Zeller. 2005. When do changes induce fixes?ACM sigsoft software engineering notes30, 4 (2005), 1–5
2005
-
[53]
Synopsys. [n. d.].OPEN SOURCE SECURITY AND RISK ANALYSIS REPORT
-
[54]
https://www.synopsys.com/software-integrity/resources/analyst-reports/ open-source-security-risk-analysis.html
-
[55]
Lingxiao Tang, Jiakun Liu, Zhongxin Liu, Xiaohu Yang, and Lingfeng Bao. 2025. LLM4SZZ: Enhancing szz algorithm with context-enhanced assessment on large language models.Proceedings of the ACM on Software Engineering2, ISSTA (2025), 343–365
2025
-
[56]
Gladys Tyen, Hassan Mansoor, Victor Cărbune, Peter Chen, and Tony Mak. 2024. LLMs cannot find reasoning errors, but can correct them given the error location. arXiv:2311.08516 [cs.AI] https://arxiv.org/abs/2311.08516
arXiv 2024
-
[57]
Seunghoon Woo, Eunjin Choi, Heejo Lee, and Hakjoo Oh. 2023. {V1SCAN}: Discovering 1-day vulnerabilities in reused {C/C++} open-source software com- ponents using code classification techniques. In32nd USENIX Security Symposium (USENIX Security 23). 6541–6556
2023
-
[58]
Seunghoon Woo, Hyunji Hong, Eunjin Choi, and Heejo Lee. 2022. {MOVERY}: A precise approach for modified vulnerable code clone discovery from modi- fied {Open-Source} software components. In31st USENIX Security Symposium (USENIX Security 22). 3037–3053
2022
-
[59]
Seunghoon Woo, Dongwook Lee, Sunghan Park, Heejo Lee, and Sven Dietrich
-
[60]
In30th USENIX Security Symposium (USENIX Security 21)
{V0Finder}: Discovering the correct origin of publicly reported software vulnerabilities. In30th USENIX Security Symposium (USENIX Security 21). 3041– 3058
-
[61]
Susheng Wu, Ruisi Wang, Kaifeng Huang, Yiheng Cao, Wenyan Song, Zhuotong Zhou, Yiheng Huang, Bihuan Chen, and Xin Peng. 2024. Vision: Identifying Affected Library Versions for Open Source Software Vulnerabilities. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (Sacramento, CA, USA)(ASE ’24). Association for C...
-
[62]
Yang Xiao, Bihuan Chen, Chendong Yu, Zhengzi Xu, Zimu Yuan, Feng Li, Binghong Liu, Yang Liu, Wei Huo, Wei Zou, et al . 2020. {MVP}: Detecting vulnerabilities using {Patch-Enhanced} vulnerability signatures. In29th USENIX Security Symposium (USENIX Security 20). 1165–1182
2020
-
[63]
Zhipeng Xue, Zhipeng Gao, Shaohua Wang, Xing Hu, Xin Xia, and Shanping Li
-
[64]
SelfPiCo: Self-Guided Partial Code Execution with LLMs. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis (Vienna, Austria)(ISSTA 2024). Association for Computing Machinery, New York, NY, USA, 1389–1401. doi:10.1145/3650212.3680368
-
[65]
Zhipeng Xue, Xiaoting Zhang, Zhipeng Gao, Xing Hu, Shan Gao, Xin Xia, and Shanping Li. 2026. Clean Code, Better Models: Enhancing LLM Performance with Smell-Cleaned Dataset.ACM Trans. Softw. Eng. Methodol.(Feb. 2026). doi:10. 1145/3793252 Just Accepted
2026
-
[66]
Xiao Yu, Lei Liu, Xing Hu, Jin Liu, and Xin Xia. 2025. Where Is Self-admitted Code Generated by Large Language Models on GitHub? arXiv:2406.19544 [cs.SE] https://arxiv.org/abs/2406.19544
arXiv 2025
-
[67]
Qi Zhan, Xing Hu, Zhiyang Li, Xin Xia, David Lo, and Shanping Li. 2024. PS3: Precise Patch Presence Test based on Semantic Symbolic Signature. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering(Lisbon, Portugal)(ICSE ’24). Association for Computing Machinery, New York, NY, USA, Article 167, 12 pages. doi:10.1145/3597503.3639134
-
[68]
Qi Zhan, Xing Hu, Xin Xia, and Shanping Li. 2024. REACT: IR-Level Patch Presence Test for Binary. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering(Sacramento, CA, USA)(ASE ’24). Association for Computing Machinery, New York, NY, USA, 381–392. doi:10. 1145/3691620.3695012
arXiv 2024
-
[69]
Jiayuan Zhou, Michael Pacheco, Jinfu Chen, Xing Hu, Xin Xia, David Lo, and Ahmed E. Hassan. 2023. CoLeFunDa: Explainable Silent Vulnerability Fix Iden- tification. InProceedings of the 45th International Conference on Software En- gineering(Melbourne, Victoria, Australia)(ICSE ’23). IEEE Press, 2565–2577. doi:10.1109/ICSE48619.2023.00214
-
[70]
Jiayuan Zhou, Michael Pacheco, Zhiyuan Wan, Xin Xia, David Lo, Yuan Wang, and Ahmed E. Hassan. 2022. Finding a needle in a haystack: automated mining of silent vulnerability fixes. InProceedings of the 36th IEEE/ACM International Conference on Automated Software Engineering(Melbourne, Australia)(ASE ’21). IEEE Press, 705–716. doi:10.1109/ASE51524.2021.9678720
-
[71]
Zhuotong Zhou, Yongzhuo Yang, Susheng Wu, Yiheng Huang, Bihuan Chen, and Xin Peng. 2024. Magneto: A Step-Wise Approach to Exploit Vulnerabilities in Dependent Libraries via LLM-Empowered Directed Fuzzing. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (Sacramento, CA, USA)(ASE ’24). Association for Computing ...
-
[72]
Markus Zimmermann, Cristian-Alexandru Staicu, Cam Tenny, and Michael Pradel
-
[73]
In28th USENIX Security Symposium (USENIX Security 19)
Small World with High Risks: A Study of Security Threats in the npm Ecosystem. In28th USENIX Security Symposium (USENIX Security 19). USENIX Association, Santa Clara, CA, 995–1010
-
[74]
Anni Zou, Wenhao Yu, Hongming Zhang, Kaixin Ma, Deng Cai, Zhuosheng Zhang, Hai Zhao, and Dong Yu. 2024. DOCBENCH: A Benchmark for Evaluating LLM-based Document Reading Systems. arXiv:2407.10701 [cs.CL] https://arxiv. org/abs/2407.10701
arXiv 2024
-
[75]
Xiaochen Zou, Yu Hao, Zheng Zhang, Juefei Pu, Weiteng Chen, and Zhiyun Qian
-
[76]
SyzBridge: Bridging the Gap in Exploitability Assessment of Linux Kernel Bugs in the Linux Ecosystem.NDSS(2024). doi:10.14722/ndss.2024.24926
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.