REFINE: Super-efficient 3D Gaussian Splatting Pruning via Rendering-Free Primitive Importance
Pith reviewed 2026-06-29 05:28 UTC · model grok-4.3
The pith
REFINE prunes 3D Gaussian splatting models with a rendering-free Hessian field that cuts pruning computation by 3000 times while preserving quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
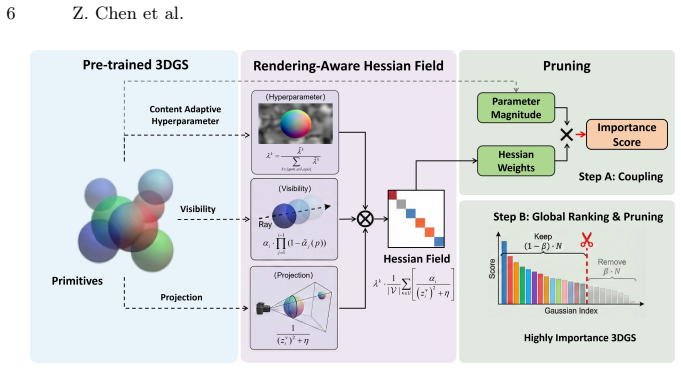
REFINE centers on an analytically approximated, rendering-aware Hessian field that quantifies the expected perceptual error induced by the removal of individual primitives by modeling the joint modulation of visibility, projection geometry and the content adaptive hyperparameter, thereby deriving an anisotropic perceptual weight field that serves as a high-fidelity proxy for primitive importance without any forward rendering passes.
What carries the argument
The analytically approximated rendering-aware Hessian field, which models visibility, projection geometry, and content adaptive hyperparameter together to produce the anisotropic perceptual weight field used as the primitive importance metric.
If this is right
- Pruning-related computational complexity drops by a factor of 3000 compared with prior methods.
- Device latency improves by a factor of approximately 20 over state-of-the-art pruning techniques.
- Rendering quality remains highly competitive with unpruned models across multiple benchmark datasets.
- The entire pruning stage bypasses forward rendering passes.
Where Pith is reading between the lines
- The same Hessian approximation idea could be tested on other point-based or splat-based rendering primitives beyond 3D Gaussians.
- If the metric can be recomputed incrementally, it might support online pruning during scene updates or streaming.
- Hardware-aware tuning of the content adaptive hyperparameter could further reduce latency on specific mobile or embedded platforms.
Load-bearing premise
The analytically approximated Hessian field accurately quantifies the expected perceptual error from removing each primitive.
What would settle it
Run the pruning with the proposed metric, then compare the actual rendered error on held-out views against the error obtained by exhaustive rendering-based importance scoring; a large mismatch between the two would falsify the approximation claim.
Figures



read the original abstract
Existing pruning methods for 3D Gaussian splatting (3DGS) suffer from either severe quality degradation or prohibitive computational overhead. In this paper, we propose REFINE, a highly accelerated 3DGS pruning framework centered on a novel rendering-free primitive importance metric. Our approach leverages an analytically approximated, rendering-aware Hessian field to quantify the expected perceptual error induced by the removal of individual primitives. By modeling the joint modulation of visibility, projection geometry and the content adaptive hyperparameter, we entirely bypass costly forward rendering passes and derive an anisotropic perceptual weight field that serves as a high-fidelity proxy for primitive importance. Extensive experiments across multiple benchmark datasets demonstrate that REFINE maintains highly competitive rendering quality while achieving a $3,000\times$ reduction in pruning-related computational complexity, translating to a practical $\sim 20\times$ speedup in device latency compared to state-of-the-art pruning methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes REFINE, a pruning framework for 3D Gaussian Splatting that introduces a rendering-free primitive importance metric based on an analytically approximated, rendering-aware Hessian field. This metric models the joint effects of visibility, projection geometry, and a content-adaptive hyperparameter to estimate the expected perceptual error from removing individual primitives, thereby avoiding forward rendering passes during pruning. Experiments on benchmark datasets are claimed to show competitive rendering quality alongside a 3,000× reduction in pruning-related computational complexity and an approximately 20× speedup in device latency relative to prior methods.
Significance. If the Hessian-based approximation proves to be a high-fidelity proxy for perceptual error, the work would address a central computational bottleneck in 3DGS pruning and enable more practical deployment on resource-limited hardware. The rendering-free design and reported complexity reduction represent a potentially impactful engineering advance in the field.
major comments (1)
- Abstract: the central claim that the analytically approximated Hessian field 'accurately quantifies the expected perceptual error' and serves as a 'high-fidelity proxy' is stated without any derivation, error bounds, or comparison to ground-truth rendering error; this leaves the soundness of the importance metric unverified from the provided text.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for clearer support of the abstract's claims regarding the Hessian-based importance metric. We address this point below and note that the full manuscript contains the relevant derivations and experiments.
read point-by-point responses
-
Referee: Abstract: the central claim that the analytically approximated Hessian field 'accurately quantifies the expected perceptual error' and serves as a 'high-fidelity proxy' is stated without any derivation, error bounds, or comparison to ground-truth rendering error; this leaves the soundness of the importance metric unverified from the provided text.
Authors: The abstract summarizes the core contribution at a high level. The analytical approximation of the rendering-aware Hessian field—including explicit modeling of visibility, projection geometry, and the content-adaptive hyperparameter—is derived step-by-step in Section 3, with the resulting anisotropic perceptual weight field shown to estimate expected error from primitive removal. Section 4 provides direct empirical comparisons of the metric against ground-truth rendering error on benchmark datasets, confirming competitive quality retention. Formal error bounds on the approximation are not derived because the metric is positioned as a practical, rendering-free proxy rather than a theoretically bounded estimator; its validity is instead substantiated through the extensive quality and complexity experiments. We can revise the abstract to reference Section 3 for the derivation if the referee prefers. revision: partial
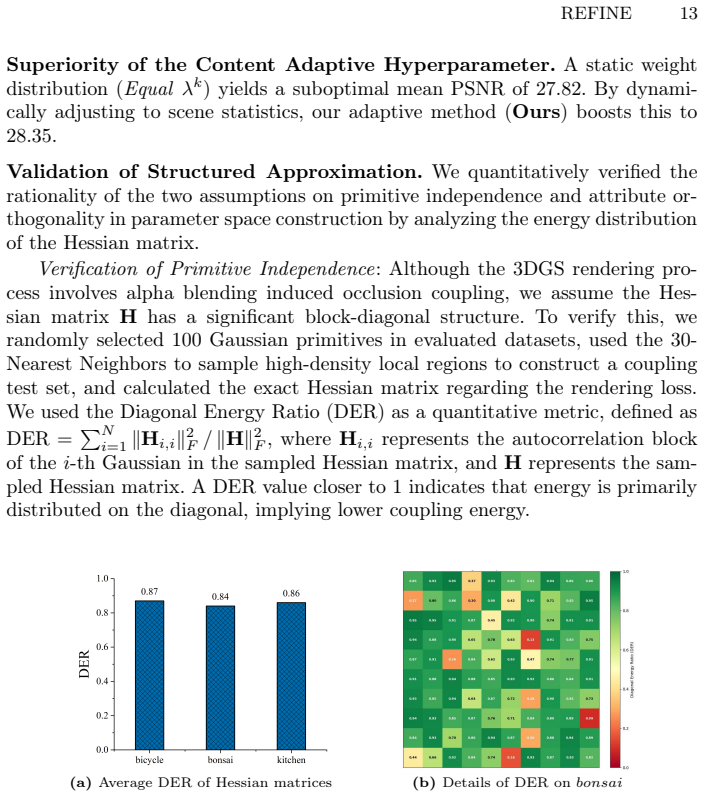
Circularity Check
No significant circularity identified
full rationale
The provided abstract and context describe a rendering-free importance metric derived from an analytically approximated Hessian field that models visibility, projection geometry, and hyperparameters. No equations, derivations, or self-citations are shown that reduce the metric to a fitted quantity defined by the same data, a self-citation chain, or an ansatz smuggled via prior work. The derivation appears self-contained against external benchmarks with independent content, consistent with the reader's assessment of no indication that the importance metric reduces to a fitted quantity. Full manuscript inspection would be needed for deeper verification, but nothing in the given text triggers any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Winter Conf
Ali, M.S., Bae, S.H., Tartaglione, E.: ElmGS: Enhancing memory and computation scalability through compression for 3D Gaussian splatting. In: Winter Conf. Appl. Comput. Vis. pp. 2591–2600 (2025)
2025
-
[2]
In: BMVC (2024) REFINE 15
Ali, M.S., Qamar, M., Bae, S.H., Tartaglione, E.: Trimming the fat: Efficient com- pression of 3D Gaussian splats through pruning. In: BMVC (2024) REFINE 15
2024
-
[3]
In: CVPR
Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Mip-NeRF 360: Unbounded anti-aliased neural radiance fields. In: CVPR. pp. 5470–5479 (2022)
2022
-
[4]
In: NeurIPS
Chen, J., Li, Z., Cai, Y., Jiang, H., Qian, C., Kang, J., Gao, S., Zhao, H., Mao, T., Zhang, Y.: HAIF-GS: Hierarchical and induced flow-guided Gaussian splatting for dynamic scene. In: NeurIPS. vol. 38, pp. 125539–125563 (2025)
2025
-
[5]
In: AAAI
Chen, Y., Li, M., Wu, Q., Lin, W., Harandi, M., Cai, J.: PCGS: Progressive com- pression of 3D Gaussian splatting. In: AAAI. vol. 40, pp. 3111–3119 (2026)
2026
-
[6]
In: ICLR
Chen, Y., Wu, Q., Li, M., Lin, W., Harandi, M., Cai, J.: Fast feedforward 3D Gaussian splatting compression. In: ICLR. vol. 2025, pp. 74859–74872 (2025)
2025
-
[7]
IEEE TCSVT (2026)
Chen, Y., Wu, Q., Li, M., Lin, W., Hou, J., Harandi, M., Cai, J.: Feedforward compression of static and streamable 3D Gaussian splatting. IEEE TCSVT (2026)
2026
-
[8]
In: ECCV
Chen, Y., Wu, Q., Lin, W., Harandi, M., Cai, J.: HAC: Hash-grid assisted context for 3D Gaussian splatting compression. In: ECCV. pp. 422–438 (2024)
2024
-
[9]
In: CVPR
Deng, K., Liu, A., Zhu, J.Y., Ramanan, D.: Depth-supervised NeRF: Fewer views and faster training for free. In: CVPR. pp. 12882–12891 (2022)
2022
-
[10]
In: Interna- tionalWorkshopontheAlgorithmicFoundationsofRobotics(WAFR).pp.263–282 (2024)
Duisterhof, B.P., Mandi, Z., Yao, Y., Liu, J.W., Seidenschwarz, J., Shou, M.Z., Ramanan, D., Song, S., Birchfield, S., Wen, B., Ichnowski, J.: DeformGS: Scene flow in highly deformable scenes for deformable object manipulation. In: Interna- tionalWorkshopontheAlgorithmicFoundationsofRobotics(WAFR).pp.263–282 (2024)
2024
-
[11]
In: NeurIPS
Fan, Z., Wang, K., Wen, K., Zhu, Z., Xu, D., Wang, Z.: LightGaussian: Unbounded 3D Gaussian compression with 15x reduction and 200+ FPS. In: NeurIPS. vol. 37, pp. 140138–140158 (2024)
2024
-
[12]
In: ECCV
Fang,G.,Wang,B.:Mini-splatting:Representingsceneswithaconstrainednumber of Gaussians. In: ECCV. pp. 165–181 (2024)
2024
-
[13]
Foresee, F.D., Hagan, M.T.: Gauss-Newton approximation to Bayesian learning. In: Int. Conf. Neural Networks. vol. 3, pp. 1930–1935 (1997)
1930
-
[14]
PsyArXiv preprint (2022)
Fujita, K., Okada, K., Katahira, K.: The Fisher information matrix: A tutorial for calculation for decision making models. PsyArXiv preprint (2022)
2022
-
[15]
In: ECCV
Girish, S., Gupta, K., Shrivastava, A.: Eagles: Efficient accelerated 3D Gaussians with lightweight encodings. In: ECCV. pp. 54–71 (2024)
2024
-
[16]
In: CVPR
Hanson, A., Tu, A., Lin, G., Singla, V., Zwicker, M., Goldstein, T.: Speedy-splat: Fast 3D Gaussian splatting with sparse pixels and sparse primitives. In: CVPR. pp. 21537–21546 (2025)
2025
-
[17]
In: CVPR
Hanson, A., Tu, A., Singla, V., Jayawardhana, M., Zwicker, M., Goldstein, T.: PUP 3D-GS: Principled uncertainty pruning for 3D Gaussian splatting. In: CVPR. pp. 5949–5958 (2025)
2025
-
[18]
ACM TOG37(6), 1–15 (2018)
Hedman, P., Philip, J., Price, T., Frahm, J.M., Drettakis, G., Brostow, G.: Deep blending for free-viewpoint image-based rendering. ACM TOG37(6), 1–15 (2018)
2018
-
[19]
In: ICASSP
Huang, H., Huang, W., Yang, Q., Xu, Y., Li, Z.: A hierarchical compression tech- nique for 3D Gaussian splatting compression. In: ICASSP. pp. 1–5 (2025)
2025
-
[20]
In: CVPR
Jiang, Y., Shen, Z., Wang, P., Su, Z., Hong, Y., Zhang, Y., Yu, J., Xu, L.: HiFi4G: High-fidelity human performance rendering via compact Gaussian splatting. In: CVPR. pp. 19734–19745 (2024)
2024
-
[21]
ACM TOG42(4), 139:1–139:14 (2023)
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3D Gaussian splatting for real-time radiance field rendering. ACM TOG42(4), 139:1–139:14 (2023)
2023
-
[22]
ACM TOG36(4), 1–13 (2017) 16 Z
Knapitsch,A.,Park,J.,Zhou,Q.Y.,Koltun,V.:TanksandTemples:Benchmarking large-scale scene reconstruction. ACM TOG36(4), 1–13 (2017) 16 Z. Chen et al
2017
-
[23]
In: AAAI
Kong, H., Yang, X., Wang, X.: Efficient Gaussian splatting for monocular dynamic scene rendering via sparse time-variant attribute modeling. In: AAAI. vol. 39, pp. 4374–4382 (2025)
2025
-
[24]
In: CVPR
Kwak, S., Kim, J., Jeong, J.Y., Cheong, W.S., Oh, J., Kim, M.: MoDec-GS: Global- to-local motion decomposition and temporal interval adjustment for compact dy- namic 3D Gaussian splatting. In: CVPR. pp. 11338–11348 (2025)
2025
-
[25]
In: NeurIPS
Lee, J.C., Ko, J.H., Park, E.: Optimized minimal 3D Gaussian splatting. In: NeurIPS. vol. 38, pp. 135864–135888 (2025)
2025
-
[26]
In: CVPR
Lee, J.C., Rho, D., Sun, X., Ko, J.H., Park, E.: Compact 3D Gaussian representa- tion for radiance field. In: CVPR. pp. 21719–21728 (2024)
2024
-
[27]
In: CVPR
Lei, J., Weng, Y., Harley, A.W., Guibas, L., Daniilidis, K.: MoSca: Dynamic Gaus- sian fusion from casual videos via 4D motion scaffolds. In: CVPR. pp. 6165–6177 (2025)
2025
-
[28]
In: CVPR
Li, H., Liu, J., Sznaier, M., Camps, O.: 3D-HGS: 3D half-gaussian splatting. In: CVPR. pp. 10996–11005 (2025)
2025
-
[29]
Journal of Physics A: Mathematical and Theoretical 53(2), 023001 (2020)
Liu, J., Yuan, H., Lu, X.M., Wang, X.: Quantum Fisher information matrix and multiparameter estimation. Journal of Physics A: Mathematical and Theoretical 53(2), 023001 (2020)
2020
-
[30]
In: ACM MM
Liu, X., Wu, X., Zhang, P., Wang, S., Li, Z., Kwong, S.: CompGS: Efficient 3D scene representation via compressed Gaussian splatting. In: ACM MM. pp. 2936– 2944 (2024)
2024
-
[31]
In: CVPR
Lu, T., Yu, M., Xu, L., Xiangli, Y., Wang, L., Lin, D., Dai, B.: Scaffold-GS: Structured 3D Gaussians for view-adaptive rendering. In: CVPR. pp. 20654–20664 (2024)
2024
-
[32]
In: ECCV
Navaneet, K., Pourahmadi Meibodi, K., Abbasi Koohpayegani, S., Pirsiavash, H.: CompGS: Smaller and faster Gaussian splatting with vector quantization. In: ECCV. pp. 330–349 (2024)
2024
-
[33]
In: CVPR
Niedermayr, S., Stumpfegger, J., Westermann, R.: Compressed 3D Gaussian splat- ting for accelerated novel view synthesis. In: CVPR. pp. 10349–10358 (2024)
2024
-
[34]
In: ACM SIGGRAPH
Papantonakis, P., Kopanas, G., Kerbl, B., Lanvin, A., Drettakis, G.: Reducing the memory footprint of 3D Gaussian splatting. In: ACM SIGGRAPH. vol. 7, pp. 1–17 (2024)
2024
-
[35]
IEEE Access (2026)
Qiao, L., Chuprat, S.: MEAA-Net: Memory-efficient asymmetric attention for resource-constrained lung nodule classification. IEEE Access (2026)
2026
-
[36]
IEEE TPAMI pp
Ren, K., Jiang, L., Lu, T., Yu, M., Xu, L., Ni, Z., Dai, B.: Octree-GS: Towards consistent real-time rendering with LOD-structured 3D Gaussians. IEEE TPAMI pp. 1–15 (2025)
2025
-
[37]
In: NeurIPS
Wang, T., Li, M., Zeng, G., Meng, C., Zhang, Q.: Gaussian herding across pens: An optimal transport perspective on global gaussian reduction for 3DGS. In: NeurIPS. vol. 38, pp. 157898–157923 (2025)
2025
- [38]
-
[39]
In: ECCV
Xie, S., Zhang, W., Tang, C., Bai, Y., Lu, R., Ge, S., Wang, Z.: MesonGS: Post- training compression of 3D Gaussians via efficient attribute transformation. In: ECCV. pp. 434–452 (2024)
2024
-
[40]
arXiv preprint arXiv:2512.07197 (2025)
Youn, S., Lee, S., Kim, G., Kwon, W., Bae, S.H., Oh, J.: SUCCESS-GS: Survey of compactness and compression for efficient static and dynamic Gaussian splatting. arXiv preprint arXiv:2512.07197 (2025)
-
[41]
In: CVPR
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR. pp. 586–595 (2018) REFINE 17
2018
-
[42]
IEEE TVCG 8(3), 223–238 (2002) 18 Z
Zwicker, M., Pfister, H., Van Baar, J., Gross, M.: EWA splatting. IEEE TVCG 8(3), 223–238 (2002) 18 Z. Chen et al. A Supplementary Material GFLOPs vs. Latency & Computation Methodology.As discussed in Sec. 4.2, REFINE reduces GFLOPs by over3000×compared to rendering-based methods like PUP, yet the wall-clock latency reduction on a high-end GPU (e.g., RTX ...
2002
-
[43]
Forward Pass (∼5,000 FLOPs):The forward pass for a single 3D Gaus- sian primitive involves four stages: (i) 3D covariance construction from scaling and quaternions (∼100 FLOPs); (ii) 2D covariance projection using the viewing REFINE 19 matrix and affine Jacobian (∼150 FLOPs); (iii) view-dependent color evalua- tion via Degree-3 SH, computing 16 basis poly...
-
[44]
optimizable parameters (SH, rotation, scaling, opacity, posi- tion)
Backward Pass (∼10,000 FLOPs):The backward pass computes loss gradients w.r.t. optimizable parameters (SH, rotation, scaling, opacity, posi- tion). Following standard automatic differentiation principles, computing vector- Jacobian products, especially through dense matrix calculus in affine projections and SH polynomials, typically requires2×to2.5×the op...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.